structured data - 표
unstructured data - 음성, 동영상, 자연어
| 구분 | 관계형 DB | 비관계형 DB |
|---|---|---|
| DB종류 | SQL | MongoDB, Cassandra |
| 자료구조 | 표, table | 표 이외의 다른 자료구조 document(json, key : value) |
| 입출력 방법 | SQL | SQL, 독자적인 명령 |
요즘은 RDB읙 경우 Tabular DB(Table 구조의), Document DB와 같이 데이터의 저장 구조의 형태에 따라서 구분하는 추세입니다.
DataTypes
| 종류 |
|---|
| Simple Structured Data |
| Complex Structured Data |
| Semistructured Data |
| Unstructured Data |
사실은 structure가 없는 Data는 없어요
정규화
DB의 구조를 잘 만드는 하나의 테크닉.
Column의 위치를 찾는 행위를 말한다.
일반적으로 있어야할 위치에 있게 하는 것
12가지의 방법이 있는데 이중 3가지의 방법이 주로 쓰입니다.
사원과 사원 번호는 밀접한 관계가 있기 때문에 함께 둡니다.
밀접하지 않은 Column은 함께 둘 필요가 없습니다.
Normalization, Denomalization
정규화는 ER-Modeling이 나오기 전부터 존재해 왔어요
정규화는 관계형이라는 개념만 있었던 시기에서부터도 이미 존재했어요
1, 2, 3 정규화는 순서의 개념이 아니에요(1 -> 2 -> 3정규화의 순서로 무조건 진행해야 한다는 것은 아니라는 이야기입니다.)
기본 전제
모든 Cell에는 한 종류의 값 하나만 들어가게 해야 함
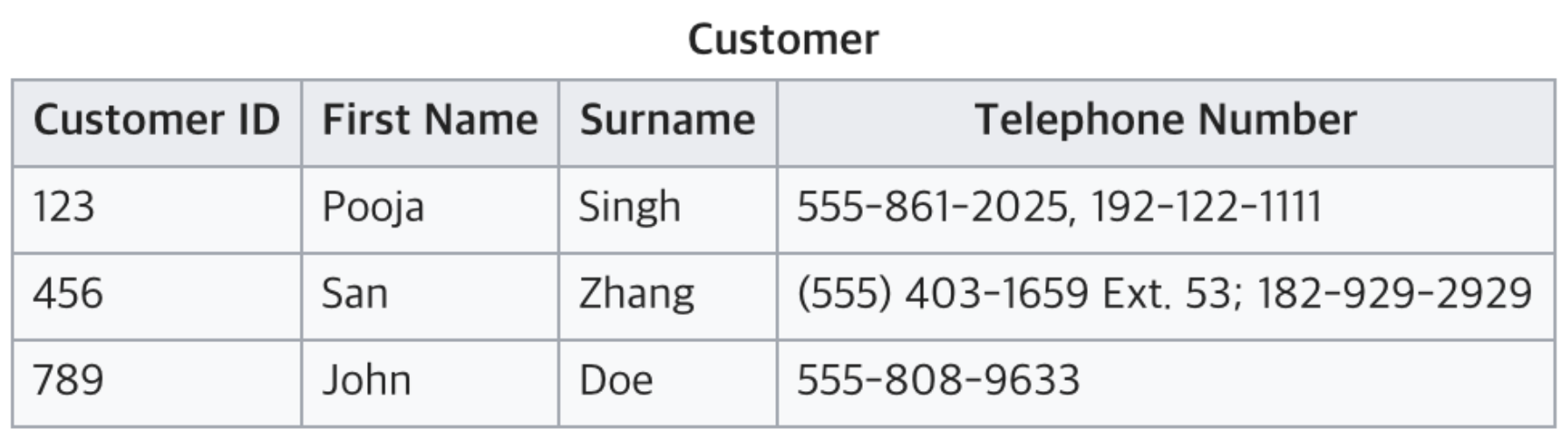
정규화 되지 않은 상태
아무런 가공이 되지 않은 Data 형태
정규화 되지 않은 상태: 전화번호를 보면 하나의 셀에 다른 종류의 값 여러개가 들어가 있어요
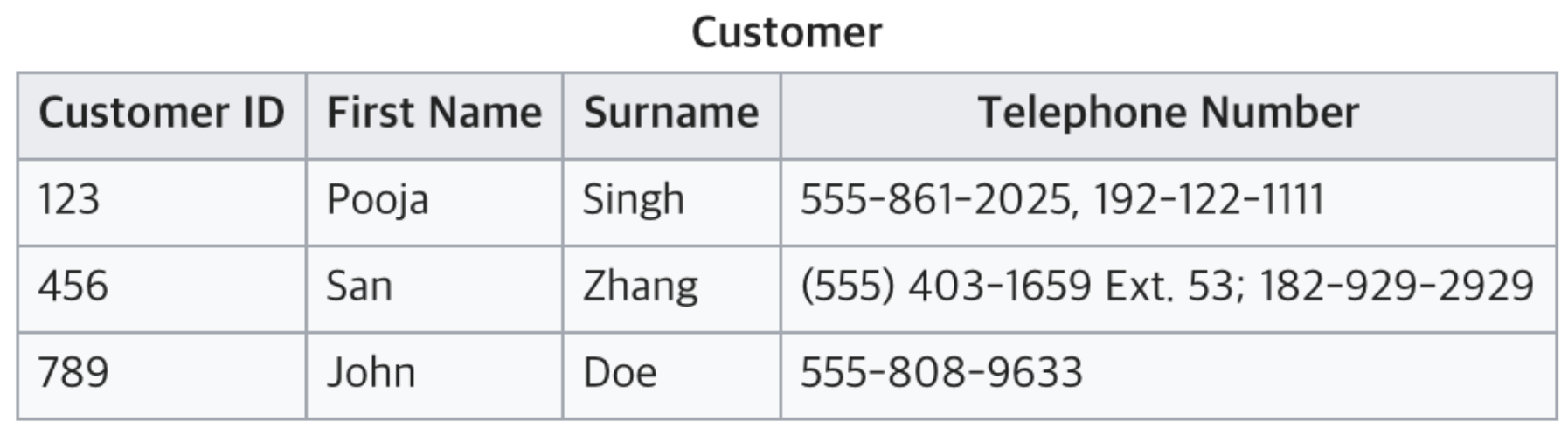
1개씩 갖을 수 있도록 나눠볼까? 하지만 전화번호 100개를 쓰는 사람에게는 대응할 수 없을 것 같아요
전화번호 100개를 가진 사람을 등록하려면
Column을 100개 만드는 거에요, 다른사람의 Column 99개는 비어있겠네요 -> 비효율적이에요
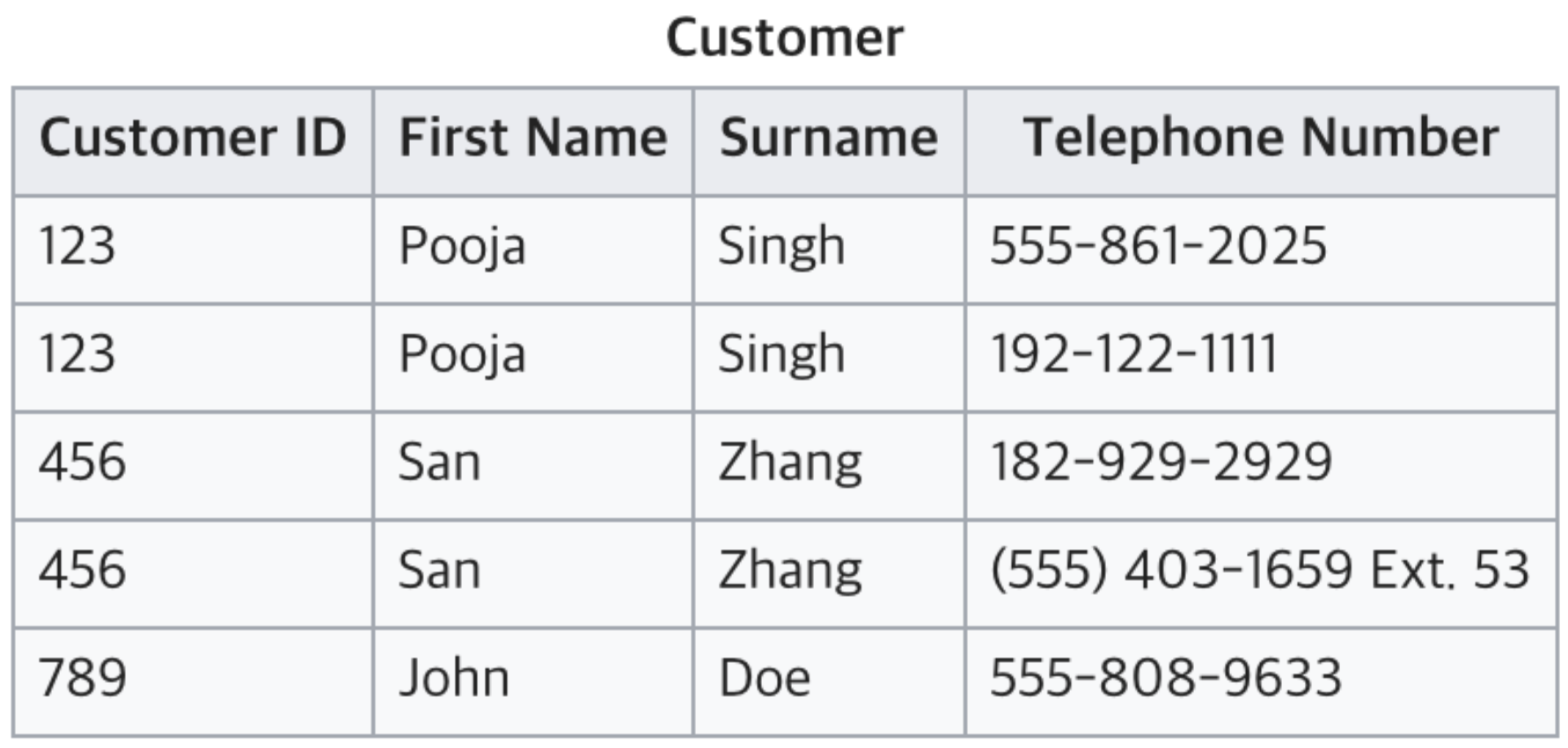
제 1정규형
제 1정규화로 나온 상태
repeating group이 제거된 상태를 말해요
Repeating group이 있는 상태
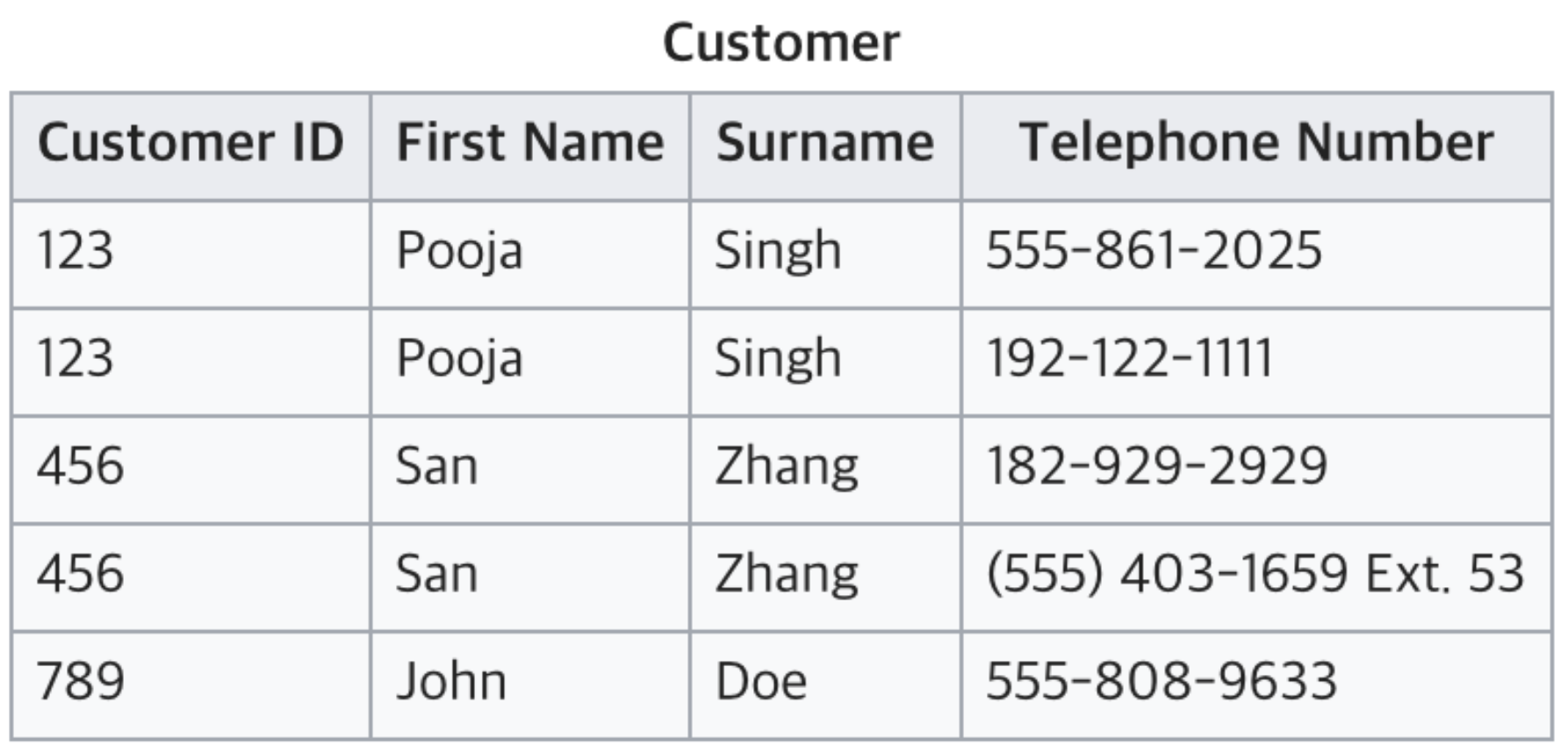
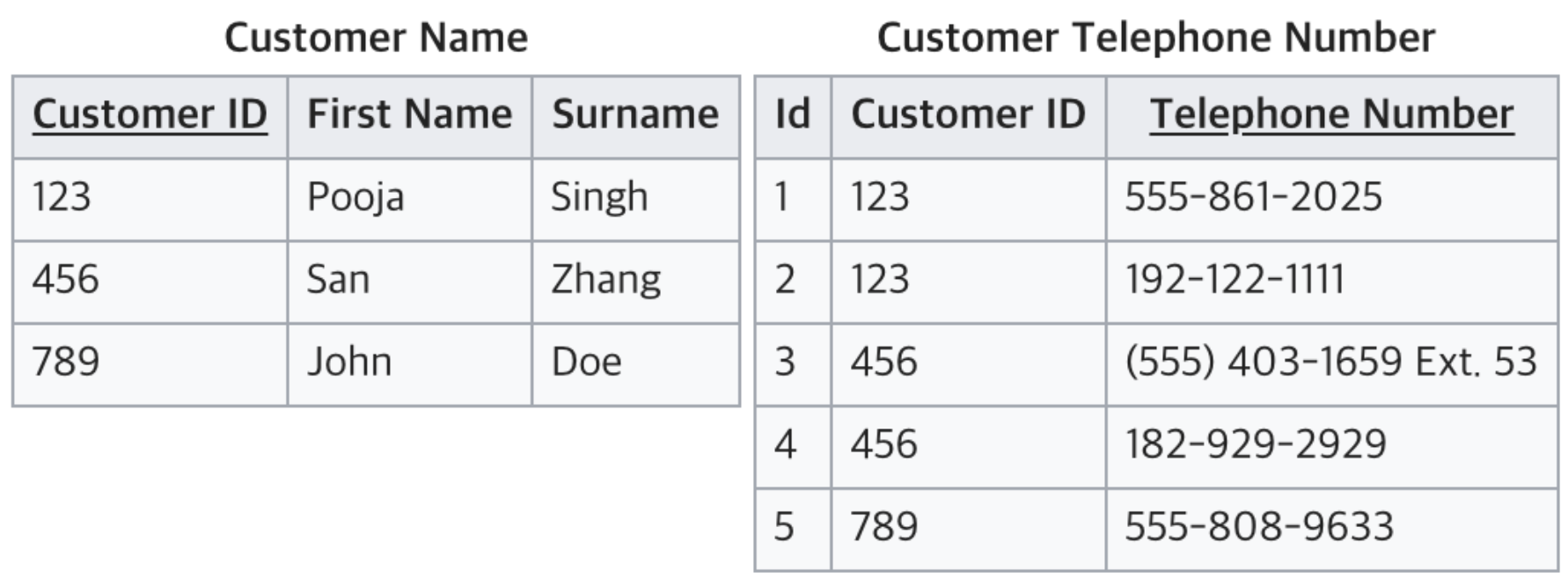
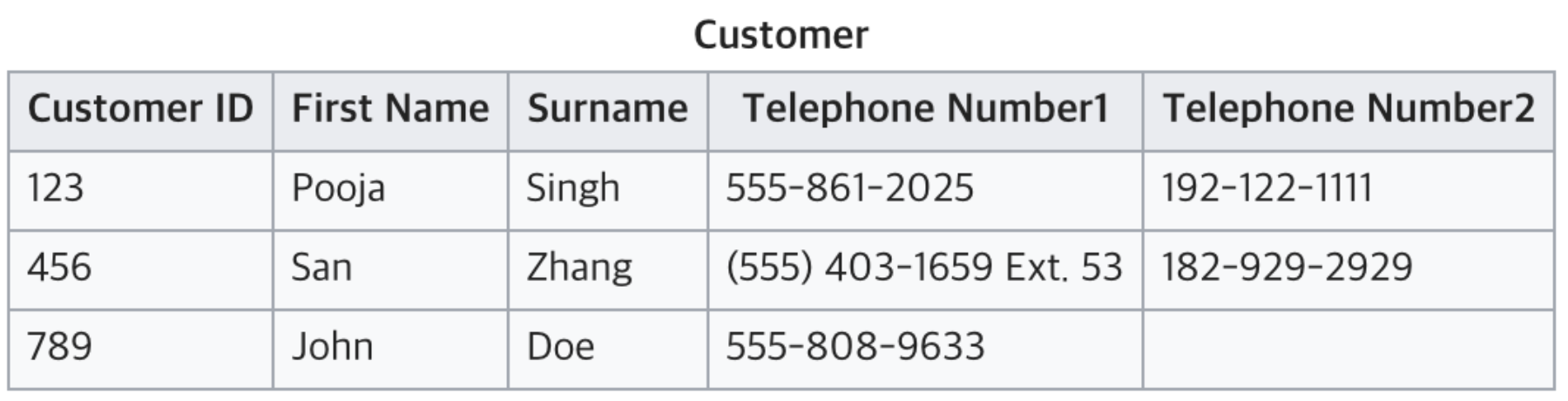
제1 정규화가 진행되었어요.
다만, Telephone Number는 의미가 있기 때문에 식별자로는
적당하지 않아요. Primary key로는 Id를 사용하는게 좋겠네요
제 2정규형
제 2정규화로 나온 상태
복합 UID에 대한 부분 종속 제거
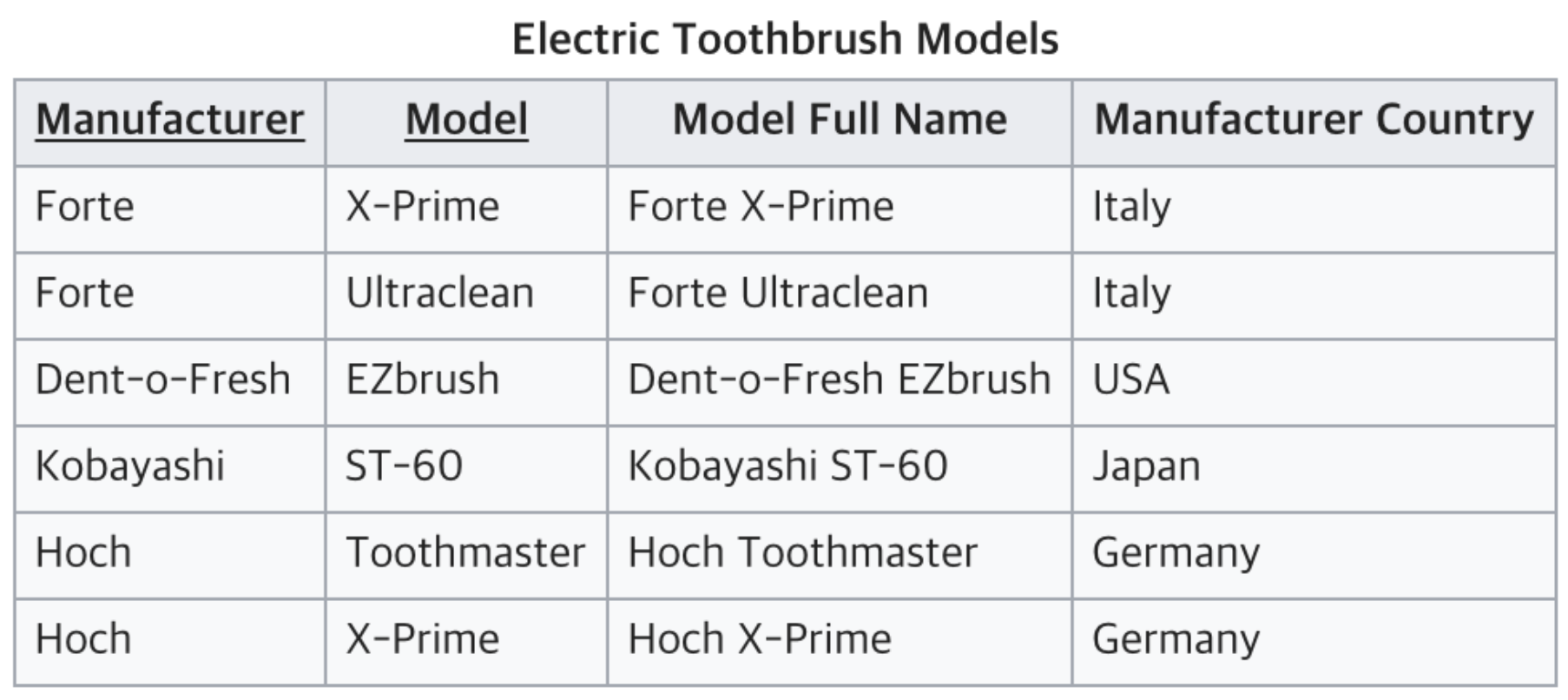
이러한 테이블이 있어요
지금 Model Full Name은 Manufacturer 및 Model 2가지와 모두 관련이 있어요.
Manufacturer Country는 Manufacturer하고만 관련이 있잖아요? Column을 분리해줘야 겠죠
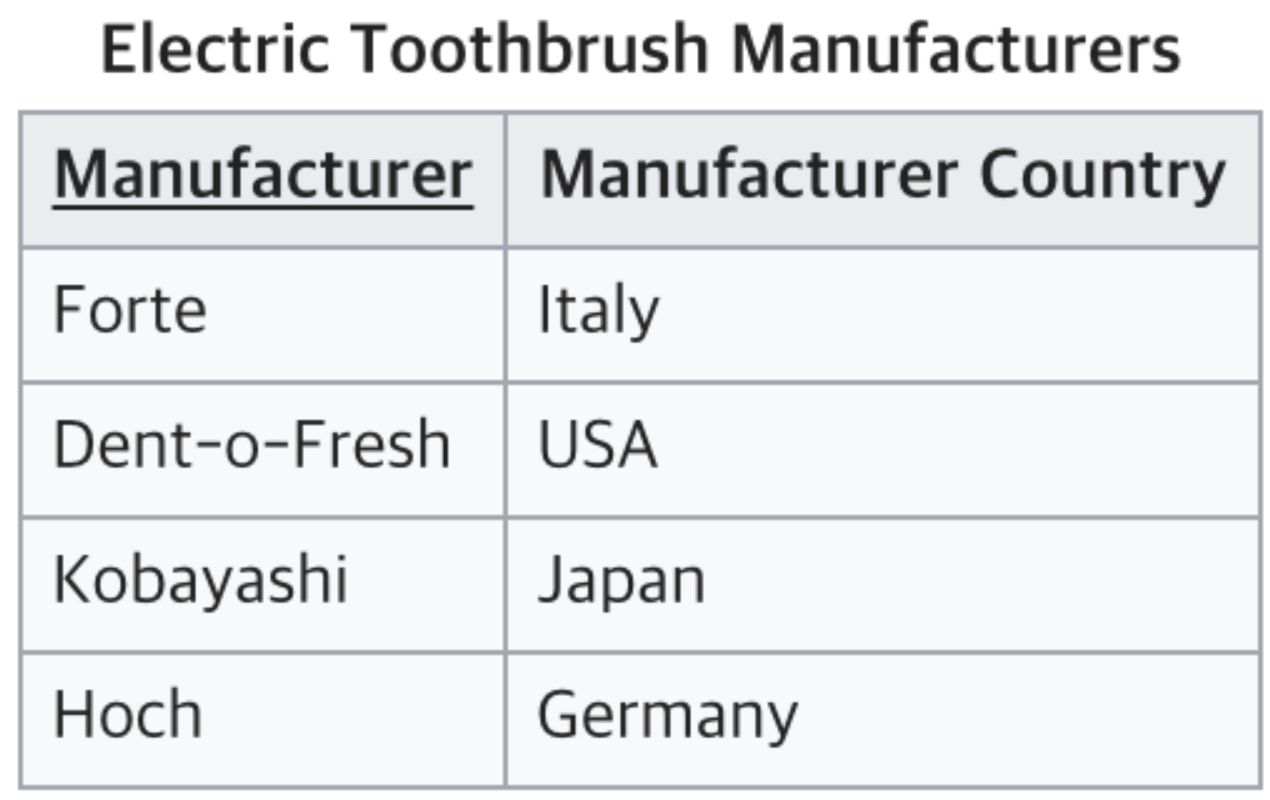
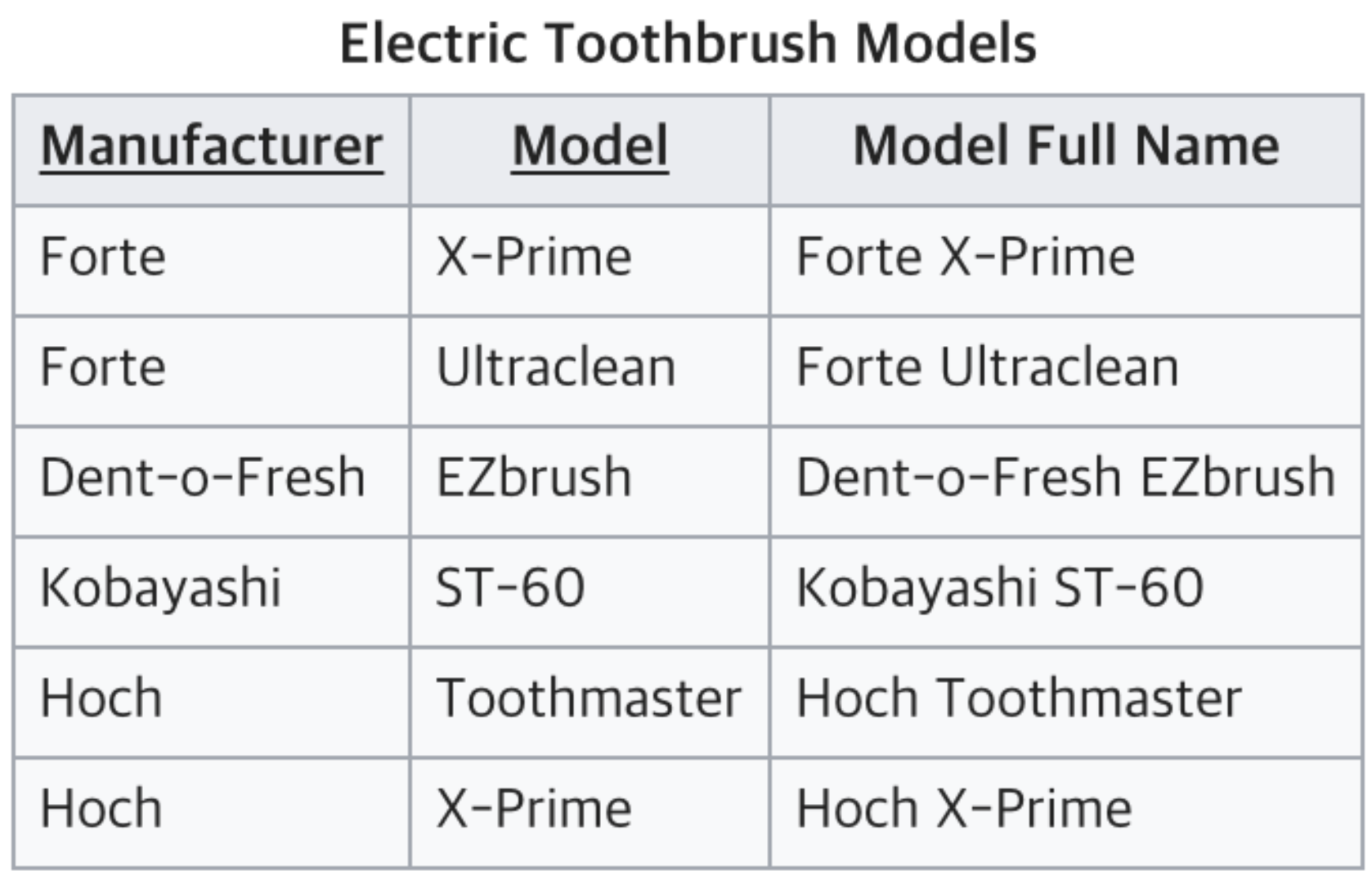
복합 UID에 대한
제 3정규형
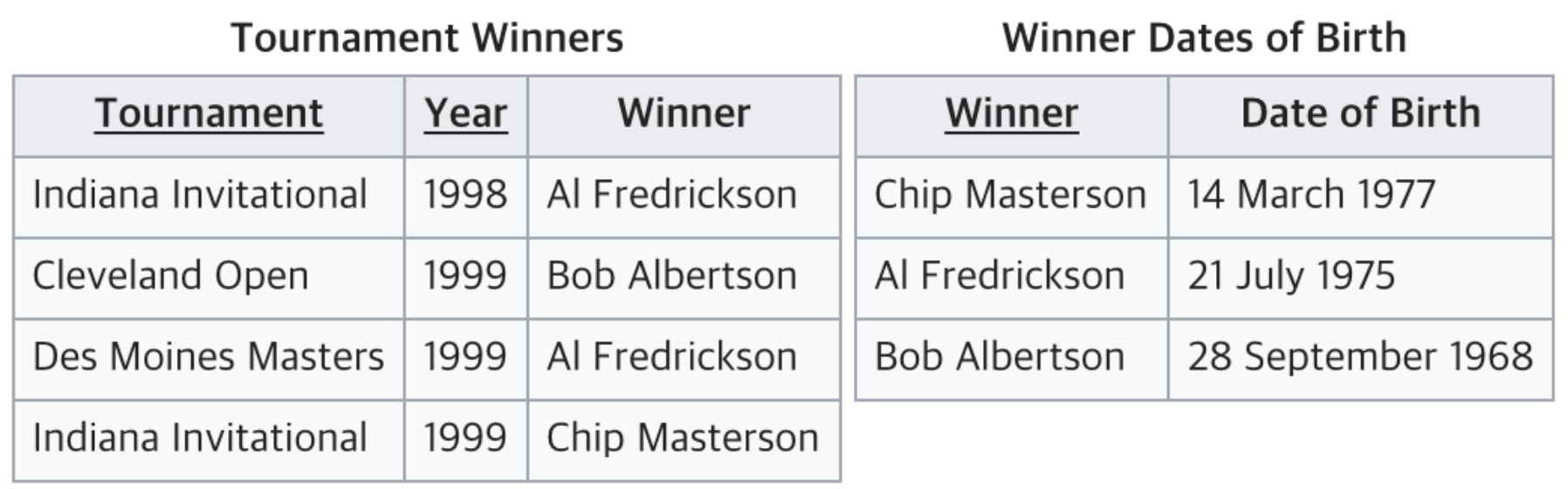
제 3정규화로 나온 상태
Non-UID에 대한 종속 제거
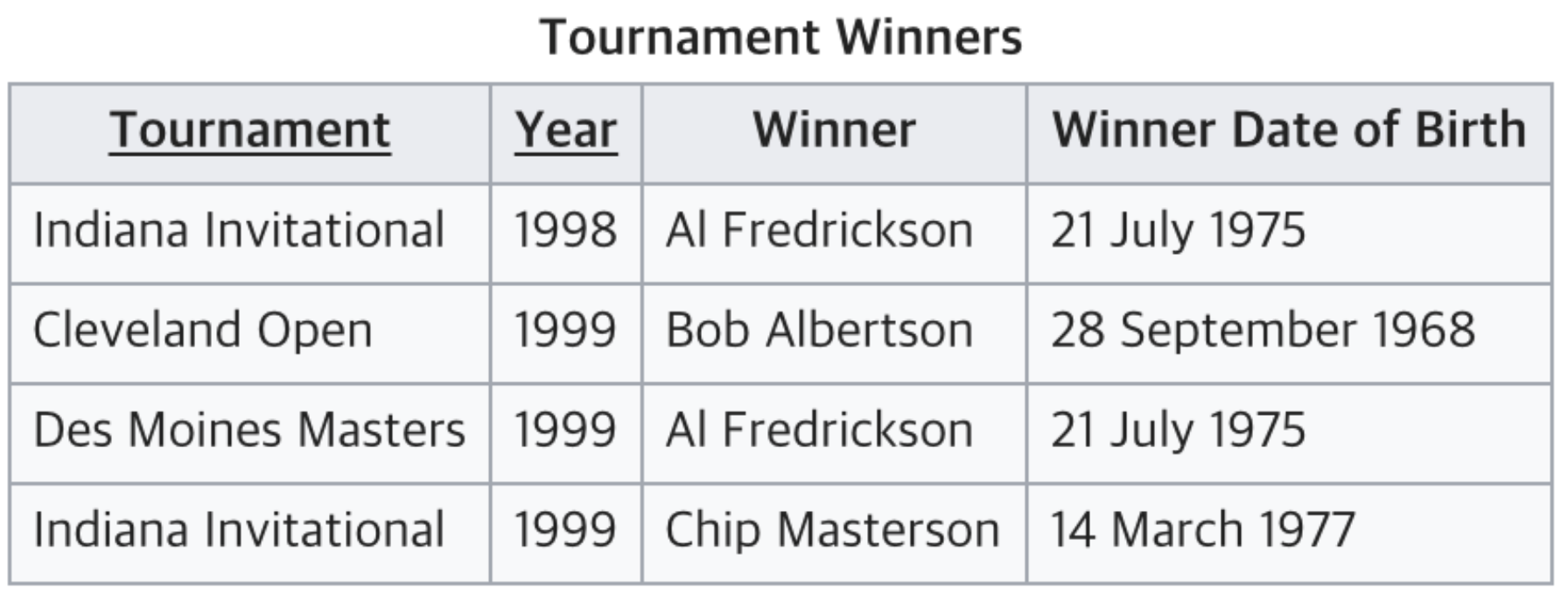
제3 정규형 위반 예시
제3 정규형 충족
UID가 아닌 애들끼리의 UID의 함수적 종속성이 있느냐
반정규화
1, 2, 3정규화를 진행한 이후에, 필요할 경우에 한하여 반 정규화를 진행할 수 있습니다.
반정규화는 특정한 원칙은 없습니다.
원칙에 집착하지만, 원칙에 구애받지 않아요 - 반정규화
식별자(Identifier)
고유하게 식별할 수 있는 이름
Table을 만들 때, 식별자를 만드는 것이 매우 중요합니다.
우리는 보통 인공 식별키를 만들어서 식별자로 만듭니다. 모두 장단이 있는 것이에오
보통 아무 의미를 갖지 않는것을 식별자로 잡는것이 좋습니다.
그 이유는 나중에 FK등을 타고 다른 table의 column으로 이동할 수 있어요.
meaning이 있다면 학과 통폐합같은 일이 일어나면 문제가 생길 수 잇어요
DB설계를 잘 하기 위한 keyword
DBMS, 식별자, 정규화, 반정규화, 데이터 무결성
PK: 새로 들어온 키가 내가 가져온 키와 비교해서 없으면 값을 허락합니다.
FK:새로 값이 들어올 때 상대방 Column에 값이 있으면 값을 허락하고, 아니면 거절합니다.
spring framework
solid
정규화
AOP
Beans
ORM
