제너레이터?
- 이터레이터를 만드는 함수
특징
- 함수 안에 yield를 사용한다.(return과 비교)
- 제너레이터 표현식을 사용할 수 있다.
- 메모리 사용이 효율적이다.
생성 방법
- 함수에서 yield를 사용한다.
def season_generator(*args):
for arg in args:
yield arg
g = season_generator('spring', 'summer', 'autumn', 'winter')
print(g.__next__())
print(g.__next__())
print(g.__next__())
print(g.__next__())

season_generator라는 함수를 선언하는데 해당 함수는 가변인자들을 받고 해당 인자 하나하나를 반복하여 yield 한다. 라는 뜻이다.
보통은 return을 사용하는데 저 yield 드는 뭘까?
다른 예시를 들어보자
def func():
print("첫번째 작업중...")
yield 1
print("두번째 작업중...")
yield 2
print("세번째 작업중...")
yield 3
ge = func()
data = ge.__next__()
print(data)위의 구문을 실행하면

만약에 yield 1을 return 1로 바꾼다면?
def func():
print("첫번째 작업중...")
return 1
print("두번째 작업중...")
yield 2
print("세번째 작업중...")
yield 3
ge = func()
data = ge.__next__()
print(data)

차이점이 분명히 있다.
return인 경우는 작업을 하던 도중에 만나면 바로 함수실행이 종료되며 함수값을 반환시킨다.
yield의 경우는 도중에 만나면 함수를 중단 시키고 해당 값을 출력한다.(함수의 재활용이 가능하다)
제너레이터 표현식
리스트를 만드는 것과 비슷하지만 바깥 괄호를 소괄호로 씌운다.
# 2.제너레이터 표현식
double_generator = (i * 2 for i in range(1, 10))
for i in double_generator:
print(i)제너레이터 사용 목적: 효율적인 메모리 사용
예를 들어서 1 부터 10000까지 숫자를 각각 3배씩 곱해서 나온 결과를 전부 출력해야한다고 가정해보자
이를 구현하는 방법으로 리스트와 제너레이터를 사용해서 구현해보면
list_data = [ i * 3 for i in range(1, 10000 + + 1)]
generator_data = ( i * 3 for i in range(1, 10000 + + 1))
위와 같은데 이 두 구문을 실행했을 때 차지하는 메모리의 크기를 비교해보자.
import sys
list_data = [ i * 3 for i in range(1, 10000 + + 1)]
generator_data = ( i * 3 for i in range(1, 10000 + + 1))
print(sys.getsizeof(list_data))
print(sys.getsizeof(generator_data))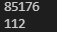
list 로 구현한 메모리가 월등하게 높은 크기를 가지고 있다. 왜일까?
리스트의 경우는 결과값을 전부 계산해서 메모리상에 저장하는 반면에 제너레이터는 식만 만들어져있을 뿐 결과값은 저장되어있지 않다가. __next__가 호출될 때만 결과값을 만들어서 저장하기 때문이다.
정리
리스트 - 이미 결과값을 계산해서 메모리상에 저장이 되어있음
제너레이터 - 식만 만들어져있을 뿐 결과값은 저장되어있지 않음. next 를 호출할 때만 결과값을 만들어 놓는다.
인공지능이나 빅데이터같은 용량이 많은 데이터를 다룰때 제너레이터를 항상 사용한다고 한다.
