

JOIN
- 두 개 이상의 테이블을 연결하여 데이터를 출력하는 명령어를 말한다.
- JOIN 연산자를 이용해 관련 있는 컬럼 기준으로 행을 합치는 연산이다.
1. 내부 조인(Inner Join)
- 두 테이블 간 교집합을 반환한다. Inner를 생략할 수 있다.
select id, s.name
from student s
join attendance a
on s.id = a.student_id
where a.student_id is null;USING
- 두 테이블에서 같은 이름을 가진 컬럼을 기준으로 조인할 때 사용된다. Inner Join, Left join, Right join 등에 함께 사용된다.
select *
from order
join customer using(customer_id)2. 자연 조인(Natural Join)
- 두 테이블 간 동일한 이름을 갖는 모든 컬럼을 기준으로 등가 조인한다. 명시적인 조인 조건(ON, USING)을 사용할 수 없다. 예상치 못한 결과를 초래할 수 있므르로 실무에서는 잘 사용되지 않는다고 한다.
SELECT * FROM student NATURAL JOIN test;3. 왼쪽 외부 조인(Left Outer Join)
- 왼쪽 테이블을 기준으로 조인한다. outer 키워드는 생략할 수 있다.
select *
from order
left outer join customer using(customer_id)4. 오른쪽 외부 조인(Right Outer Join)
- 오른쪽 테이블을 기준으로 조인한다. outer 키워드는 생략할 수 있다.
select *
from order
right outer join customer using(customer_id)5. 전체 외부 조인(Full Outer Join)
- Mysql에서는 전체 외부 조인을 지원하지 않는다. 두 테이블의 전체 조합을 얻기 위해서 Left Outer Join과 Right Outer Join을 구한 후 이를 Union하여 구할 수 있다.
select o.order_id, o.item_name, c.customer_name
from order o
left outer join customer c
on o.id = c.order_id
union
select o.order_id, o.item_name, c.customer_name
from order o
right outer join customer c
on o.id = c.order_id6. 셀프 조인
- 동일 테이블에서 특정 관계 데이터를 추출하기 위해 셀프 조인을 사용할 수 있다. 테이블을 지칭하는 별도의 식별자가 필요하다.
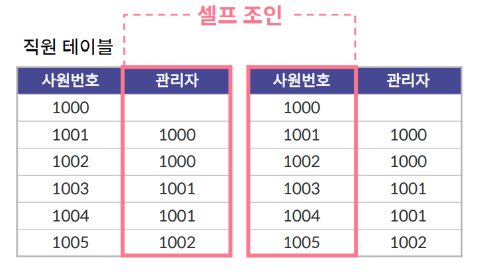
select a.employee_id, a.employee_name, b.employee_name as manager_name
from EMPLOYEE a
join EMPLOYEE b
on a.manager_id = b.employee_id서브쿼리
- select문 안에 다시 select문이 기술된 형태의 쿼리를 말한다.
1. 스칼라 서브쿼리(Scalar Sub-query)
- 하나의 속성을 가지면서 하나의 행만 반환하는 쿼리이다. 이는 select, where, having 절에서 사용 가능하다.
- 각 부서에서 가장 많은 급여를 받는 직원들의 정보를 조회하는 스칼라 서브쿼리는 다음과 같이 작성할 수 있다.
select e.name, e.salary, d.department_name
from employees e
join departments d
on e.department_id = d.id
where e.salary = (
select max(salary)
from employees
where department_id = e.department_id
);2. 인라인 뷰 서브쿼리(Inline Views Sub-query)
- from 절에서 사용되며 일시적인 테이블을 생성하는 데 사용된다. 이 테이블은 쿼리 실행시에만 존재한다. 이와 유사한 CTE와 비교해보면 하나의 쿼리 스크립트 안에서 CTE는 함수로 동작하는 개념이고, 인라인 뷰 서브쿼리는 람다로 동작하는 것과 유사하다. 재사용성에 차이가 있다.
select e.name
from (select name, department_id from employees) AS e
WHERE e.department_id = 1;3. 중첩 서브쿼리(Nested Sub-query)
1) 단일행 서브쿼리
- 서브쿼리의 결과가 한 개의 행만 반환하며, 단일행 비교 연산자(=, <, >, <=, >=)와 같이 사용된다.
select id, name, salary
from employee
WHERE department_id = (
select department_id
from employee
where name = 'juny');2) 다중행 서브쿼리
- 서브쿼리의 결과가 두 개 이상의 행을 반환하며 다중 행 비교 연산자(In, All, Any, Exists)와 함께 사용된다.
- In: 서브쿼리 결과에 존재하는 값들 중 하나와 일치하는 경우
- Exists: 서브쿼리 결과 값이 존재하는지 확인
- All: 서브쿼리 결과에 존재하는 모든 값들에 대해 조건을 만족하는 경우
- Any: 서브쿼리 결과에 존재하는 값들 중 조건을 만족하는 것이 하나 이상 존재하는 경우
select name from employee
where deparment_id in (
select id
from department
where name = '개발' OR NAME = '영업');1) 연관 서브쿼리
- 메인쿼리의 컬럼이 서브쿼리에 포함되며, 메인쿼리의 컬럼은 서브쿼리에 특정 조건으로 사용된다.
select id, department_id, name, salary
from employee a
where salary > (
select avg(salary)
from employee b
where b.department_id = a.department_id
);2) 비연관 서브쿼리
- 메인쿼리의 컬럼이 서브쿼리에 포함되지 않으며, 주로 메인쿼리에 특정한 값을 제공할 때 사용된다.
select id, name, salary
from employee
WHERE department_id = (
select department_id
from employee
where name = 'juny');

꾸준하게