
최근 신규 프로젝트를 배포한 후, AWS MSK의 디스크 사용량이 급증하는 문제가 생겼다. 예상보다 훨씬 빠른 속도로 특정 토픽들에 메시지가 쌓이고 있는 것이 원인이었고 다행히 해당 토픽의 데이터는 장기간 보관할 필요가 없어서 retention.ms을 1시간으로 변경하는 것으로 대응했다. 이 과정은 Kafka의 리텐션 정책을 다시 돌아보는 계기가 됐다. MSK 대시보드의 수많은 설정 중, 이번 글에서는 데이터의 생명 주기와 직결되는 Retention 관련 설정에 대해서만 집중적으로 다뤄보려고 한다.
Kafka에서 데이터가 얼마나 오래 저장될지는 리텐션 정책(Retention Policy)에 의해 결정된다.
cleanup.policy 설정값에 따라 크게 두 가지로 나눌 수 있다.
cleanup.policy=delete
default 설정값이다. 설정된 시간(retention.ms)이나 크기(retention.bytes)를 초과한 데이터를 물리적으로 삭제한다.
retention.ms: 데이터가 보관될 최대 시간 (default: 7일). 이 시간을 초과한 로그 세그먼트는 삭제 대상이다.retention.bytes: 각 파티션이 가질 수 있는 최대 크기 (default: 10GB). 파티션 크기가 이 값을 초과하면 가장 오래된 로그 세그먼트부터 삭제된다.
그리고 위 두 설정값은 OR 조건으로 동작한다. Log Manager의 삭제 스레드가 log.retention.check.interval.ms 마다 실행되면서 둘 중 하나의 조건이라도 만족하면 데이터 삭제 작업을 수행한다.
log.retention.check.interval.ms: 리텐션 정책(삭제 대상)을 확인할 백그라운드 스레드의 실행 간격
kafka는 메시지를 하나하나 지우는 방식이 아니라, 로그 세그먼트 파일 단위로 이루어지기 때문에 retention은 segment 설정과도 밀접한 관련이 있다.
retention.ms가 1일로 설정되어있어도, 특정 메시지가 1일이 지났다고해서 즉시 삭제되는 것이 아니라 해당 메시지가 포함된 세그먼트 전체가 삭제 조건을 만족해야 파일이 삭제된다. 그래서 segment.bytes 설정이 매우 크다면 우리의 예상보다 데이터가 오래 남아있을 수 있기 때문에 해당 설정도 함께 검토해야 한다.
cleanup.policy=compact
메시지 키를 기준으로 각 키의 가장 마자막 값만 유지하는 정책이다. 키가 동일한 새로운 메시지가 들어오면 이전 메시지는 삭제(압축) 대상이 된다. 따라서 데이터의 최종 상태를 추적하는 용도에 유용하다.
cleanup.policy가 compact 단독으로 설정된 경우에는retetnion.ms, retention.bytes 설정은 아무런 역할을 하지 않는다. 이 정책의 목표는 '오래된 데이터 삭제'가 아니라 'Key 별로 최신 데이터만 남기는 것'이기 때문에.
나는 이 정책의 동작 원리가 궁금해서 찾아봤다. 로그 세그먼트 파일을 직접 수정 하는 것인가? 이는 Kafka의 모든 로그 세그먼트는 불변이기 때문에 불가능하다.
동작 원리는 다음과 같다.
compact는 Kafka 브로커의 백그라운드 스레드인 로그 클리너(Log Cleaner)가 오래된 세그먼트를 읽어 필요한 데이터만 남긴 새로운 세그먼트를 만든 후, 기존 세그먼트를 통째로 교체하는 방식으로 동작한다.
조금 더 자세히 말하자면, log.cleaner.backoff.ms (default: 15초) 주기로 로그 클리너가 깨어나 압축 대상을 찾고 min.cleanable.dirty.ratio (default: 0.5) 설정을 확인하고, dirty 부분의 비율이 이 값을 넘으면 압축 시작을 준비한다. 로그 클리너는 오직 비활성 세그먼트들만을 대상으로 압축을 수행한다.
Active Segment: 현재 새로운 메시지가 쓰이고 있는 가장 마지막 세그먼트 파일. 활성 세그먼트는 절대 압축 대상이 되지 않는다.Inactive Segments: 더 이상 데이터가 쓰이지 않고 닫힌 이전 세그먼트 파일.
또한, 로그는 논리적으로 Clean/Dirty 부분으로 나뉜다.
Clean: 압축되어 모든 키에 대해 유일한 값만 존재하는 로그의 앞부분Dirty: 아직 압축되지 않아 키 중복 있을 수 있는 로그의 뒷부분
따라서 Dirty Ratio = 전체 로그의 바이트(Byte) 크기 / Dirty 부분의 바이트(Byte) 크기이다.
해당 비율은 로그 클리너가 너무 자주, 그리고 너무 적은 양의 데이터를 처리하느라 자원(CPU, I/O)을 낭비하는 것을 막기 위한 장치이며 Clean과 Dirty의 경계는 세그먼트 파일 단위가 아니라 특정 오프셋(Offset)이다.
로그 클리너는 Dirty 로그를 처음부터 끝까지 읽고, {Key, 마지막 메시지의 Offset} 형태의 인메모리 맵을 생성한다. 따라서 스캔이 끝나면, 각 키의 가장 마지막 버전이 어떤 오프셋에 있는지 알 수 있다.
이후 새로운 임시 세그먼트 파일(.cleaned)을 만들고, 다시 원본 세그먼트들을 읽으면서 읽고 있는 메시지의 {Key, Offset} 맵에 기록된 값과 일치하면, 그 메시지는 최신 값이므로 새로운 .cleaned 세그먼트 파일에 복사한다.
모든 복사가 끝나면, Kafka는 원본 세그먼트 파일을 새로 만든 .cleaned 세그먼트 파일로 원자적(atomic)으로 교체하고 기존의 낡은 세그먼트 파일은 삭제된다.
다이아그램으로 보면 아래와 같다.
[원본 비활성 세그먼트 파일]
(offset 10, key: A, value: v1)
(offset 11, key: B, value: v1)
(offset 12, key: A, value: v2)
|
| <--- 로그 클리너 스레드가 처리 (키의 마지막 오프셋을 추적하는 인메모리 맵 생성)
|
[새로운 .cleaned 임시 세그먼트 파일 생성]
(offset 11, key: B, value: v1) // 복사
(offset 12, key: A, value: v2) // 복사
|
| <--- 작업 완료 후 원자적으로 교체 (Swap)
|
[새로운 압축된 세그먼트 파일]
(offset 11, key: B, value: v1)
(offset 12, key: A, value: v2)그렇다면 Compact 정책에서 특정 키의 데이터를 완전히 삭제하려면 어떻게 해야할까?
해당 키에 value가 null인 메시지를 보내면 된다. 이 메시지를 Tombstone(묘비석)이라 부른다. (Tomb는 무덤이라는 뜻)
로그 클리너는 이 Tombstone을 보고 해당 키의 모든 이전 데이터를 삭제하며, Tombstone 자체도 delete.retention.ms (default: 24시간)가 지나면 삭제한다. 이는 모든 컨슈머가 키 삭제 이벤트를 인지할 시간을 보장하기 위함이다.
키의 값이 빠르게 변경될 때, 이전 값이 너무 빨리 압축되어 사라지는 것을 막기 위한 min.compaction.lag.ms 라는 설정도 있다. 메시지가 토픽에 기록된 후 최소한 이 시간 동안은 압축되지 않도록 보장한다. 따라서 모든 상태 변화를 순서대로 처리해야 하는 컨슈머를 보호할 수 있게 된다. (delete 정책에서는 의미 없는 설정)
compact, delete 모두 설정 (하이브리드 방식)
cleanup.policy에 compact, delete 두 가지를 모두 설정하는 것도 가능하다. 이 경우 Kafka는 먼저 압축(compact)을 통해 키별 최신 값만 남긴 후, 그 데이터에 대해 삭제(delete) 정책(retention.ms/bytes)을 적용하여 오래된 데이터를 최종적으로 삭제한다.
정리
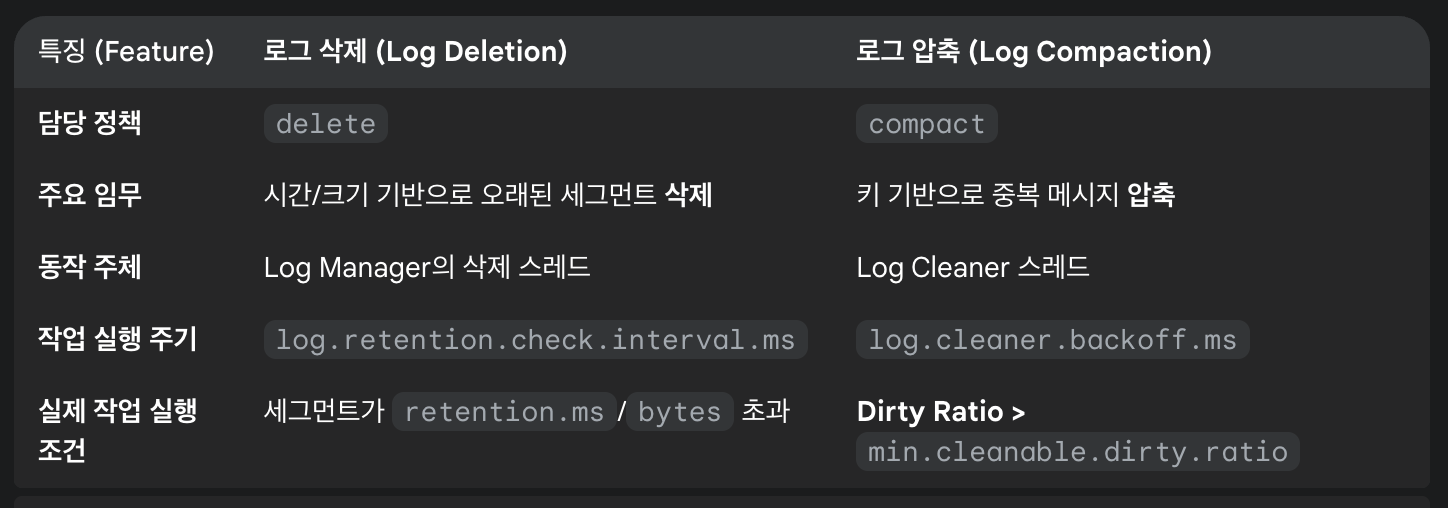
Gemni가 지금까지의 내용을 표로 간단하게 정리해줬다. 이번 경험을 통해 Kafka의 리텐션 정책을 명확히 구분할 수 있게 되었다. 시간/크기 기반으로 데이터를 삭제하는 delete와, 키(Key)를 기준으로 최신 값만 남기는 compact가 완전히 다른 설정과 동작 방식을 가진다는 것을 이해했다. 이제는 데이터의 특성에 따라 정책 및 관련된 세부 설정들을 고려해볼 수 있을 것 같다.
