

1조 개의 UUID를 생성해도 중복될 확률이 굉장히 낮다고 한다. 분산 시스템에서 고유한 식별자를 보장하기 위해서 또는 사람이 알아보기 힘들고, 다음 번호를 예측할 수 없으므로 약간의 보안 목적으로 사용한다. 기존 Jwt 토큰에는 이메일이 담겨있었다. 보안에 취약하므로 이를 사용자 ID로 변경하는 과정에서 Long값이 아닌 UUID를 사용하려고 한다.
UUID
- 128비트, 16바이트 크기를 가진다.
349BB85C-E8B6-493A-B204-AA60EAA9C388- 사람이 읽기 쉽게
-으로 구분되어 출력된다. - UUID는 5개의 필드로 구성되며, 버전이 존재한다.
- Spring JPA에서 UUID를 생성하면 랜덤 UUID인 버전 4로 생성된다.
16cfa1e6-3c43-4102-aedc-f84843411485생성된 UUID를 uuidDecoder로 이를 디코딩해 보면 아래와 같은 정보를 얻을 수 있다.- https://www.uuidtools.com/decode
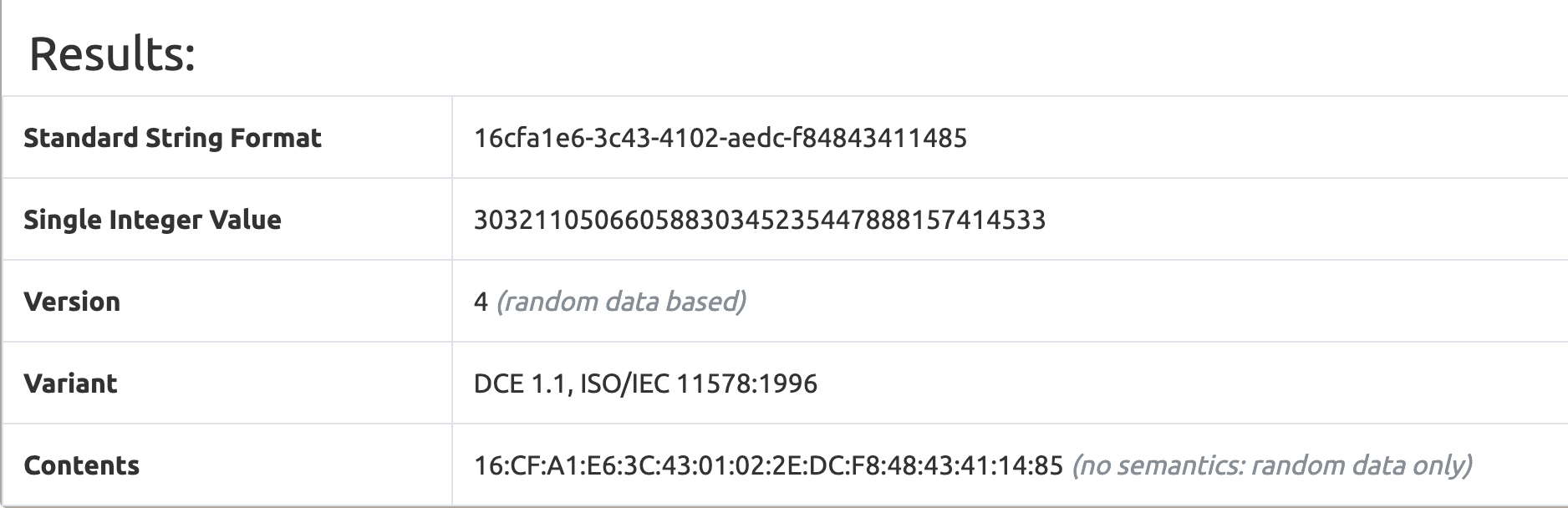
UUID의 단점
1. 저장 공간 크기 문제
- 기존에 AutoIncrement로 Long을 사용했다면 이를 위해서 8바이트를 사용한다. 하지만 UUID를 문자열로 저장할 경우
-제거하고 저장하더라도 32바이트를 사용한다. 즉, 기존보다 4배 더 많은 공간을 사용하게 된다.
UUID 바이너리로 저장하기 (JPA, Mysql)
-
UUID를 문자열이 아닌 UUID 바이너리로 저장하게 되면 기존 크기인 128비트, 16바이트만 사용하면 된다.
-
349BB85C-E8B6-493A-B204-AA60EAA9C388
- 먼저
'-'을 제거한다.REPLACE('1bba776a-24bd-445d-94a4-ae76e69c2a1e', '-', '')
- 16바이트 바이너리로 변환한다.
unhex(’1bba776a24bd445d94a4ae76e69c2a1e’)
- 먼저
-
이를 JPA Hibernate를 이용하면 아래와 같이 설정할 수 있다.
@Id
@GeneratedValue(generator = "uuid2")
@GenericGenerator(name = "uuid2", strategy = "uuid2")
@Column(columnDefinition = "BINARY(16)")
private UUID id;왜 컬럼 Definition에서 길이를 제한할까?
- 바이너리로 저장할 때 남는 공간은 0으로 패딩 해주기 때문이다. 공간을 추가로 설정할 경우 패딩값이 저장되어 데이터를 읽지 못한다.
UUID 조회하기
- jpa가 유저를 등록할 때 아래 값으로 UUID 저장
- binary로 저장해도 datagrip에서는 읽기 좋게 변환해서 보여준다.
BA2250DB7DA24190840C8A474B87F94F
- mysql에서 조회할 때
select * from user_ip_addresses where user_id = unhex(replace('93e205ff-6032-4d89-bb87-65f0cd22c41e', '-', ''));
select * from users where HEX(id) = '2752CBB604884147B6A3A522A49568BF';
select * from users where id = UNHEX('2752CBB604884147B6A3A522A49568BF');2. 인덱싱 속도 문제
1) 키 길이에 따른 성능 저하
- MySQL InnoDB는 기본 키를 클러스터드 인덱스로 사용하여 B-Tree 자료 구조를 통해 데이터가 기본 키 순서에 따라 물리적으로 정렬된다.
- MySQL 공식 문서에서는 기본 키가 짧을수록 성능에 유리하다고 한다. 기본 키가 클수록 보조 인덱스가 더 큰 공간을 차지하고, 조회할 때 사용하는 B-Tree 페이지가 더 커지기 때문이다. https://dev.mysql.com/doc/refman/8.4/en/innodb-index-types.html
- UUID는 32바이트 문자열이고, 이를 바이너리로 저장해도 16바이트이다. 즉 Long을 쓰는 것보다도 약 두 배 더 길다.
2) 랜덤 방식에 따른 성능 저하
-
기본 키가 AUTO_INCREMENT가 아닌 RANDOM 방식일 때 B-Tree 페이지가 더 크게 생성되고, 이로 인해 조회 속도가 느려진다는 내용을 테스트한 글이다.
-
UUID 방식을 적용해도 성능이 크게 느려지지 않는다는 스택오버플로우 글도 있다.
-
즉, 보안을 위해 UUID를 적용하되 이에 따라 성능 이슈가 생기면 UUID를 랜덤으로 만들면서 순차적으로 정렬할 수 있게하여 검색 성능을 올리는 작업이 필요할 수 있다.
UUID를 적용하는 게 무조건 능사는 아니다. UUID는 바이너리로 저장해도 16바이트 크기를 가지며, Long 타입보다 2배 더 많은 공간을 차지한다. AutoIncrement로 생성한 것에 비해 검색 속도도 뒤떨어진다. 하지만, 분산 시스템에서 고유한 식별자를 제공하고 싶을 때나 예측하기 어려운 식별자를 제공하고 싶을 때 유용하다.
- 찾아본 결과 일반적으로 주문 번호는 UUID를 많이 사용한다. 상품은 제각각이다. 유튜브 같은 경우 영상을 알아볼 수 없는 값으로 설정했지만 네이버 웹툰이나 쿠팡, 직방 등 대부분의 상품들은 Long으로 설정한 값으로 보인다. 사람이 쉽게 알아볼 수 있다.
- 사용자 ID는 UUID를 많이 사용할까? 구글, 네이버 같은 경우 로그인하면 jwt 토큰을 발급하지 않고 세션 쿠키로 사용자를 식별하기 때문에 어떻게 관리하는지 알 수 없었다.
- 기존 프로젝트에 사용자 ID와 주문 ID 정도만 UUID로 관리해보기로 했다.
JWT.IO UUID
- io.jsonwebtoken.RequiredTypeException: Cannot convert existing claim value of type 'class java.lang.String' to desired type 'class java.util.UUID'. JJWT only converts simple String, Date, Long, Integer, Short and Byte types automatically.
- JWT에 UUID로 바로 담을 수 없고, 간단한 데이터 타입으로 담아야 한다!
참고자료
- https://datatracker.ietf.org/doc/html/rfc4122
- https://www.uuidtools.com/uuid-versions-explained
- https://www.percona.com/blog/tuning-innodb-primary-keys/
- https://stackoverflow.com/questions/56611375/innodb-clustered-index-performance-when-using-random-values-as-primary-key
- https://chanos.tistory.com/entry/MySQL-UUID를-효율적으로-활용하기-위한-노력과-한계
- https://dev.mysql.com/doc/refman/8.4/en/binary-varbinary.html

