
얼마 전 면접을 보고, 용어나 프로그램들의 기본적인 개념에 대해 부족한 부분이 많은 것 같아 차근차근 정리해보려고 한다.
그 중에서 이번에는 parquet 파일이란 무엇이며, 어떠한 장점이 있어 사용되고 있는지 정리해본다.
Parquet(파케이) 파일이란?
- 하둡 에코시스템에서 많이 사용되는 파일 포맷 중 하나
- Twitter, Cloudera에서 개발하여, 현재 Apache에서 관리
- columnar 저장 포맷 (기존의 row 기반 포맷과 다름)
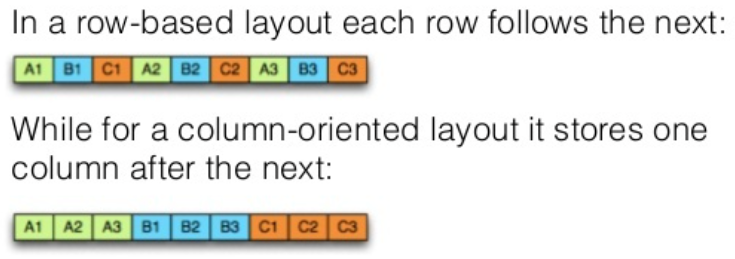
생겨난 배경
Twitter에서는 HDFS에 SNS에서 발생한 대량의 데이터를 저장하고 있었는데,
데이터의 양이 방대해 너무 많은 디스크를 소모하는 것을 개선하기 위해
데이터 사이즈를 줄이는 파일 포맷을 개발하게 됨.
→ 작은 파일 사이즈와 낮은 I/O 사용을 목적으로 개발
장점
- 압축률이 좋다.
→ 컬럼 단위로 구성하면 데이터가 균일해 압축률이 높아지기 때문. - 데이터를 읽을 때, 전체 컬럼 중 일부 컬럼을 선택해서 가져가서 읽으면 되기 때문에 I/O가 줄어든다.
→ 불필요한 디스크 사용을 줄임. - 컬럼에 동일한 데이터 타입이 저장되기 때문에 컬럼별로 적합한 인코딩을 사용할 수 있다.
- 복잡한 데이터를 대량으로 다루는데 최적화 되어 있으며, 모든 종류의 빅데이터를 저장하는데 적합하다.
→ 구조적 데이터 테이블, 이미지, 동영상, 문서
특징
-
스키마 정보가 포함되어 있어 spark에서 기존 데이터 스키마를 유지하여 파일 읽기와 쓰기가 가능함.
-
모든 칼럼은 호환성을 위해 자동 NULL 허용함.
-
언어를 가리지 않는다.
-
pyspark에서 parquet 파일 읽고 쓰기
PARQUET_FILEPATH = "test.parquet"
# 데이터프레임의 스키마 정보를 유지하면서 parquet 파일로 저장
df.write.format('parquet').save(PARQUET_FILEPATH)
df.write.parquet(PARQUET_FILEPATH)
# parquet 데이터 불러오기
df = spark.read.parquet(PARQUET_FILEPATH)
df = spark.read.format('parquet').load(PARQUET_FILEPATH)Parquet와 CSV 차이점
parquet는 스토리지를 줄여주고, 스캔하는 시간도 대폭 줄여준 덕분에, 비용 절감 효과가 있다.
| Dataset | Amazon S3 | 쿼리 런타임 | 스캔한 데이터 | 비용 |
|---|---|---|---|---|
| csv | 1TB | 236초 | 1.15TB | $5.75 |
| parquet | 130GB | 6.78초 | 2.51GB | $0.01 |
| 절약 | 약 87% | 34배 | 99% | 99.7% |
보다 자세한 활용은 직접 데이터 처리를 테스트 해보면서 익혀 나가자..!
