Webflux + R2DBC 스택에 대해 공부하고 있습니다.
본 게시글은 이해도가 성숙되기 전, 삽질(?) 로그를 담고 있어 그다지 유익하지 않을 수도 있습니다. 😂
https://github.com/infobip/infobip-spring-data-querydsl 라이브러리를 주제로 다루고 있습니다.
최근에 리액티브 프로그래밍도 공부 할 겸, MVC & Jpa로 개발해두었던 사이드 프로젝트 서버 환경을 Webflux & R2DBC로 마이그레이션 할 일이 생겼습니다.
관련 Git Repository
(Kotlin + Spring 으로 할 수 있는 건 다 하고 있는 어마어마한 프로젝트.. ㅋㅋㅋ 조만간 블로그에 정리해두어야겠다.)
제대로 써본 적은 없지만, 어깨 너머로 경험해본 R2DBC 생태계는 JPA에 비해 너무나도 미성숙해 보였습니다.
(나름 메이저(?) dev.miku의 어이없는 칼럼 매핑 이슈)
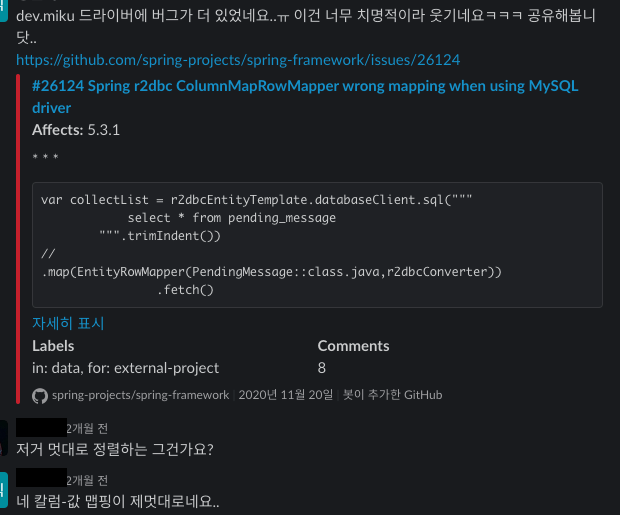
++ 쿼리 조금 복잡해진다 싶으면 Row Query 때려박는(?!) 모습 등등..
어찌됐든 R2DBC로 갈아타기로 한 상황에서,
Jpa + QueryDsl 조합으로 DB 접근을 깔끔하게 가져가는 경험을 R2DBC에서도 할 수 없을까?
싶어서 Github에 쳐봤는데, 아래와 같은 프로젝트를 만날 수 있었습니다.
https://github.com/infobip/infobip-spring-data-querydsl/tags

설명만 보면 fancy한 프로젝트가 아닐 수 없죠?
바로 사용해봤습니다.
하지말걸..
Setup
스프링 버전에 맞춰서 아래 의존성을 추가해줍니다.
2.7.0 이전 스프링 프로젝트인 경우 6.2.0이 호환 가능한 최신 버전입니다.
r2dbc 런타임 구현체로는 jasync를 사용했습니다.
implementation("com.infobip:infobip-spring-data-r2dbc-querydsl-boot-starter:6.2.0")
kapt("com.infobip:infobip-spring-data-jdbc-annotation-processor-common:6.2.0")
runtimeOnly("io.r2dbc:r2dbc-pool")
runtimeOnly("com.github.jasync-sql:jasync-r2dbc-mysql:2.0.8")UseCases
interface QuerydslR2dbcRepository<T, ID> extends
ReactiveSortingRepository<T, ID>,
ReactiveQuerydslPredicateExecutor<T>,
QuerydslR2dbcFragment<T>위 인터페이스를 상속받아서,
interface Dao: QuerydslR2dbcRepository<User, Long>
@Service
class ExampleService(
private val repository: Dao,
) {
fun useQueryDsl(): Flow<User> =
repository.query { queryFactory ->
// 우리가 아는 QueryDsl 문법~~
queryFactory
.select(user)
.from(user)
}
.all()
.asFlow()
}
대충 이런 꼴로 쓸 수 있습니다.
나이스하죠?
이 게시글은 이것으로 마무리... 했으면 좋았을테지만..
사용에 있어서 숙지해야 할 것들이 몇 가지 있습니다.
되던 것도 안되는 마술
위 의존성을 추가하고, 아무 설정 없이 앱을 키면, 잘만 되던 r2dbc repository들이 갑자기 동작을 못합니다. (ㅋㅋ)
// 익숙한 친구
interface PostR2dbcRepository : CoroutineCrudRepository<PostEntity, Long>
// 를 못쓴다..
postRepository.findAllById(postIds).toList()
아래와 같은 오류가 발생합니다.
java.util.NoSuchElementException: key Id is missing in the map.결론부터
말하면,, 이것은 Infobip 라이브러리의 NamingStrategy 설정으로 인해 SQL select <=> Entity Column 매핑이 잘못 이루어지기 때문에 발생합니다.
NamingStrategy
따라서 기본 NamingStrategy를 변경해주면 해결할 수 있습니다.
어이없게도, infobip-querydsl 의 기본 네이밍 전략은 PascalCase 입니다.
public class PascalCaseNamingStrategy implements NamingStrategy {
@Override
public String getTableName(Class<?> type) {
return type.getSimpleName();
}
@Override
public String getColumnName(RelationalPersistentProperty property) {
return property.getName().substring(0, 1).toUpperCase() + property.getName().substring(1);
}
}칼럼명 Resolve가, JPA 사용하던 시절처럼 CamelCase로 잘 됐으면 좋겠습니다.
Bean을 덮어써줍시다.
@Bean
@Primary
fun namingStrategy(): NamingStrategy = object : NamingStrategy {
override fun getTableName(type: Class<*>): String = type.simpleName
}원인을 찾아 다이브 해보겠습니다. (스킵하셔도 되는 부분입니다.)
R2DBC에서 DAO Property <-> Table Column 사이의 매핑이 일어나는 곳은 아래와 같습니다.
// spring-data-r2dbc
public class MappingR2dbcConverter {
@Nullable
private Object readFrom(
Row row,
@Nullable RowMetadata metadata,
RelationalPersistentProperty property,
String prefix
) {
// row와 metadata 정보를 토대로,
// 영속화 하려는 ORM 객체의 property에 주입한다.
}
}jasync는 쿼리 실행 결과를 JasyncResult 클래스로 보관합니다.
여기서 위 readFrom 함수의 row들이 생성된 채로 대기합니다.
// jasync-r2dbc-mysql
// 쿼리 결과를 받아와서, 대상 타입에 캐스팅
class JasyncResult {
// resultSet = DB 수행 결과 (테이블 칼럼에 매핑되는 값을 담고 있음 : value)
// ResultSet 타입은 Row 인터페이스를 구현한 ArrayRowData의 일급 컬렉션
private val resultSet: ResultSet
// metadata = DB 메타데이터 (테이블 칼럼 정보를 담고 있음 : key)
fun map(BiFunction<Row, RowMetadata, ? extends T> mappingFunction): Publisher<T>
}property 값들은 R2dbcMappingContext 라는 spring-data Bean 안에서 BasicRelationalPersistentProperty 클래스로 감싸져 생성됩니다.
@Bean
@ConditionalOnMissingBean
public R2dbcMappingContext r2dbcMappingContext(
ObjectProvider<NamingStrategy> namingStrategy,
R2dbcCustomConversions r2dbcCustomConversions
) {
R2dbcMappingContext relationalMappingContext = new R2dbcMappingContext(
namingStrategy.getIfAvailable(() -> NamingStrategy.INSTANCE));
relationalMappingContext.setSimpleTypeHolder(r2dbcCustomConversions.getSimpleTypeHolder());
return relationalMappingContext;
}위의 선언을 보시면, NamingStrategy 빈에 의존하고 있는 것을 알 수 있습니다.
이게 PascalCase로 되어 있어서, 결론적으로 Property Binding에 실패하고 있었습니다.
그러니까, 가령 PostEntity가 있었다고 하면,
- CamelCase
PostEntity.id -> 'id' as an identifier
- PascalCase
PostEntity.id -> 'Id' as an identifier프로퍼티 바인딩이 위와 같이 되어, 파스칼 케이스를 쓰는 경우
실제 쿼리 결과로 가져왔을
select p.id from PostEntity p ...에서의 id와 Id를 동일시 하지 못하고 에러가 나게 됩니다.
Projections
비슷한 맥락에서
Projections.constructor(..)문법을 쓸 때에도 주의해야 합니다.
JPA를 쓸 때에는 DTO 생성자에 순서 & 타입만 맞추어 주입해주면 되었지만,
R2DBC에서는 (적어도 지금까지 파악한 바로는)
Column 이름과 DTO Property 이름 간의 연관관계가 존재해야 합니다.
@ProjectColumnCaseFormat
앞선 이슈처럼, 쿼리를 만들어낼 때 참고하는 NamingStrategy의 기본값이 Pascal 이라서, QueryDsl 구문을 사용할 때도 마찬가지로 매핑 과정에서 런타임 오류가 발생합니다.
QueryDsl은 어노테이션 프로세서를 기반으로 만들어진 Q Class로부터 쿼리를 생성하기 때문에, 앞서 만들어준 NamingStrategy 빈과는 또 다른 무언가를 통해서 문제를 해결해야 합니다.
여기까지 깨닫고 눈물을 흘릴 뻔 했으나..
다행히도 비슷한 이슈가 GitHub에 등록되어 있었고, 이에 대한 대안이 준비되어 있었습니다.
https://github.com/infobip/infobip-spring-data-querydsl/issues/21
@ProjectColumnCaseFormat(CaseFormat.LOWER_UNDERSCORE)를 선언해서,
PostEntity.userId -> PostEntity.user_id
...등으로 적절히 매핑이 가능하게 설정해줄 수 있습니다.
Caveat #1 - @PersistenceConstructor
spring-data-r2dbc의 MappingR2dbcConverter는 @PersistenceConstructor 어노테이션을 바탕으로 테이블 엔티티를 만들어냅니다. (마치 리플렉션 처럼 ..)
Projection constructor에 @PersistenceConstructor를 붙여주지 않으면,
DTO에 쿼리 결과를 영사하는 것이 불가능합니다 🥲
Caveat #2 - alias
Projection에 주입해주는 칼럼 명에 주의를 기울여야 합니다.
가령
Projections.constructor(SomeDto::class.java, PostEntity.id, UserEntity.id)쿼리는 결과가 깨집니다.
id 이름이 같아서요...
따라서, alias를 설정해주되, 꼭 @ProjectColumnCaseFormat에 부합하게 세팅해야 합니다.
예를 들어, 위 케이스에 alias를 설정해준다고 하면,
data class SomeDto @PersistenceConstructor constructor(postId, userId)
// O
Projections.constructor(
SomeDto::class.java, PostEntity.id.alias("post_id"), UserEntity.id.alias("user_id")
)
// X (Error)
Projections.constructor(
SomeDto::class.java, PostEntity.id.alias("postId"), UserEntity.id.alias("userId")
)사용 시에 위처럼 적어주어야 합니다.
왜일까
@ProjectColumnCaseFormat(LOWER_UNDERSCORE) 세팅을 통해,
모든 DTO 프로퍼티가 lower-underscore로 바뀐 상태에서,
QueryDsl alias로 설정한 query result 값들이 DTO 프로퍼티와 매칭됩니다.
따라서 이 때 매칭은 무조건 lower-underscore 기준이어야 하는 것이죠..
마치며
긴 글이 되었는데 막상 추려보면 주의할 점 두 가지로 요약이 됩니다.
원인을 파악하는 데에는 한참 걸렸고, 디버깅 할때는 오픈소스 컨트리뷰션 각!? 하며 열심히 찾았는데..
막상 뭔가 액션을 취하기에는.. spring-data-r2dbc와 queryDsl 양 쪽 모두를 고려해보았을 때, 현 해결책이 최적이라는 결론에 도달했습니다.
QueryDsl의 alias(쿼리 결과)는 그 자체로 불변하는 것이 이치에 맞고,
Spring-Data-R2DBC의 프로퍼티 바인딩은 NamingStrategy에 의존하는 것이 가장 깔끔하기 때문에,
두 라이브러리 가운데 하나의 구현을 바꾸는 것보단, 절충해서 사용하는 것이 가장 낫겠죠..
나름 재밌는 시간이었지만 고생에 비해 가성비가 안나온 이번 주제를 .. 마무리 해 보겠습니다ㅏ... ㅎㅎ 😭

최고의 가성비인듯한데요ㅎ 잘 보고 갑니다.