Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution 리뷰
Paper(논문)
목록 보기
1/1
Qwen2-VL: Enhancing Vision-Language Model’s Perception
of the World at Any Resolution
Abstract
- Qwen2-VL 시리즈는 Qwen-VL 모델의 고도화된 업그레이드임
- 기존의 고정된 해상도 방식을 재정의함
- Qwen2-VL은 Naive Dynamic Resolution mechanism을 도입하여 다양한 해상도의 이미지를 동적으로 처리하고 이를 여러 개의 visual token으로 변환할 수 있게 함
- Naive Dynamic Resolution mechanism은 더 효율적이고 정확한 시각적 표현을 생성하여, 인간의 지각 과정과 유사한 방식으로 작동함
- Multimodal Rotary Position Embedding (M-RoPE)을 통합하여 텍스트, 이미지, 비디오의 위치 정보를 효과적으로 융합함
- 이미지와 비디오를 처리하는 통합 패러다임을 사용하여 모델의 시각 인식 능력을 향상시킴
- Qwen2-VL은 대규모 비전-언어 모델(LVLMs)의 스케일링 법칙을 연구함
- Qwen2-VL 시리즈는 2B, 8B, 72B 파라미터 버전으로 모델 크기와 학습 데이터 양을 확장함으로써 경쟁력 있는 성능을 달성함
- Qwen2-VL-72B 모델은 GPT-4o, Claude3.5-Sonnet과 유사한 성과를 내며, 다양한 멀티모달 벤치마크에서 다른 일반 모델을 능가함
- 코드는 https://github.com/QwenLM/Qwen2-VL에서 제공됨
Introduction
- 인공지능 분야에서 대규모 비전-언어 모델(LVLMs)은 전통적인 대형 언어 모델의 강력한 텍스트 처리 능력을 기반으로 한 큰 도약을 의미함
- 이러한 고급 모델들은 이제 이미지, 오디오, 비디오를 포함한 더 넓은 범위의 데이터를 해석하고 분석할 수 있는 능력을 포함하게 되었음
- 이러한 능력 확장은 LVLMs를 다양한 현실 문제를 해결하는 데 필수적인 도구로 변모시켰음
- LVLMs는 방대한 양의 복잡한 지식을 기능적 표현으로 응축할 수 있는 독특한 능력으로 인정받고 있음
- LVLMs는 다양한 데이터 형태를 통합함으로써 인간이 환경을 인식하고 상호작용하는 미묘한 방식을 더 가깝게 모방하고자 함
- 이를 통해 이러한 모델들은 우리가 환경과 상호작용하고 이를 인식하는 방식을 보다 정확하게 표현할 수 있음
- 최근 대규모 비전-언어 모델(LVLMs)의 발전은 짧은 기간 동안 상당한 성과를 거둠 (Li et al., 2023c; Liu et al., 2023b; Dai et al., 2023; Zhu et al., 2023; Huang et al., 2023a; Bai et al., 2023b; Liu et al., 2023a; Wang et al., 2023b; OpenAI, 2023; Team et al., 2023).
- 이들 모델은 일반적으로 비주얼 인코더 → 크로스 모달 커넥터 → LLM의 공통 접근 방식을 따름 (OpenAI, 2023; Touvron et al., 2023a,b; Chiang et al., 2023; Bai et al., 2023a).
- 이러한 설정은 다음 토큰 예측을 주요 학습 방법으로 하고, 고품질 데이터셋의 사용과 결합되어 발전을 이끌어 냄 (Liu et al., 2023a; Zhang et al., 2023; Chen et al., 2023b; Li et al., 2023b).
- 또한, 더 큰 모델 구조 (Alayrac et al., 2022), 고해상도 이미지 (Li et al., 2023a,d), 전문가 혼합 모델(MoE) (Wang et al., 2023b; Ye et al., 2023b), 모델 앙상블 (Lin et al., 2023), 그리고 시각적-텍스트적 연결을 위한 정교한 커넥터 (Ye et al., 2023a)와 같은 고급 기법들이 LVLM의 복잡한 시각 및 텍스트 정보 처리 능력을 향상시키는 데 중요한 역할을 함.
- 그러나 현재의 LVLM은 일반적으로 고정된 이미지 입력 크기 제약을 받음. 표준 LVLM은 입력 이미지를 고정된 해상도로 인코딩하며(예: 224×224), 종종 다운샘플링 또는 업샘플링 방식으로 처리하거나 스케일-패딩 방식을 사용함 (Zhu et al., 2023; Huang et al., 2023a; Liu et al., 2023b,a).
- 이러한 일관된 해상도 처리 방식은 모델이 일관된 해상도로 이미지를 처리할 수 있게 하지만, 다양한 스케일의 정보를 포착하는 데 한계가 있으며 특히 고해상도 이미지에서 세부 정보가 많이 손실되는 문제가 발생함. 그 결과, 이러한 모델들은 인간의 시각만큼 세밀하게 정보를 인식하지 못함.
- 또한 대부분의 LVLM은 CLIP 스타일의 고정된 비전 인코더를 사용함(Radford et al., 2021). 이는 복잡한 추론 작업이나 이미지 내 세부 사항 처리에 있어 미리 학습된 모델이 생성한 시각적 표현이 충분한지에 대한 의문을 제기함.
- 최근 연구(Bai et al., 2023b; Ye et al., 2023a)는 LVLM 학습 과정에서 비전 트랜스포머(ViT)를 미세 조정하여 이러한 한계를 해결하려고 시도했으며, 이를 통해 성능 향상을 보임.
- 모델의 해상도 변화에 대한 적응력을 더욱 향상시키기 위해 LVLM 학습 과정에 동적 해상도 학습을 도입함. 특히, ViT에 2D 회전 위치 임베딩(RoPE)을 사용하여 모델이 다양한 공간적 스케일에서 정보를 더 잘 포착할 수 있게 함.
- 비디오 콘텐츠는 기본적으로 연속된 프레임으로 구성되는데, 많은 기존 모델들은 이를 독립적인 모달리티로 취급함
- 그러나 현실의 동적인 특성을 이해하는 것은 모델이 실제 세계의 복잡성을 파악하는 데 매우 중요함
- 텍스트는 본질적으로 1차원이지만, 실제 세계 환경은 3차원으로 존재함
- 현재 모델에서 사용하는 1차원 위치 임베딩은 3차원 공간과 시간적 역동성을 효과적으로 모델링하는 데 한계가 있음
- 이러한 한계를 극복하기 위해, Multimodal Rotary Position Embedding (M-RoPE)을 개발했으며, 시간적 정보와 공간적 정보를 별도의 구성 요소로 표현함
- 이를 통해 모델은 비디오나 스트리밍 데이터와 같은 동적인 콘텐츠를 자연스럽게 이해할 수 있으며, 실제 세계를 더 잘 이해하고 상호작용할 수 있음
- 또한, 대규모 언어 모델(LLMs)의 스케일링과 비교했을 때, 현재의 대형 비전-언어 모델(LVLMs)은 학습 데이터와 모델 파라미터 측면에서 스케일링의 영향을 탐구하는 초기 단계에 있음
- LVLMs의 스케일링 법칙, 즉 모델과 데이터 크기의 증가가 성능에 미치는 영향을 탐구하는 것은 여전히 개방된 연구 분야로, 매우 유망함
- 이번 연구에서는 Qwen 계열의 최신 대형 비전-언어 모델인 Qwen2-VL 시리즈를 소개함. 이 시리즈는 2B, 8B, 72B의 파라미터를 가진 세 가지 공개 가중치 모델로 구성됨
- Qwen2-VL의 주요 발전 사항은 다음과 같음:
- 다양한 해상도와 종횡비에 걸친 높은 이해력: Qwen2-VL은 DocVQA, InfoVQA, RealWorldQA, MTVQA, MathVista 등의 시각적 벤치마크에서 선도적인 성능을 달성함
- 20분 이상의 확장된 길이의 비디오 이해: Qwen2-VL은 20분 이상의 비디오를 이해할 수 있으며, 이를 통해 고품질의 비디오 기반 질의응답, 대화, 콘텐츠 생성 등을 수행할 수 있음
- 기기 운영을 위한 강력한 에이전트 능력: Qwen2-VL은 고급 추론 및 의사결정 능력을 통해 모바일폰, 로봇 등과 같은 기기와 통합되어 시각 입력과 텍스트 지시에 따라 자율적으로 작동할 수 있음
- 다국어 지원: 글로벌 사용자층을 위해 영어와 중국어뿐만 아니라 대부분의 유럽어, 일본어, 한국어, 아랍어, 베트남어 등을 포함한 이미지 내 다국어 맥락 이해를 지원함
Approach
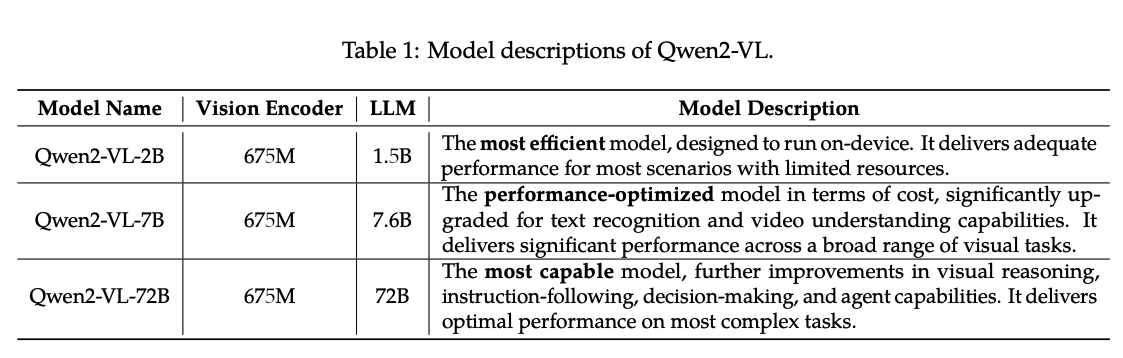
- Qwen2-VL 시리즈는 3가지 크기의 모델로 구성되어 있으며, 각각 Qwen2-VL-2B, Qwen2-VL-7B, Qwen2-VL-72B임
- 표 1에는 하이퍼파라미터와 중요한 정보들이 나열되어 있음
- 특히 Qwen2-VL은 다양한 크기의 LLM에서 675M 파라미터를 가진 ViT(Vision Transformer)를 사용하여, LLM의 규모와 상관없이 ViT의 연산 부담을 일정하게 유지함
2.1 Model Architecture
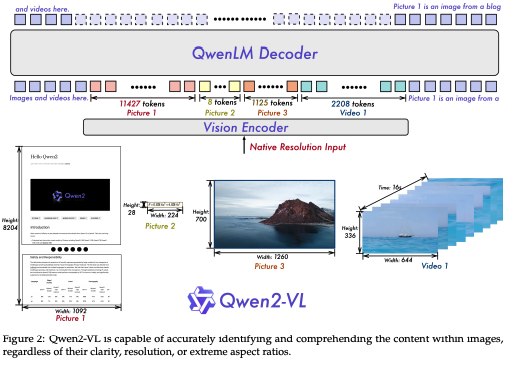
- 그림 2는 Qwen2-VL의 전체 구조를 보여줌
- Qwen-VL(Bai et al., 2023b)의 프레임워크를 유지했으며, 이는 비전 인코더와 언어 모델을 통합함
- 다양한 규모의 적응을 위해 약 6억 7,500만 개의 파라미터를 가진 Vision Transformer(ViT)(Dosovitskiy et al., 2021)를 구현하여 이미지와 비디오 입력을 처리함
- 언어 처리 측면에서는 더 강력한 Qwen2(Yang et al., 2024) 시리즈 언어 모델을 선택함
- 모델의 비디오에서 시각 정보를 효과적으로 인식하고 이해하는 능력을 더욱 향상시키기 위해 몇 가지 주요 업그레이드를 도입함
- Naive Dynamic Resolution
- Qwen2-VL에서의 주요 구조적 개선 중 하나는 Naive Dynamic Resolution 지원을 도입한 것임(Dehghani et al., 2024)
- 이전 버전과 달리 Qwen2-VL은 이제 해상도에 상관없이 이미지를 처리할 수 있으며, 이를 가변적인 수의 시각 토큰으로 동적으로 변환함
- 이 기능을 지원하기 위해, ViT의 원래 절대 위치 임베딩을 제거하고 2차원 위치 정보를 캡처하기 위해 2D-RoPE(Su et al., 2024; Su, 2021)를 도입함
- 추론 단계에서는 다양한 해상도의 이미지가 단일 시퀀스로 묶여 처리되며, 이 시퀀스 길이는 GPU 메모리 사용을 제한하도록 제어됨
- 또한 각 이미지의 시각 토큰 수를 줄이기 위해, ViT 이후 간단한 MLP 레이어를 사용하여 인접한 2 × 2 토큰을 하나의 토큰으로 압축하며, <|vision_start|> 및 <|vision_end|> 토큰은 압축된 시각 토큰의 시작과 끝에 배치됨
- 결과적으로, 224 × 224 해상도의 이미지는 patch_size=14를 사용하는 ViT에 의해 인코딩된 후 LLM에 들어가기 전에 66개의 토큰으로 압축됨

Multimodal Rotary Position Embedding (M-RoPE)
- 또 다른 주요 구조적 개선점은 Multimodal Rotary Position Embedding (M-RoPE)의 혁신임
- 기존 LLM에서 사용하는 1D-RoPE는 1차원의 위치 정보만 인코딩할 수 있는 반면, M-RoPE는 멀티모달 입력의 위치 정보를 효과적으로 모델링함
- M-RoPE는 원래의 로터리 임베딩을 세 가지 구성 요소(시간, 높이, 너비)로 분해하여 이 작업을 수행함
- 텍스트 입력의 경우, 이 세 가지 구성 요소는 동일한 위치 ID를 사용하여 M-RoPE는 기능적으로 1D-RoPE와 동일하게 작동함 (Su, 2024)
- 이미지 처리 시, 각 시각적 토큰의 시간 ID는 일정하게 유지되며, 높이와 너비 구성 요소에는 이미지 내 토큰의 위치에 따라 서로 다른 ID가 할당됨
- 비디오의 경우, 프레임 시퀀스로 처리되며, 각 프레임마다 시간 ID가 증가하고 높이와 너비 구성 요소는 이미지와 동일한 ID 할당 방식을 따름
- 모델의 입력이 여러 모달리티를 포함하는 경우, 각 모달리티의 위치 번호는 이전 모달리티의 최대 위치 ID에 1을 더한 값으로 초기화됨
- M-RoPE의 예시는 그림 3에 나와 있으며, 이는 위치 정보 모델링을 강화할 뿐만 아니라 이미지와 비디오의 위치 ID 값을 줄여, 추론 시 더 긴 시퀀스로 extrapolate(확장)할 수 있게 함
- Qwen2-VL은 이미지와 비디오 데이터를 혼합하여 학습하여, 이미지 이해와 비디오 해석 능력을 모두 보장함
- 비디오 정보를 가능한 한 완전히 보존하기 위해, 초당 2프레임으로 비디오를 샘플링함
- 또한, 3D 컨볼루션(3D convolutions)을 통합하여 비디오 입력을 처리하며, 2D 패치 대신 3D 튜브를 처리할 수 있도록 함으로써 시퀀스 길이를 늘리지 않고도 더 많은 비디오 프레임을 처리할 수 있게 함
- 일관성을 유지하기 위해, 각 이미지는 두 개의 동일한 프레임으로 처리됨
- 긴 비디오를 처리하는 데 필요한 계산 요구량과 전반적인 학습 효율성의 균형을 맞추기 위해, 각 비디오 프레임의 해상도를 동적으로 조정하여, 비디오당 토큰 수를 16384로 제한함
- 이러한 학습 방식은 모델이 긴 비디오를 이해하는 능력과 학습 효율성 간의 균형을 맞춤
Training
- Qwen2-VL은 Qwen-VL (Bai et al., 2023b)을 기반으로 한 3단계 훈련 방법론을 채택함
- 첫 번째 단계에서는 Vision Transformer (ViT) 컴포넌트의 학습에 집중하며, 방대한 이미지-텍스트 쌍 데이터셋을 사용해 대형 언어 모델(LLM)의 의미적 이해를 향상시킴
- 두 번째 단계에서는 모든 파라미터를 해제하고 더 다양한 데이터로 더 포괄적인 학습을 진행함
- 마지막 단계에서는 ViT 파라미터를 고정하고, LLM을 교육용 데이터셋으로 독점적으로 미세 조정함
- 모델은 이미지-텍스트 쌍, OCR 데이터, 이미지-텍스트가 혼합된 기사, 시각적 질문 응답 데이터셋, 비디오 대화 및 이미지 지식 데이터셋을 포함한 다양한 데이터셋으로 사전 학습됨
- 데이터는 주로 정리된 웹 페이지, 오픈 소스 데이터셋 및 합성 데이터를 포함하며, 지식 데이터의 기준일은 2023년 6월임
- 이러한 다양한 데이터 구성은 강력한 멀티모달 이해 능력을 개발하는 데 중요한 역할을 함
- 초기 사전 학습 단계에서 Qwen2-VL은 약 6000억 개의 토큰을 학습함
- Qwen2-VL의 LLM 컴포넌트는 Qwen2 (Yang et al., 2024)의 파라미터로 초기화되고, 비전 인코더는 DFN에서 파생된 ViT로 초기화됨
- 단, 원래 DFN의 ViT에 있던 고정 위치 임베딩은 RoPE-2D로 교체됨
- 이 사전 학습 단계는 이미지-텍스트 관계 학습, OCR을 통한 이미지 내 텍스트 인식, 이미지 분류 작업을 주로 다룸
- 두 번째 사전 학습 단계에서는 8000억 개의 추가 토큰이 포함된 이미지 관련 데이터를 학습함
- 이 단계는 더 많은 혼합 이미지-텍스트 콘텐츠를 도입하여 시각적 정보와 텍스트 정보 간의 상호작용을 더 세밀하게 이해할 수 있도록 함
- 시각적 질문 응답 데이터셋이 포함되어 모델이 이미지 관련 질문에 응답할 수 있는 능력을 향상시킴
- 멀티태스킹 데이터셋도 포함되어, 모델이 다양한 작업을 동시에 처리할 수 있는 능력을 개발하는 데 중요한 역할을 함
- 순수 텍스트 데이터도 모델의 언어적 능력을 유지하고 발전시키는 데 중요한 역할을 함
- 사전 학습 과정에서 Qwen2-VL은 총 1.4조 개의 토큰을 처리하며, 이 토큰에는 텍스트 토큰뿐만 아니라 이미지 토큰도 포함됨
- 훈련 과정에서는 텍스트 토큰에 대해서만 감독이 제공됨
- 사전 학습 단계에서의 방대한 텍스트 및 시각적 데이터는 모델이 시각적 정보와 텍스트 정보 간의 복잡한 관계를 깊이 이해할 수 있도록 하며, 다양한 멀티모달 작업을 위한 탄탄한 기반을 마련함
- 교육용 미세 조정 단계에서는 ChatML (OpenAI, 2024) 형식을 사용하여 명령을 따르는 데이터를 구성함
- 이 데이터셋은 순수 텍스트 기반 대화 데이터뿐만 아니라 멀티모달 대화 데이터를 포함함
- 멀티모달 구성 요소는 이미지 질문-응답, 문서 파싱, 다중 이미지 비교, 비디오 이해, 비디오 스트림 대화 및 에이전트 기반 상호작용을 포함함
- 다양한 데이터 유형을 포함한 포괄적인 접근 방식을 통해, 여러 모달리티에 걸친 명령을 이해하고 실행하는 능력을 강화하고자 함
- 이를 통해 전통적인 텍스트 기반 상호작용뿐만 아니라 복잡한 멀티모달 작업도 처리할 수 있는 보다 다재다능하고 강력한 언어 모델을 개발하는 것이 목표임
2.2.1 Data Format
- Qwen-VL과 마찬가지로, Qwen2-VL도 비전(vision)과 텍스트 입력을 구분하기 위해 특수 토큰을 사용함
- <|vision_start|>와 <|vision_end|> 토큰은 이미지 특징 시퀀스의 시작과 끝에 삽입되어 이미지 콘텐츠를 구분함
Dialogue Data
- 대화 형식 측면에서, 우리는 ChatML 형식을 사용하여 인스트럭션 튜닝 데이터셋을 구축함. 각 상호작용의 진술은 두 개의 특수 토큰 (<|im_start|>와 <|im_end|>)으로 표시되어 대화 종료를 용이하게 함
- 파란색으로 표시된 부분은 지도 학습된 부분을 나타냄


Visual Grounding
- 모델에 시각적 그라운딩 기능을 부여하기 위해, 바운딩 박스 좌표는 [0, 1000) 범위로 정규화되고, "(X왼쪽 위, Y왼쪽 위),(X오른쪽 아래, Y오른쪽 아래)"로 표현됨
- <|box_start|>와 <|box_end|> 토큰은 바운딩 박스 텍스트를 구분하는 데 사용됨
- 바운딩 박스와 텍스트 설명을 정확하게 연결하기 위해 <|object_ref_start|>와 <|object_ref_end|> 토큰을 도입하여 바운딩 박스가 참조하는 내용을 표시함. 이를 통해 모델은 특정 영역에 대한 정확한 설명을 효과적으로 해석하고 생성할 수 있음
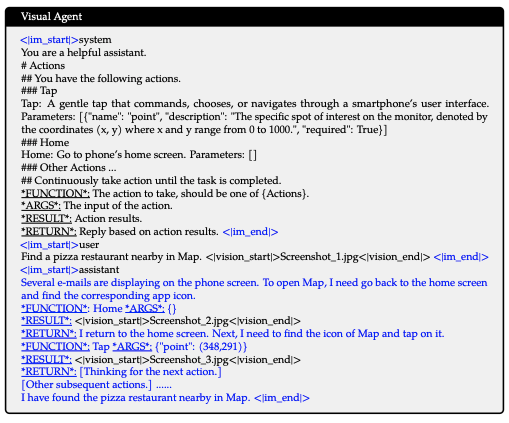
Visual Agent
- Qwen2-VL을 범용 비전-언어 에이전트(VL-Agent)로 개발하기 위해, UI 작업, 로봇 제어, 게임, 네비게이션과 같은 다양한 에이전트 작업을 순차적 의사결정 문제로 다룸
- 이를 통해 Qwen2-VL은 다단계 행동 실행을 통해 작업을 수행할 수 있게 됨
- 각 작업에 대해 허용 가능한 작업 세트와 함수 호출을 위한 키워드 패턴(밑줄 표시)을 정의함(Qwen 팀, 2024)
- Qwen2-VL은 관찰을 분석하고, 추론 및 계획을 수행한 후 선택한 작업을 실행하고, 환경과 상호작용하여 새로운 관찰을 획득함. 이 사이클은 작업이 성공적으로 완료될 때까지 반복됨
- 다양한 도구를 통합하고 대규모 비전-언어 모델(LVLMs)의 시각 인식 능력을 활용함으로써, Qwen2-VL은 실제 시각적 상호작용이 포함된 점점 더 복잡한 작업을 반복적으로 실행할 수 있음
2.3 Multimodal Model Infrastructure
- Qwen2-VL 모델들은 알리바바 클라우드의 PAI-Lingjun 인텔리전트 컴퓨팅 서비스(Alibaba Cloud, 2024c)에서 확장 가능한 컴퓨팅, 자동 복구, 지연 탐지 기능을 사용하여 훈련됨.
- 스토리지: Qwen2-VL 사전 훈련 및 후속 훈련을 위한 스토리지 시스템은 알리바바 클라우드의 초고속 CPFS(Cloud Parallel File Storage) (Alibaba Cloud, 2024a)를 사용함. 텍스트 데이터와 비전 데이터를 분리하여 저장함. 텍스트 데이터는 CPFS에 저장하고 mmap을 사용해 효율적으로 접근하며, 비전 데이터는 알리바바 클라우드의 OSS(Object Storage Service) (Alibaba Cloud, 2024b)를 통해 지속적으로 저장함. 훈련 중에는 Python 클라이언트를 통해 OSS에서 비전 데이터를 동시 접근하며, QPS(queries per second) 제한을 피하기 위해 동시성 및 재시도 매개변수를 조정함. 비디오 데이터의 디코딩이 주요 병목현상임을 확인했으며, 특히 긴 비디오에서 문제가 발생함. 여러 차례의 오픈소스(FFmpeg-Developers, 2024) 및 내부 소프트웨어 시도가 실패한 후, 캐싱 디코딩 기술을 사용함. 체크포인팅을 통해 각 GPU의 옵티마이저와 모델 상태를 CPFS에 저장함.
- 병렬성: Qwen2-VL 모델 훈련을 확장하기 위해 데이터 병렬성(DP) (Li et al., 2020), 텐서 병렬성(TP) (Krizhevsky et al., 2012; Shoeybi et al., 2019), 파이프라인 병렬성(PP) (Huang et al., 2019; Narayanan et al., 2021; Lamy-Poirier, 2023)을 결합한 3D 병렬성을 사용함. 또한 메모리 절약을 위해 deepspeed의 zero-1 redundancy 옵티마이저(Rajbhandari et al., 2020)를 사용해 상태를 분할함. 메모리 사용을 줄이기 위해 선택적 체크포인팅 활성화(Chen et al., 2016)와 함께 시퀀스 병렬성(SP) (Korthikanti et al., 2023)을 사용함. TP 훈련을 활성화할 때는 항상 비전 인코더와 대형 언어 모델을 함께 샤딩하지만, 상대적으로 적은 파라미터를 가진 비전 병합기는 샤딩하지 않음. TP 훈련은 컨볼루션 연산자의 비결정적 동작으로 인해 모델의 공유 가중치가 달라지는 결과를 초래했으며, 우리는 이 문제를 공유 가중치를 오프라인으로 줄이는 방식으로 해결하여 추가적인 all-reduce 통신 단계를 피함. 이 접근 방식은 성능에 거의 영향을 미치지 않음.
- Qwen2-VL 72B 훈련을 위해 1F1B PP(Narayanan et al., 2021)를 활용함. 비전 인코더, 비전 어댑터 및 LLM의 몇 가지 디코더 레이어를 하나의 단계로 결합하고, 나머지 디코더 레이어를 균등하게 분할함. 데이터 포인트마다 비전과 텍스트 시퀀스 길이가 동적임. 1F1B 프로세스를 시작하기 전에 동적 시퀀스 길이를 브로드캐스트하고 배치 인덱스를 사용하여 형상 정보를 접근함. 또한 인터리브드 1F1B PP(Narayanan et al., 2021)를 구현했으나 표준 1F1B 설정보다 느리다는 것을 확인함.
- 소프트웨어: 훈련을 위해 PyTorch(Paszke et al., 2019; Ansel et al., 2024) 2.1.2 버전과 CUDA 11.8(Nvidia, 2024b)를 사용함. 또한 효율적인 훈련을 위해 비전 인코더와 LLM에서 플래시 어텐션(Dao et al., 2022; Dao, 2024; Shah et al., 2024)을 활용함. LayerNorm(Ba et al., 2016), RMSNorm(Zhang and Sennrich, 2019), Adam(Loshchilov and Hutter, 2019)과 같은 결합된 연산자(Nvidia, 2024a)도 사용함. 이 외에도 매트릭스 곱셈 과정에서 통신과 계산을 겹치는 방식을 활용함.
Experiments
- 이 섹션에서는 다양한 시각 벤치마크를 통해 모델의 성능을 평가하고, 우리의 접근 방식의 장점을 비교 분석함.
- 이후, 일반적인 시각 인식, 문서 이해, 이미지 내 다국어 인식, 비디오 이해, 에이전트 능력 등 특정 능력에 대한 세부적인 검사를 수행함.
- 마지막으로, 여러 주요 구성 요소를 조사하기 위해 소거 연구(ablation study)를 제시함.
Compare to SOTAs
- 다양한 시각적 벤치마크, 비디오 작업, 에이전트 기반 평가를 통해 모델의 시각적 능력을 평가함.
- Qwen2-VL은 동일한 규모에서 매우 경쟁력 있는 성능을 보여주며, 새로운 최첨단(SoTA) 결과를 달성함.
- 전체적으로 Qwen2-VL-72B 모델은 대부분의 평가 지표에서 일관되게 최고의 성과를 내며, 종종 GPT-4o(OpenAI, 2024)와 Claude 3.5-Sonnet(Anthropic, 2024)와 같은 비공개 소스 모델을 능가함.
- 특히 문서 이해 작업에서 큰 이점을 보여줌.
- 그러나 MMMU(Yue et al., 2023) 벤치마크에서는 Qwen2-VL-72B 모델이 GPT-4o에 비해 여전히 뒤처져, 보다 복잡하고 도전적인 문제를 처리하는 데 개선의 여지가 있음을 나타냄.
Quantitative Results
- 이 섹션에서는 다양한 데이터셋에 걸친 Qwen2-VL 시리즈의 광범위한 평가 결과를 제시하여, 모델의 다양한 측면에서의 능력을 포괄적으로 이해할 수 있도록 함.
General Visual Question Answering
- 우리의 모델이 일반적인 시각적 질문 답변(Visual Question Answering) 작업에서 능력을 철저히 평가하기 위해, 다양한 최신 벤치마크에서 광범위한 평가를 진행함: RealWorldQA (X.AI, 2024a), MMStar (Chen et al., 2024a), MMVet (Yu et al., 2024), MMT-Bench (Ying et al., 2024), MMBench (Liu et al., 2023d), MMbench-1.1 (Liu et al., 2023d), MME (Fu et al., 2023), HallusionBench (Guan et al., 2023).
- Qwen2-VL 시리즈는 이러한 벤치마크 전반에서 뛰어난 성능을 보이며, 특히 72B 모델은 일관되게 최첨단 결과를 달성하거나 이를 초과함. 7B 및 2B 모델도 강력한 성능을 입증함.
- RealWorldQA에서 Qwen2-VL-72B는 77.8점을 기록해, 이전 최고 기록인 72.2를 넘어섰고, GPT-4o(75.4)와 같은 강력한 기준도 초과함. 이는 물리적 환경에 대한 우수한 이해력을 보여줌.
- MMStar에서는 시각적으로 필수적인 샘플을 통해 진정한 멀티모달 역량을 평가하는데, Qwen2-VL-72B는 68.3점을 기록해 이전 최고 기록인 67.1을 초과, 시각적 정보와 텍스트 정보를 통합하는 능력을 강조함.
- MMVet에서 Qwen2-VL-72B는 16개의 복잡한 멀티모달 작업에서 시각-언어 능력의 통합을 평가하며, 74.0이라는 놀라운 점수를 기록해 GPT-4V(67.5) 등 강력한 경쟁자들을 크게 능가함.
- MMT-Bench 평가에서 Qwen2-VL-72B는 32개의 핵심 메타 작업과 162개의 세부 작업에서 고급 추론 및 지침 이행을 평가, 71.7점을 기록하며 이전 최고 기록인 63.4를 크게 초과함. 이로써 전문가 수준의 지식 적용, 시각 인식, 위치 파악, 추론 및 계획 실행 능력을 입증함.
- MMBench에서 Qwen2-VL-72B는 20개의 세부 능력을 평가하며, 영어 테스트 세트에서 86.5점을 기록해 최첨단 성과와 일치하며, 중국어 테스트 세트에서 86.6점을 기록해 새로운 기준을 세움.
- MME에서는 14개의 세부 작업에서 지각 및 인지 능력을 평가하며, Qwen2-VL-72B는 2482.7점의 누적 점수를 기록해 이전 최고 기록인 2414.7을 크게 초과, 시각적 지각과 고급 인지 작업에서의 탁월한 능력을 보여줌.
- 이러한 종합적인 결과는 Qwen2-VL 시리즈가 일반 시각 질문 답변 작업에서 뛰어난 능력을 보임을 강조함. 모델은 실제 공간 이해, 멀티모달 통합, 복잡한 추론, 지침 이행, 다양한 지각 및 인지 작업에서 고급 역량을 발휘함. 특히 72B 모델의 뛰어난 성능은 Qwen2-VL 시리즈를 시각 질문 답변 분야에서 선도적인 솔루션으로 자리매김하게 함. 모델은 시각적으로 필수적인 작업을 처리하고 핵심 시각-언어 능력을 통합하며, 다양한 멀티모달 시나리오에서 전문성을 입증함. 이러한 종합적인 평가를 통해 Qwen2-VL 시리즈는 최첨단 멀티모달 벤치마크가 제시하는 복잡한 과제를 효과적으로 해결하며, 대형 비전-언어 모델의 새로운 표준을 세움.
Document and Diagrams Reading
- 우리 모델의 OCR(문자인식) 및 문서와 다이어그램 이해 능력을 DocVQA (Mathew et al., 2021), ChartQA (Masry et al., 2022), InfoVQA (Mathew et al., 2021), TextVQA (Singh et al., 2019), AI2D (Kembhavi et al., 2016) 데이터셋에서 테스트함
- DocVQA/InfoVQA/ChartQA 데이터셋은 문서, 고해상도 인포그래픽, 차트에서 텍스트를 이해하는 모델의 능력을 평가하며, TextVQA는 자연스러운 이미지 내 텍스트 이해 능력을 평가함
- OCRBench 데이터셋은 수식 분석 및 정보 추출을 포함한 텍스트 기반 VQA 외에도 다양한 작업을 포함한 혼합 작업 데이터셋임
- AI2D 데이터셋은 텍스트가 포함된 과학 다이어그램에 대한 선택형 질문을 평가함
- 또한 OCRBench (Liu et al., 2023e)에서 모델의 OCR 및 수식 인식 능력과 MTVQA (Tang et al., 2024) 데이터셋에서 다국어 OCR 능력을 테스트함
- 실험 결과, DocVQA, InfoVQA, TextVQA, OCRBench에서 우리 모델이 여러 지표에서 최첨단(SOTA) 수준의 성과를 달성했으며, 다양한 분야의 이미지에서 텍스트 내용을 잘 이해함을 입증함
Multilingual Text Recognition and Understanding
- 특히, 우리 모델은 다국어 OCR에서 모든 기존의 일반-purpose LVLM을 능가함
- MTVQA 데이터셋에서 기존 LVLM(프로프라이어 모델인 GPT-4o, Claude 3.5 Sonnet 등 포함)을 능가했으며, 내부 벤치마크에서도 아랍어를 제외한 모든 외국어에서 GPT-4o를 초과하는 성과를 보임
Mathematical Reasoning
- 수학적 추론 능력을 평가하기 위해 MathVista (Lu et al., 2024a) 및 MathVision (Wang et al., 2024) 데이터셋에서 실험을 진행함
- MathVista는 6,141개의 다양한 수학 및 시각적 작업 예시를 포함한 종합 벤치마크임
- MathVision은 실제 수학 대회에서 시각적 맥락에 포함된 3,040개의 수학 문제로 구성되어 있으며, 16개의 수학 분야를 다루고 5개의 난이도로 분류됨
- 이러한 문제들은 LVLM이 강력한 시각적 이해력, 수학적 깊은 이해, 논리적 추론 능력을 발휘해야 함을 강조함
- Qwen2-VL 시리즈는 MathVista에서 70.5점을 기록하며 다른 LVLM보다 우수한 성과를 보였고, MathVision에서도 25.9점을 기록하며 새로운 오픈소스 벤치마크를 설정함
Referring Expression Comprehension
- 시각적 위치 지정 작업과 관련하여, RefCOCO, RefCOCO+, RefCOCOg (Kazemzadeh et al., 2014; Mao et al., 2016) 데이터셋에서 Qwen2-VL을 평가함
- Qwen2-VL은 고해상도 이미지에서 세부 사항을 인식할 수 있는 합리적인 구조 설계를 통해 기존 Qwen-VL보다 성능이 크게 향상되었으며, 일반 모델들 중에서도 최고 수준의 결과를 달성함
- 이는 시각적 위치 지정 작업에 있어 Qwen2-VL 모델의 우수성을 입증하며, 정밀한 시각적 이해가 필요한 실제 응용 분야에서의 잠재력을 보여줌
3.2.6 Video Understanding
- 우리는 다양한 비디오 이해 과제에서 모델을 평가했으며, 관련 벤치마크는 몇 초짜리 짧은 비디오부터 최대 1시간짜리 긴 비디오까지 포함함
- 표 4는 Qwen2-VL 및 베이스라인 모델의 성능을 보여줌
- 전반적으로, Qwen2-VL은 2B, 7B, 72B 크기에서 강력한 결과를 보여주었으며, Qwen2-VL-72B가 MVBench (Li et al., 2024), PerceptionTest (Patraucean et al., 2024), EgoSchema (Mangalam et al., 2023)에서 최고의 성과를 거둠
- 이는 Qwen2-VL이 비디오 이해 작업에서 뛰어난 성능을 발휘함을 나타내며, Qwen2-VL의 크기를 확장하면 성능이 크게 향상됨
- 1시간까지의 비디오를 포함하는 까다로운 Video-MME 벤치마크(Fu et al., 2024)에 대해 평가 시 비디오당 추출된 프레임 수를 최대 768로 제한하였으며, 이로 인해 긴 비디오에 대한 성능에 영향을 미칠 가능성이 있음
- 향후 연구에서는 Qwen2-VL을 확장하여 더 긴 시퀀스를 지원하고, 긴 비디오를 처리할 수 있도록 할 예정임
3.2.7 Visual Agent
- Qwen2-VL은 환경과 상호작용하는 능력과 복잡한 순차적 의사결정 작업을 여러 차례의 상호작용을 통해 완료하는 능력에 대해 평가됨
- 구현은 Qwen-Agent 프레임워크(Qwen Team, 2024)를 기반으로 함
Function Calling
- LLM에서의 함수 호출(Yan et al., 2024; Srinivasan et al., 2023; Chen et al., 2023c)과 달리, LVLM에서의 함수 호출은 종종 시각적 단서에서 정보를 추출하는 작업이 포함됨
- LVLM의 함수 호출 능력을 평가할 공개 벤치마크가 없기 때문에, 우리는 내부 평가 데이터셋을 구성함
- 평가 데이터셋을 구성하기 위해 다음 절차를 따름(Chen et al., 2023c): 장면 분류, 이미지 수집, 이미지 콘텐츠 추출, 질문/함수/인수 생성
- 먼저, 다양한 시각적 애플리케이션을 기반으로 장면을 카테고리로 분류함
- 이후 각 카테고리에 대해 인터넷에서 고품질의 대표 이미지를 다운로드하고 신중히 선택함
- 그 후, 고급 LVLM(Bai et al., 2023b)을 활용하여 각 이미지를 분석해 주요 시각 요소와 텍스트 정보를 추출함
- 마지막으로, 이미지에서 추출된 콘텐츠 정보를 바탕으로 고급 LLM(Yang et al., 2024)을 사용해 특정 기능 호출이 필요한 일련의 질문을 생성하고, 해당 함수 호출에 필요한 입력 매개변수를 지정함
Evaluation Metrics
- LLM에서의 함수 호출 평가 방식(Yan et al., 2024)과 유사하게, 함수 선택의 정확성과 인수 입력의 정확성을 평가하는 두 가지 메트릭을 설계함
- Type Match(TM): 모델이 올바른 함수를 성공적으로 호출한 횟수의 비율을 계산함
- Exact Match(EM): 각 함수 호출에서 함수에 전달된 인수가 이미지의 콘텐츠 정보와 정확히 일치하는지 확인하여 정확도 비율을 계산함
성능 평가
- 표 5에서 보이는 것처럼, Qwen2-VL은 GPT-4o에 비해 타입 매치(93.1 vs. 90.2)와 정확 매치(53.2 vs. 50.0)에서 우수한 성능을 보이며, 이를 통해 Qwen2-VL의 함수 호출 기능이 더 효율적임을 입증하고 외부 도구 통합을 통한 응용 확장의 가능성을 강조함.
- 평가 결과에 따르면, GPT-4o는 두 가지 이유로 성능이 떨어짐: 첫째, 불확실한 상황에서 GPT-4o는 외부 도구 사용을 회피하는 보수적인 접근을 취함. 둘째, 광학 문자 인식(OCR) 기능에서 GPT-4o는 특히 한자 인식 측면에서 Qwen2-VL보다 뒤처짐.
- UI Operations/Games/Robotics/Navigation: Qwen2-VL의 복잡한 작업 처리 능력을 평가하기 위해 다양한 VL 에이전트 작업(모바일 작업, 로봇 제어, 카드 게임, 비전-언어 내비게이션)에서 평가를 수행함. 이러한 작업은 여러 단계를 통해 완료되어야 하므로 Qwen2-VL의 32K 컨텍스트 길이를 지원하는 이력을 통해, 작업 후 매번 새로운 관찰 이미지를 추가하여 지속적인 추론이 가능함.
UI Operations
- AITZ 작업(Zhang et al., 2024b)을 사용해 Qwen2-VL을 평가하였고, 이는 AITW(Rawles et al., 2024b)에서 파생된 핵심 테스트 세트를 사용함. 휴대폰의 일반적인 작업 패턴에 따라 Qwen2-VL은 화면의 아이콘과 상호작용하는 동작(탭, 입력, 스와이프)을 수행하여 작업을 완료함. 예를 들어, Google Maps에서 근처 피자 레스토랑을 찾는 작업에서 'pizza'를 입력하고, 적절한 레스토랑을 선택한 후 링크를 클릭함. AITZ 설정에 따라 타입 매치(탭, 입력 또는 스와이프의 정확도)와 정확 매치(탭 위치, 입력 텍스트 또는 스와이프 방향의 정확도)를 보고함. Qwen2-VL은 UI 기반 작업에서 GPT-4와 기존 SOTA(최첨단) 모델을 능가함.
Robotic Control
- ALFRED 작업(Shridhar et al., 2020a)에서 AI2THOR(Kolve et al., 2017)을 사용하여 Qwen2-VL을 평가함. 이 작업은 가상 환경에서 복잡한 가사 작업(예: 빵 굽기, 사과 썰기 등)을 수행하는 에이전트의 능력을 평가함. 위치 이동, 물건 집기, 내려놓기, 열기, 닫기, 청소, 가열, 냉각, 자르기와 같은 고수준 동작을 정의함. 에이전트는 조작을 위해 물체를 인식해야 하며, 정확도를 높이기 위해 SAM(Kirillov et al., 2023)을 통합함. ALFRED 작업은 작업 성공률(SR)과 하위 목표 달성 지표(GC)를 보고하며, Qwen2-VL은 유효하지 않은 데이터 세트에서 ThinkBot(Lu et al., 2023)을 약간 능가함.
Card Games
- RL4VLM(Zhai et al., 2024)의 카드 게임 환경을 사용하여 Qwen2-VL의 성능을 평가함. 숫자 줄, 블랙잭, EZPoint, Point24와 같은 여러 카드 기반 게임에서 Qwen2-VL의 성능을 테스트함. 각 게임은 +1 또는 -1 작업을 통해 목표 숫자에 도달하거나, 딜러와 경쟁하여 카드를 뽑거나 유지하는 등 다양한 도전을 제시함. 또한, Qwen2-VL은 강력한 OCR 기술을 통해 카드 인식 및 게임 진행을 이해해야 함. Qwen2-VL은 모든 과제에서 우수한 성능을 보임.
Vision-Language Navigation
- R2R(Anderson et al., 2018) 및 REVERIE(Qi et al., 2020)를 사용하여 Qwen2-VL의 비전-언어 내비게이션(VLN) 작업을 평가함. 이 작업에서 모델은 지시에 따라 다음 위치를 스스로 결정해야 하며, 성공률(SR)을 통해 성능을 평가함. Qwen2-VL의 성능은 GPT-4o와 유사하지만, 전문 VLN 모델(Chen et al., 2022; Sigurdsson et al., 2023)에는 미치지 못함. 이러한 격차는 여러 이미지로부터 생성된 불완전하고 비구조적인 지도 정보 때문임. 3D 환경에서 정확한 지도와 위치 모델링은 여전히 멀티모달 모델의 주요 과제임.
3.3 Ablation Study
- 이 섹션에서는 이미지 동적 해상도, M-RoPE, 모델 크기에 대한 ablation 연구를 제시함. 이러한 실험은 모델 성능에 미치는 주요 구성 요소들의 영향을 파악하기 위한 것임.
3.3.1 Dynamic Resolution
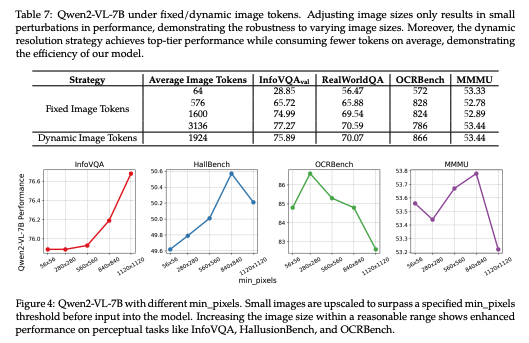
- Table 7에서 동적 해상도와 고정 해상도 간의 성능을 비교함. 고정 해상도에서는 이미지 토큰 수를 일정하게 유지하기 위해 이미지를 리사이징하였으며, 특정 높이와 너비로 리사이징하는 대신 원본 비율을 유지함. 반면, 동적 해상도에서는 최소 픽셀 수를 100 × 28 × 28, 최대 픽셀 수를 16384 × 28 × 28로 설정하여 이미지의 기본 해상도에 따라 이미지 토큰 수가 결정되도록 함.
- 실험 결과, 이미지 크기 조정은 성능에 미미한 변화를 초래하여, 모델이 다양한 이미지 크기에 대해 견고함을 보임. 또한 동적 해상도 방식이 더 효율적인 것으로 나타남. 고정 해상도 방식은 어떤 단일 해상도도 모든 벤치마크에서 최적의 성능을 내지 못했으나, 동적 해상도 방식은 평균적으로 적은 토큰을 사용하면서도 일관되게 높은 성능을 달성함.
- 추가적으로, 단순히 이미지 크기를 키우는 것이 항상 성능 향상으로 이어지지는 않음. 각각의 이미지에 적합한 해상도를 선택하는 것이 더 중요함. Figure 4에 따르면, 작은 이미지를 최소 픽셀 수 이상의 크기로 업스케일했을 때 지각적 작업(예: InfoVQA, HallusionBench, OCRBench)에서 성능이 향상됨. 이는 계산량 증가에 기인한 것으로 보임.
- 그러나 OCRBench에서는 최소 픽셀 수가 너무 높을 경우 성능이 급격히 저하됨. 이는 OCRBench에 매우 작은 이미지가 많고, 과도한 확대가 이러한 이미지들을 학습 데이터 분포에서 벗어나게 하여 비정상적인 샘플로 만들기 때문임. 반면, MMMU 벤치마크에서는 최소 픽셀 수를 증가시키는 것이 성능에 거의 영향을 미치지 않음. 이는 MMMU의 성능 병목이 이미지 해상도보다는 모델의 추론 능력과 더 관련이 있을 것으로 추측됨.
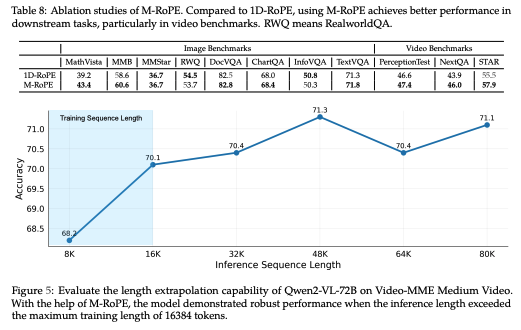
3.3.2 M-RoPE
- 이 절에서는 M-RoPE의 효과를 증명함.
- 먼저 다양한 다운스트림 작업에서 M-RoPE의 성능을 검증함.
- Qwen2-1.5B와 ViT-L을 백본으로 사용하여 사전 학습된 모델의 결과를 보고함.
- 표 8에서 볼 수 있듯이, 1D-RoPE와 비교할 때 M-RoPE를 사용하면 다운스트림 작업, 특히 비디오 벤치마크에서 더 나은 성능을 달성함.
- 또한, M-RoPE의 길이 extrapolation(추정) 능력을 Video-MME 중간 길이 비디오에서 평가함.
- 그림 5는 서로 다른 추론 길이에서 Qwen2-VL-72B의 성능을 보여줌.
- M-RoPE를 활용하여, 모델은 다양한 추론 길이에서도 강력한 성능을 발휘함.
- 특히 학습 중에는 비디오당 최대 16K 토큰으로 제한했음에도 불구하고, 추론 시 최대 80K 토큰에서 뛰어난 성능을 보여줌.
3.3.3 Model Scaling
- 모델의 크기에 따라 다양한 역량 차원에서 성능을 평가함.
- 구체적으로, 복잡한 대학 수준 문제 해결, 수학 능력, 문서 및 표 이해, 일반적인 시나리오 질문-답변, 비디오 이해로 차원을 분류함.
- 모델의 전체 성능은 각 차원과 관련된 다양한 벤치마크에서의 점수를 평균하여 평가함.
- 특히 대학 수준 문제 해결 능력을 평가하기 위해 MMMU (Yue et al., 2023) 벤치마크를 사용하고, MathVista (Lu et al., 2024a) 및 MathVision (Wang et al., 2024)의 평균 점수를 수학 능력의 지표로 사용함.
- 일반적인 시나리오 질문-답변에서는 RealWorldQA (X.AI, 2024a), MMBench-V1.1 (Liu et al., 2023d), MMT-Bench (Ying et al., 2024), HallBench (Guan et al., 2023), MMVet (Yu et al., 2024), MMStar (Chen et al., 2024a) 벤치마크에서 평균 점수를 계산함.
- 문서 및 표 이해 능력은 DocVQA (Mathew et al., 2021), InfoVQA (Mathew et al., 2021), ChartQA (Masry et al., 2022), TextVQA (Singh et al., 2019), OCRBench (Liu et al., 2023e), MTVQA (Tang et al., 2024)의 벤치마크 평균 점수로 반영됨.
- 비디오 이해 능력은 MVBench (Li et al., 2024), PerceptionTest (Patraucean et al., 2024), EgoSchema (Mangalam et al., 2023), Video-MME (Fu et al., 2024)의 평균 점수로 평가됨.
- 그림 6(a)에서 볼 수 있듯이, 모델 크기가 커질수록 특히 수학적 능력에서 성능이 지속적으로 향상됨을 확인할 수 있음.
- 반면에, OCR(광학 문자 인식) 관련 작업에서는 작은 규모의 모델도 상대적으로 강력한 성능을 보임.
- 그림 6(b)에서는 Qwen2-VL-7B의 2차 사전 학습 단계에서 학습 토큰 수와 모델 성능 간의 관계를 시각화함.
- 학습 토큰 수가 증가함에 따라 모델 성능도 향상되지만, 비전 질문 답변(VQA) 작업에서는 성능이 다소 변동함.
- 반면, AI2D (Kembhavi et al., 2016) 및 InfoVQA (Mathew et al., 2021)와 같은 텍스트와 그래픽 정보를 이해하는 작업에서는 학습 데이터가 증가함에 따라 모델 성능이 꾸준히 향상됨.
4. Conclusion
- Qwen2-VL 시리즈는 총 2B, 8B, 72B 파라미터를 가진 세 가지 오픈 웨이트 모델을 포함한 다재다능한 대형 비전-언어 모델임.
- Qwen2-VL은 여러 멀티모달 시나리오에서 GPT-4o 및 Claude3.5-Sonnet과 같은 최고 수준의 모델 성능을 보여주며, 다른 모든 오픈 웨이트 LVLM 모델을 능가함.
- Qwen2-VL 시리즈는 Naive Dynamic Resolution과 Multimodal Rotary Position Embedding (M-RoPE)을 도입하여 다양한 모달 간 정보를 효과적으로 융합하고, 20분 이상의 비디오를 이해할 수 있는 능력을 가짐.
- 고급 추론 및 의사결정 능력으로 인해 Qwen2-VL은 휴대폰, 로봇 등 다양한 기기와 통합될 수 있음.
- 또한, Qwen2-VL은 이미지 내 다국어 텍스트, 특히 유럽 언어, 일본어, 한국어, 아랍어, 베트남어 등을 이해할 수 있는 지원을 제공함.
- 우리는 Qwen2-VL 모델 가중치를 공개하여 연구자와 개발자가 다양한 응용 프로그램과 연구 프로젝트에서 그 잠재력을 활용할 수 있도록 했음.
- 우리는 이러한 노력에 헌신함으로써 AI 기술을 발전시키고 사회에 긍정적인 영향을 미치는 것을 목표로 하고 있음.
