

크리스마스에 시작한 클라우드 2기가 어느덧 한 달이 다 되어간다. 코드를 직접 작성하여 제출하고 채점 받는 앨리스 플랫폼에도 어느 정도 익숙해졌다. 특히 이번 주에 수백 번 sql문을 실행해 보면서 머리로 안다는 것과 손가락 끝에서 나오는 바이브의 차이를 확실히 알 수 있었다.

저 위에 찐하게 칠해진 칸이 보이는가? 덕분에 낯설게만 느껴졌던 데이터베이스랑 조금은 친해졌다.
select
select
(무)의식적으로 select 나가는 중
이번 포스팅에는 한 주 동안 허겁지겁 섭취한 개념들을 정리하는 시간을 가져보려고 한다.
데이터베이스
데이터베이스란 한 조직 안에서 여러 사용자와 응용 프로그램이 공동으로 사용하는 데이터들을 통합하여 저장하고 운영하는 데이터를 말한다.
- 기존의 파일시스템의 구조 의존성(응용 프로그램에 직접 연결), 데이터 중복, 무결성 부재(데이터의 정확성, 일관성, 신뢰성 부족) 문제를 해결하기 위해 등장하였다.
- 데이터베이스는 데이터의 삽입, 삭제, 갱신을 통해 최신 데이터를 유지하기 용이하며, 데이터가 저장된 물리적 위치가 아닌 값을 가지고 검색(내용에 대한 참조)할 수 있다.
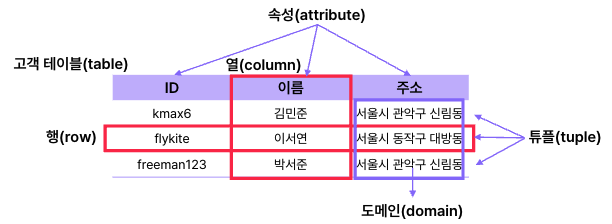
관계형 데이터베이스
데이터가 하나 이상의 열과 행의 테이블(또는 관계)에 저장되어 서로 다른 데이터 구조가 어떻게 관련되어 있는지 쉽게 파악하고 이해할 수 있도록 사전 정의된 관계로 데이터를 구성하는 정보 모음
- 데이터를 행과 열을 가지는 테이블로 표현한다.
- 정의된 테이블(스키마)에 맞게 데이터가 삽입되어 데이터의 안정성을 보장한다.
SQL(Structured Query Language)
관계형 데이터베이스를 활용하기 위해 사용하는 표준 언어를 말한다.
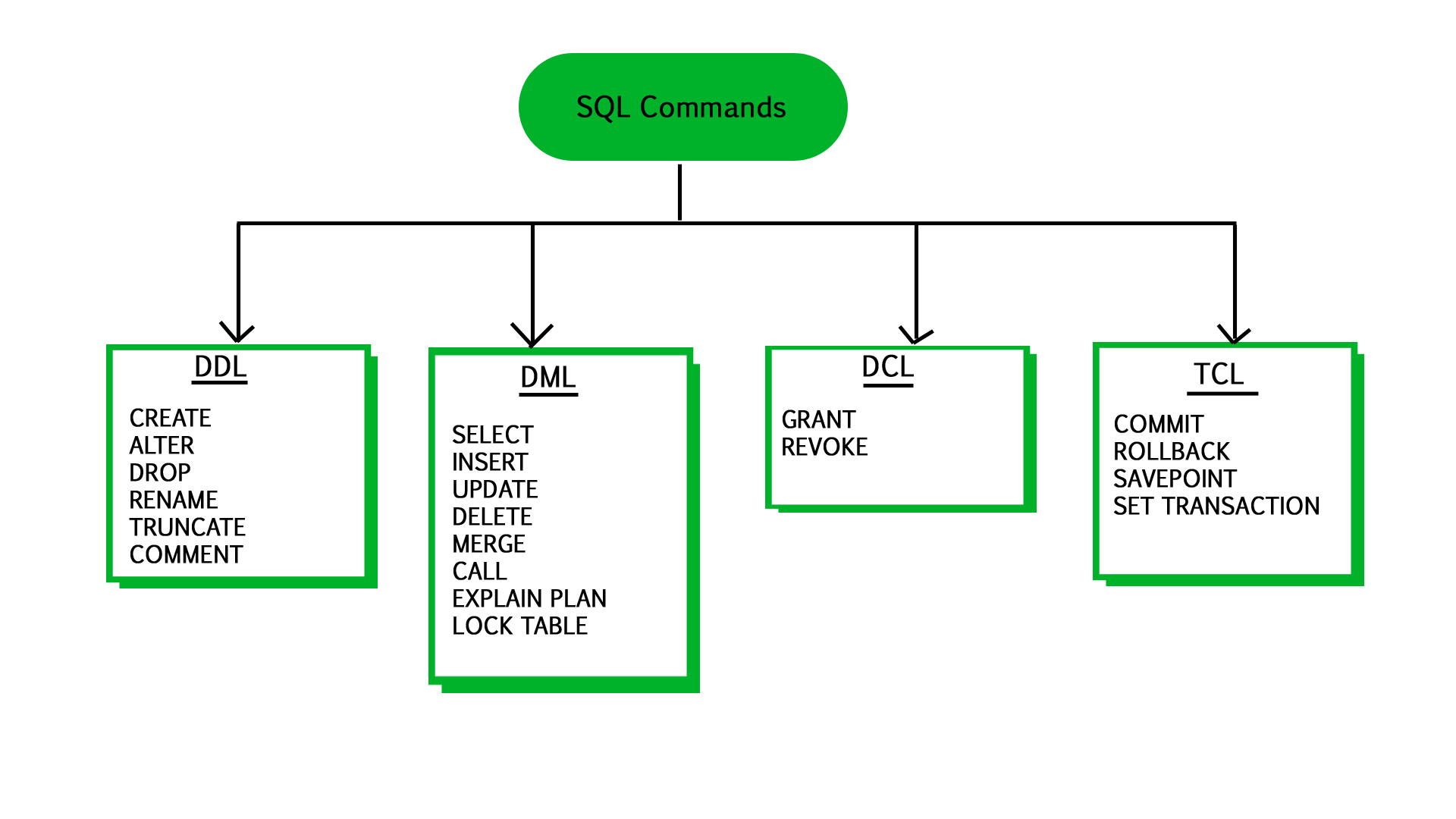
데이터 정의어(DDL, Data Definition Language)
데이터 조작어(DML, Data Manipulation Language)
1. 데이터 조회 및 검색(SELECT)
DISTINCT- 뒤에 나오는 컬럼의 중복을 제거한다.
- 2개 이상의 컬럼을 적으면 한 쪽 컬럼에 중복이 있어도 다른 쪽 컬럼의 값이 다르면 다르게 취급한다.
WHERE- 검색하고자 하는 데이터의 조건을 설정한다.
비교연산자- < : 미만, 초과
- <= : 이상, 이하
- = : 값 지정
- != : ~이 아닌 값
복합조건 연산자- AND, && : A, B 모두 만족하는 값
- OR, || : A 또는 B인 값
- NOT, ! : A가 아닌 값
기타 연산자
- BETWEEN : a ~ b 사이에 포함된 값- IN : b에 a가 포함된 값
- NOT IN : b에 a가 포함되지 않은 값
LIKE- 특정 문자가 포함된 문자열을 찾고 싶을 때 사용하는 명령이다.
- '%치%' : 치가 들어간 문자열
- '치%' : 치로 시작하는 문자열
- '%치' : 치로 끝나는 문자열
ORDER BY- 데이터를 검색할 때 정렬하여 결과를 출력한다.
- ASC 오름차순, DESC 내림차순
COUNT- 테이블 안에 있는 컬럼의 개수를 검색한다.
LIMIT- 데이터의 일부만 보고 싶을 때 사용한다.
SUM,AVG- 총합과 평균을 구하고 싶을 때 사용한다.
MAX,MIN- 최댓값과 최솟값을 찾고 싶을 때 사용한다.
GROUP BY- 데이터를 그룹지을 때 사용한다. 그룹 기준 컬럼을 정해야 한다.
HAVING- 데이터 그룹에 조건을 적용하여 검색한다.
INNER JOIN .. ON ..- 두 테이블의 정보를 한 번에 조회할 수 있다.
LEFT JOIN: 왼쪽 테이블의 모든 값 포함하여 연결한다.RIGHT JOIN: 오른쪽 테이블의 모든 값 포함하여 연결한다.
- 단일 행 서브쿼리 (결과가 한 행)
- 특징
- 괄호와 함께 사용되어야 한다.
- 서브쿼리 안에서 ORDER BY 절은 사용할 수 없다.
- 연산자의 오른쪽에 사용되어야 한다.
- 오로지 SELECT 문에서만 가능하다.
- 단일 행 서브쿼리 연산자
- =, <>, >, >=, <, <=
- 특징
- 다중 행 서브쿼리 (결과가 여러 행)
- 다중 행 연산자
- IN : 하나라도 만족하면 반환
- ANY : 하나라도 만족하면 반환, 비교 연산 가능
- ALL : 모두 만족하면 반환, 비교 연산 가능
- 다중 행 연산자
2. 데이터 추가(INSERT)
3. 데이터 변경(UPDATE)
4. 데이터 삭제(DELETE)
데이터 제어어(DCL, Data Control Language)
- 데이터베이스에 접근하는 권한을 관리하는 등 데이터를 제어한다.
- GRANT, REVOKE - 아래는 TCL이라고 분류하기도 한다
- COMMIT, ROLLBACK
데이터 타입
VARCHAR(n), INT, FLOAT, DATETIME ...
제약조건
- 테이블에 잘못된 데이터가 입력되는 것을 방지하기 위한 규칙이다.
1. NOT NULL
id VARCHAR(10) NOT NULL- 널(NULL)값을 허용하지 않는다.
2. UNIQUE
id VARCHAR(10) UNIQUE- 중복되는 값이 있으면 에러 발생, NULL값은 비교 불가능하여 에러가 발생하지 않는다.
3. DEFAULT
superior VARCHAR(30) DEFAULT '지니'- 기본값을 설정하여 아무런 값을 지정하지 않으면 DEFAULT 값으로 설정된다.
4. CHECK
age INT CHECK(age <= 8)- 값의 범위를 제한하여 벗어날 시 에러가 발생한다.
5. CONSTRAINT 제약 조건 정의
CONSTRAINT [제약조건이름] [제약조건](UNIQUE, CHECK, ...) [적용할 속성);
CONSTRAINT id_unique UNIQUE (id),
CONSTRAINT age_check CHECK (age <= 8)
-- 제약 조건 변경
ALTER TABLE bookstore ADD CONSTRAINT minimum_price CHECK (price >= 0);6. 제약 조건 삭제
ALTER TABLE [테이블명] DROP CONSTRAINT [제약조건이름]
ALTER TABLE item DROP CONSTRAINT age_check키
조건에 만족하는 튜플을 찾거나 정렬할 때 기준이 되는 속성
1. 기본키(Primary Key)
- 서로 다른 튜플을 유일하게 식별할 수 있는 기준이 되는 속성을 말한다.
- 중복되는 값을 가질 수 없다.- 널 값을 가질 수 없다.
- 테이블 당 1개만 설정할 수 있다.
2. 외래키(Foreign Key)
- 다른 테이블의 기본키를 참조하는 속성으로 테이블의 관계를 정의한다.
- 참조되는 테이블의 기본키에 없는 값은 지정할 수 없다.
CREATE TABLE item(
id INT PRIMARY KEY,
name VARCHAR(30)
);
CREATE TABLE order_history(
item_id INT,
order_id INT,
FOREIGN KEY (item_id) REFERENCES item(id),
CONSTRAINT order_history_pk PRIMARY KEY (item_id, order_id)
);- 후보키: 기본키가 될 수 있는 키로 유일성과 최소성을 만족한다.
- 대체키: 후보키 중에 기본키가 아닌 키를 말한다.
- 슈퍼키: 튜플을 식별할 수 있는 유일성은 만족하지만 최소성은 만족하지 않는 키를 말한다.
무결성 제약 조건
- 개체 무결성: 기본키는 널 값과 중복된 값을 가질 수 없다.
- 참조 무결성: 외래키는 널이거나 참조되는 릴레이션의 기본키 값과 동일하다.
- 도메인 무결성, NULL 무결성, 고유 무결성, 키 무결성
이상 현상과 정규화
이상현상(Anomaly)
- 잘못된 데이터베이스 설계로 발생하는 오류
- 삽입 이상, 갱신 이상, 삭제 이상
함수 종속성
- X -> Y 관계
- 어떤 속성 X의 한 값이 다른 속성 Y에 속한 하나의 값에만 매핑되는 경우를 말한다.- X를 결정자, Y를 종속자라고 한다.
정규화
이상현상을 제거하기 위해 데이터베이스를 구조화하는 과정을 말한다.
- 데이터 간의 종속성을 제거하여 중복되는 데이터를 줄인다.
- 데이터의 일관성과 무결성을 보장한다.
1차 정규화
테이블의 컬럼이 하나의 값만 갖도록 도메인을 원자값으로 설정하는 과정을 말한다.
2차 정규화
부분 함수 종속을 제거하고 완전 함수 종속이 되도록 테이블을 분해하는 과정을 말한다.
- 기본키를 구성하는 속성 중 일부가 결정자 역할을 하는 경우에 부분 함수 종속이 발생할 수 있다.
- 기본키가 복합키일 때 부분 함수 종속이 발생할 수 있다.
3차 정규화
이행 함수 종속을 제거하도록 테이블을 분해하는 과정을 말한다.
- X -> Y, Y -> Z라는 종속 관계가 있을 때, X -> Z가 성립하는 경우 이행 함수 종속이 발생할 수 있다.
- 이외에도 BCNF, 4차 정규화, 5차 정규화가 있다.
역정규화
정규화된 데이터베이스의 성능을 개선하기 위해 다시 통합하여 구조를 재구성하는 것을 말한다.
인덱스(Index)
- 데이터베이스 테이블의 검색 속도를 향상 시키기 위한 자료구조를 말한다.
- 장단점
- 일반적으로 인덱스를 사용하면 테이블을 조회하는 속도와 성능이 올라가지만, 인덱스를 관리하기 위한 추가 작업이 필요하다. 또한, 인덱스를 저장할 추가 저장 공간이 필요하다. - 사용 전략
- 규모가 큰 테이블
- 데이터의 삽입, 수정, 삭제 작업이 많지 않은 컬럼
- WHERE 조건절이나 ORDER BY(정렬), JOIN을 자주 하는 컬럼
- 데이터의 중복도가 낮은 컬럼
CheatSheet
데이터베이스 생성, 사용, 삭제하기
-- 데이터베이스 생성하기
CREATE DATABASE electronic_car;
-- 생성한 데이터베이스 확인하기
SHOW DATABASES;
-- 데이터베이스 사용하기
USE electronic_car;
-- 데이터베이스 삭제하기
DROP DATABASE electronic_car;사용자 생성, 권한 부여, 확인, 제거하기
-- 사용자 생성하기
CREATE USER juny@localhost IDENTIFIED BY '1234';
-- 권한 부여하기
GRANT ALL PRIVILEGES ON electronic_car.* TO juny@localhost;
-- 설정 권한 적용하기
FLUSH PRIVILEGES;
-- 권한 확인하기
SHOW GRANTS FOR juny@localhost;
-- 권한 제거하기
REVOKE ALL ON electronic_car.* FROM juny@localhost;테이블 확인하기
SHOW TABLES;테이블 구조 확인하기
DESC item;테이블 정의하기
CREATE TABLE item(
id VARCHAR(10),
name VARCHAR(30),
customer_id VARCHAR(10),
FOREIGN KEY (customer_id) REFERENCES customer(customer_id)
);테이블 수정하기
ALTER TABLE item ADD COLUMN price INT NULL; // 컬럼 추가
ALTER TABLE item MODIFY COLUMN id VARCHAR(15) NOT NULL // 컬럼 변경
ALTER TABLE item CHANGE COLUMN name item_name VARCHAR(30) NOT NULL // 컬럼 이름 변경
ALTER TABLE item DROP COLUMN isbn; // 컬럼 삭제
ALTER TABLE item RENAME cleaning_item; // 테이블 이름 변경테이블 삭제하기
DROP TABLE member; 데이터 검색하기
SELECT DISTINCT name FROM item WHERE name = '치킨';
---
SELECT * FROM item WHERE price >= 50000;데이터 삽입하기
INSERT INTO item (id, name) VALUES ('1', '호빵');
---
INSERT INTO item VALUES ('1', '호빵');데이터 수정하기
UPDATE item SET item_name = '막대사탕(딸기맛)' WHERE item_name = '막대사탕';데이터 삭제하기
DELETE FROM item WHERE item_name = '막대사탕(딸기맛)';서브쿼리
SELECT * FROM employee WHERE payment >
(SELECT * FROM employee WHERE payment > 2500);스칼라 서브쿼리
SELECT students.name, (
SELECT math
FROM middle_test as m
WHERE m.student_id = students.student_id
) AS middle_avg
FROM students;인덱스 추가, 확인, 삭제하기
CREATE INDEX item_index ON item(id);
-- 인덱스 확인하기
SHOW INDEX FROM item;
-- 인덱스 삭제하기
ALTER TABLE item DROP INDEX item_index;#코딩독학 #코딩인강 #코딩배우기 #개발자 #코딩이란 #코딩교육
#프론트엔드부트캠프 #백엔드부트캠프 #국비지원부트캠프 #개발자 #백엔드 #AI부트캠프 #개발자국비지원 #백엔드개발자 #프론트엔드개발자
