
Overview
Anomaly Detection의 4가지 분류
Reconstruction/Classification/Feature matching/Probilistic
Reconstruciton 중 autoencoder를 활용한 code를 review하고자 함.
Unsupervised learning
vgg19 사전학습 모델 기반 autoencoder 구성.
하나의 class에 대해 정상 img data만으로 autoencoder를 학습하고, 이상치가 존재하는 test set에서 이상 유무 판단과 이상 판단 부분 탐지 수행.
Source
- (논문) DFR: Deep Feature Reconstruction for Unsupervised Anomaly Segmentation
- (Github) github/YoungGod/DFR
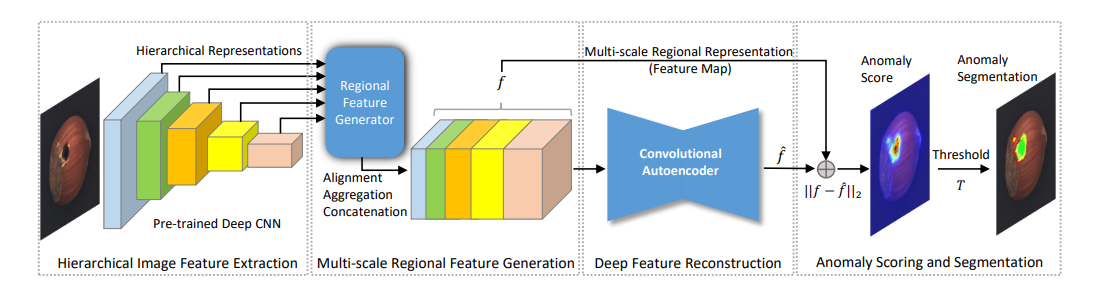
DFR code
1. Hierarchical Feature Extraction with Pretrained VGG19
torchvision.models.vgg19.features: 사전 학습 모델을 불러오는 subpackage, attribute로 features 입력 시, 아래와 같이 Feature Sequential 반환
nn.ReflectionPad2d(padding): input tensor를 padding할 때, tensor point를 중심으로 경계를 반사해서 값을 채움
Receptive field: 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기 > 층을 지날수록 출력은 압축되고, kernel은 그대로기에 Receptive field는 증가
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(33): ReLU(inplace=True)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace=True)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)## 계층 이미지 특성을 뽑아내기 위한 사전학습 가중치 구성
## imagenet으로 사전학습한 vgg19 model의 가중치 base로 image를 입력받아 각 단계에서의 feature를 reluN_N으로 저장
## layers로 사용할 feature를 선택해 해당 단계까지의 계산된 tensor를 반환
class vgg19(torch.nn.Module):
def __init__(self):
super(vgg19, self).__init__()
vgg = torchvision.models.vgg19(pretrained = True)
features = vgg.features
# 각 층에 해당하는 가중치를 import
self.conv1_1 = features[0]
self.relu1_1 = features[1]
self.conv1_2 = features[2]
self.relu1_2 = features[3]
self.pool1 = features[4]
self.conv2_1 = features[5]
self.relu2_1 = features[6]
self.conv2_2 = features[7]
self.relu2_2 = features[8]
self.pool2 = features[9]
self.conv3_1 = features[10]
self.relu3_1 = features[11]
self.conv3_2 = features[12]
self.relu3_2 = features[13]
self.conv3_3 = features[14]
self.relu3_3 = features[15]
self.conv3_4 = features[16]
self.relu3_4 = features[17]
self.pool3 = features[18]
self.conv4_1 = features[19]
self.relu4_1 = features[20]
self.conv4_2 = features[21]
self.relu4_2 = features[22]
self.conv4_3 = features[23]
self.relu4_3 = features[24]
self.conv4_4 = features[25]
self.relu4_4 = features[26]
self.pool4 = features[27]
self.conv5_1 = features[28]
self.relu5_1 = features[29]
self.conv5_2 = features[30]
self.relu5_2 = features[31]
self.conv5_3 = features[32]
self.relu5_3 = features[33]
self.conv5_4 = features[34]
self.relu5_4 = features[35]
self.pool5 = features[36]
self.pad = nn.ReflectionPad2d(padding=1)
# edge effects 완화를 위한 reflection padding 사용
def forward(self, x, layers):
# 층을 지나면서 층에 상응하는 receptive field size는 증가
x = self.pad(x)
conv1_1 = self.conv1_1(x)
relu1_1 = self.pad(self.relu1_1(conv1_1))
conv1_2 = self.conv1_2(relu1_1)
relu1_2 = self.relu1_2(conv1_2)
pool1 = self.pool1(relu1_2)
pool1 = self.pad(pool1)
conv2_1 = self.conv2_1(pool1)
relu2_1 = self.pad(self.relu2_1(conv2_1))
conv2_2 = self.conv2_2(relu2_1)
relu2_2 = self.relu2_2(conv2_2)
pool2 = self.pool2(relu2_2)
pool2 = self.pad(pool2)
conv3_1 = self.conv3_1(pool2)
relu3_1 = self.pad(self.relu3_1(conv3_1))
conv3_2 = self.conv3_2(relu3_1)
relu3_2 = self.pad(self.relu3_2(conv3_2))
conv3_3 = self.conv3_3(relu3_2)
relu3_3 = self.pad(self.relu3_3(conv3_3))
conv3_4 = self.conv3_4(relu3_3)
relu3_4 = self.relu3_4(conv3_4)
pool3 = self.pool3(relu3_4)
pool3 = self.pad(pool3)
conv4_1 = self.conv4_1(pool3)
relu4_1 = self.pad(self.relu4_1(conv4_1))
conv4_2 = self.conv4_2(relu4_1)
relu4_2 = self.pad(self.relu4_2(conv4_2))
conv4_3 = self.conv4_3(relu4_2)
relu4_3 = self.pad(self.relu4_3(conv4_3))
conv4_4 = self.conv4_4(relu4_3)
relu4_4 = self.relu4_4(conv4_4)
pool4 = self.pool4(relu4_4)
pool4 = self.pad(pool4)
conv5_1 = self.conv5_1(pool4)
relu5_1 = self.pad(self.relu5_1(conv5_1))
conv5_2 = self.conv5_2(relu5_1)
relu5_2 = self.pad(self.relu5_2(conv5_2))
conv5_3 = self.conv5_3(relu5_2)
relu5_3 = self.pad(self.relu5_3(conv5_3))
conv5_4 = self.conv5_4(relu5_3)
relu5_4 = self.relu5_4(conv5_4)
out = {
'relu1_1': relu1_1,
'relu1_2': relu1_2,
'relu2_1': relu2_1,
'relu2_2': relu2_2,
'relu3_1': relu3_1,
'relu3_2': relu3_2,
'relu3_3': relu3_3,
'relu3_4': relu3_4,
'relu4_1': relu4_1,
'relu4_2': relu4_2,
'relu4_3': relu4_3,
'relu4_4': relu4_4,
'relu5_1': relu5_1,
'relu5_2': relu5_2,
'relu5_3': relu5_3,
'relu5_4': relu5_4,
}
# dict format으로, choice_feature으로 str를 받아서 해당 layer까지의 계산을 산출
return dict((key, value) for key, value in out.items() if key in layers)2. Multi-Regional Feature Generator
torch.nn.functional.interpolate(input,size,mode,align_corners): 원하는 size로 변환하기 위해서 down/up sampling
input- input tensor
size- output size(new_h, new_w)
mode- sampling mode('nearest','linear','bicubic','trillinear','area')
nearest: 주변 값 사용/ linear, cubic: regression
align_corners- output edge를 input과 맞출 것인지, segmentation시 True가 높은 성능
torch.unbind(input, dim): tensor dimension을 삭제, 해당 dim을 삭제한 여러개의 tensor 집합인 tuple을 반환
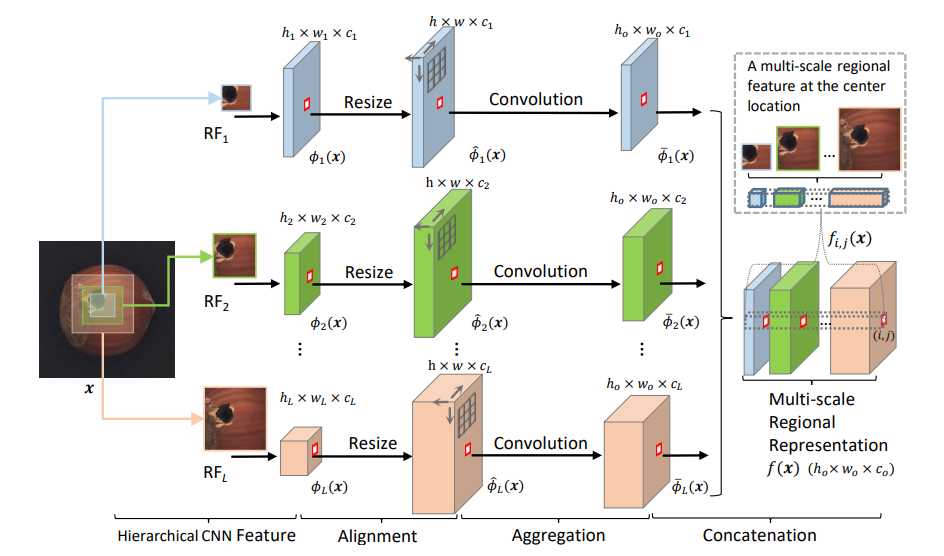
Multi-region 특성을 반영하기 위해서 여러 깊이의 층을 사용.
이는 층의 깊이의 정도가 클수록 receptive field가 커지는 것을 활용한 것.
여러 깊이의 feture를 하나의 층으로 합쳐 반영할 수 있는 region을 최대화하는 step
## 계층 이미지 특성 생성
## 선택한 layers에 해당하는 가중치로 계산한 값을 하나로 합침
class multi_regional_feature(nn.Module):
def __init__(self, map_size = (224,224), device = 'cuda',
kernelsize = (4,4), stride = (4,4), layers = ('relu1_1', 'relu2_1',
'relu3_1', 'relu3_3', 'relu4_1')):
super(multi_regional_feature, self).__init__()
self.mapsize = map_size
self.device = torch.device(device)
self.kernel_size = kernelsize
self.stride = stride
self.layers = layers
def forward(self, input):
vgg = vgg19().to(self.device)
feat_maps = vgg(input, self.layers)
multi_features = torch.Tensor().to(self.device)
# feat_maps에는 self.layers에 해당하는 사전학습 가중치 존재
for _, feat_map in feat_maps.items():
feat_map = nn.functional.interpolate(feat_map, size=(224,224),mode='bilinear',align_corners=True)
# 압축된 size 통합하기 위해 upsampling으로 size 통일
mean_filter = torch.nn.AvgPool2d((4,4), stride=(4,4))
# 평균 필터 (224,224) > (64,64)
feat_map = mean_filter(feat_map)
multi_features = torch.cat([multi_features, feat_map], dim=1)
# channel 기준으로 계층 feature 통합
return multi_features
# [Batch, Channel_total, 64, 64]
## latent_dim를 구하기 위해 pca에 사용할 2차원 vector 구성
def pca_vec(self, input):
vgg = vgg19()
feat_maps = vgg(input, ('relu1_1', 'relu2_1',
'relu3_1', 'relu3_3', 'relu4_1'))
multi_features = torch.Tensor().to(self.device)
for _, feat_map in feat_maps.items():
feat_map = nn.functional.interpolate(feat_map, size=(224,224),mode='bilinear',align_corners=True)
mean_filter = torch.nn.AvgPool2d((4,4), stride=(4,4))
feat_map = mean_filter(feat_map)
multi_features = torch.cat([multi_features, feat_map], dim=1)
# 여기까지는 계층 feature 구성과 동일
# [Batch, Channel_total, 64, 64]
features = torch.unbind(multi_features, dim=3)
# 64개의 tuple [Batch, Channel_total, 64]
features = torch.cat(features, dim=2)
# [Batch, Channel_total, 64*64]
features = features.permute(0,2,1)
# [Batch, 64*64, Channel_total]
features = torch.unbind(features, dim=0)
# Batch개의 tuple [64*64, Channel_total]
features = torch.cat(features, dim=0)
# [64*64*Batch, Channel_total]
# Channel_total을 줄이고자 pca input 준비
return features3. Deep Feature Reconstruction with Autoencoder

## 저차원 latent space로 압축했다가 재구성해 정상 image 학습
## loss function: 입력 image와 재구성 image 차의 평균 사용
class CAE(nn.Module):
def __init__(self, in_channels=1500, latent_dim=50):
# 90% 분산을 유지하는 latent_dim를 pca를 통해 계산해 입력
super(CAE, self).__init__()
layers = []
layers += [nn.Conv2d(in_channels, (in_channels + 2*latent_dim) // 2, kernel_size=1, stride=1, padding=0)]
layers += [nn.BatchNorm2d(num_features = (in_channels + 2* latent_dim) // 2)]
layers += [nn.ReLU()]
layers += [nn.Conv2d((in_channels + 2*latent_dim) // 2, 2*latent_dim, kernel_size=1, stride=1, padding=0)]
layers += [nn.BatchNorm2d(num_features = 2* latent_dim)]
layers += [nn.ReLU()]
layers += [nn.Conv2d(2*latent_dim, latent_dim, kernel_size=1, stride=1, padding=0)]
self.encoder = nn.Sequential(*layers)
layers = []
layers += [nn.Conv2d(latent_dim, 2*latent_dim, kernel_size=1, stride=1, padding=0)]
layers += [nn.BatchNorm2d(num_features = 2*latent_dim)]
layers += [nn.ReLU()]
layers += [nn.Conv2d(2*latent_dim, (in_channels + 2*latent_dim) // 2, kernel_size=1, stride=1, padding=0)]
layers += [nn.BatchNorm2d(num_features = (in_channels + 2*latent_dim) // 2)]
layers += [nn.ReLU()]
layers += [nn.Conv2d((in_channels + 2*latent_dim) // 2, in_channels, kernel_size=1, stride=1, padding=0)]
self.decoder = nn.Sequential(*layers)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
def loss_function(self, x, x_hat):
loss = torch.mean((x - x_hat)**2)
return loss
def compute_score(self, x, x_hat):
loss = torch.mean((x - x_hat)**2, dim=1)
return loss4. Anomaly Scoring & Segmentation
class Anoseg():
def __init__(self):
super(Anoseg, self).__init__()
self.device = torch.device('cuda')
self.feature_extractor = multi_regional_feature(
map_size = (224,224), device = 'cuda',
kernelsize = (4,4), stride = (4,4),
layers = ('relu1_1', 'relu2_1',
'relu3_1', 'relu3_3', 'relu4_1')
).to(self.device)
self.train_data = self.build_dataset('train')
# self.valid_data = self.build_dataset('valid')
self.test_data = self.build_dataset('test')
self.autoencoder = CAE(in_channels=1216, latent_dim=50).to(self.device)
# self.autoencoder = self.build_encoder()
self.thred = 2.472419500350952
self.optimizer = optim.Adam(self.autoencoder.parameters())
## latent_space를 결정할 n_dim 계산
## 분산 90%를 만족하는 components 출력해 이를 바탕으로 autoencoder 생성
def build_encoder(self):
multi_features = torch.Tensor()
for train_img in self.train_data:
train_img = train_img.to(self.device)
feature = self.feature_extractor.pca_vec(train_img)
multi_features = torch.cat([multi_features, feature], dim=0)
channel = multi_features.shape[1]
pca = PCA(n_components = 0.90)
pca.fit(multi_features)
n_dim, input_feature = pca.components_.shape
# pca.components_.shape > ndarray of shape (n_components, n_features)
ae = CAE(in_channels= channel, latent_dim=n_dim)
return ae
def build_dataset(self, mode):
type = 'screw'
# 사물 종류 지정
# self.target_type
# fold = self.fold
train_val_png = sorted(glob('/content/'+ type +'/train/*/*.png'))
# 정상 이미지 경로를 정렬해서 받아놓음
'''folds =[]
kf = KFold(n_splits = 5, shuffle = True)
for train_idx, val_idx in kf.split(train_eval_png):
folds.append((train_idx, val_idx))
train_idx, val_idx = folds[self.fold]
'''
imgs = []
def img_load(img_path):
img = cv2.imread(img_path)[:,:,::-1].copy()
img = transforms.ToTensor()(img)
# 원본 img size > [3,900,900]
resize = transforms.Resize(size=(224, 224))
# img size > [3,224,224]
img = resize(img)
return img
for path in train_val_png:
imgs.append(img_load(path))
# imgs에 list로 image tensor를 받아놓음
# return len(imgs)
train_set, val_set = random_split(imgs,[100, len(imgs)-100])
# 100장의 정상 이미지로 훈련
train_dataloader = DataLoader(train_set, batch_size=2, shuffle=True, num_workers=2)
#valid_dataloader = DataLoader(val_set, batch_size=10, shuffle=False)
if mode == 'train':
return train_dataloader
#if mode == 'valid':
# return valid_dataloader
if mode == 'test':
# 이상 이미지 + 정상 이미지 set
test_png = sorted(glob('/content/'+ type +'/test/*/*.png'))
imgs = []
labels = []
imgs_labels = []
for path in test_png:
imgs.append(img_load(path))
labels.append(path.split('/')[-2])
#imgs_labels.append([imgs,labels])
test_dataloader = DataLoader(imgs, batch_size=1, shuffle=False)
return test_dataloader
## 학습한 모델가지고 원본 이미지와 재구성 이미지 차를 score로 지정
## score를 바탕으로 이상치를 구분할 threshold 계산에 사용
def score(self, input):
# [1,3,224,224]
self.feature_extractor.eval()
self.autoencoder.eval()
inc_in = self.feature_extractor(input)
dec_out = self.autoencoder(inc_in)
# [1,Channel_total,56,56]
scores = self.autoencoder.compute_score(dec_out, inc_in)
# Channel 기준으로 평균해 놓은 tensor 차
# [1,1,56,56]
scores = scores.reshape((1,1,56,56))
scores = nn.functional.interpolate(scores, size=(224,224), mode="bilinear", align_corners=True).squeeze()
# [224,224]
# 이미지에 적용하기 위해 이미지 size와 동일하게 확장
return scores
## 정상 이미지를 가지고 False Positive Rate이 0.05가 되는 임계값을 threshold로 설정
def estimate_thred_with_fpr(self, expected_fpr=0.05):
threshold = 0
scores_list = []
for i, train_img in enumerate(self.train_data):
train_img = train_img[0:1].to(self.device)
# 이미지 한장으로 학습한 autoencoder에 넣어서 score 출력
scores_list.append(self.score(train_img).data.cpu().numpy())
# [224,224]
scores = np.concatenate(scores_list, axis=0)
# [len(train_data) * 224, 224]
max_step = 100
min_th = scores.min()
max_th = scores.max()
# one value
delta = (max_th - min_th) // max_step
for step in range(max_step):
threshold = max_th - step * delta
binary_score_map = np.zeros_like(scores)
binary_score_map[scores <= threshold] = 0
binary_score_map[scores > threshold] = 1
# 정상 이미지에서 threshold 이상인 pixel은 잘못 예측된 값
fpr = binary_score_map.sum() / binary_score_map.size
if fpr >= expected_fpr:
print(threshold)
return threshold
## test_set으로 binary_score mask 출력
def segment(self, input, threshold=0.5):
scores = self.score(input).data.cpu().numpy()
# [224,224]
binary_scores = np.zeros_like(scores)
binary_scores[scores <= threshold] = 0
binary_scores[scores > threshold] = 1
return binary_scores
## 훈련 step
def optimize_step(self, input):
self.feature_extractor.train()
self.autoencoder.train()
self.optimizer.zero_grad()
inc_in = self.feature_extractor(input)
dec_out = self.autoencoder(inc_in)
total_loss = self.autoencoder.loss_function(dec_out, inc_in)
total_loss.backward()
self.optimizer.step()
return total_loss
## 훈련 함수
def train(self):
epochs = 10
for epoch in range(1,epochs+1):
self.feature_extractor.train()
self.autoencoder.train()
losses = []
for i, train_img in enumerate(self.train_data):
train_img = train_img.to(self.device)
total_loss = self.optimize_step(train_img)
loss = {}
loss['total_loss'] = total_loss.data.item()
losses.append(loss['total_loss'])
print(losses)
## 이상치가 하나라도 존재하면(binary_score == 1) prediction 이상치로 판단
## subplots로 입력 img, masked img 시각화
def test_seg(self):
for i, img in enumerate(self.test_data):
img = img.to(self.device)
binary_score = self.segment(img, self.thred)
prediction = np.any(binary_score > 0)
img = img.to('cpu')
# cuda는 imshow 불가
img = torch.squeeze(img[0])
# Batch dimension 삭제
img = img.permute(1,2,0)
# (h, w, channel) format으로 전환해야 imshow 가능
f,axs = plt.subplots(1,2, figsize =(15,15))
axs[0].imshow(img)
axs[1].imshow(binary_score)
axs[1].imshow(img, alpha = 0.75)
plt.show()
print(prediction)5. Train & Execute
main = Anoseg()
main.train()
main.estimate_thred_with(0.05)
main.test_seg()Conclusion
train_data set으로 latent_dim를 계산하는 과정에서 4차원 tensor를 2차원으로 압축해 연산하는 과정이 RAM memory를 초과해 n_dim를 임의로 설정해 autoencoder를 구성.

