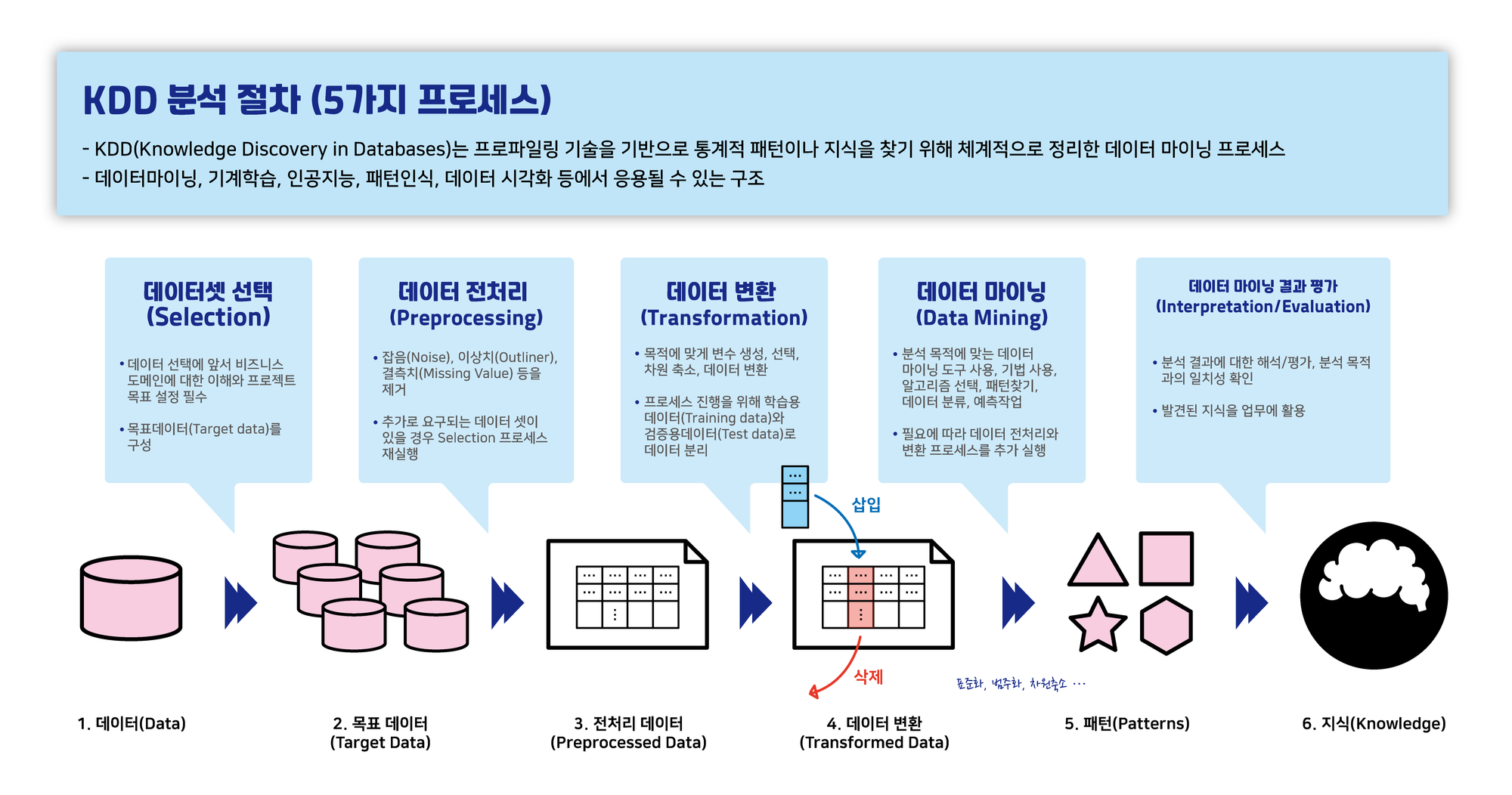
SELECT, FROM
select 문을 이용해 DB에 있는 데이터를 조회할 수 있다.
숫자나 계산식, 문자열등을 출력할 수도 있다.
select 1+1;
--문자열은 더하기가 안됩니다.
select 'hello'+'world';
select 'hello', 'world';
select * from `thelook_ecommerce.users`;
select id, first_name, last_name from `thelook_ecommerce.users`;*를 사용하면 해당 테이블의 모든 데이터를 가져올 수 있다.
from 뒤에는 가져올 테이블 명이 들어간다.
AS, LIMIT, DISTINCT
AS
해당 칼럼의 별칭을 정하여 그 별칭으로 보여주는 기능이다. 주로 식으로 된 칼럼등을 간결하게, 가독성 있게 표현할 때 사용한다.
select name as product_name
from `thelook_ecommerce.products`;name 칼럼의 이름을 가독성 좋게 product_name으로 설정하였다.
테이블 이름에도 사용할 수 있다.
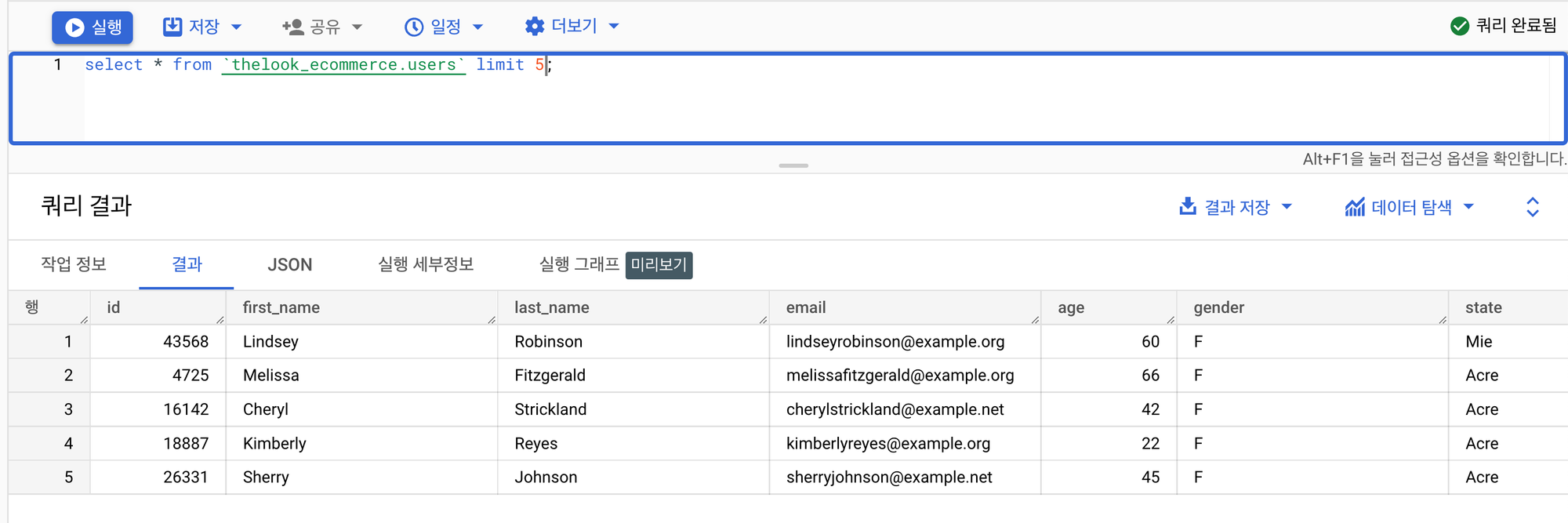
LIMIT
조회할 결과의 수를 제한한다.
select * from `thelook_ecommerce.users` limit 5;해당 코드는 5개의 행(튜플)만 출력하도록 하고 있다.
DISTINCT
결과에서 중복되는 행을 제거한다.
WHERE, 다양한 연산자
데이터에 조건을 부여하여 원하는 데이터만 필터링한다. 여러 연산자를 사용할 수 있다.
WHERE, 비교연산자
SELECT *
FROM `thelook_ecommerce.users`
WHERE first_name = 'Michael';파이썬의 if문과 비슷한 느낌이다.
비교 연산자의 경우에도 비슷한데 같음(=)이랑 같지 않음(<>)이라는 표현이 있다는 것만 차이점이라 볼 수 있겠다.
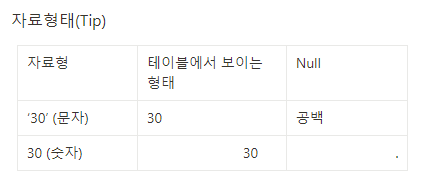
참고
테이블에서 문자와 숫자의 시각화 형태는 다르다.
논리연산자
AND, OR, NOT 구문을 사용할 수 있다.
SQL 연산자
SQL에만 있는 특이한 연산자에 대해 다뤄보겠다.
between A and B: A와 B를 포함한 사이의 값이며, 날짜의 경우에는 B의 값이 미만으로 들어간다는 것을 유의해두자.
-- 1월 가입 유저
select *
from thelook_ecommerce.users
where created_at between '2020-01-01' and '2020-02-01'IN A: A안의 값과 일치하는 값을 조회
select *
from `thelook_ecommerce.products`
where brand in ('Onia', 'Hurley', 'Matix');LIKE(비교문자) : 비교 문자와 형태가 일치하는 레코드를 조회한다. 대소문자를 가리지 않으며%를 사용한다.
select *
from `thelook_ecommerce.products`
where name like '%Young%';위 코드는 Young이라는 문자열이 포함된 레코드를 조회한다.
select *
from `thelook_ecommerce.products`
where name like 'Hurley%';위 코드는 Hurley로 시작하는 레코드를 조회하며, %가 뒤에 있으면 해당 단어로 끝나는 레코드를 조회한다.
IS NULL
NULL인 값을 찾는다. 0은 해당되지 않는다.
select *
from `thelook_ecommerce.order_items`
where shipped_at IS NULL;
-- 값이 없는 것들만 출력데이터 집계함수, GROUP BY
집계함수
여러 행으로부터 하나의 결과값을 반환하는 함수이다. 다음과 같은 경우에서 각 지역별로 10월에 방문한 방문자수의 합을 계산할 때 사용한다.
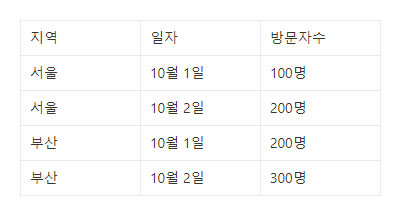
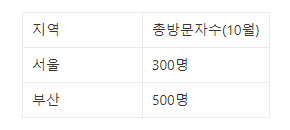
COUNT: 해당 항목 레코드의 개수를 반환SUM: 해당 항목 레코드의 합계 반환AVG: 해당 항목 레코드의 평균 반환MIN / MAX: 해당 항목 레코드의 최소 / 최대 반환VARIANCE: 분산 반환STDDEV: 표준편차 반환
GROUP BY
특정 항목을 기준으로 그룹화하여 조회할 수 있다. 그룹화 하려는 항목이 반드시 select에 들어가야 한다.
select category, avg(cost)
from `thelook_ecommerce.products`
group by category;그룹화할 항목을 선택한 후, 해당 항목을 select문의 처음 부분에 넣고 조회하려는 항목을 그 뒤에 둔다.
HAVING, ORDER BY
HAVING
GROUP BY로 묶여진 데이터에 조건을 부여할 때 사용한다.
select
country, #2. 그룹 계산할 값을 select 첫부분
count(id) as user_count #3. 그룹 계산할 실제 컬럼
from `thelook_ecommerce.users`
group by country #1. 그룹 계산할 값
having count(id) >= 4000; #4. 그룹 계산된 것 중에서 조건을 걸때ORDER BY
출력 결과를 정렬할 때 사용한다. 기본값은 오름차순(ASC)이며, DESC(내림차순)로 내림차순 정렬도 가능하다.
select *
from `thelook_ecommerce.users`
order by age asc;SQL 쿼리 작성(생각) 순서
모두가 이런식으로 작성하는 것은 아니지만 다음 순서로 생각하면 좋다.
- from → 테이블 선정!
- where → 조건!
- group by → 집계(o) → 나라 / 성별
- having → 집계된 내용 어떻게 더 조건! (group by 계산된 식에 대한 추가조건)
- select
- order by
- limit
필요없는 내용은 지우면서 진행하면 쉽게 작성할 수 있다.
