
계기
이전 아차차 프로젝트를 진행할 당시, hadoop을 단순 저장소로만 활용하고 분산 시스템으로서 활용하지 못한 것이 아쉬웠기 때문에, 해당 프로젝트를 디벨롭 하는 과정에서 하둡 분산 클러스터를 구축해보고자 했다.
구성 및 설정
AWS EC2를 4대 구성하여 활용하였다.
여러 레퍼런스들을 찾아보았지만 같은 계정 내에서 3~4대 구성한 경우는 많았지만 각기 다른 계정에서 각각 구축하여 연동한 케이스는 많이 없어 고생 좀 했다.
각 EC2 서버는 이하와 같이 설정해 주었다.
서버 구성
| 서버 | 설정 노드 |
|---|---|
| EC2 1 | namenode01 |
| EC2 2 | namenode02 |
| EC2 3 | datanode01 |
| EC2 4 | datanode02 |
또한, 이후 작업하면서 통신이 잘 되지 않는 경우가 여러 번 발생하였는데, 이는 AWS EC2 사이트 내에서 인바운드 설정을 해주지 않아서 발생하는 경우가 많았음..
꼭 필요한 포트는 인바운드 설정을 잊지 말고 해주자!
인바운드 설정 포트
| 포트명 | 포트넘버 |
|---|---|
| Namenode | 9000 |
| Datanode | 9866-9867 |
| Secondary Namenode | 9868 |
| Namenode Web UI | 9870 |
| Datanode Web UI | 9864 |
설치
java : jdk-11
hadoop : 3.2.4
java 설치
hadoop은 java로 만들어져 있기 때문에 java가 사전에 설치되어 있어야 한다.
$ sudo apt install openjdk-11-jdk
$ sudo vim ~/.bashrc
# 이하 입력 후 저장
# java
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
$ source ~/.bashrchadoop 설치
$ wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
$ tar xvzf hadoop-3.2.4.tar.gz
$ ln -s hadoop-3.2.4 hadoop
$ rm hadoop-3.2.4.tar.gz # 필수 아님
$ sudo vim ~/.bashrc
# 이하 입력 후 저장
# hadoop
export HADOOP_HOME=/home/ubuntu/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/etc/hadoop
# hadoop user
export HDFS_NAMENODE_USER=ubuntu
export HDFS_DATANODE_USER=ubuntu
export HDFS_SECONDARYNAMENODE_USER=ubuntu
export YARN_RESOURCEMANAGER_USER=ubuntu
export YARN_NODEMANAGER_USER=ubuntu
$ source ~/.bashrc설치는 이렇게 끝!
설정 파일 작성
hadoop 관련 설정 파일을 작성하기 전, 각 서버별 hostname 및 ip를 설정해준다.
hostname 설정
노드별로 그에 맞게 작성해준다.
$ sudo vim /etc/hostname
# 기존에 적혀 있던 내용 지우고 작성한다.
namenode01 # 그 외 다른 서버들도 각자 노드에 맞게 설정
$ sudo reboothostname ip 설정
설정한 hostname별 ip를 각 서버에 저장해준다.
기본적으로 public ip를 기재하나, 이 때, namenode들의 경우, 자기 자신의 ip는 private ip로 기재한다.
예) namenode01
$ sudo vim /etc/hosts
# 이하 입력 후 저장
172.31.42.91 namenode01 # 자기 자신이므로, private ip로 기재
3.38.81.197 namenode02 # namenode02에서 기재할 경우에는 여기에 private ip
43.201.142.87 datanode01
35.79.182.1 datanode02방화벽 설정
또한, 서버끼리 통신할 수 있도록 방화벽 설정에서 필요로 하는 포트들을 허용해준다.
설정해야 하는 포트들은 위에 기재한 인바운드 규칙의 포트들과 같으며 이하와 같이 모든 노드에서 실행해준다.
$ sudo ufw allow {허용해 줄 포트번호}
$ sudo ufw status # 허용한 포트들 확인
$ sudo ufw enable # 방화벽 올리기hadoop 설정 파일 작성
hadoop 관련 설정 파일들을 작성해준다.
노드별로 설정해야 하는 파일 내용이 다른 경우가 있으므로, 유의해서 작성하자.
(공통) mapred-site.xml
$ cd $HADOOP_CONF_DIR
$ cp mapred-site.xml mapred-site-template.xml
$ sudo vim mapred-site.xml
# 이하 입력 후 저장
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(공통) core-site.xml
$ sudo vim core-site.xml
# 이하 입력 후 저장
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode01:9000</value>
</property>
</configuration>(공통) yarn-site.xml
$ sudo vim yarn-site.xml
# 이하 입력 후 저장
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode01</value>
</property>
<property>
<name>yarn.nodemanager.hostname</name>
<value>namenode01</value>
<property>
</configuration>(노드별) hdfs-site.xml
namenode01 / namenode02
$ sudo vim hdfs-site.xml
# 이하 입력 후 저장
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop/namenode_dir</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>namenode01:9870</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>namenode02:9868</value>
</property>
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>datanode01 / datanode02
$ sudo vim hdfs-site.xml
# 이하 입력 후 저장
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop/datanode_dir</value>
</property>
</configuration>(노드별) hadoop-env.sh
namenode01 / namenode02
$ sudo vim hadoop-env.sh
# line 위치의 경우, 조금씩 다를 수 있으니 확인하자. 이하 입력 후 저장
# line 54
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
# line 58
export HADOOP_HOME=/home/ubuntu/hadoop
# line 68
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# line 198
export HADOOP_PID_DIR=$HADOOP_HOME/pidsdatanode01 / datanode02
$ sudo vim hadoop-env.sh
# line 위치의 경우, 조금씩 다를 수 있으니 확인하자. 이하 입력 후 저장
# line 54
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
# line 58
export HADOOP_HOME=/home/ubuntu/hadoop
# line 68
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop(namenode만)workers
$ cd $HADOOP_CONF_DIR
$ vim workers
# 이하 입력 후 저장
datanode01
datanode02모든 설정 파일까지 작성을 완료하였다.
마지막으로 통신 시 접속 가능하도록 하기 위해 sshkey를 보내주어야 한다.
공개키(public key) 복사
통신을 위해, namenode01에서 생성한 공개키를 각 서버에 복사해 주어야 한다.
다만, 각 서버에 보내기 위해서는 해당 서버들의 pem-key를 가지고 있어야 하므로 로컬에서 namenode01에 해당 key들을 보내준다.
서로 다른 계정의 서버들이므로 이 작업이 필요하다.
로컬에서 작업
# namenode02 pem key -> namenode01에 보내기
$ scp -i namenode01.pem -r {경로}/namenode02.pem ubuntu@{namenode01 ip}:
# datanode01 pem key -> namenode01에 보내기
$ scp -i namenode01.pem -r {경로}/datanode01.pem ubuntu@{namenode01 ip}:
# datanode02 pem key -> namenode01에 보내기
$ scp -i namenode01.pem -r {경로}/datanode02.pem ubuntu@{namenode01 ip}:다른 서버들의 pem-key를 가진 namenode01에서 공개키를 생성하고 해당 키를 각 서버에 복사해준다.
namenode01
# -t : type(rsa), -P : 이전 암호 초기화 -f : 파일 저장 위치
# namenode01 공개키 생성
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# namenode02 copy
$ scp -i namenode02.pem ~/.ssh/id_rsa.pub ubuntu@{namenode02 ip}:~/.ssh/
# datanode01 copy
$ scp -i datanode01.pem ~/.ssh/id_rsa.pub ubuntu@{datanode01 ip}:~/.ssh/
# datanode02 copy
$ scp -i datanode02.pem ~/.ssh/id_rsa.pub ubuntu@{datanode02 ip}:~/.ssh/namenode02 / datanode01 / datanode02
# 전달 받은 공개키를 읽어준다.
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys긴 설정이 드디어 끝났다!
이제 hadoop을 실행시켜보자!
hadoop 실행
첫 시작이므로, namenode를 포맷하고 실행시켜 준다.
이하 작업은 namenode01에서만 진행한다.
namenode01
$ hdfs namenode -format
$ start-all.sh
$ jps이하와 같이 분산되어 노드들이 올라온 것을 확인할 수 있다.
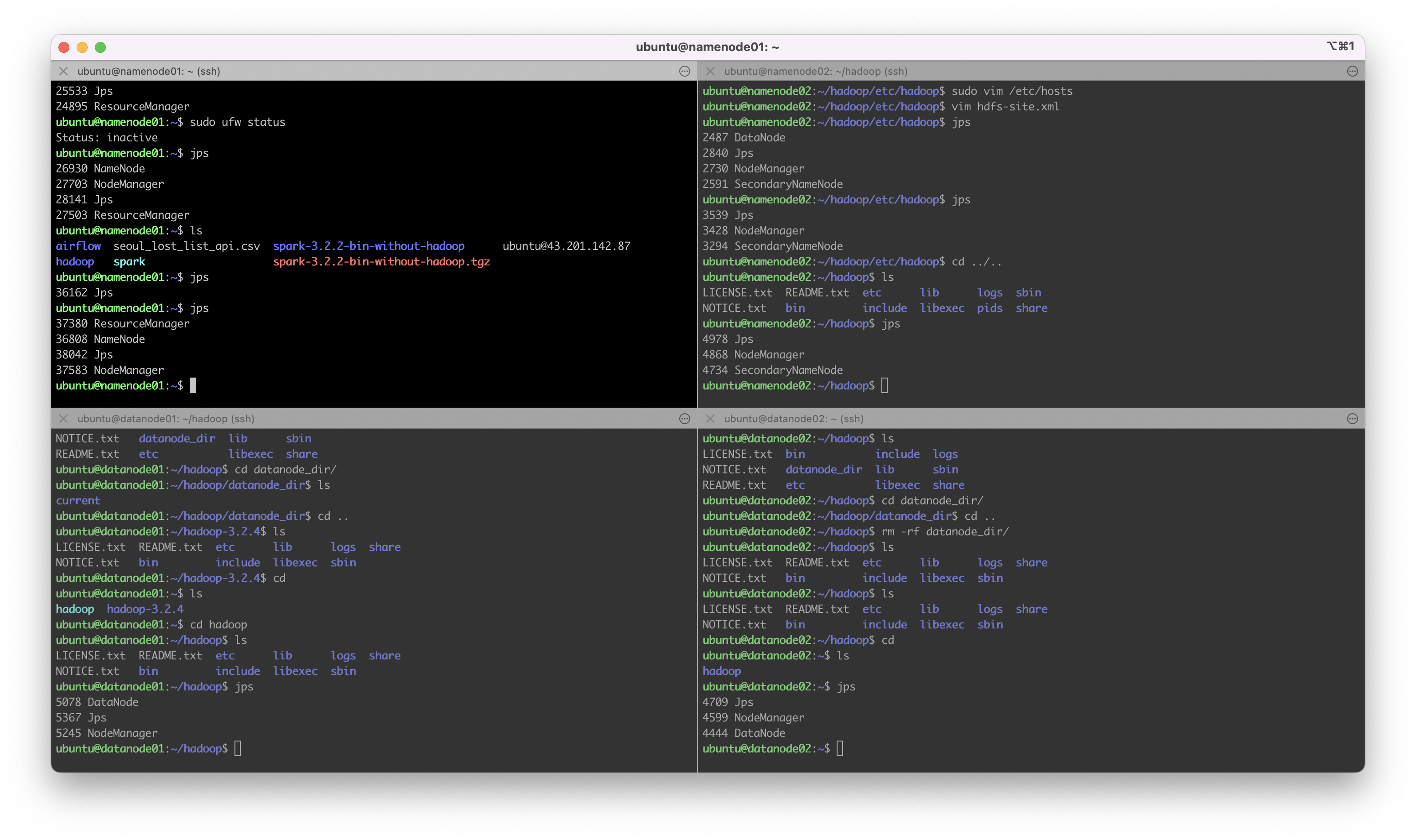
처음에는 EC2 하나에 다른 데스크탑이나 노트북 서버와 연결하려고 했으나, EC2를 외부 서버와 연결하는 건 불가능했다. (이걸 알기까지도 시간이 걸림)
또한, 레퍼런스가 생각보다 많이 없어서 각기 다른 계정에서 생성한 서버의 연결에 있어서 여러 시행착오를 겪었지만 팀원들 모두 방화벽이나 포트포워딩에 대한 이해도를 높일 수 있었고 결과적으로 분산 노드까지 구현할 수 있게 되어서 아주 뿌듯한 경험이었다~!
