https://finance.naver.com/ 해당 링크의 페이지를 사용해서 크롤링 실습을 진행한다. 만들어볼 프로젝트는 환율 계산기이다. 네이버 금융페이지의 환율 공시 정보를 기반으로 해서 금액을 입력하면 환율에 따른 외화로 환전이 되게끔 한다.
환율 가져오기
find(), split() 함수
requests 를 사용하여 문자열을 가져오고 문자열 조작함수를 통해 작성자가 원하는 데이터만 추출하는 작업을 진행한다.
※문자열 조작 파싱 - HTML 문서를 일반 문자열로 취급하여 원하는 문자열의 위치 등을 이용해 원하는 데이터를 추출하는 방법
- find() : 문자열의 위치와 길이를 기반으로 작업하는 함수
- split() : 문자열을 배열로 쪼개내어 작업하는 함수
네이버 금융사이트에서 '환전고시 환율' 에 있는 환율 데이터를 가져오는 작업을 진행하기전, 해당
url에 접근했을 때 사용자에게 어떤 html을 제공하는지 확인한다. 해당 페이지에 들어가서 우클릭 후 '페이지 소스 보기'를 통해서 html을 살펴본다.
예를 들어서 미국 USD를 찾아온다고 가정해보자. 페이지소스로 들어가서 검색기능을 이용하여 찾아보면

이렇게 data클래스의 div 안에 data_lst클래스의 ul 안에 속한 li 내부의 blind클래스를 가진 span에 적혀있다는 사실을 알수 있다.
res = req.get('https://finance.naver.com/marketindex/?tabSel=exchange#tab_section')
html = res.text
pos = html.find('미국 USD') #1076(값이 다를수 있음)
이렇게 위치를 찾아낼수 있고 , split을 이용해서 실제 환율 수치를 추출해서 가져올수있다.
- 미국 USD의 환율 수치를 표시한 데이터의 위치를 찾아낸다.
<span class="value">1,228.50</span> - split 함수를 이용해서 해당 데이터를 가져온다.
import requests as req
res = req.get('https://finance.naver.com/marketindex/?tabSel=exchange#tab_section')
html = res.text
a = html.split('<span class="value">')[1].split('</span>')[0]
print(a) #1,228.50
이렇게 find처럼 위치를 표시하는것과 달리 split은 앞과 뒤를 지정해주기 때문에 데이터 추출에서는 수월하게 작업이 가능하다는 것을 알 수 있다.
정규식(Regular Expression)
패턴 검색 기법
- (): 캡쳐
- []: 이중 아무거나
- .: 아무거나
- *: 0개 이상
- +: 1개이상
- ?: 없을 수도
- \: 위 특수 기호 무효화
뭔 뜻이지? 싶은데, 실습을 통해서 알아보자. match 메서드는 정규식과 변수의 내용이 얼마나 일치하는지를 보여준다. r뒤에 적힌 문자열이 정규식 문자열에 해당한다.
import re
s = 'hi'
greet = 'how are you?'
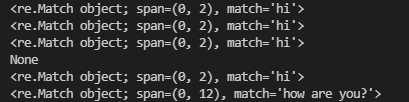
print (re.match(r'hi', s)) # 정규식으로 작성한 문자열과, 변수의 내용이 얼마나 일치하는가?
print(re.match(r'h.', s)) # h앞에 아무 문자나 와도 될때, 변수의 내용과 얼마나 일치하는가?
print(re.match(r'hi1*', s)) # *앞에 위치한 문자가 0개 이상이어도 될때, 변수의 내용과 얼마나 일치하는가?
print(re.match(r'hi1+', s)) # +앞에 위치한 문자가 1개 이상이어야 할때 ,변수의 내용과 얼마나 일치하는가?
print(re.match(r'hio?', s)) # ?앞에 위치한 문자가 있어도 되고 없어도 될때, 변수의 내용과 얼마나 일치하는가?
print(re.match(r'how are you\?', greet)) # \뒤의 특수기호는 무효화된다.
[]의 경우도 알아보자.
import re
rate = '이 영화는 A등급이다.'
print(re.match(r'이 영화는 A등급이다.', rate))위와 같이 영화의 등급에 대한 문구를 정규식을 통해 검색을 한다고 가정했을때, 영화의 등급이 A,B,C,F로 나뉘어져있다면, 등급 정도에 따라 match값이 none이 나올수도 있게 된다. 물론 이를 해결하기 위해서는 아무문자나 와도 된다라는 뜻으로 '.'을 써도 되지만, 영화의 등급종류는 4개로 정의했으므로 "이 4개중에서 하나면 나와도 된다." 라는 조건을 걸고 싶다면 어떻게 할까?
print(re.match(r'이 영화는 [ABCF]등급이다.', rate))이렇게 []안에 조건의 경우의 수를 기록하는 것이다. 이렇게 하면 rate의 문구중 A 대신 B C F를 입력해도 match가 된다.
마지막으로 ()캡처를 알아보자. 이전에 우리가 미국 USD 의 환율 데이터 값을 추출했던 것처럼 만약 영화의 등급값만을 추출하기 위해선 split를 사용하면 알수 있었다.
print(rate.split('이 영화는')[1].split('등급')[0]) #A이 방법말고 ()를 사용하면 좀더 단순한 코드로 만들수 있다.
print(re.findall(r'이 영화는 (.)등급이다', rate)) # ['A']해당 정규식 문자열과 변수의 문자열을 비교하여 ()에 쌓여있는 문자열을 추출한다.
그럼이제 환율 데이터값을 정규식으로 가져오는 실습을 해보자. 네이버 금융 > 시장지표> 환전 고시 환율 중에서 미국 USD와 그에대한 환율 값을 가져올 것이다. 미국USD 라는 글자와 데이터가 어디에 위치해 있는지를 콘솔을 통해서 확인한다.
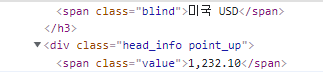
미국USD부터 value클래스를 가진 span의 값이 바로 환율의 값이므로, 캡처를 이용해서 작성한다.
import re
import requests as req
url = 'https://finance.naver.com/marketindex/?tabSel=exchange#tab_section'
res = req.get(url)
body = res.text
r = re.compile(r"미국 USD.*value\">(.*)</")
captures = r.findall(body)
print(captures)이러면 미국 USD에서부터 시작해서 value/>다음의 값을 캡쳐한다. 이때 캡쳐값은 </가 나타나기 전까지의 값 전부를 캡쳐한다. 라는 뜻으로 해석이되는데, 과연 어떻게 나올까?
 엥? 아무것도 출력되지 않는다? 왜?
엥? 아무것도 출력되지 않는다? 왜?
위에서 html 엘리먼트 캡쳐화면을 자세히 보면 미국 USD와 환율 데이터값은 서로 다른줄에 위치해있는데, 이때 줄바꿈을 위해 입력된 enter는 패턴검색 기법중 .에서 읽지 못하는 것이었다. 따라서 enter가 발생하는 순간 끝이나버리고, 결국에는 아무 값도 출력하지 못한 것이었다.
그럼 줄바꿈까지 고려해서 검사한다는 조건을 추가하려면, 현재 작성한 정규식옆에 조건을 붙여준다.
r = re.compile(r"미국 USD.*value\">(.*)</", re.DOTALL)
DOTALL은 이제 "모든 것을 포함해서 검사를 진행한다" 라는 뜻으로 줄바꿈 문자까지 포함해서 검색을 진행하게 된다.
자, 그럼이제 실행하면 원하는 환율값이 나타날까?

이것도 지금 일부분만 캡쳐한 것이다. 아니, 숫자 몇개만 나올줄 알았는데, 이젠 왜이렇게 무더기로 쏟아져 나오는 것일까?
이유는 바로 미국 USD.*에서 알수 있다. .과*은 각각 '아무거나'와 '0개 이상'이라는 뜻을 가지고 있다는 뜻인다. 이둘을 겹쳐서 사용해서 아무거나 0개 이상을 만족하는 </까지 죄다 긁어 모은 것이다.
그렇다면 범위를 좁혀줘야한다. r = re.compile(r"미국 USD.*?value\">(.*?)</", re.DOTALL) 이렇게 .*옆에 ?를 붙여주면, 아무거나 0개이상 가져오되 제일 좁은 범위로 가져오라는 뜻으로 변경된다. 뒷부분의 캡쳐부분에도 마찬가지로 ? 를 붙여서 아무거나 캡쳐하되 제일 좁은 범위로 캡처하라는 뜻이 된다.

수정후 다시 실행을 진행하면 이렇게 환율 수치가 나타나게 된다.
좀더 나아가서 네이버 금융 사이트에서 나라별 이름과 그 나라에 해당하는 환율 데이터를 가져오기위해 코드를 수정하자. 미국USD나 일본JPY같은 이름들은 콘솔을 통해 살펴보면 h_lst내부의 blind클래스 내부에 텍스트로 작성되어있다.
따라서 r = re.compile(r"h_lst.*?blind\">(.*?)</span>.*?value\">(.*?)</", re.DOTALL) h_lst다음에 아무거나 0개이상으로 검색하되 제일 좁은 범위로 검색한다. 뭘? blind"> 와 </span> 사이의 내용을 아무거나 0개이상 제일 좁은 범위로.
결과는

데이터 추출을 하기전에, 원하는 사이트의 html 구조를 파악하고 난 다음에 검색을 진행해야한다.
그럼이제 원화 금액을 입력하면 어느정도의 달러가 나오는지를 출력해주는 코드를 작성해보자.
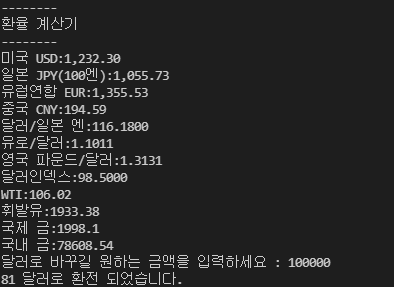
- 정규식 패턴 검색을 통해 가져온 각 나라별 환율과 기타 정보를 차례대로 보여준다.
- 달러로 환전할 금액을 입력하라는 입력창이 나타나며, 금액을 입려하면 금액/ 달러 환율 의 값을 출력해준다.
import re
import requests as req
url = 'https://finance.naver.com/marketindex/?tabSel=exchange#tab_section'
res = req.get(url)
body = res.text
r = re.compile(r"h_lst.*?blind\">(.*?)</span>.*?value\">(.*?)</", re.DOTALL)
captures = r.findall(body)
print(captures)
print("--------")
print("환율 계산기")
print("--------")
for c in captures:
print(c[0] + ":" + c[1])
usd = float(captures[0][1].replace(',',""))
won = input("달러로 바꾸길 원하는 금액을 입력하세요 : ")
won = int(won)
dollar = won / usd
result = int(dollar)
print(f"{result} 달러로 환전 되었습니다.")