이번에는 Article Comment 엔티티에 인덱싱및 기타 작업을 진행한다.
@Getter
@ToString
@Table(indexes = {
@Index(columnList ="content"),
@Index(columnList ="createdAt"),
@Index(columnList ="createdBy")
})
@Entity
public class ArticleComment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Setter private Long id;
@Setter private @ManyToOne(optional = false) Article article; // 게시글 (ID)
@Setter @Column(nullable = false, length = 500 )private String content; // 본문
@CreatedDate @Column(nullable = false) private LocalDateTime createdAt; // 생성일시
@CreatedBy @Column(nullable = false, length = 100)private String createdBy; // 생성자
@LastModifiedDate @Column(nullable = false)private LocalDateTime modifiedAt; // 수정일시
@LastModifiedBy @Column(nullable=false, length = 100)private String modifiedBy; // 수정자
}
Article 엔티티와 거의 비슷하다. 댓글의 경우 게시글은 하나지만 댓글은 여러개 일수 있으므로 @ManyToOne 을 추가했다.
또한 생성자 생성과, 동등성 검사를 위한 equals, hascode또한 생성한다.
protected ArticleComment() {
}
private ArticleComment(Article article, String content) {
this.article = article;
this.content = content;
}
public static ArticleComment of(Article article, String content) {
return new ArticleComment(article,content);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof ArticleComment that)) return false;
return id != null && id.equals(that.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}애플리케이션 구동
main/java/ 안에서 애플리케이션을 실행시킨다.
drop table if exists article
Hibernate:
drop table if exists article_comment
Hibernate:
create table article (
id bigint not null auto_increment,
content varchar(10000) not null,
created_at datetime(6) not null,
created_by varchar(100) not null,
hashtag varchar(255),
modified_at datetime(6) not null,
modified_by varchar(100) not null,
title varchar(255) not null,
primary key (id)
) engine=InnoDB
Hibernate:
create table article_comment (
id bigint not null auto_increment,
content varchar(500) not null,
created_at datetime(6) not null,
created_by varchar(100) not null,
modified_at datetime(6) not null,
modified_by varchar(100) not null,
article_id bigint not null,
primary key (id)
) engine=InnoDB
Hibernate: create index IDX571gx7oqo5xpmgocegaidlcu9 on article (title)
Hibernate: create index IDXai44fu6vaa28ebpydglnv7t3e on article (hashtag)
Hibernate: create index IDXrmt77yibijtk4sarremr67saa on article (created_at)
Hibernate: create index IDXjl4utii2etiocimt799wvtuvv on article (created_by)
Hibernate: create index IDXpieqqnljv147sefofs56h25qx on article_comment (content)
Hibernate: create index IDXh1jx107qecntcbcpc2vfb07ij on article_comment (created_at)
Hibernate: create index IDXc6pa61djuf2o8xnceyyvtdbaq on article_comment (created_by)run을 돌려보면 테이블이 생성되었다는 문구와 인덱싱까지 되었다는 알림을 볼 수 있다.
그리고 DB Browser로 돌아가보면 board 스키마에 테이블이 생성되어있는것도 확인해 볼수 있다.
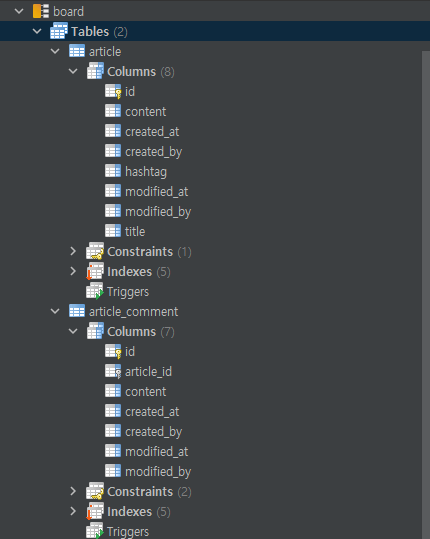
참고로 workbench 에서 해당 테이블의 ddl을 확인해보고 싶다면
mysql> show create table 테이블명;을 입력하면

결과 창이 나타나는데 마우스 우클릭 Copy field(unquoted)를 클릭하고 붙여넣기를 하면 나중에라도 테이블 생성을 워크벤치에서 해야할때 바로 사용할수 있다.

article 테이블에 연관관계 설정을 해준다.
@OrderBy("id")
@OneToMany(mappedBy ="article", cascade = CascadeType.ALL )
private final Set<ArticleComment> articleComments = new LinkedHashSet<>();코드 내부에 @ToString을 보면 lazy load를 포함하고 있어서 나중에 퍼포먼스나 메모리 저하를 일으킬수 있다는 경고가 나타난다.
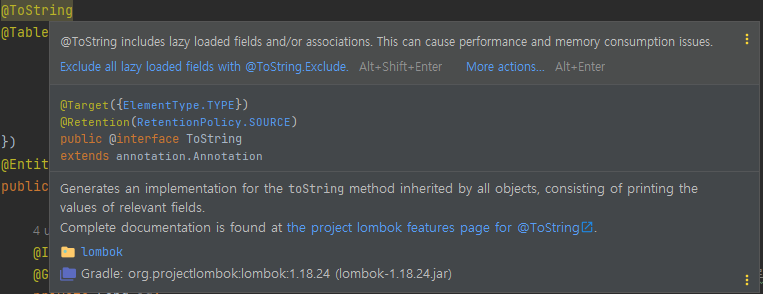
해당 알림 문구 아래의 파란 글씨 Exclude all lazy loaded fields with @ToString.Exclude를 선택하면 해결이 경고가 사라지는데, 이 조치는 퍼포먼스나 메모리 저하보다 더 큰 문제를 해결 하는데, 바로 순환 참조현상을 막아준다. 순환 참조는 참조하는 대상이 서로 물려있어서 참조할수 없게 되는 현상을 말한다.
@ToString이 Article.java를 거쳐갈때 Set에서 articleComments를 찍으려고 시도하기위해 AricleComment로 이동한다. ArticleComment에도 @ToString이 존재해서 필드 전체를 찍으려고 하는데 그중에 게시물 ID 인 private Article article이 있기때문에 또 Article로 넘어가서 내용을 찍어야하는데 또 @ToString이 있어서 다시 찍고... 또 ArticleComment 가고... 또하고.. 또하고..
이런 식으로 무한 반복이 일어나게 된다. 댓글에서로부터 글을 참조하는 경우는 정상적인 경우지만 글에서 댓글리스트를 뽑아보는 경우는 많지 않아서 Article에 있는 @ToString을 exclude 한 것이다.
이로써 양방향 바인딩이 완료되었다. 지금까지는 JPA 기능을 사용하면서 엔티티를 정의한 것 뿐 테스트는 이루어지지 않았다. 이를 위해서는 리포지토리 코드를 만들어야 한다.
만든 다음 ArticleRepository에서 테스트를 생성한다. 리포지토리관련 테스트가 아니라 JPA 테스트이기 때문에 이름을 변경했다. junit 대신에 assertj를 사용했다(import static org.assertj.core.api.Assertions.*;)
import static org.assertj.core.api.Assertions.*;
@DisplayName("JPA 연결 테스트")
@Import(JpaConfig.class)
@DataJpaTest
class JpaRepositoryTest {
private final ArticleRepository articleRepository;
private final ArticleCommentRepository articleCommentRepository;
public JpaRepositoryTest(
@Autowired ArticleRepository articleRepository,
@Autowired ArticleCommentRepository articleCommentRepository
) {
this.articleRepository = articleRepository;
this.articleCommentRepository = articleCommentRepository;
}
@DisplayName("select 테스트")
@Test
void givenTestData_whenSelecting_thenWorksFine() {
// Given
// When
// Then
}
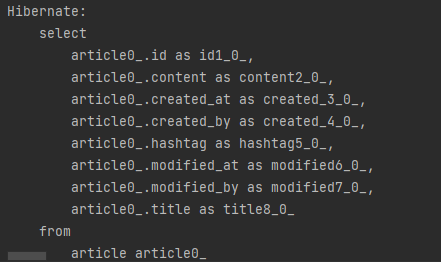
}articleREpostory를 findAll 을 사용하여 모든 내용을 List로 가져오는 테스트를 진행한다.
@Test
@DisplayName("select 테스트")
void givenTestData_whenSelecting_thenWorksFine() {
// Given
// When
List<Article> articles = articleRepository.findAll();
// Then
assertThat(articles)
.isNotNull()
.hasSize(0);
}
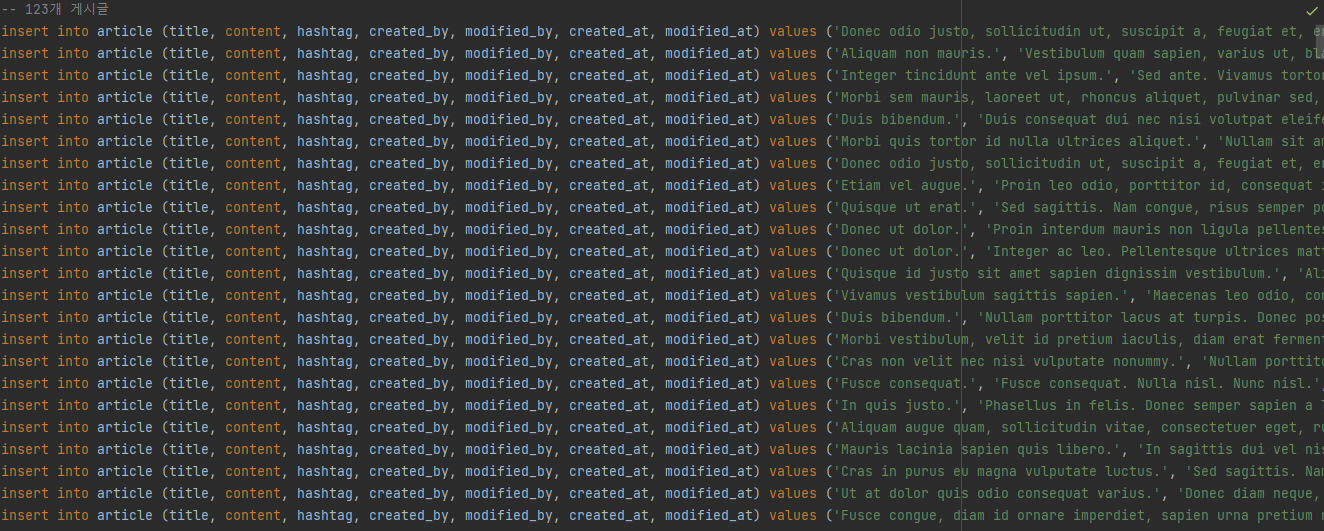
테스트 결과는 잘 나타났으니, 여기에 테스트 데이터를 추가해서 결과를 확인 하려고 한다.mockaroo 라는 사이트를 사용해서 대량의 테스트 데이터를 만든다.
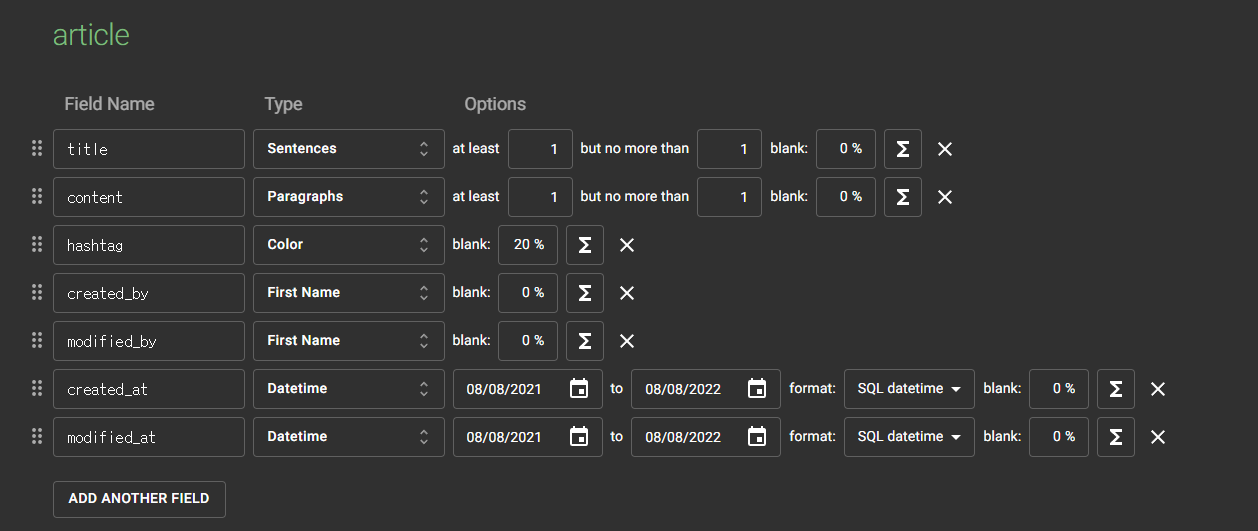
resource에 data.sql을 생성해서 데이터를 사용한다. 123개의 게시글과 1000개의 댓글 더미데이터를 복사해서 붙여넣었다.
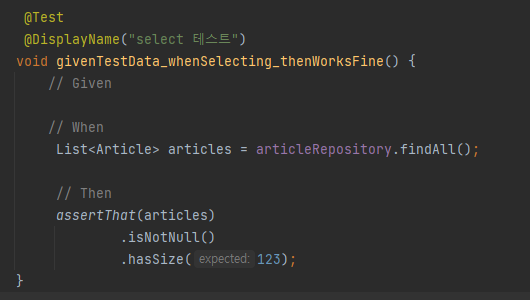
테스트 레포지토리로 돌아가서 expected 수치를 123으로 변경하고 다시 실행하면
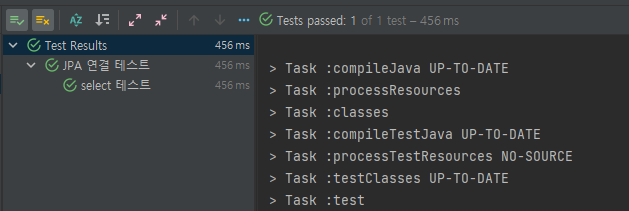
테스트 성공
나머지 CRUD 테스트도 진행한다.
※ insert 테스트
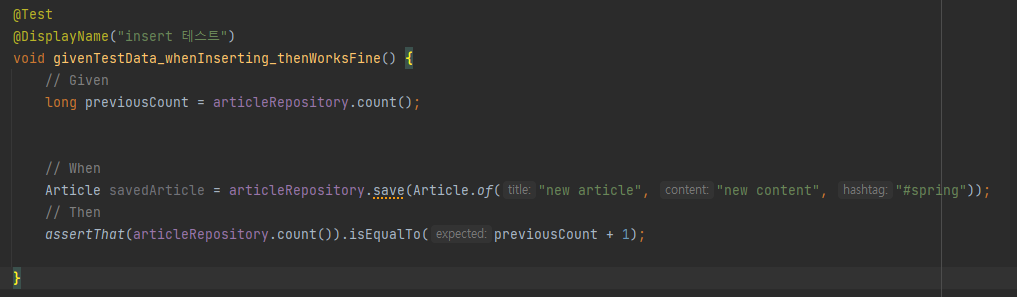
articleRepository의 갯수previousCount로 선언, 새로운 article 엔티티를 생성후 저장한 다음, articleRepository의 갯수가 previousCount에서 1을 더한 값과 같으면 테스트 성공이다.
오류 발생 not-null property references a null or transient value
전체 내용은 org.springframework.dao.DataIntegrityViolationException: not-null property references a null or transient value : com.jycproject.bulletinboard.domain.Article.createdAt; nested exception is org.hibernate.PropertyValueException: not-null property references a null or transient value : com.jycproject.bulletinboard.domain.Article.createdAt
createdAt에서 문제가 발생한 모양.
현재 JpaConfig에서는 Auditing 세팅이 되어있지만 추가적으로 하나 더작성해야하는데, 바로 엔티티에서도 Auditing을 쓰겠다는 표시를 해줘야한다. domain/Article에서 아래의 내용을 작성해야한다.
@EntityListeners(AuditingEntityListener.class)@EntityListeners - Entity를 DB에 적용하기 이전, 이후에 커스텀 콜백을 요청할 수 있는 어노테이션
AuditingEntityListener - Entity 영속성 및 업데이트에 대한 Auditing 정보를 캡처하는 JPA Entity Listener
이 문구는 당연히 ArticleComment 엔티티에도 작성되어있어야 한다. 그래야 Auditing을 쓸수 있기 때문이다.
다시 테스트를 돌려서 성공 확인
※update 테스트
엔티티에 이미 가지고 있는 데이터의 정보를 변경하는 테스트를 실행한다.
article테이블에서 특정 id를 찾고, id의 hashtag의 값을 변경한다음 articleRepository에 저장한다.
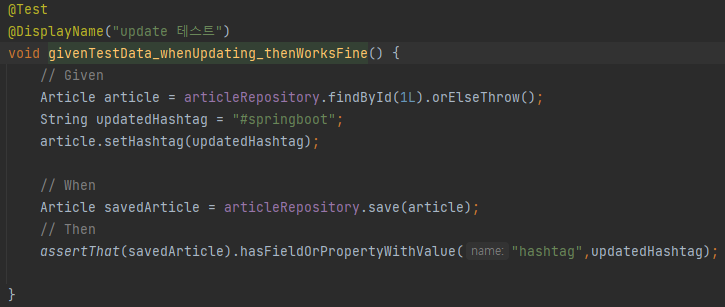
테스트는 성공했으나. 변동된 사항을 보여주지 않는다.
@Test 별로 나누어진 테스트 메소드들은 @DataJpaTest로 인해서 @Transactional이 자동으로 걸리게 된다. 테스트를 돌릴 때 트랜잭션은 기본값이 롤백으로 동작한다. 따라서 롤백에 의해서 중요하지 않다라고 판단이 된다면 동작이 생략될 수 있는데, 그중 하나가 바로 update인 것이다. update 테스트 내용은 영속성 컨테스트에서 가져온 데이터를 세이브 하는 것 이외에 다른 조회를 하거나 동작을 하지않고 끝내버리게 된다면 롤백이 되어버려서 변경한 hashtag의 값도 spring으로 돌아오게 된다.
그래서! 이렇게 되기를 원하지 않는다면!
save 다음에 flush를 작성해줘야한다.
articleRepository.flush();이렇게 말고도 save 대신 saveAndFlush라는 메소드가 있는데 그것을 사용해도 된다.
Article savedArticle = articleRepository.saveAndFlush(article);그리고 돌려보면 데이터베이스의 hashtag의 값이 변동된 것을 보여준다
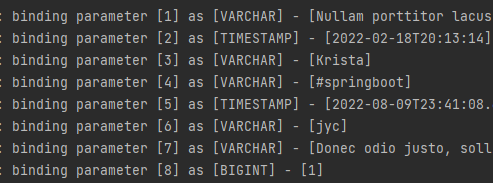
하지만 롤백이 진행되기 때문에 다시 원래대로 돌아올 것이다.
※ delete 테스트
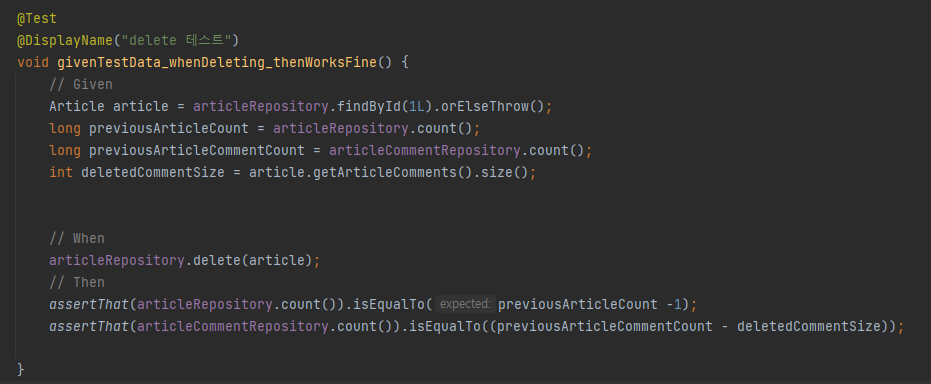
게시판을 지우는 작업이 제대로 동작하는지 테스트한다. 댓글은 다수로 작성되어있을수 있으므로 게시글을 지울때 댓글이 전부 사라져야한다. 따라서 갯수 비교를 할 때, 댓글의 양을 따로 지정한뒤 비교하는 것이 좋다.
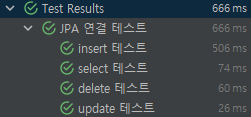
통과! 이로써 crud 테스트는 끝났다.
커밋 작업을 수행하기 전에 yaml에서 주석 처리했던 내용은
# datasource:
# url: jdbc:h2:mem:board;mode=mysql //inmemory 모드로 board이름을 사용하고 mysql모드를 활성화
# driver-class-name: org.h2.Driver // 드라이버 이름
# sql.init.mode: always
# test.database.replace: none // 모든 테스트는 내 testDB설정을 사용하게 하겠다.테스트 환경을 h2 Db를 이용해서 MySQL과 가까운 환경에서 테스트를 하고싶을때 사용하는 설정이다.
이제 커밋메시지를 작성하고 push를 진행한뒤 pull request를 보냈다.

이번에는 깃헙에서 말고 깃 크라켄에서 pull request를 진행한다.
상세작업은 깃허브로 가서 해야하므로 깃허브에서 request를 통해 merge를 해도 무방하다.
데이터베이스 접근 로직 테스트 정의 완료!
