
※ Effective C++을 읽고 내 생각대로 요약한 내용.
[Ch 2. 생성자, 소멸자 및 대입 연산자]
[항목 5]
◎ 선언하지 않았음에도 컴파일러가 자동으로 생성하는 함수
- 사용자가 선언하지 않았다면 컴파일러는
< 생성자 / 소멸자 / 복사 생성자 / 복사 대입 연산자 >를 자동으로 선언
□ 복사 생성자 / 복사 대입 연산자는 원본 객체의 비정적 데이터를 복사
□ 복사 대입 연산자를 private로 선언한 기본 클래스로부터 파생된 클래스의 경우 암시적 복사 대입 연산자를 가질 수 없음.
□ 참조자 / 상수 멤버 등 복사에 대한 처리가 애매한 멤버가 존재할 시 C++는 '컴파일을 거부'
[항목 6]
◎ 컴파일러가 자동 생성하는 함수가 필요없다면 확실하게 금지하자
- 자동 생성되는 기능을 허용하지 않으려면 대응되는 멤버 함수를 private로 선언, 구현은 하지 않은 채로 유지
[항목 7]
◎ 다형성을 가진 기본 클래스는 반드시 가상 소멸자를 선언하자
class BaseClass
{
}
class DerivedA : public BaseClass
{
}
main()
{
Derived* pA = new DerivedA();
... // 계속 사용하다가
BaseClass* pBase = pA;
delete pBase; // 문제 발생!! BaseClass의 소멸자가 가상이 아니라면
// Derived 클래스의 소멸자는 호출되지 않는다.
}
// .h꼭 가상 소멸자 선언, 정의하기
class BaseClass
{
pubiic:
virtual ~BaseClass();
}
// cpp
BaseClass::~BaseClass{}- 기본 클래스 인터페이스를 통해 파생 클래스 타입을 조작하는 경우는 가상 소멸자를 등록하도록 하자.
- 기본 클래스가 추상 클래스로 설계되는 경우도 소멸자의 호출은 정의되어야한다.
[항목 8]
◎ 예외가 소멸자를 떠나지 못하도록 붙들어놓자.
- 소멸자 안에서 호출된 함수가 예외를 밖으로 넘길 가능성이 있다면 소멸자에서 모두 받아서 삼키거나 (catch) / 프로그램을 끝내야한다.
- 예외가 발생할 수 있는 함수가 있다면 그것은 소멸자에서 호출하지 말아야 하며, 사용자에게 처리를 맡긴다.
class A
{
public:
void ThrowF(){throw 1;}
~A()
{
...
ThrowF();// 여기서 예외가 발생할 가능성이 있다면
}
}
-----------------------------------------------------------
// 문제가 발생하는 상황
int main()
{
try
{
func();
}
catch(...)
{
}
}
-----------------------------------------------------------
func()
{
A a;
throw 2; // 에러가 던져진 상태
}이 상황에선 stackUnwinding으로 인해 에러가 던져진 상태에서 a의 정리->~A가 호출되는데 ~A에서 에러 발생 -> 프로그램 종료 또는 정의되지 않은 행동 (UB) 이 발생한다.
이를 방지하기 위해
- 에러가 발생할 수 있는 작업에 대해선 소멸자가 아닌 다른 함수로 분리해서 사용자가 호출한다.
2-1. 사용자가 호출하는 경우
사용자는 에러에 대한 핸들링까지 해야한다.
2-2. 사용자가 호출하지 않는 경우.
사용자는 소멸자에서 처리하는 방식을 따라야 한다. (자신이 제어를 포기했으므로)
// 변경된 코드
class A
{
public:
...
void ThrowF() {throw 1;}
bool m_bClosed;
~A()
{
if(true == m_bClosed)
return;
// 2-2. 소멸자에서 삼키기 / 종료를 결정한다.
try
{
...
ThrowF();// 여기서 예외가 발생할 가능성이 있다면
}
catch(){...}
}
void Close()
{
...
m_bClosed = true;
}
}
-----------------------------------------------------------
// 2-1. 유저가 핸들링
int main()
{
A a;
...
try
{
a.Close();
}
catch(...)
{
...// 다양한 핸들링
}
}
-----------------------------------------------------------
의 형태로 사용하자.
[항목 9]
◎ 객체 생성 및 소멸 과정 중에는 절대 가상 함수를 호출하지 말자.
- 순수 가상 함수와 관련되어서는 가상 함수와 purecall에서 테스트한 내용과 같이 purecall에러에 대한 내용을 설명하며, 생성자 / 소멸자에서 절대로 순수 가상 함수의 호출을 하지 말라고 한다.
- 생성자 / 소멸자에서 순수 가상 함수가 아닌 가상 함수의 실행 => 실행은 아무 문제 없이 된다. 하지만 내가 원하는 클래스 객체가 정의한 함수가 실행되는가? 에 대한 문제가 생길 수 있음 ( 실행은 잘 됨, 하지만 생성자에서 Derived 클래스의 함수 실행을 원했는데 Base의 실행이 되면?? 매우 행복해질 수 있다.)
class Base
{
public :
// 문제 상황
// Base 클래스를 상속받은 클래스가 생성될 때
// 자동으로 상속받은 클래스가 정의한 F()를 호출하고 싶다!!
// 하지만 현실은 내가 원하는 대로 진행되지 않는다!!
Base() { F(); }
// Base의 생성자에서 순수 가상 함수를 바로 호출하는 경우 - 컴파일 에러
// 이렇게 한번 랩핑해서 실행시키면 컴파일에러는 발생하지 않는다. (매우 악독함)
void Init(){F();}
virtual void F() { printf("base\n"); };
};
class Derived : public Base
{
public:
Derived() {}
virtual void F() { printf("derived\n"); }
};
int main()
{
// 위 링크에서 테스트 한 것과 같이
// d가 생성될 때 Base의 생성자 -> Base의 F가 호출된다!!
// 순수 가상 함수의 형태가 아닌 가상 함수를 실행됐을 때
// 정상적으로 작동하는 것이 오히려 더 큰 문제가 될 수 있다!!
Derived d;
}
결과 ("derived"를 기대했지만 "base"가 나오는 모습)
[항목 10]
◎ 대입 연산자는 *this의 참조자를 반환하게 하자.
- 대입 연산자는 좌변 인자에 대한 참조자를 반환하도록 구현 (일종의 관례)
- 열혈 C++에서도 언급되었던 내용
- 모든 형태의 대입 연산자에선 좌변 객체의 참조자를 반환하게 만들자
int x,y,z;
x = y = z = 15; // 대입이 사슬처럼 이어짐
x = (y = (z = 15)); // 다음과 같은 형태도 가능
// ex)
class MyClass
{
public:
...
MyClass& operator=(const MyClass& other)
{
...
return *this;
}
MyClass& operator+=(const MyClass& other)
{
...
return *this;
}
{[항목 11]
◎ operator= 에서는 자기대입에 대한 처리가 빠지지 않도록 하자.
- 자기대입이란?
□ 객체가 자기 자신에 대해 대입 연산자를 적용하는 것
MyClass my;
...
my = my;- 자기 대입의 원인은 여러 곳에서 객체를 참조하기 때문 (중복 참조)
---------------------- 문제 코드 1 ----------------------
Widget& Widget::operator= (const Widget& rhs)
{
delete pb;
pb = new Bitmap(*rhs.pb);
return *this
}
// ① : 자기대입에 대한 검사 없음
// ② : 예외 처리에 대해 안전하지 않음.
// pb가 삭제된 이후 new pb가 예외를 내보내게 되면
// 작업은 pb가 삭제된 채로 종료되고, Widget의 pb는 삭제된 상태로 끝나고 만다.
// 내가 느낀 바로는 예외 발생 시
// operator= 의 작업이 마치 원자적(all or nothing)이지 않은 상태로 진행됨을 의미하는 것 같음.
// (똥을 싸다 끊긴 느낌처럼 pb만 해제되고 다음 작업의 진행없이 종료하는 것이 문제
// - 우리는 이렇게 예외가 발생해도 앞서 말한 문제가 일어나지 않도록 설계해야한다.)
①의 개선
// 일치성 검사를 통해 자기대입을 점검
Widget& Widget::operator= (const Widget& rhs)
{
if(this == &rhs) return *this;
delete pb;
pb = new Bitmap(*rhs.pb);
return *this
}- 자기대입에 대한 검사는 진행하지만, 자주 일어나지 않는 상황(자기대입)에 대한 검사 코드 => 처리 성능이 떨어질 수 있음
- 여전히 예외처리에 대한 문제가 발생
①과 ②의 해결
Widget& Widget::operator= (const Widget& rhs)
{
Bitmap *pOrigin = pb;
pb = new Bitmap(*rhs.pb);
delete pOrigin;
return *this;
}
// new에서 예외가 발생해도 안전하다고 할 수 있음.
// 자기자신이 들어와도 복사 후 삭제
// 가장 효율적인 방법은 아니지만, 동작함.복사 후 맞바꾸기 (copy and swap)
위 코드를 C++가 가진 두 가지 특징을 이용해 구현할 수 있음
- 복사 대입 연산자는 인자를 값으로 취하도록 선언이 가능
- 값에 의한 전달을 수행하면 전달된 대상의 사본이 생김
class Widget
{
...
void swap(Widget& rhs);
...
// 복사 생성자를 통해 임시로 생성된 객체를
// 기존의 객체와 교체
// 생성 과정에서 예외가 발생해도 예외에 안전하다.
// 자기대입 상황에서도 동일하게 복사가 진행됨
Widget& Widget::operator=(Widget rhs)
{
swap(rhs);
return *this;
}
}[항목 12]
◎ 객체의 모든 부분을 빠짐없이 복사하자.
-
복사 함수 (복사 생성자와 복사 대입 연산자)에 대해서 모든 데이터에 대해 복사를 완전하게 하도록 하자 (멤버가 추가됐다면 추가된 멤버에 대한 복사 로직 추가 필요)
-
상속 관계에서의 복사 함수는 명시적으로 기본 클래스에 대한 복사 함수를 호출해줘야한다.
이게 무슨 말이냐?
class BaseCustomer
{
public:
BaseCustomer() { printf("BaseCustomer()\n"); }
BaseCustomer(const BaseCustomer& other) { printf("BaseCustomer(const BaseCustomer&)\n"); }
BaseCustomer& operator= (const BaseCustomer& other)
{
printf("BaseCustomer operator= ()\n");
return *this;
}
private:
int x = 0;
};
// 파생 클래스의 복사 함수에서 명시적으로 기본 클래스의 복사 함수를 호출한 경우
class DerivedCustomerWithCall : public BaseCustomer
{
public:
DerivedCustomerWithCall() { printf("DerivedCustomerWithCall()\n"); }
DerivedCustomerWithCall(const DerivedCustomerWithCall& other) : BaseCustomer(other){
printf("DerivedCustomerWithCall(const DerivedCustomerWithCall& other)\n");
}
DerivedCustomerWithCall& operator= (const DerivedCustomerWithCall& other)
{
BaseCustomer::operator=(other);
printf("DerivedCustomerWithCall operator= ()\n");
return *this;
}
};
// 파생 클래스의 복사 함수에서 명시적으로 기본 클래스의 복사 함수를 호출하지 않은 경우
class DerivedCustomerWithoutCall : public BaseCustomer
{
public:
DerivedCustomerWithoutCall() { printf("DerivedCustomerWithoutCall()\n"); }
DerivedCustomerWithoutCall(const DerivedCustomerWithoutCall& other) {
printf("DerivedCustomerWithCall(const DerivedCustomerWithoutCall& other)\n");
}
DerivedCustomerWithoutCall& operator= (const DerivedCustomerWithoutCall& other)
{
printf("DerivedCustomerWithoutCall operator= ()\n");
return *this;
}
};
// 명시적으로 호출하는 객체
DerivedCustomerWithCall dcWithCall;
// 명시적으로 호출하지 않는 객체
DerivedCustomerWithoutCall dcWithoutCall;
printf("\n\n------------------------ 생성 완료 ------------------------\n\n");
printf("\n\n-------------------- 명시적 호출 버전 ---------------------\n\n");
DerivedCustomerWithCall dcWithCall2 = dcWithCall;
dcWithCall2 = dcWithCall;
printf("\n\n------------------- 명시적 호출 X 버전 --------------------\n\n");
DerivedCustomerWithoutCall dcWithoutCall2 = dcWithoutCall;
dcWithoutCall2 = dcWithoutCall;
printf("\n\n--------------------------- 종료 --------------------------\n\n");
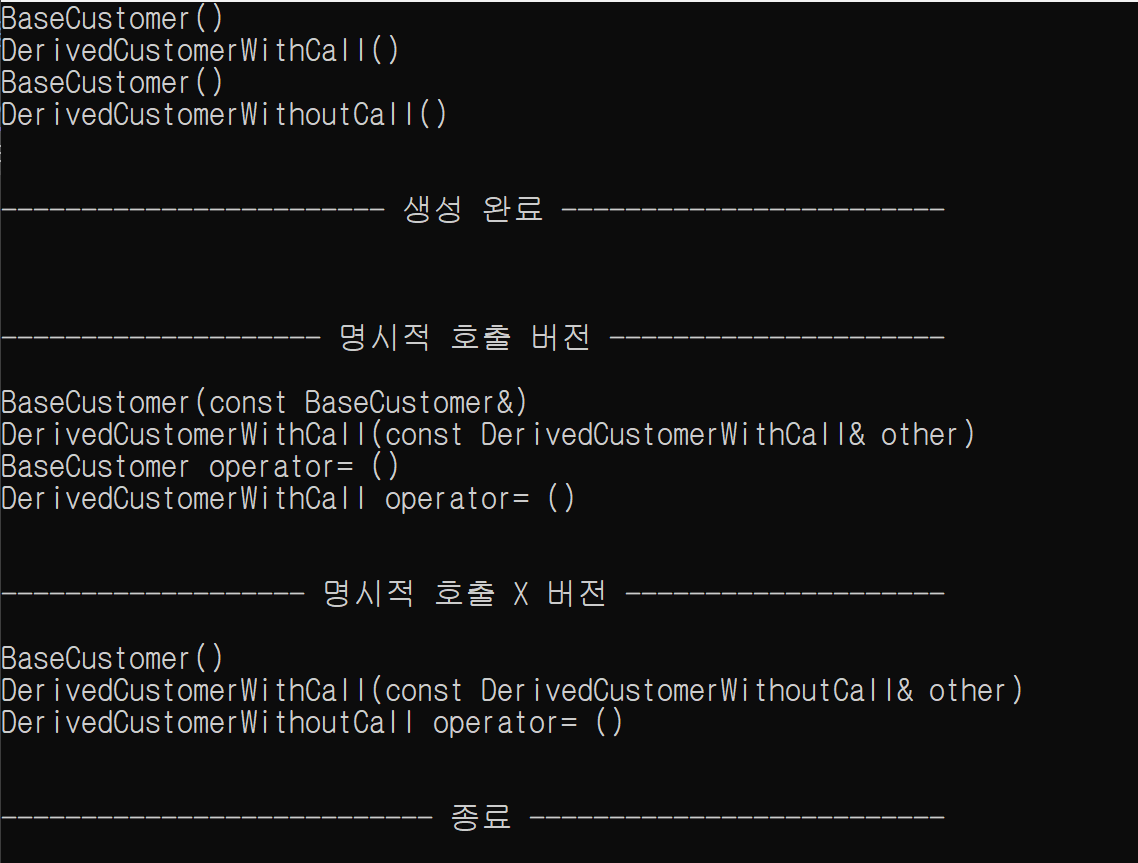
파생 클래스의 복사 함수에서 기반 클래스의 복사 함수를 명시적으로 호출하지 않으면 기반 클래스의 복사 함수는 호출되지 않는다.
명시적으로 호출하지 않는 버전을 보자.
-
복사 생성자 호출 시 기대한 것 : 파생 클래스의 복사 생성자 호출 -> 기본 클래스의 복사 생성자가 호출되는 것이지만 기본 클래스의 기본 생성자가 호출됨
-
복사 대입 연산자 호출 시 기대한 것 : 파생 클래스의 복사 대입 연산자 호출 -> 기본 클래스의 복사 대입 연산자가 호출되는 것이지만 기본 클래스의 복사 대입 연산자는 호출되지 않는다.
상속 관계에서 파생 클래스의 복사 함수를 정의할 때 기본 클래스에 대한 복사를 명시하도록 하자
😈 예외로부터 안전한 코드를 만들도록 하자 [Ch 3. 자원 관리]
[항목 13]
◎ 자원 관리에는 객체가 그만!
-
파일 / 동적 메모리 / 뮤텍스 / GUI 등 시스템에 반환해야하는 자원의 관리는 객체 생성으로 하도록 하자 (Resource Acquisition is Initialization)
-
객체의 생성자에서 할당 / 소멸자에서 해제함으로써 예외와 메모리 누수에서 안전하도록 설계한다.
[항목 14]
◎ 자원 관리 클래스의 복사 동작에 대해 진지하게 고찰하자.
- RAII 객체로 자원을 관리할 때 자원의 복사를 허락할 것인지 (참조 카운팅 또는 자원의 깊은 복사) / 막을 것인지 / 소유권을 옮길 것인지 결정하라.
[항목 15]
◎ 자원 관리 클래스에서 관리되는 자원은 외부에서 접근할 수 있도록 하자.
- 자원 관리는 RAII 객체를 통해서 할 수 있지만 ( 스마트 포인터, 자체 참조 객체 등.. ) 실제 사용은 자원을 대상으로 이루어지기 때문에 자원을 얻어야함
<typedef int FontHandle;
void ReleaseFont(FontHandle f) {}
// API 수준에서 자원을 사용해 작업하는 함수
// 자원이 필요하다!
void UseFontHandle(FontHandle f) {}
class Font
{
public:
Font(FontHandle f) : _f(f)
{}
~Font() { ReleaseFont(_f); }
private:
FontHandle _f;
};
- 자원을 얻어야 하는 경우 RAII 객체로부터 명시적 / 암시적 변환 함수의 호출을 통해 자원을 얻어올 수 있다.
class Font
{
public:
Font(FontHandle f) : _f(f)
{
printf("생성자 호출 \n");
}
Font(const Font& other) : _f(other._f){ printf("복사 생성자 호출 \n"); }
// 명시적 변환 함수.
FontHandle get() const { printf("명시적 변환 함수 호출 \n"); return _f; }
// 암시적 변환 함수
operator FontHandle() { printf("암시적 변환 함수 호출\n"); return _f; }
~Font() { ReleaseFont(_f); }
private:
FontHandle _f;
};
Font f(3);
// 명시적 변환
UseFontHandle(f.get());
// 암시적 변환
UseFontHandle(f);
// 암시적 변환으로 제공, 만약 f가 소멸되면 f2는 이미 소멸되어버린 f의 FontHandle을 가짐
FontHandle f2 = f;다만, 암시적 변환은 실수를 저지를 여지가 많기 때문에 명시적 변환을 제공할 것인지 / 암시적 변환을 허용할 것인지에 대한 결정은 조심스럽게 하자.
또한 RAII 클래스에서 객체에 대한 접근을 열어주는 것이 캡슐화 위배가 아닌가 ?
=> 그렇게 생각할 수도 있지만 애초에 RAII 의 핵심은 "데이터 은닉"이 목적이 아닌 "자원 해제"임
[항목 16]
◎ new / delete를 사용할 때는 형태를 반드시 맞추자.
- 지금 보니까 잘 정리되진 않았지만. new / delete 테스트에서 테스트했던 내용과 관련된 부분을 설명하는 것 같다.
또한 여기선 []에 대해 "기본 제공 타입이라 해도 이들의 배열에 대해 []로 해제하지 않으면 UB가 나타날 수 있다"라고 설명하고 있음
[항목 17]
◎ new로 생성한 객체를 스마트 포인터에 저장하는 코드는 별도의 한 문장으로 만들자.
int priority();
void processWidget(std::tr1::shared_ptr<Widget> pw, int priority)
main()
{
...
processWidget(std::tr1::shared_ptr<Widget>(new Widget), priority())
}를 실행하게 되면 컴파일러는 processWidget 호출 코드를 만들기 위해 각 인자를 평가하게 되고, 함수의 호출 전에 3개의 연산을 위한 코드를 만들어야한다.
- priority() 호출
- new Widget 실행
- shared_ptr 생성자 호출
여기서 컴파일러 제작사마다 다른 연산 실행 순서가 정해질 수 있음.
다만, shared_ptr의 생성자는 new Widget후에 실행되어야 할 것임.
만약
① new Widget 실행
② priority() 호출
③ shared_ptr 생성자 호출
시점에 new 생성 -> priority() 호출 과정에서 예외 발생한다면
new로 생성한 메모리에 대한 누수가 발생할 수 있다.
(즉,
자원이 생성되는 시점 ---> 예외가 발생할 수 있다! ---> 자원 관리 객체로 넘어가는 시점
그렇기 때문에 이런 식으로 사용하자
std::tr1::shared_ptr<Widget> pw(new Widget);
processWidget(pw, priority());😈 결국 자원 관리도 예외에 대한 처리가 중요하다?[Ch 4. 설계 및 선언]
[항목 18]
◎ 인터페이스 설계는 제대로 쓰기엔 쉽게, 엉터리로 쓰기엔 어렵게 하자.
- 사용자의 실수에 명확하게 알 수 있도록 타입을 적절히 준비해두자
---- 실수 코드 ----
class Date {
public:
// 월, 일, 년 순
Date(int month, int day, int year);
};
// 사용할때 실수로 일과 월이 잘못 들어갔다!
// 이런 실수를 방지하자.
Date d(30, 3, 1995); ---- 실수 방지 코드 ----
// 일 / 월 / 년을 새롭게 정의
struct Day {
explicit Day(int d) : val(d) {}
int val;
};
struct Month {
explicit Month(int m) : val(m) {}
int val;
};
struct Year {
explicit Year(int y) : val(y) {}
int val;
};
class Date {
public:
Date(const Month& m, const Day& d, const Year& y);
};
// 순서를 명확하게 만든다.
// 순서가 바뀌었다면 컴파일 에러로 명확하게 알 수 있다.
Date d(Month(3), Day(30), Year(1995));-
기본 제공 타입(int 등)처럼 동작하도록 만들자.
□ 사용자는 기본 제공 타입의 사용에 익숙 -> 우리가 만들 인터페이스도 일관성을 지키자. -
shared_ptr를 반환해 사용자가 해제할 일이 없도록 하자.
[항목 19]
◎ 클래스 설계는 타입 설계와 똑같이 취급하자.
클래스 설계 전에 이 항목들을 고려하자.
- 객체의 생성 및 소멸을 어떻게 설정할 것인가?
- 객체 초기화(복사 생성자)와 객체 대입(복사 대입)에 대한 처리를 어떻게 할 것인가?
- '값에 의한 전달'을 처리하는 복사 생성자를 어떻게 처리할 것인가?
- 객체 값에 대한 제약을 명확히 해야한다.
- 명시적 / 암시적 타입 변환을 허용할 것인가?
- 상속을 염두에 두고 클래스를 설계하였는가? (virtual)
- 어떤 연산자와 함수가 의미있을까?
- 표준 함수들 중 금지할 함수가 존재하는가?
- 멤버에 대해 접근 제한자(private, protect, public)을 설정하고, friend로 권한을 줄것인가?
- 예외 및 자원 사용 등에 대해서 안전한가?
- 동일 계열의 타입군 전체에 대해서 적용해야하나?
(그렇다면 클래스 템플릿을 활용하자)- 정말로 필요한가?
(간단하게 비멤버함수나 템플릿으로도 정의가 가능한데 굳이 새로운 클래스를 만들었나?)
[항목 20]
◎ '값에 의한 전달'보다는 '상수객체 참조자에 의한 전달' 방식을 택하는 편이 더 낫다.
-
기본 제공 타입 및 STL 반복자, 그리고 함수 객체 타입에는 '값에 의한 전달'이 더 적절하다.
-
C++는 기본적으로 함수에 객체를 전달할 때 '값에 의한 전달(call by value)'을 사용 -> 다른 방식을 지정하지 않는 한 함수 매개변수는 실제 인자의 '사본'을 통해 초기화되며, 호출한 쪽도 '사본'을 돌려받고, 사본을 만들어내는 원천은 복사 생성자임
-
함수에 객체가 전달될 때 객체의 생성 (복사 생성자), 소멸 (소멸자)에 호출에 대한 작업이 계속 일어남
struct Str
{
Str(const char* s) :str{ s } { printf("Str() : %s\n",str.c_str()); }
Str(const Str& s) :str{ s.str } { printf("Str(const Str&) : %s\n",str.c_str()); }
~Str() { printf("~Str() : %s\n", str.c_str()); }
// std::string의 생성자 호출도 일어나지만 코드 수준에서 확인을 위해 랩핑
std::string str;
};
class Person
{
public :
Person() : name{ "name" }, address{"address"} { printf("Person()\n"); };
Person(const Person& other) : name{ other.name }, address{other.address} { printf("Person(const Person&)\n"); }
virtual ~Person() { printf("~Person()\n"); }
// ...
private:
Str name;
Str address;
};
class Student : public Person
{
public :
Student() : schoolName{ "schoolName" }, schoolAddress{ "schoolAddress" } { printf("Student()\n"); }
Student(const Student& other) : Person(other), schoolName{ other.schoolName}, schoolAddress{ other.schoolAddress } { printf("Student(const Student&)\n"); }
~Student() { printf("~Studentt()\n"); }
private:
Str schoolName;
Str schoolAddress;
};
bool validateStudent(Student s) { return true; }
int main()
{
printf("\n----------------------- 시작 -----------------------\n\n");
Student plato;
printf("\n------------------- 함수 호출 -------------------\n\n");
bool platoIsOk = validateStudent(plato);
printf("\n----------------------- 종료 -----------------------\n\n");
}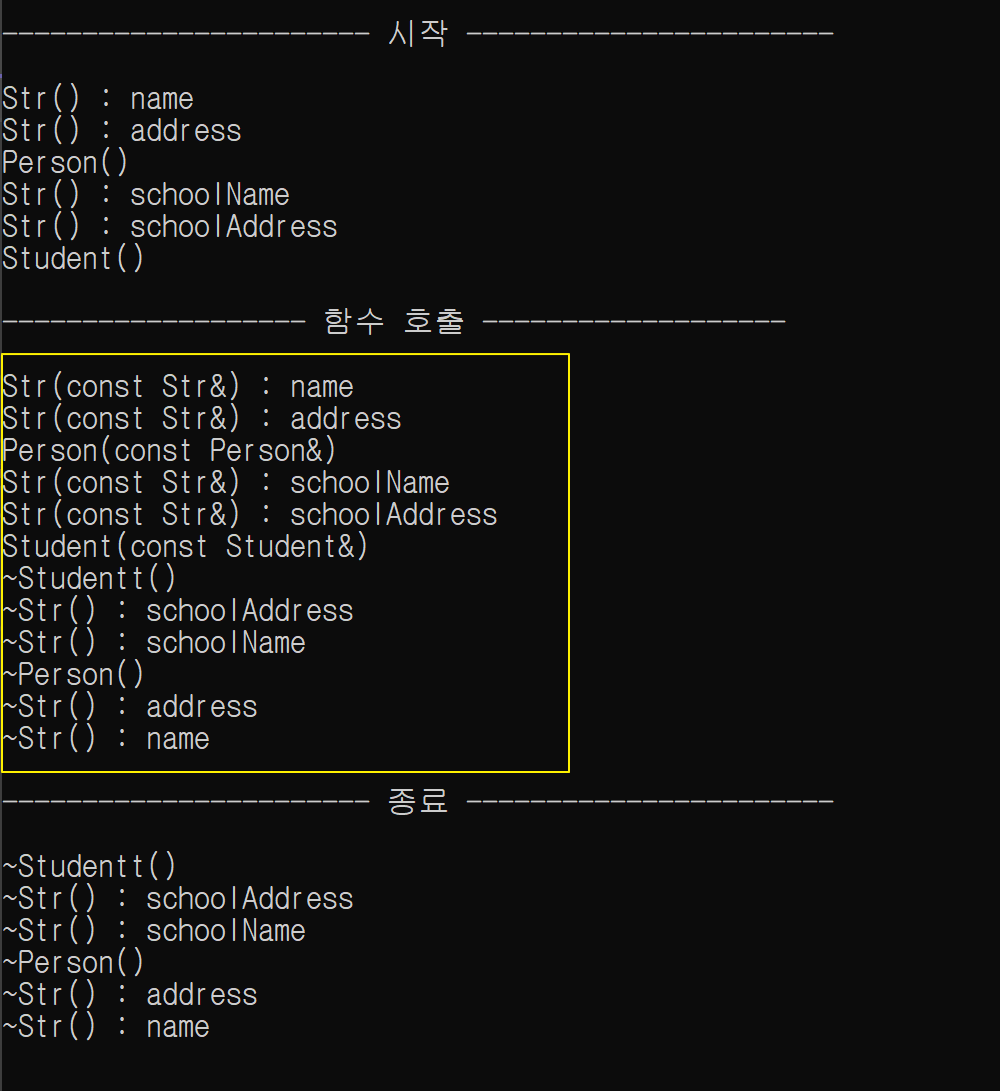
함수 호출 시 객체의 사본이 생성/소멸 되며 노란색 박스만큼의 작업이 이루어진다.
- 사본을 만드는 방식으로 객체를 전달했을 때 '복사 손실'이 발생할 수 있음
// 복사 손실 문제
class Person
{
public :
// 기존 코드는 동일
virtual void Print() const
{
printf("Person::Print()\n");
}
class Student : public Person
{
public :
// 기존 코드는 동일
virtual void Print() const override
{
Person::Print();
printf("Student::Print()\n");
}
};
bool copySlicing(Person p) { p.Print(); return true; }
int main()
{
printf("\n----------------------- 시작 -----------------------\n\n");
Student plato;
printf("\n------------------- 함수 호출 -------------------\n\n");
copySlicing(plato);
printf("\n----------------------- 종료 -----------------------\n\n");
}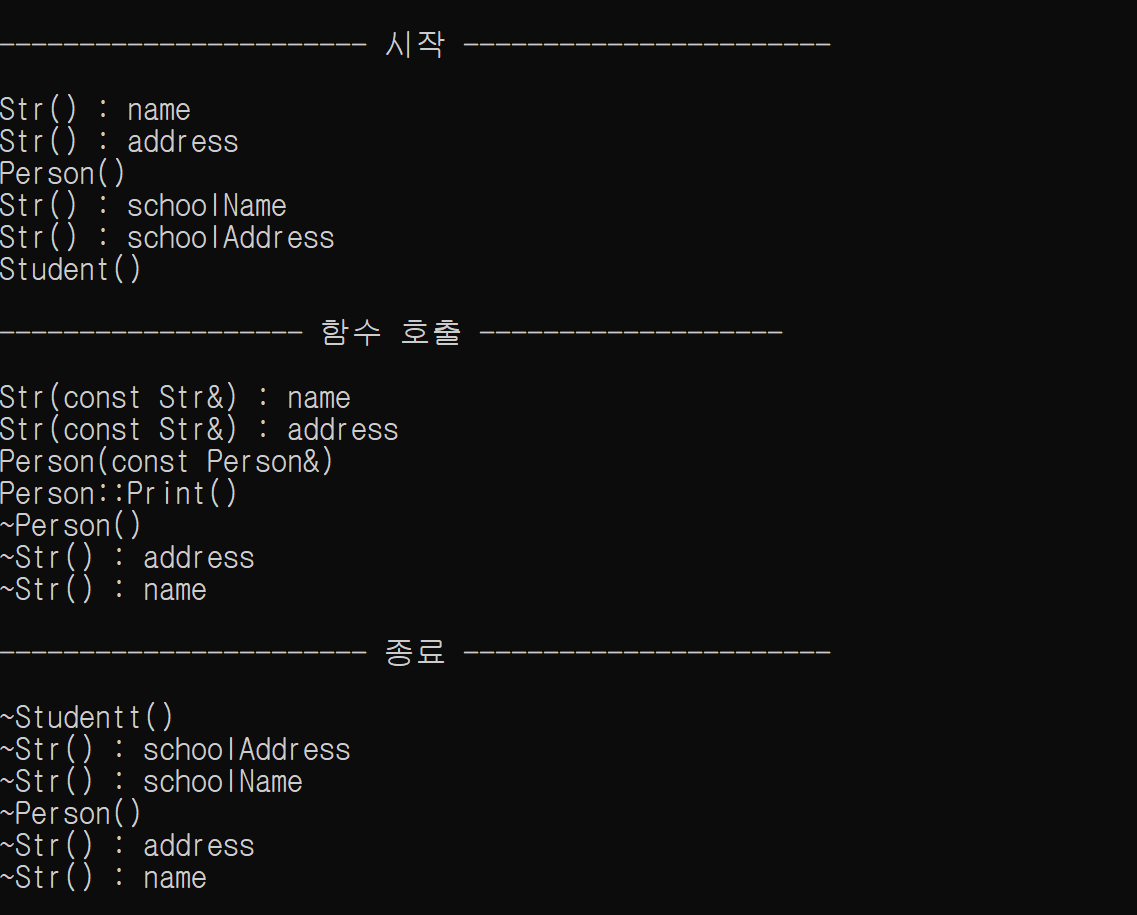
복사손실이란?
파생 클래스 객체를 기본 클래스 타입의 객체로 전달할 때, 파생 클래스의 데이터가 소실되어 기본 클래스 부분만 복사되는 현상
=>함수 호출 부분을 보면 Student 객체를 Person 객체로 전달할때 Person의 사본만 만들어짐 -> Student 객체의 기능을 할 수 없다!!
- 참조에 의한 전달 방식으로 만들면 이러한 단점들을 해결할 수 있다.(매번 함수 호출 시 객체의 사본 생성, 복사 손실)
// 참조에 의한 전달 방식으로 생성
// 기존과 동일
// 참조로 받는다! const& : 변경하지 않겠다!
bool validateStudent(const Student& s) { return true; }
printf("\n----------------------- 시작 -----------------------\n\n");
Student plato;
printf("\n------------------- 함수 호출 -------------------\n\n");
bool platoIsOk = validateStudent(plato);
printf("\n----------------------- 종료 -----------------------\n\n");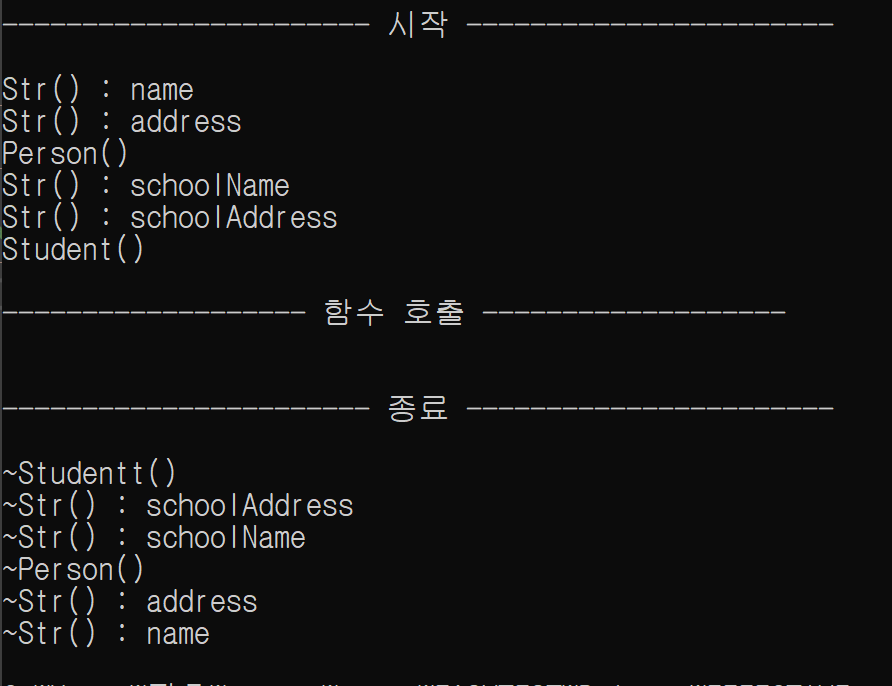
복사가 생기지 않음을 확인할 수 있음.
[항목 21]
◎ 함수에서 객체를 반환해야 할 경우에 참조자를 반환하려고 들지 말자
절대 해선 안된다.
- 지역 스택 객체에 대한 포인터나 참조자를 반환하는일 (함수 호출 과정에서 스택에서 벌어지는 일을 생각하면.. 당연히 UB)
- 힙에 할당된 객체에 대한 참조자를 반환하는 일 ( Delete 어떻게 할건데.. )
- static 변수로 할당하면? ( 스레드 안전성 문제, 논리 오류 존재한다)
-> 객체로 반환해야 할 경우엔 그냥 객체로 반환하자!
[항목 22]
◎ 데이터 멤버가 선언될 곳은 private 영역임을 명심하자.
-
문법적 일관성을 지킬 수 있으며 데이터에 대한 접근 권한을 설정할 수 있다. (외부 접근에 대한 getter / setter 설정으로)
-
이렇게 함으로써 캡슐화를 시킨다 (함수를 통해 데이터 멤버에 접근할 수 있도록 하면 구현과 수정이 용이하며, 사용자는 내부 구현을 신경쓸 필요가 없음)
-
쓸모 있는 구분은 결국 private이냐 (캡슐화) / private이 아니냐 (캡슐화x) 이다.
-
protected 변수도 public 변수와 마찬가지로 변수가 바뀌었을 때 변수에 의존하는 코드들을 다 바꿔야함 => 결국 이런 구조에선 코드도 다 망가진다. public이든 protected든 getter / setter 로 데이터에 접근하도록 하고 멤버는 private으로 가지자
[항목 23]
◎ 멤버 함수보다는 비멤버 비프렌드 함수와 더 가까워지자.
- private 멤버에 직접 접근할 일이 없는 멤버 함수는 '비멤버 비프렌드' 함수로 쫓아내버리자 (편의성 함수의 경우) : 멤버 함수로 두면 private 멤버에 접근할 일이 없지만, 언제든지 접근할 수 있다. 그 가능성을 '비멤버 비프렌드'로 옮겨 아예 접근할 수 없도록 한다. (캡슐화 ↑)
0...... - 또한 쫓아낸 '비멤버 비프렌드' 함수를 클래스와 같은 namespace안에 두고 여러 헤더파일로 나누어 관리하도록 한다. (패키징 유연성 ↑, 기능적인 확장성 ↑)
[항목 24]
◎ 타입 변환이 모든 매개변수에 대해 적용되어야 한다면 비멤버 함수를 선언하자
// --------------------------- 문제 ---------------------------
class Rational
{
public:
Rational(int n = 0, int d = 1) : num{ n }, den{d} {}
int numerator() const { return num; }
int denominator() const { return den; }
const Rational operator*(const Rational& other)
{
return Rational(num * other.num, den * other.den);
}
private:
int num;
int den;
};
int main()
{
Rational oneHalf(1, 2);
Rational result;
// 성공
// oneHalf.operator*(2)
// -> 2는 Rational(2)로 암시적 변환
result = oneHalf * 2;
//실패
// 2.operator*(oneHalf)
// -> int(2)에는 클래스 멤버함수가 없음. this 자리는 변환 안 됨.
result = 2 * oneHalf;
}
// --------------------- 비멤버 함수로 옮긴다 ---------------------
const Rational operator*(const Rational& lhs, const Rational& rhs)
{
printf("전역 호출\n");
return Rational(lhs.numerator() * rhs.numerator(), lhs.denominator() * rhs.denominator());
}
// 위와 같은 형태는 1, 2 모두 성공-> 이렇게 사용할 경우는 암시적 변환이 잘 적용되도록 비멤버 함수로 만든다.
[항목 25]
◎ 예외를 던지지 않는 swap에 대한 지원도 생각해보자.
- 복사를 사용하는 std::swap()
- 기본 std::swap (Modern C++11 Move전)은 복사를 사용
- 내부 데이터를 포인터로 가지는 경우 swap 호출 시 custom swap으로 객체에 대한 복사를 줄이고 싶을 때 사용할 수 있는 방법.
namespace std
{
// 기본 std::swap의 전형적인 구현
template <typename T>
void swap(T& a, T& b)
{
T temp(a);
a = b;
b = temp
}
}
- 외부 함수로는 private한 데이터에 대한 접근이 불가함 -> 멤버 함수 제작 필요
- 문법적 제약 (함수 템플릿의 부분 특수화가 금지됨) -> 비멤버 오버로딩 필요
- 사용자가 swap 호출 시 std::swap이 아닌 custom swap에 대한 우선순위 부여 -> ADL : Argument-dependent lookup (인자 기반 탐색) 활용
- 인자 기반 탐색이란?
어떤 함수에 어떤 타입의 인자가 있으면, 그 함수의 이름을 찾기 위해 해당 타입의 인자가 위치한 네임스페이스 내부의 이름을 탐색하는 규칙
// ------------------ 일반 클래스의 경우 ------------------
namespace MyNamespace
{
class Widget
{
public:
// 1. 멤버 함수 (private 접근용)
void swap(Widget& other)
{
// custom swap
}
private:
WidgetImpl *pImpl;
};
// 2. 비멤버 함수 (ADL용)
void swap(Widget& a, Widget& b) {
a.swap(b);
}
}
// 3. std::swap 특수화 (가능함!)
namespace std
{
// std안에서 Widget에 대한 완전 특수화 (타입 고정)
template<>
void swap(Widget& a, Widget& b) {
a.swap(b);
}
}
// ------------------ 템플릿 클래스의 경우 ------------------
namespace MyNamespace
{
template<typename T>
class Widget
{
public:
// 1. 멤버 함수 (private 접근용)
void swap(Widget& other)
{
// custom swap
}
private:
WidgetImpl *pImpl;
};
// 2. 비멤버 함수 (ADL용) - ★이게 유일한 방법★
template<typename T>
void swap(Widget<T>& a, Widget<T>& b) {
a.swap(b);
}
// 3. std::swap 특수화 -> [컴파일 에러!]
// C++은 함수 템플릿의 부분 특수화를 금지함.
// namespace std
// {
// template<typename T>
// void swap<Widget<T>>(Widget<T>& a, ...) { ... } // 불가능
// }
}사용하는 측에선 해당 형태로 사용하도록 한다.
// std::swap을 일단 넣어두되, 찾을만큼 찾고 (ADL (인자 기반 탐색)으로 먼저 찾고), 없으면 그때 사용해줘! 라는 의미.
using std::swap;
swap(a, b);
// std::swap(a,b); 이것은 바로 std에서 제공되는 swap을 사용해달라는 의미
// 일반 클래스에서는 템플릿 완전 특수화를 통해 특수화된 swap (3번) 찾을 수 있음,
// 클래스 템플릿의 경우는 기본 제공 std::swap사용그리고 멤버함수의 swap은 예외에 대한 안전성 보장을 무조건 하도록 만들어야한다.
| 구분 | ① 멤버 함수 swap | ② 비멤버 swap (ADL) | ③ std::swap 특수화 | 비고 |
|---|---|---|---|---|
| 일반 클래스 | 필수 (private 접근용) | 권장 (택1) (일관성 유지) | 권장 (택1) ( std::swap 직접 호출 대응) | std::swap의 완전 특수화가 문법적으로 허용됨. 비멤버 함수가 없어도 특수화 덕분에 동작함. |
| 템플릿 클래스 | 필수 (private 접근용) | 필수 (★) (ADL을 위한 유일한 해법) | 불가능 ❌ (문법적 금지) | C++은 함수 템플릿의 부분 특수화(Partial Specialization)를 금지함. 따라서 std::swap 특수화가 불가능하며, 비멤버 오버로딩이 유일한 방법임. |
⭐ 컴파일러를 잘 모르니 정말 어렵다. 몇 번이고 계속 읽어보고 사용해봐야 사용법이 익을 듯하다
[Ch 5. 구현]
[항목 26]
◎ 변수 정의는 늦출 수 있는 데까지 늦추는 근성을 발휘하자.
-
변수를 정의하게 되면 생성자와 소멸자의 호출에 대한 비용은 무조건 존재
-
함수에서 미리 객체를 정의해놓고 활용하면 사용하지 않더라도 객체의 생성/소멸에 대한 비용이 들어가기 때문에 필요할때 정의하며, 생성자로 초기화할 수 있다면 그렇게 진행하도록 한다.
// --------- 비효율적인 코드 1 ---------
std::string encryptPassword(const std::string & password)
{
const size_t MinimunPasswordLength = 10;
// password.length() < MinimunPasswordLength 상황엔 사용하지 않는데 미리 정의되어있음 -> 쓸데없는 생성자 / 소멸자의 호출이 이루어진다.
string encrypted;
if (password.length() < MinimunPasswordLength)
{
throw logic_error("Password is too short");
}
return encrypted;
}
// --------- 비효율적인 코드 2 ---------
std::string encryptPassword(const std::string & password)
{
const size_t MinimunPasswordLength = 10;
if (password.length() < MinimunPasswordLength)
{
throw logic_error("Password is too short");
}
// 사용할 때 정의하도록 만들었지만
// 생성자 -> 대입 연산자에 의해 대입이 이루어진다.
string encrypted;
encrypted = password;
return encrypted;
}
// --------- 수정 코드 ---------
std::string encryptPassword(const std::string & password)
{
const size_t MinimunPasswordLength = 10;
if (password.length() < MinimunPasswordLength)
{
throw logic_error("Password is too short");
}
// 필요할 때 생성하며, 기본 생성자 + 대입으로 이루어지던 작업을
// 복사 생성자 한번으로 처리하였다.
string encrypted(password);
return encrypted;
}[항목 27]
◎ 캐스팅은 절약, 또 절약! 잊지 말자
-
기존 C 스타일 캐스트
(T) 표현식 또는 T (표현식) 의 형태
-
C++ 스타일 캐스트
-
static_cast(표현식)
- 암시적 변환을 강제로 진행할 때 사용
- 흔히 이루어지는 타입변환을 진행할 때 사용
( void <-> 일반 포인터 )
( BaseClass <-> DerivedClass* )
( Object -> const Object )
-
dynamic_cast(표현식)
- 안전한 다운캐스팅을 할 때 사용 (주어진 객체가 어떤 클래스 상속 계통에 속한 특정 타입인지 아닌지를 결정할 때)
- 신경 쓰일 정도로 런타임 비용이 높은 캐스팅
-
const_cast(표현식)
- 객체의 상수성 또는 휘발성 (volatile) 제거 용도로 사용
( const object -> object )
( volatile int -> int )
- 객체의 상수성 또는 휘발성 (volatile) 제거 용도로 사용
-
reinterpret_cast(표현식)
- 하부 수준 캐스팅에 사용
( 포인터 -> int ) 등..
- 하부 수준 캐스팅에 사용
-
-
C 스타일의 캐스트보단 C++ 스타일의 캐스트를 활용하자
- 알아보기 쉽다 -> 어느 부분에서 타입 시스템이 망가졌는지 확인이 편하다
- 각각의 캐스트엔 목적이 있기 때문에, 어떤 목적으로 캐스트롤 사용했는지 알 수 있으며, 컴파일러 쪽에서도 사용 에러를 진단하기 용이하다.
-
캐스팅은 "컴파일러야 이 타입으로 처리해줘"가 아니다.
- 실제로 자료형 (int -> double, 처리 타입이 아예 다름) 또는 상속관계의 포인터 변환 (기본 클래스 객체와 파생 클래스 객체의 실제 위치가 다를 수 있음) => 런타임에 추가적인 처리 비용이 들 수 있음
-
의도대로 동작하지 않을 수 있다.
// -------------------- 문제 코드 --------------------
class Window
{
public:
virtual void onResize() {}
};
class SpecialWindow : public Window
{
public:
virtual void onResize()
{
//우리는 이 객체에서 Window클래스의 onResize를 실행하고 싶다.
// 잘못된 방식!! 새로운 Window 임시객체가 생성되고, 그것의 onResize를 호출한다.
static_cast<Window>(*this).onResize();
}
};
// -------------------- 정상 코드 --------------------
class Window
{
public:
virtual void onResize() {}
};
class SpecialWindow : public Window
{
public:
virtual void onResize()
{
// 정상적으로 *this에서 Window::onResize()를 호출한다.
Window::onResize();
}
};
-
기반 클래스 포인터(Base*)를 가지고 있는데, 파생 클래스(Derived)에만 있는 함수를 써야 해서 캐스팅을 해야 한다면 dynamic_cast를 하고 싶어진다면 다시 생각해보자 (dynamic_cast를 하지 않는 구조로).
-
(대안 1) : 애초에 파생 클래스 포인터를 관리해서 사용하도록 한다.
-
(대안 2) : 기반 클래스에 가상 함수를 달아 가상 함수를 호출하도록 하자
// ----------------- 나쁜 예시 ----------------- vector<Window*> winPtrs; // 루프 도는 중.. if (SpecialWindow* sw = dynamic_cast<SpecialWindow*>(winPtrs[i])) { sw->blink(); // 캐스팅 성공 시 호출 } // ----------------- 대안 1 ----------------- vector<SpecialWindow*> specialWinPtrs; // 애초에 전용 컨테이너 사용 // 루프 도는 중.. specialWinPtrs[i]->blink(); // 캐스팅 필요 없음! 빠르고 안전함. // ----------------- 대안 2 ----------------- vector<Window*> winPtrs; // 루프 도는 중.. winPtrs[i]->blink(); // 애초에 blink를 가상 함수로!!
-
[항목 28]
◎ 내부에서 사용하는 객체에 대한 '핸들'을 반환하는 코드는 되도록 피하자.
'핸들'이란? 다른 객체에 손을 댈 수 있게 하는 매개자 (참조자, 포인터 및 반복자를 의미)
- 핸들을 반환하게 되면 발생할 수 있는 문제
- 핸들을 반환하게되면 상수함수여도 호출한 쪽에서 객체를 수정 가능하다.
- 무효 참조 핸들이 생길 수 있다.
class Point
{
public:
Point(int x, int y);
...
void SetX(int newVal);
void SetY(int newVal);
private:
int x,y;
};
struct RectData
{
Point ulhc; // upper left handle corner
Point lrhc; // lower right handle corner
}
class Rectangle {
private:
shared_ptr<RectData> pData;
public:
// 문제 1. upperLeft가 상수함수여도 호출한 쪽에서 객체를 수정 가능하다.
Point& upperLeft() const { return pData->ulhc; }
// 문제 2. 문제 1은 해결되었지만 무효 참조 핸들이 생길 수 있다.
const Point& lowerRight() const { return pData->lrhc; }
};
class GUIObject { ... };
const Rectangle boundingBox(const GUIObject& obj){ ... }
int main()
{
GUIObject *pgo;
...
// 문제2 !! 임시객체가 갖고 있는 데이터에 대한 연결
// 임시객체는 바로 소멸됨!! ->
// 현재 pUpperLeft는 사라진 임시객체가 반환한 주소를 들고 있음.. UB
const Point *pUpperLeft = &boundingBox(*pgo).upperLeft());
}
[항목 29]
◎ 예외 안전성이 확보되는 그날 위해 싸우고 또 싸우자!
예외 안전성을 가진 함수란?
- 예외가 발생했을 때 자원이 새도록 만들지 않아야 한다.
- 예외가 발생해도 자원에 대한 반환은 이루어져야함.
- 예외가 발생했을때 자료구조가 더럽혀지지 않아야 한다.
- 아마도.. 예외가 발생하더라도 사용하는 데이터에 대한 처리는 일관되게 처리해야 한다는 의미인 것으로 느껴짐
-
예외 안전성을 갖춘 함수란 아래의 3가지 보장 중 하나를 제공한다.
- 기본적인 보장 (basic guarantee)
- 예외를 처리하긴 하나, 프로그램의 상태가 예측되진 않음 (예외 처리의 형태를 다양하게 만들 수 있으니)
- 예외를 처리하긴 하나, 프로그램의 상태가 예측되진 않음 (예외 처리의 형태를 다양하게 만들 수 있으니)
- 강력한 보장 (strong guarantee)
- 원자성 (all or nothing)을 보장하는 형태, 예외가 발생한다면 예외 전의 상태를 보장
- 원자성 (all or nothing)을 보장하는 형태, 예외가 발생한다면 예외 전의 상태를 보장
- 예외불가 보장 (nothrow guarantee)
- 예외를 절대 던지지 않겠다는 보장
// 절대 예외를 던지지 않겠다 (x) // 이 함수에서 예외가 발생되면 unexpected() 함수가 호출되어야함 (o) // set_unexpected 함수로 실제 unexpected함수 호출 시 실행 함수 지정 int doSomething() throw; - 기본적인 보장 (basic guarantee)
-
강력한 보장을 제공하는 방법 (Copy - And - Swap)
- 이 방법은 객체에 대해 적용하기는 좋지만, 함수 전체가 강력한 예외 안전성을 갖는걸 보장하지는 않는다.
- 또한 복사에 대한 비용이 존재하고, 위와 같은 단점이 있기 때문에 실용성이 확보되는 경우에만 강력한 보장을 제공하라!
struct PMImpl
{
std::shared_ptr<Image> bgImage;
int imageChanges;
};
class PrettyMenu
{
std::shared_ptr<PMImpl> pImpl;
Mutex mutex;
public:
void changeBackground(std::istream& imgSrc)
{
using std::swap;
// 1. 자원 관리 (RAII)
std::lock_guard<Mutex> guard(mutex);
// 2. 사본 생성 (Copy)
// 여기서 예외가 나면? 원본 pImpl은 건드리지 않았으므로 안전!
std::shared_ptr<PMImpl> pNew(new PMImpl(*pImpl));
// 3. 사본 수정 (Modify)
// 여기서 예외가 나도 pNew만 사라질 뿐, 원본은 안전!
pNew->bgImage.reset(new Image(imgSrc));
++pNew->imageChanges;
// 4. 맞바꾸기 (Swap)
// 포인터 swap은 절대로 예외를 던지지 않음 (Nothrow)
swap(pImpl, pNew);
// 종료 시 맞바꾼 데이터 제거
}
// 다만..
void SomeFunc(...)
{
...
// f1 실행 후 f2에서 예외가 발생한다면
// f1 과 f2가 예외에 대해 강력한 보장을 한다고 해도
// SomeFunc은 강력한 보장을 할 수 없음
// 이미 f1()에 대해 내부가 변경되었기 때문에..
// 기본적인 보장을 해야한다.
f1();
f2()
...
}
};[항목 30]
◎ 인라인 함수는 미주알고주알 따져서 이해해 두자.
- 장점
- 함수 호출 비용 제로 : 스택 프레임 생성, 인자 전달, 점프(Jump) 등의 오버헤드가 사라짐
- 문맥적 최적화 : 대체적으로 컴파일러 최적화는 함수 호출이 없는코드가 연속적으로 이어지는 구간에 적용되도록 설계되었기 때문에 컴파일러가 함수 본문에 대해 "문맥적 최적화 ( 인라인된 코드를 펼쳐놓고 필요없는 부분 제거 )" 를 걸기 용이함
- 단점
- 코드 비대화, 캐시 적중률 하락, 페이징 횟수의 증가 : 함수 호출문 -> 본문으로 바꿔치기하는 것이기 때문에 남발했다간 코드의 크기가 커질 수 있음 (페이징 횟수가 늘어나고, 명령어 캐시 적중률이 떨어질 가능성이 큼)
- 라이브러리 설계 시 유지보수의 문제 : 해당 인라인 함수를 호출하는 코드까지 모두 다시 컴파일 필요 (일반 함수의 경우 라이브러리 수정, 빌드 후 링크만 하면 됨)
✨ inline은 컴파일러에게 하는 '요청'이지 '명령'이 아니다.
- 컴파일러가 판단하기에 복잡한 함수 (loop, 재귀 등..)가 존재하는 형태
- 가상 함수의 호출을 하는 형태
-
암시적 inline
- 클래스의 정의 안에 함수를 바로 정의하는 형태
class Person
{
public:
...
// 암시적 inline 요청
int age() const {return theAge;}
};-
생성자 / 소멸자에서는 웬만하면 inline하지 마라
class Base { public : ... private: std::string bm1, bm2; } class Derived : public Base { public: // inline Derived() {} ... private: std::string dm1, dm2, dm3; } // 생성자 , 소멸자에선 멤버에 대해 자동으로 생성 / 소멸되도록 코드가 만들어진다. // inline이 된다는 것은 이 거대한 코드가 다 박혀버리기 때문에 웬만해서는 생성자 / 소멸자를 inline으로 작성하지 말아라. // 생성자에 대한 개념적인 코드 Derived::Derived() { Base::Base(); try{ dm2.std::string::string(); } catch(...) { Baes::~Base(); throw; } .... }[항목 31]
◎ 파일 사이의 컴파일 의존성을 최대로 줄이자.
-
컴파일러는 객체의 크기를 컴파일 시점에 알아야 한다 -> 클래스 설계 시 그 클래스의 구현 세부사항에 다른 클래스의 구현을 알아야하는 경우 컴파일 의존성이 발생한다. (컴파일 시간이 매우 길어짐)
-
이에 대한 해결로 인터페이스 / 구현의 분리가 필요.
컴파일 의존성을 최소화하는 핵심 원리 : 정의부에 대한 의존성을 선언부에 대한 의존성으로 변경해야함⭐ 다음의 방법들은 구현과 인터페이스를 분리함으로써 파일들 간의 컴파일 의존성을 완화시킴
⭐ 하지만 헤더 파일에 함수 본문이 위치하지 않기 때문에 인라인 최적화가 되기는 어려움.
-
방법 1. Pimpl 관용구 (pointer to implementation) 을 활용
- 대상 변경 시 해당 cpp만 재컴파일 -> 컴파일 시간의 단축, ABI 호환성 좋음 (DLL)
- 구성 요소에 대한 노출이 없음 (헤더엔 impl*만 존재)
- 모든 로직은 impl* 를 거치기 때문에 실행 비용↑
- impl*에 대한 크기와 초기화가 필요하다.
<// ---- Person.h 파일 ---- class PersonImpl; class Date; class Address; // 이러한 형태의 클래스를 핸들 클래스라고 함 class Person { public: Person(const std::string& name, const Date& birthday, const Address& addr); std::string name() const; std::string birthDate() const; std::string address() const; //... private: std::tr1::shared_ptr<PersonImpl> pImpl; }; ---- Person.cpp 파일 ---- #include "Person.h" #include "PersonImple.h" // 실제 PersonImpl클래스 정의도 include해야함 Person:: Person(const std::string& name, const Date& birthday, const Address& addr){...} std::string Person::name() cosnt { return pImpl->name(); }
-
-
방법 2. 인터페이스 클래스를 활용
추상 클래스 또는 인터페이스 클래스를 통해 인터페이스만 제공하고, 팩토리 함수를 통해 파생 클래스의 인스턴스를 생성해서 활용하도록 한다. -
(2-1) 가상 함수 구현을 통한 활용
- 대부분의 함수가 가상 함수로 이루어짐 -> 가상 함수 호출의 비용이 존재 (vptr -> 함수 호출)// ---- Person.h ---- class Person { public: virtual ~Person(); virtual std::string name() const = 0; virtual std::string birthDate() const = 0; virtual std::string address() const = 0; static std::tr1::shared_ptr<Person> create(const std::string& name, const Date& birthday, const Address& addr); // ... } // ---- Person.cpp ---- // 인터페이스 클래스 Person을 상속한 RealPerson 클래스 class RealPerson : public Person { public: RealPerson(...); virtual ~RealPerson(); virtual std::string name() const override {...}; virtual std::string birthDate() const override {...}; virtual std::string address() const {...}; // ... private : std::string theName; Date therBirthDate; Address theAddress; } std::tr1::shared_ptr<Person> create(const std::string& name, const Date& birthday, const Address& addr) { return std::tr1::shared_ptr<Person>(new RealPerson(...)); } // 사용자는 이렇게 사용하면 된다. std::tr1::shared_ptr<Person> pp(Person::create(name, dateofBirth,address)); // ...- (2-2) 다중 상속을 통한 활용 (항목 40 예정)[Ch 6. 상속, 그리고 객체 지향 설계]
[항목 32]
◎ public 상속 모형은 반드시 "is-a" (..는 ...의 일종이다)를 따르도록 만들자.
✨public 상속은 "is-a (..는 ...의 일종이다)"를 의미한다. 잊지 말자.
-
Derived : public Base는 이런 의미를 갖는다.
- "Base(기본 클래스) 객체가 쓰이는 곳이라면 어디든 Derived(파생 클래스) 객체를 갖다 놓아도 아무 문제 없이 완벽하게 동작해야 한다."
- Derived는 Base이다 / 하지만 Base는 Derived가 아니다
- "Base(기본 클래스) 객체가 쓰이는 곳이라면 어디든 Derived(파생 클래스) 객체를 갖다 놓아도 아무 문제 없이 완벽하게 동작해야 한다."
-
Base의 모든 상태와 동작은 Derived에서도 유효하게 적용되어야한다.
class Bird { // ... } class FlyingBird : public Bird { public : virtual void fly(); // ... } class Penguin : public Bird { /// } int main() { Penguin p; // 항목 18의 내용과 같이 사용자의 실수를 명확히 알 수 있도록 // 컴파일 타임에 에러를 뱉는 것이 좋은 설계 p.fly(); // 컴파일 에러! } // ----- 문법적 하자는 없지만 논리적으로 설계가 잘못된 상태 ----- class Rect { public : virtual void SetHeight(int newHeight); virtual void SetWidth(int newWidth); virtual int height() const; virtual int width() const; } // 직사각형의 가로만 늘리는 형태 // 정사각형이 들어간다면 정사각형은 정사각형이 아니게 된다. void makeBigger(Rect& r) { int oldHeight = r.height(); r.setHeight(r.width() + 10); assert(r.height() == oldHeight); } class Square : public Rect{...} main() { Square s; assert(s.width() == s.height()); makeBigger(s); assert(s.width() == s.height()); }[항목 33]
◎ 상속된 이름을 숨기는 일은 피하자.
멤버 함수 이름 탐색
