두 개 이상의 테이블에서 데이터를 결합하여 결과를 반환하는데 사용한다.
JOIN 을 적절히 사용하면 더 많은 정보를 얻을 수 있고, 데이터를 검색하는 시간을 줄일 수 있다.
JOIN의 여러 종류
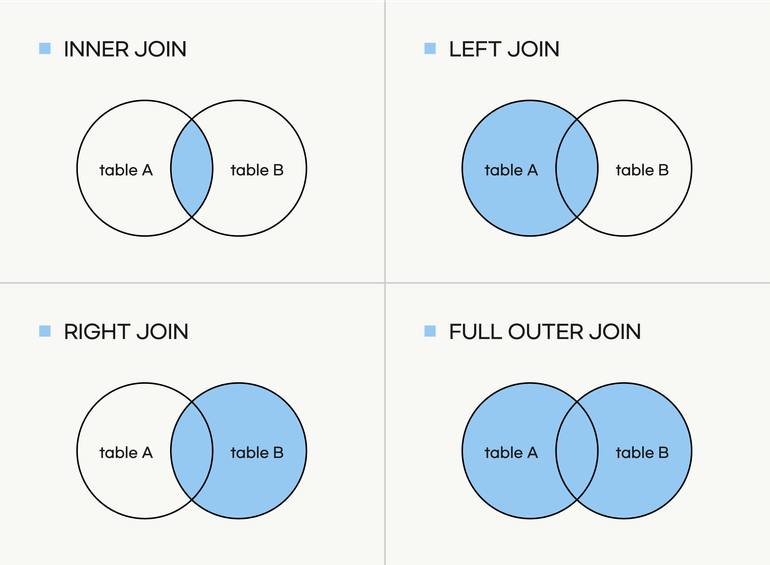
그림을 보면서 공부하면 조금 더 쉽게 와닿을 것이다. 쉬운 이해를 위해 두 테이블을 JOIN 하는 경우만 다루겠다.
INNER JOIN
두 테이블 모두에서 일치하는 값이 있는 행을 반환한다. JOIN의 기본값이다.
- 기본 형태
select table1.id, table2.id
from table1
[inner] join table2
on table2.id=table1.id특정 칼럼을 기준으로 일치하는 값이 있는 행만 반환하고 나머지는 무시된다.
on은 각 테이블을 합칠 기준이 되는 칼럼을 정해준다. 보통 공통 칼럼(필드)을 기반으로 한다.
다음과 같이 테이블 이름을 별칭으로 두어 쉽게 선언하게 할수도 있다.
select
o.order_id,
o.product_id,
p.name,
o.created_at
from `weniv.weniv_order` as o
join `weniv.weniv_product` as p
on o.product_id = p.id
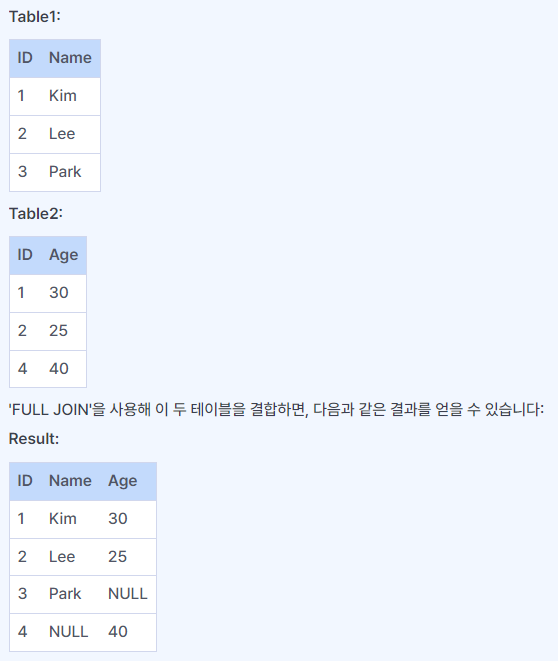
ID가 3인 Park와 ID가 4인 행은 결과에서 제외되었다. Park은 Table2에 없으며, ID가 4인 행은 Table1에 없기 때문이다.
LEFT JOIN
왼쪽 테이블(기본 테이블)의 모든 레코드와 해당하는 오른쪽 테이블의 레코드를 합하여 반환한다. 일치하는 행이 없으면 NULL이 두 번째 테이블의 값으로 반환된다.

ID가 3인 Park의 나이는 Table2에 없기 때문에 결과에서 Age는 NULL로 표시한다.
RIGHT JOIN
오른쪽 테이블(두 번째 테이블)의 모든 레코드와 그에 해당하는 왼쪽 테이블(첫 번째 테이블)의 레코드를 반환한다. 만약 왼쪽 테이블에 일치하는 레코드가 없다면, 해당 결과는 NULL 값을 가진다.

그림에서는 두 번째 테이블에 4라는 ID가 있지만 첫 번째 테이블에는 없기에 NULL로 나온다.
FULL JOIN
두 테이블의 모든 레코드를 결합하여 반환한다. 왼쪽 테이블과 오른쪽 테이블의 합집합을 반환하는 것과 같다.
CROSS JOIN
두 테이블의 모든 가능한 조합을 반환한다. ON 키워드를 활용한 조건을 지정하지 않는다는 특징이 있다.
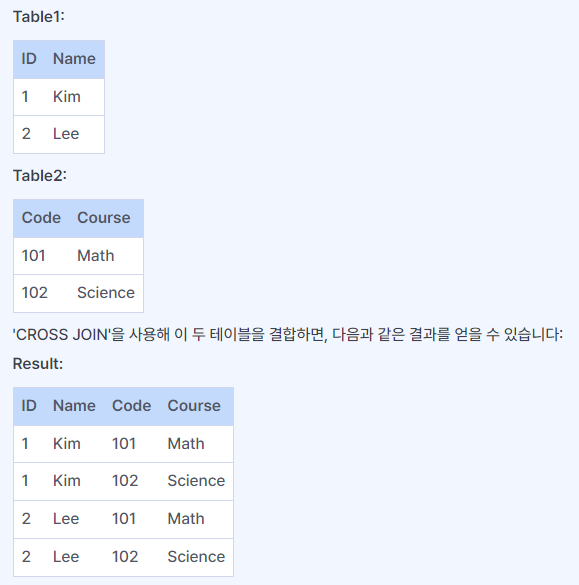
일반적으로 두 테이블 간에 관계가 없는 경우나, 모든 가능한 조합을 생성해야 하는 특정 상황에서 사용한다.
결과의 레코드 수가 빠르게 증가할 수 있으므로 주의가 필요하다.
