Type
자바스크립트의 타입은 자료형으로 해석되기도 한다. 타입은 단순한 데이터를 저장하는 원시타입, 객체로 저장되는 참조타입으로 구분된다.
원시타입
값이 변경 불가능하며 값을 변수에 저장하거나 전달할 때 값에 의한 전달을 한다. 따라서 원시 값을 다른 변수에 할당할 때에는 값의 참조가 저장되는 것이 아닌, 값 자체가(실제 메모리에 저장된 주소) 복사되어 저장된다.
let str1 = 'hello';
let str2 = str1;
console.log(str2); // 'hello'
str1 = 'world';
console.log(str2); // str2에 할당된 값은 여전히 'hello' 입니다.위의 코드를 보면 str1의 값은 변했지만 str1을 복사했던 str2의 값은 변하지 않았다!
이러한 원시 타입에는 string, number, bigint, boolean, undefined, symbol, null이 속한다. 원시타입은 str2의 입장에서 str1의 값을 바꿀 수 없지만 참조타입은 str2입장에서 str1의 값을 바꿀 수 있다.
객체타입
-
객체는 프로퍼티(데이터 멤버인 필드와 메서드 간 기능의 중간인 클래스 멤버의 특수한 유형)로 값과 메서드를 가지며 이 둘은 각각 객체의 상태와 동작을 나타낸다.
-
값을 변수에 저장할 때 데이터 멤버가 너무 많아 값의 위치(주소)가 저장된다. 따라서 객체 값을 다른 변수에 할당 할때는 값의 참조(주소)만 저장된다. 그러므로 하나의 객체의 원소를 바꾸면 복사했던 다른 객체의 원소도 바뀐다.
// 객체타입
let arr1 = [1, 2, 3];
let arr2 = arr1;
console.log(arr2); // [1, 2, 3]
arr1[0] = 10;
console.log(arr2); // [10, 2, 3]
// 비교해보세요. (원시타입)
let value1 = 10;
let value2 = value1;
console.log(value2); // 10
value1 = 20;
console.log(value2); // 10배열
파이썬의 리스트를 생각하면 된다. 약간씩만 다른데 그 부분을 살펴보자.
배열 생성
const arr = [];
const arr = [1, 2, 3];
const arr2 = new Array(4, 5, 6); // [4, 5, 6]
const arr2 = new Array(3); // [비어 있음 x 3]자바스크립트의 배열은 특별한 점이 있는데 존재하지 않는 원소에도 접근이 가능하다.
const arr = [1, 2, 3];
// 배열 안의 원소에 접근하기 위해서는 인덱스 번호를 이용합니다.
console.log(arr[0]); // 1
console.log(arr[1]); // 2
console.log(arr[2]); // 3
console.log(arr[3]); // undefined정의되지 않았다고 나온다.
파이썬의 len()과 같은 length프로퍼티가 있다.
const myArray = [1, 2, 3, 4, 5];
console.log(myArray.length); // 5배열의 메서드
push와 pop
push 메서드는 파이썬의 append와 비슷하지만 요소를 추가하고 길이를 반환한다는 차이점이 있다. pop은 같다.
const arr = [1, 2, 3];
arr.push(4);
console.log(arr); // [1, 2, 3, 4]
arr.pop();
console.log(arr); // [1, 2, 3]shift와 unshift
shift는 파이썬의 popleft()와 같다. unshift는 appendleft()와 같다.
const myArray = ["사과", "바나나", "수박"];
myArray.shift();
console.log(myArray);
myArray.unshift("오이", "배");
console.log(myArray);splice
splice 메서드는 배열에 요소를 추가, 제거 또는 교체를 한번에 할 수 있다.
// splice(삭제나 추가를 시작할 메서드, 삭제할 요소 개수, 추가할 요소들)
const arr = [1, 2, 3];
arr.splice(1, 0, 4);
console.log(arr); // [1, 4, 2, 3]
arr.splice(2, 1, 5);
console.log(arr); // [1, 4, 5, 3]slice
배열에서 요소들을 추출하여 새로운 배열로 반환하는 메서드이다.
// slice(추출을 시작할 인덱스, 추출을 끝낼 인덱스)
// 추출을 끝낼 인덱스-1까지 추출한다.
const myArray = ["apple", "banana", "cherry", "durian", "elderberry"];
console.log(myArray.slice(1, 4));
console.log(myArray.slice());
console.log(myArray.slice(0, 10));
두 번째 인덱스를 생략하거나 배열의 길이보다 더 큰 값을 전달하면 배열 끝까지 추출한다.
sort
파이썬과 동일하다.
const avengers = ['아이언맨', '스파이더맨', '헐크', '토르'];
console.log(avengers.sort());
숫자끼리 정렬하면 특이한 모습을 보인다.
const nums = [3, 1, 8, 6];
console.log(nums.sort()); // [1, 3, 6, 8]
const nums2 = [23, 5, 1000, 42];
console.log(nums2.sort()); 
위와 같은 결과가 나오는 이유는 원소를 문자열로 전환한 후에 유니코드 순서대로 변환하기 때문이다. (앞자리끼리 비교한다고 생각하면 편함)
숫자형 데이터 정렬을 원래 의도대로 하기 위해 비교 함수를 사용한다.
const num3 = [13, 9, 10];
num3.sort(function (a, b) {
console.log('a: ' + a, 'b: ' + b);
return a - b;
});
/**
"a: 9"
"b: 13" // a - b는 음수임으로 a를 앞으로 => [9, 13, 10]
"a: 10"
"b: 9" // a - b는 양수임으로 b를 앞으로 => [9, 13, 10]
"a: 10"
"b: 13" // a - b는 음수임으로 a를 앞으로 => [9, 10, 13]
"a: 10"
"b: 9" // a - b 는 양수임으로 b를 앞으로 => [9, 10, 13]
*/forEach
배열의 각 요소에 대해 주어진 함수를 실행한다. 이 함수는 인자로 배열요소, 인덱스를 받는다. 인덱스를 사용하지 않는다면 생략해도 된다.
const arr = ['참외', '키위', '감귤'];
arr.forEach(function(item, index) {
console.log(item, index);
arr[index] = index;
});
// 결과
// 참외 0
// 키위 1
// 감귤 2이러한 메서드는 배열의 각 요소를 이용하여 다른 배열을 만들거나, 요소를 삭제하거나, 값을 변경하는 등의 작업을 수행할 수 있다.
const avengers = ['spiderman', 'ironman', 'hulk', 'thor'];
const newAvengers = [];
avengers.forEach(function (item) {
newAvengers.push('💖' + item + '💖');
});
map
배열의 각 요소에 대해 주어진 함수를 실행하고, 그 결과를 새로운 배열로 반환한다. 첫 번째 인자로는 각 요소를 처리할 함수를, 두 번째는 요소의 인덱스를 전달한다.
const arr = [1, 2, 3];
const newArr = arr.map(function(item, index) {
return item * index;
});
console.log(newArr);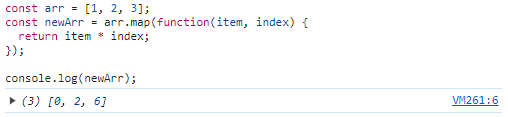
forEach 메서드와 map 메서드는 비슷한 것 같지만 forEach는 반환값이 없고 map 메서드는 새로운 배열을 반환한다는 차이점이 있다!
filter
기존의 배열에서 특정 조건을 만족하는 요소들만 추출(필터링)하여 새로운 배열을 만든다.
const arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
const newArr = arr.filter(function(el) {
return el % 2 === 0;
});
console.log(newArr);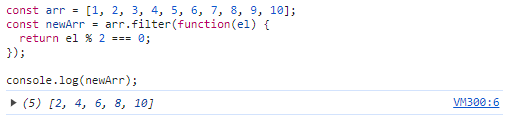
includes
해당 요소가 포함이 되어 있으면 true, 아니면 false를 반환한다.
const arr1 = ['hello', 'world', 'hojun']
arr1.includes('world')
const arr1 = ['hello', 'world', 'hojun']
arr1.includes('leehojun')
const arr1 = ['hello', 'world', 'hojun']
arr1.includes('jun')
객체
딕셔너리와 같은 형태라고 생각하면 편하다. 아래와 같은 형식으로 babaYaga 객체를 생성하고 이러한 키+값 쌍을 합쳐서 자산(properties)이라 표현한다. 프로퍼티 값이 함수면 메소드라고 부른다.
const babaYaga = {
name: "John Wick",
age: 53,
from: "벨라루스",
askingHim: function(){
console.log("Yeah, I'm thinking I'm back!");
}
};객체 속성에 접근하기
객체 이름 + 점 연산자 + 접근하고자 하는 값의 key를 입력해서 접근할 수 있다. 대괄호로도 접근이 가능하다.
console.log(`${babaYaga.name} from ${babaYaga.from}`);
console.log(`${babaYaga['name']} from ${babaYaga['from']}`);여기서 $표시는 파이썬의 f-string 문법과 비슷하다고 생각하면 될 것 같다. 차이점은 백틱 표시가 양 끝에 붙는다는 것이 되겠다.
객체에 속성 추가하기
파이썬에서 객체에 인스턴스 추가하는 것과 같다고 보면 된다.
babaYaga.job = "Killer";객체의 속성 삭제하기
delete babaYaga.job;특정 프로퍼티 존재 여부 확인
console.log('age' in babaYaga);
console.log('mercy' in babaYaga);객체의 메서드
hasOwnProperty()
객체가 특정 프로퍼티를 가지고 있는지를 나타내는 불리언 값을 반환한다. 위에서 본 in과 같은 결과를 나타낸다.
const aespa = {
members: ['카리나', '윈터', '지젤', '닝닝'],
from: '광야',
sing: function(){
return "적대적인 고난과 슬픔은 널 더 popping 진화시켜!"
}
};
console.log(aespa.hasOwnProperty('itzy'));
console.log(aespa.hasOwnProperty('from'));for ... in
객체 안의 프로퍼티들에 접근하여 어떤 키와 값을 가지는지 살펴보거나, 조건에 따라 값을 수정할 때 사용한다.
for (const variable in object) {
// ...
}여기서 주의할 점은 for문에서 처리되는 프로퍼티는 반드시 순서대로 반복되지 않는다는 것이다. 순서가 중요하면 일반적인 반복문을 사용하자.
keys(), values()
파이썬 딕셔너리와 같다고 보면 된다. 차이점은 object라는 객체가 붙는데 개발자들이 편하게 사용하도록 내장된 객체이다.
console.log(Object.keys(aespa));
console.log(Object.values(aespa));참고사항
수강생 중 은선님이 공유해주신 자바스크립트 문법 테스트 사이트이다. 흥미로워서 공유해 본다.
https://jsisweird.com/
피드백
파이썬과 유사한 점이 있기에 금방금방 지나가는 중이다. 뭔가 조금씩 미묘하게 달라서 어려운 것 같은데 보다보면 괜찮은 것 같고 그렇다. 이것도 깊게 파면 어려울 것 같은데 일단은 백엔드를 목표로 하기에 이런게 있다~ 정도로만 보고 넘어가겠다.
