개요
사이드 프로젝트(이하 블루밍)에서 배포를 앞두고 모니터링 시스템을 구축하기로 했다. 사용자 유치가 시작되고 나면 가장 먼저 사용자들이 서비스를 이용하는 데 있어 생기는 로그들을 수집해 관리하는 것이 필요하다고 생각해 모니터링 시스템을 구축하게 되었다. 모니터링 시스템은 작년 새싹톤 네트워킹 시간에 어벤져스 팀의 발표를 보러 갔다가 처음 봤다. 그 땐 그걸 모니터링 시스템이라고 하는지도, 모니터링 시스템에서 어떤 정보들을 보여주고 있는지도 전혀 이해를 하지 못한 채로 우와 멋있다만 하고 왔다.. 그리고 드디어 내 손으로 만들어 배포하게 된 어플의 모니터링 시스템을 구축하게 되었다. 감회가 참 새롭다.
우선 모니터링 시스템 구축 방법 이전에 이론 관련 내용을 정리하고 넘어가면 좋을 것 같아 이번 포스팅에서는 이론 내용 위주로 정리하고, 다음 포스트에서 본격적인 시스템 구축 프로세스를 정리해보려 한다.
서비스 메트릭스(metrics) 모니터링 시스템
메트릭(metric)
하드웨어나 소프트웨어에 대한 성능 측정을 위한 측정 수치값이다.
즉, cpu 사용률, ram 사용률, 스레드 사용률 등 시간에 따른 추이를 추적할 가치가 있는 데이터를 metric이라 부른다.
메트릭스라고 해서 영화 매트릭스를 떠올렸다…
서비스 메트릭스 모니터링 시스템에 필요한 정보
참고한 블로그에 따르면 크게 다음 세가지로 구분해 볼 수 있다고 한다.
- 컴퓨터 자원에 대한 모니터링
- 서비스의 로그에 대한 모니터링
- 저장된 데이터들에 대한 모니터링
우리는 우선 1, 2번에 대한 내용들을 모니터링 시스템에 반영하기로 했다. 아직 배포 이전이라 사용자도 없기에 저장된 데이터들을 다루는 것은 아직까진 불필요하다고 판단했다. 또한, 2번에서도 로그 중 가장 필요한 로그들을 우선적으로 가져오기로 했다. 우리는 우선 경고(WARN), 오류(ERROR) 단계의 로그들을 가져오기로 했다. (INFO도 많이들 가져오던데 추후 논의해 INFO로 가져올 로그 내용들을 정하기로 했다. 그리고 로깅 단계에 대한 이야기는 로그 모니터링 때 좀 더 자세히 정리하겠다.)
모니터링 시스템을 구축하기 전에 알아야 할 구성 개요
위에서는 모니터링 시스템에서 시각화 할 정보들에 대해 알아보았다. 그런데 과연 이 모니터링 시스템은 어떻게 어떤 구성으로 구축해야할까?
사실 이 >어떤 구성<이라는 것에 대해 깊게 고민해보지 않은 상태로 어제 페어 프로그래밍을 하러 갔다. 그래서 문제가 생겼고, 이 문제를 서버에 설치 다 해놓고 마지막 시각화 단계에서 문제가 생겨 한참을 헤맸다. 그래서 이런 불상사가 생기지 않게 이론적인 고민을 우선적으로 하고 실습으로 넘어가도록 하자.
다음은 블루밍의 서버 및 모니터링 시스템 구축 구조이다.
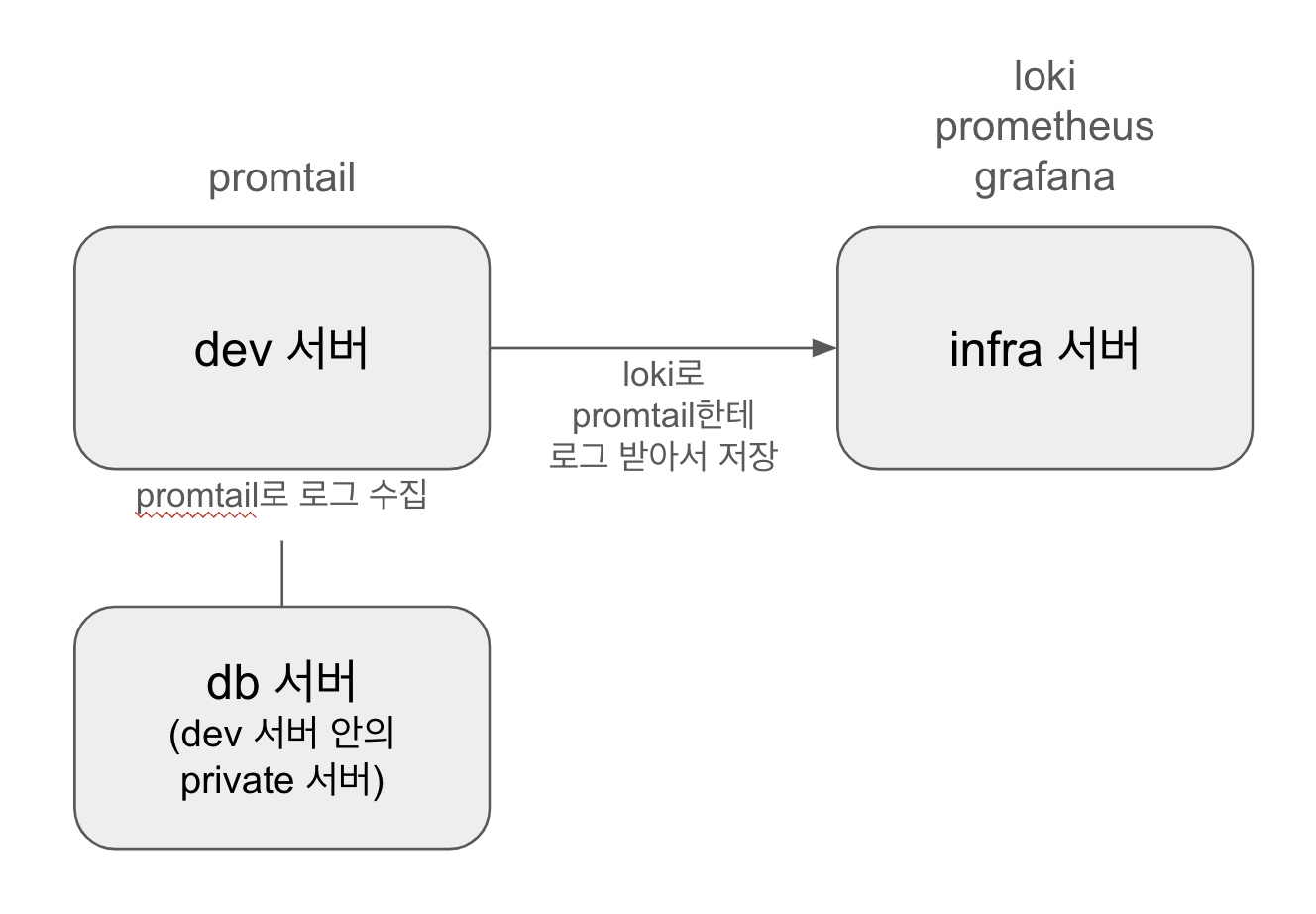
이 구조도를 잘 이해하고 작업에 시작해야 실수로 버리는 시간을 아낄 수 있다. 명심 또 명심
배포를 위한 prod 서버가 따로 존재하지만 아직 배포 이전이고 유의미한 로그 정보를 갖고 있는 것은 dev 서버이기 때문에 dev 서버를 우선적으로 시스템을 구축했다.
- 모니터링 시스템 구축을 위해 새로 생성한
infra서버에prometheus와grafana를 설치해 dev 서버 메트릭 정보를 시각화한다. 이 때 dev 서버 메트릭 정보는springboot actuator가 제공한다. - dev 서버의 로그 정보는 가져올 로그 정보들을 미리 설정한 다음
promtail을 설치해promtail이 로그를 수집하도록 한다. promtail이 수집한 로그 정보를 infra 서버의loki로 넘기면loki가 이 로그 정보들을 가지고 있다가grafana를 통해 시각화해 보여준다.
정리
모니터링 시스템 구축을 처음하면서 어떻게 시작해야할지부터 헤맸어서 생각보다 시간이 더 많이 걸렸던 것 같다. 어떤 내용이 모니터링 시스템에 포함되어야하는지는 서비스마다 그 중요도가 다를 것이고, 이는 개발자가 결정하기 나름인 것 같다. 그러나 그 이전에 모니터링 시스템 구축을 할 줄 알아야 뭘 보든말든 할 것 아닌가. 그래서 모니터링 시스템에 보편적으로 담는 내용들과 구축을 위해 필수로 이해하고 있어야 할 서버 및 인프라 구조에 대해 꼭 정리하고 싶었다. 마지막으로, 이 모니터링 시스템이 유용할 그 날이 꼭 오길 바라며…!!!(성공적인 사용자 유치를 기원하며) 포스팅을 마친다.
참고
