01. ORM
MyBatis 란?
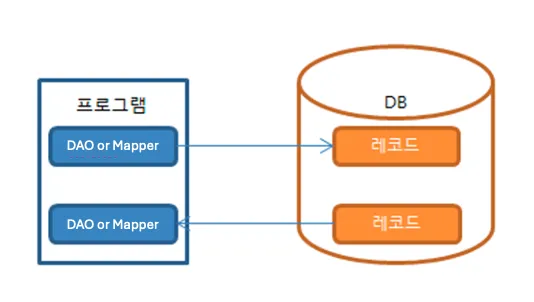
RowMapper 가 가지고있는 단점인 “반복되는 코드”를 줄이고 “함께있는 프로그램 코드와 쿼리 코드를 분리하여 관리”하고 싶은 니즈를 반영하여 탄생
- MyBatis 특징
- jdbc로 처리하는 코드의 설정(Connection) 부분을 줄이고 실제 sql문에 연결함으로서 빠른 개발이 가능하게 한다. (SQL Mapper 특징)
- MyBatis 코드는 map 인터페이스(또는 클래스)와 SQL 쿼리와 ResultSet 매핑을 위한 xml 및annotation을 사용한다.
- 다른 방식에 비해 객체자체보다 쿼리에 집중할 수 있다
하지만 MyBatis도 한계점이 존재!
- MyBatis 한계점
- 결국 SQL을 직접 작성하는것은 피곤하다…(DB 기능에 종속적) 😫
- 테이블마다 비슷한 CRUD 반복, DB타입 및 테이블에 종속적이다. 😵💫
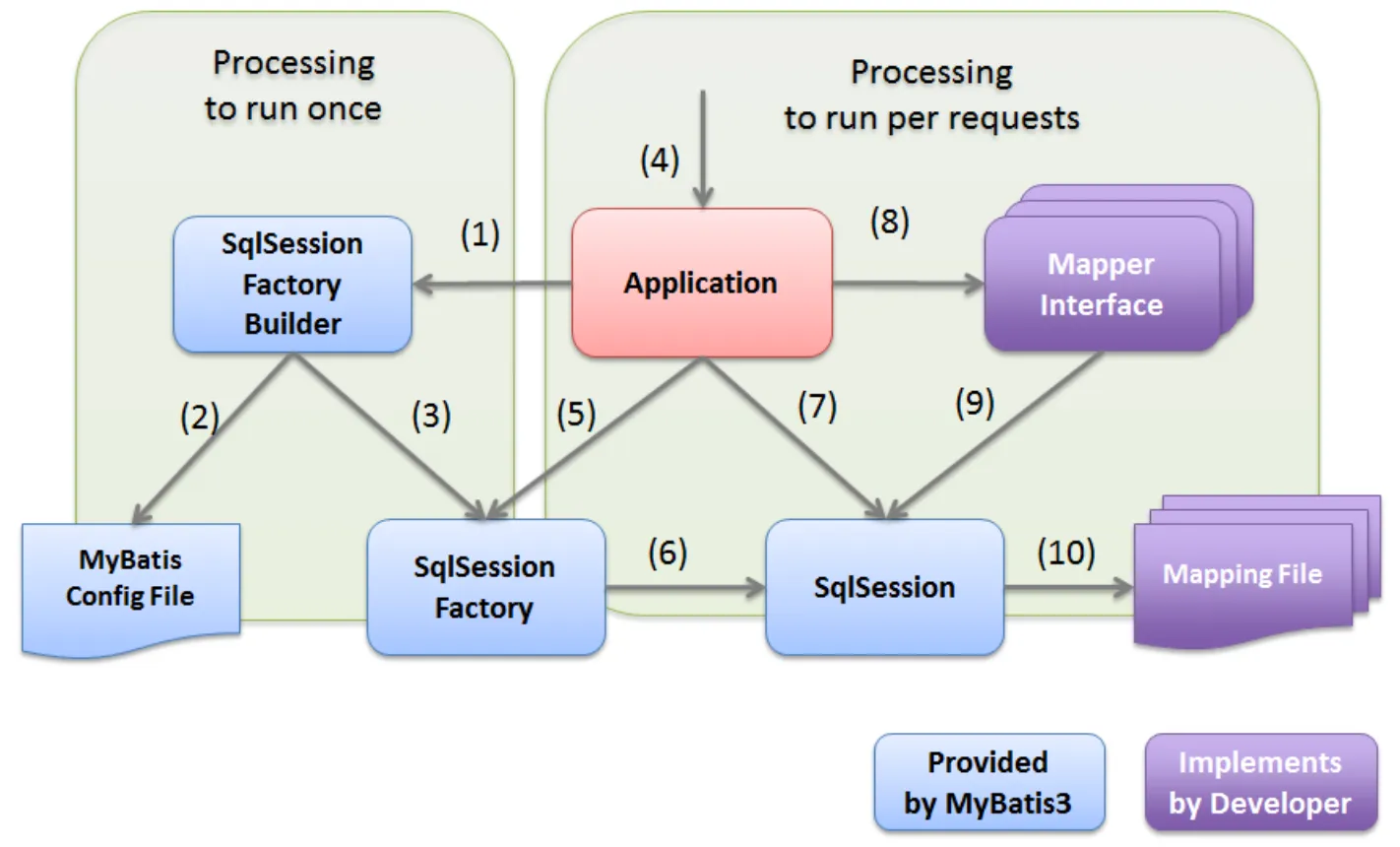
MyBatis 의 동작
쿼리 코드 만들기 (JpaRepository)
QueryMapper 의 DB의존성 및 중복 쿼리 문제로 ORM 이 탄생했다.
- ORM 은 DAO 또는 Mapper 를 통해서 조작하는것이 아니라 테이블을 아예 하나의 객체(Object)와 대응
ORM 이 해결해야하는 문제점 과 해결책
- 문제점
상속의 문제
- 객체 : 객체간에 멤버변수나 상속관계를 맺을 수 있다.
- RDB : 테이블들은 상속관계가 없고 모두 독립적으로 존재한다. 💁♂️ 해결방법 : 매핑정보에 상속정보를 넣어준다. (`@OneToMany`, `@ManyToOne`)
관계 문제
- 객체 : 참조를 통해 관계를 가지며 방향을 가진다. (다대다 관계도 있음)
- RDB : 외래키(FK)를 설정하여 Join 으로 조회시에만 참조가 가능하다. (즉, 다대다는 매핑 테이블 필요) 💁♂️ 해결방법 : 매핑정보에 방향정보를 넣어준다. (`@JoinColumn`, `@MappedBy`)
탐색 문제
- 객체 : 참조를 통해 다른 객체로 순차적 탐색이 가능하며 콜렉션도 순회한다.
- RDB : 탐색시 참조하는 만큼 추가 쿼리나, Join 이 발생하여 비효율적이다. 💁♂️ 해결방법 : 매핑/조회 정보로 참조탐색 시점을 관리한다.(`@FetchType`, `fetchJoin()`)
밀도 문제
- 객체 : 멤버 객체크기가 매우 클 수 있다.
- RDB : 기본 데이터 타입만 존재한다. 💁♂️ 해결방법 : 크기가 큰 멤버 객체는 테이블을 분리하여 상속으로 처리한다. (`@embedded`)
식별성 문제
- 객체 : 객체의 hashCode 또는 정의한 equals() 메소드를 통해 식별
- RDB : PK 로만 식별 💁♂️ 해결방법 : PK 를 객체 Id로 설정하고 EntityManager는 해당 값으로 객체를 식별하여 관리 한다.(`@Id`,`@GeneratedValue` )
- 해결책
영속성 컨텍스트(1차 캐시)를 활용한 쓰기지연- 영속성 이란?
- 데이터를 생성한 프로그램이 종료되어도 사라지지 않는 데이터의 특성을 말한다.
- 영속성을 갖지 않으면 데이터는 메모리에서만 존재하게 되고 프로그램이 종료되면 해당 데이터는 모두 사라지게 된다.
- 그래서 우리는 데이터를 파일이나 DB에 영구 저장함으로써 데이터에 영속성을 부여한다.
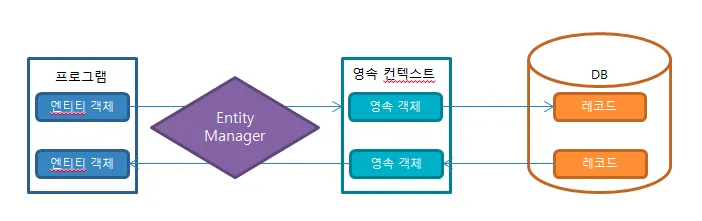
- 영속성 이란?
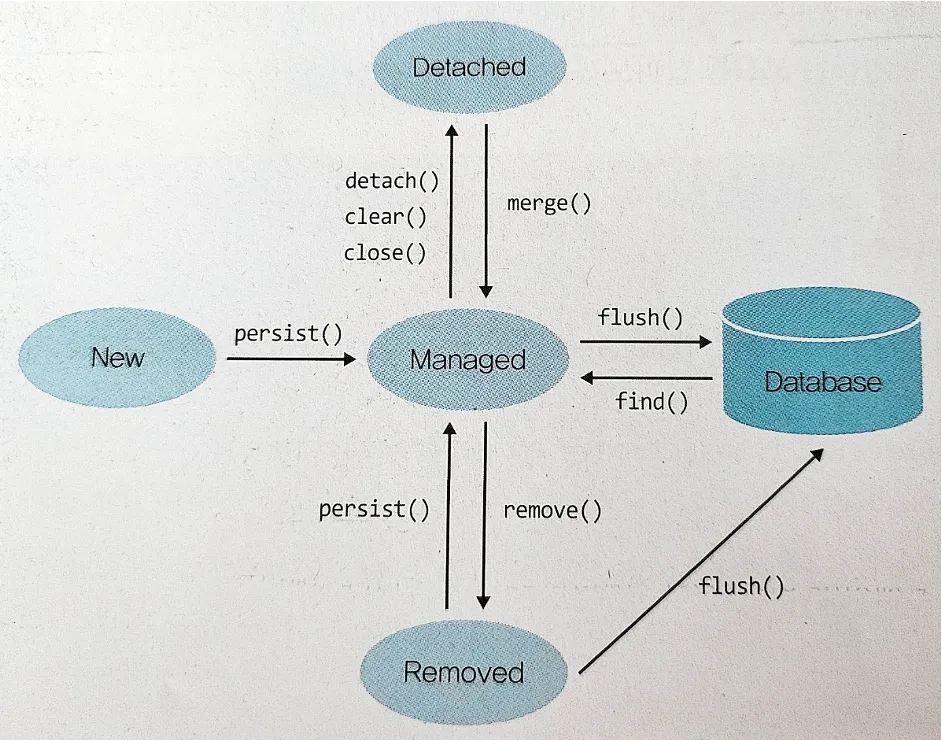
영속성 4가지 상태 ( 비영속 > 영속 > 준영속 | 삭제)
① 비영속(new/transient) - 엔티티 객체가 만들어져서 아직 저장되지 않은 상태로, 영속성컨텍스트와 전혀 관계가 없는 상태
② 영속(managed) - 엔티티가 영속성 컨텍스트에 저장되어, 영속성 컨텍스트가 관리할 수 있는 상태
③ 준영속(detached) - 엔티티가 영속성 컨텍스트에 저장되어 있다가 분리된 상태로, 영속성컨텍스트가 더 이상 관리하지 않는 상태
④ 삭제(removed) - 엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제하겠다고 표시한 상태
- 객체의 영속성 상태는 Entity Manager 의 메소드를 통해 전환된다.
- 💁♂️ Raw JPA 관점에서 순서대로 요약정리 해보자면
- new >(비영속상태)> persist(),merge() >(영속성 컨텍스트에 저장된 상태)> flush() >(DB에 쿼리가 전송된 상태)> commit() >(DB에 쿼리가 반영된 상태)
Item item = new Item(); // 1 item.setItemNm("테스트 상품"); ------------------------------------------------------------- EntityManager em = entityManagerFactory.createEntityManager(); // 2 EntityTransaction transaction = em.getTransaction(); // 3 ------------------------------------------------------------ transaction.begin(); em.persist(item); // 4-1 em.flush(item). // 4-2 (DB에 SQL 보내기/commit시 자동수행되어 생략 가능함) transaction.commit(); // 5 ------------------------------------------------------------- em.close(); // 6 ------------------------------------------------------------- 1️⃣ 영속성 컨텍스트에 담을 상품 엔티티 생성 2️⃣ 엔티티 매니저 팩토리로부터 엔티티 매니저를 생성 3️⃣ 데이터 변경 시 무결성을 위해 트랜잭션 시작 4️⃣ 영속성 컨텍스트에 저장된 상태, 아직 DB에 INSERT SQL 보내기 전 5️⃣ 트랜잭션을 DB에 반영, 이 때 실제로 INSERT SQL 커밋 수행 6️⃣ 엔티티 매니저와 엔티티 매니저 팩토리 자원을 close() 호출로 반환
- 쓰기 지연이 발생하는 시점
- flush() 동작이 발생하기 전까지 최적화한다.
- flush() 동작으로 전송된 쿼리는 더이상 쿼리 최적화는 되지 않고, 이후 commit()으로 반영만 가능하다.
- 쓰기 지연 효과
- 여러개의 객체를 생성할 경우 모아서 한번에 쿼리를 전송한다.
- 영속성 상태의 객체가 생성 및 수정이 여러번 일어나더라도 해당 트랜잭션 종료시 쿼리는 1번만 전송될 수 있다.
- 영속성 상태에서 객체가 생성되었다 삭제되었다면 실제 DB에는 아무 동작이 전송되지 않을 수 있다.
- 즉, 여러가지 동작이 많이 발생하더라도 쿼리는 트랜잭션당 최적화 되어 최소쿼리만 날라가게된다.
ORM 을 사용하는 가장 쉬운 방법 : JpaRepository
💁♂️ Repository vs JpaRepository
- 기존 Repository
@Repository을 클래스에 붙인다.@Component어노테이션을 포함하고 있어서 앱 실행시 생성 후 Bean으로 등록된다.- 앞서배운 Repository 기본 기능만 가진 구현체가 생성된다. (DB별 예외처리 등)
- 새로운 JpaRepository
- JpaRepository<Entity,ID> 인터페이스를 인터페이스에 extends 붙인다.
@NotRepositoryBean된 **상위 인터페이스들의 기능을 포함한 구현체가 프로그래밍된다. (@NotRepositoryBean** = 빈생성 막음 →상속받으면 생성돼서 사용가능)
- JpaRepository (마스터 셰프): 데이터 액세스를 위한 핵심 기능의 종합적인 요리책(기능) 을 제공합니다.
@NotRepositoryBean인터페이스 (셰프): 각 인터페이스는 특정 데이터 액세스 방법을 제공하는 전문적인 기술 또는 레시피를 나타냅니다.- JpaRepository 상속: 마스터 셰프의 요리책과 셰프의 전문성을 얻습니다.
- SpringDataJpa 에 의해 엔티티의 CRUD, 페이징, 정렬 기능 메소드들을 가진 빈이 등록된다. (상위 인터페이스들의 기능)

첫 시작