
📝문제1. 백준 2562번
- 문제
https://www.acmicpc.net/problem/2562
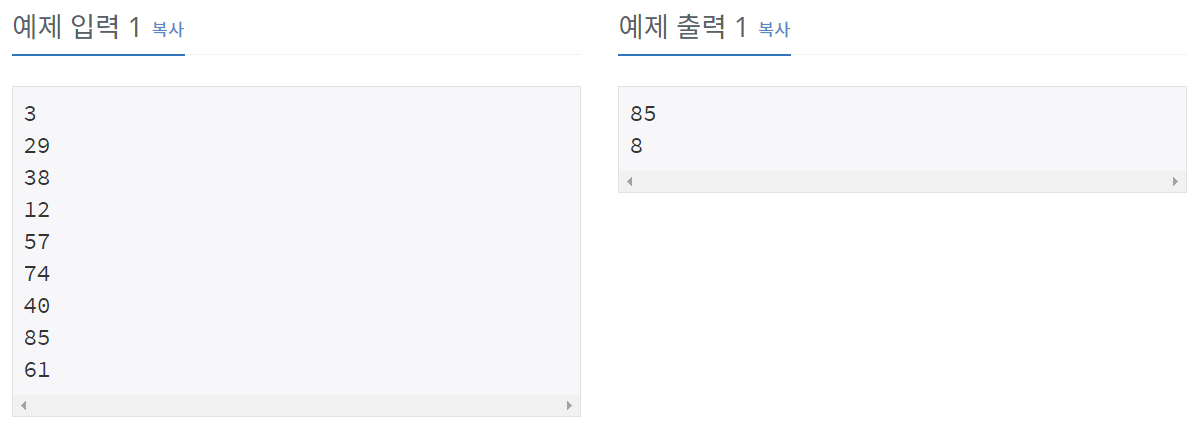
9개의 서로 다른 자연수가 주어질 때, 이들 중 최댓값을 찾고 그 최댓값이 몇 번째 수인지를 구하는 프로그램을 작성하시오.
예를 들어, 서로 다른 9개의 자연수
3, 29, 38, 12, 57, 74, 40, 85, 61
이 주어지면, 이들 중 최댓값은 85이고, 이 값은 8번째 수이다.
입력
첫째 줄부터 아홉 번째 줄까지 한 줄에 하나의 자연수가 주어진다. 주어지는 자연수는 100 보다 작다.
출력
첫째 줄에 최댓값을 출력하고, 둘째 줄에 최댓값이 몇 번째 수인지를 출력한다.
- 코드💻
alist = []
for _ in range(9):
alist.append(int(input()))
print(max(alist))
print(alist.index(max(alist)) + 1)

✔️ 개념 복습
리스트에서 특정 원소의 인덱스 값을 알고 싶다면 alist.index('1') 문법을 이용하면 간편하게 구할 수 있다. -> alist라는 리스트에 있는 '1'이라는 원소가 몇 번째에 있는지 알고 싶은 경우
📝문제2. 백준 1316번
- 문제
https://www.acmicpc.net/problem/1316
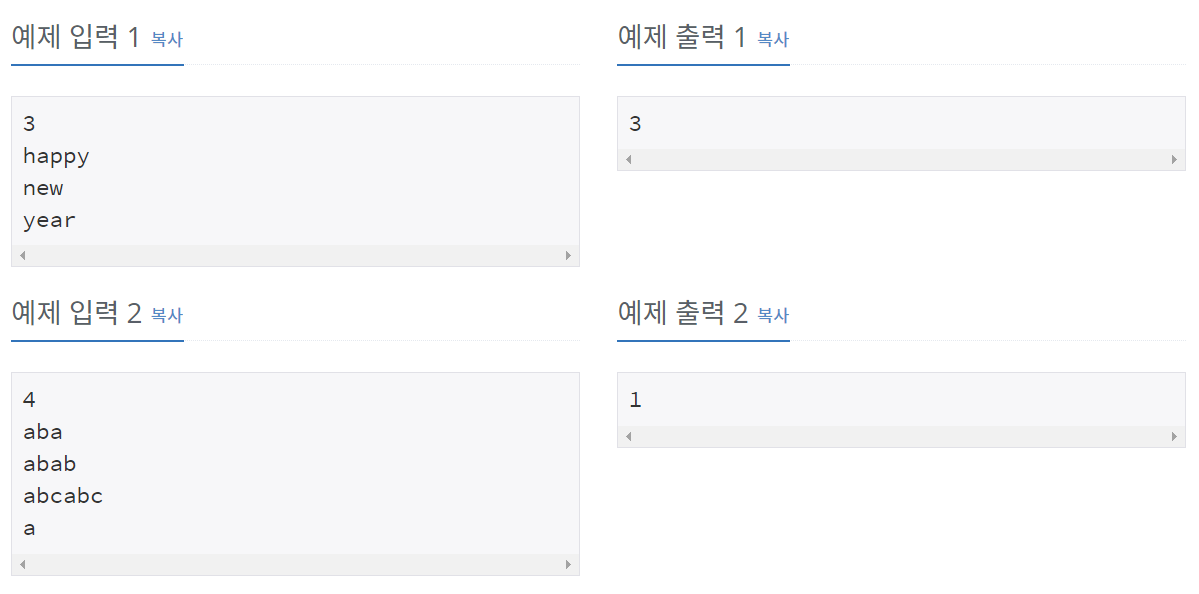
그룹 단어란 단어에 존재하는 모든 문자에 대해서, 각 문자가 연속해서 나타나는 경우만을 말한다. 예를 들면, ccazzzzbb는 c, a, z, b가 모두 연속해서 나타나고, kin도 k, i, n이 연속해서 나타나기 때문에 그룹 단어이지만, aabbbccb는 b가 떨어져서 나타나기 때문에 그룹 단어가 아니다.
단어 N개를 입력으로 받아 그룹 단어의 개수를 출력하는 프로그램을 작성하시오.
입력
첫째 줄에 단어의 개수 N이 들어온다. N은 100보다 작거나 같은 자연수이다. 둘째 줄부터 N개의 줄에 단어가 들어온다. 단어는 알파벳 소문자로만 되어있고 중복되지 않으며, 길이는 최대 100이다.
출력
첫째 줄에 그룹 단어의 개수를 출력한다.
- 코드💻
n = int(input())
vlist = []
for i in range(n):
vlist.append(input())
check = 0 # 그룹단어이면 1, 아니면 0
count = 0 # 그룹단어 개수
mlist = [] # 단어의 문자를 저장할 변수 (중복 피하기 위해)
for i in vlist:
# 단어 길이가 1이나 2이면 그룹단어로 취급
# (a/ab/aa 세 경우만 있기 때문)
if len(i) <= 2:
count += 1
# 단어 길이가 3 이상인 경우
else:
# 0번째 원소 먼저 저장
mlist.append(i[0])
# (단어 길이 - 1) 만큼 반복(비교)
for k in range(len(i) - 1):
if i[k] == i[k + 1]:
# 연속해서 계속 같은 원소가 나온다면 '일단'은 그룹단어임
check = 1
else: # i[k] != i[k+1]인 경우
if i[k + 1] in mlist:
# 이미 존재하는 원소라면 '완전' 그룹단어 아님
check = 0
break
else:
# 처음 나오는 원소라면 '일단'은 그룹단어임
mlist.append(i[k])
check = 1
if check == 1:
count += 1
# 초기화 (새로운 단어)
check = 0
mlist = []
print(count)
- 다른 코드💻
n = int(input())
count = n
for _ in range(n):
word = input()
for i in range(len(word) - 1):
if word.find(word[i]) > word.find(word[i+1]):
count -= 1
break
print(count)- 과정📖
처음엔 문제 자체가 이해가 안가서 여러번 읽어보았다.. 그룹단어라는 말이 어려웠는데, 이해한 결과 -> 한 문자가 연속해서 여러번 나오는 것은 괜찮지만, 연달아 나오는 것이 아니라 다른 문자가 나온 뒤에 또 다시 나오는 것은 안된다. 이런 의미였다. (맞나?) 예를 들어 aabbcc는 되지만, aabbcca는 안된다.
그래서 이해한 것을 바탕으로 그냥 단순하게 코드를 구현했다. 주석을 달아 두었는데, 옳은 설명인지와 이해가 가게 달아두었는지는 잘 모르겠다.. 그리고 너무 비효율적인 방식으로 푼 것 같다. 다른 풀이를 찾아보니 훨씬,,, 간단하게 풀 수 있는 문제였다. 나는 굉장히 오래 걸렸고 중간중간 계속 조건을 넣어줘야 했는데 이렇게 짜면 훨씬 간단하게 금방 짤 수 있을 것 같다! 이런 간결하고 깔끔한 코드를 짜기 위해 더 노력해야겠다,,

✔️ 개념 복습
a라는 원소가 list에 있는지 없는지 확인하는 방법
1. if a in alist: or if a not in alist:
2. alist.find(a) -> 특정 원소를 찾고 인덱스 값을 반환해줌. 만일 없다면 -1 반환. (여러개 있는 경우 맨 처음 것의 인덱스 값 반환)
📝문제3. 문자열 압축
- 문제
https://programmers.co.kr/learn/courses/30/lessons/60057
- 정답 코드💻
def solution(s):
least_length = len(s)
temp = 0
# 문자열의 길이를 반으로 자름
# 길이의 반을 넘어서면 어차피 두 문자열로 나뉘기 때문.
for i in range(1, len(s)//2 + 1):
# zip 함수에 문자열, n 전달
temp = zip(i, s)
if temp < least_length:
least_length = temp
return least_length
# 문자열을 n개 단위로 잘라 압축하고, 압축된 문자열의 길이를 반환해주는 함수
def zip(num, s):
i = 0
zip_list = []
while True:
if i+num > len(s):
zip_list.append(s[i:])
break
else:
zip_list.append(s[i:i+num])
i = i+num
my_zip = ""
before = zip_list[0]
count = 1
for i in range(1, len(zip_list)):
curr = zip_list[i]
# 앞에 나온 것과 계속 같은 것이 나온다면
if curr == before:
# 나온 횟수 저장
count += 1
# 앞에 나온 것과 다른 것이 나온다면
# 저장된 횟수만큼 압축 문자열에 추가
else:
if count == 1:
my_zip = my_zip + before
else:
my_zip = my_zip + str(count) + before
count = 1
before = curr
my_zip = my_zip + before
return len(my_zip)- 비교 분석📖
https://grapetown.tistory.com/2
여러 정답 코드 중 이 글을 참고했다..
뭔가 나에게 맞는 코드를 찾는 것도 어려운 것 같다
좀 많이 어렵게 느껴짐,,,!!
📝문제4. 기둥과 보 설치
- 문제
https://programmers.co.kr/learn/courses/30/lessons/60061
- 정답 코드💻
def isValid(answer):
for x,y,a in answer:
if a==0:
if (x,y-1,0) in answer or (x-1,y,1) in answer or (x,y,1) in answer or y==0:
continue
else:
return False
if a==1:
if (x,y-1,0) in answer or (x+1,y-1,0) in answer or ((x-1,y,1) in answer and (x+1,y,1) in answer):
continue
else:
return False
return True
def solution(n, build_frame):
answer = set()
for x,y,a,b in build_frame:
if b==0:
answer.remove((x,y,a))
if not isValid(answer):
answer.add((x,y,a))
else:
answer.add((x,y,a))
if not isValid(answer):
answer.remove((x,y,a))
answer = [list(i) for i in answer]
answer.sort(key=lambda x:(x[0],x[1],x[2]))
return answer- 비교 분석📖
처음 봤을 때 시뮬레이션 문제 같아서 하나하나 조건을 세부적으로 만들어가며 풀려고 했는데 너무 복잡해지고 길어져서 중간에 포기했다,, 잘 안되기도 했고,, 여러 코드를 찾아봤는데 이렇게 간단한 코드가 있었다,, 휴 뭔가 문제가 길고 조금만 어려운 것 같으면 집중이 잘 안되는 것 같다. 두렵게 생각하지 말고 일단 문제를 이해하는 것부터 시작해봐야겠다,,!
https://yjyoon-dev.github.io/kakao/2020/12/21/kakao-pillarfloor/
참고 블로그!
✔️ 개념 복습 - set(집합)
set : 파이썬에서 집합의 개념. 순서가 없고, 집합 내에서는 유일한 값을 가짐.
s2 = set("Hello")
s2
{'e', 'H', 'l', 'o'}
순서가 없기 때문에 인덱스로 값에 접근할 수 없다. 만일 값에 인덱스를 통해 접근하고 싶다면 리스트나 튜플로 변환 후 사용해야 한다. 교집합, 합집합, 차집합을 사용하는 경우 유용하게 사용된다고 한다.
1개의 값 추가 -> add
여러개의 값 추가 -> update
특정 값 제거 -> remove
**
+ 람다 문법 참고 글**
https://velog.io/@oaoong/Python-lambda-%ED%91%9C%ED%98%84%EC%8B%9D
문제 출처 : 백준, 프로그래머스 홈페이지
#. 주절주절🔨
알고리즘 너무 어렵다,, 뭔가 길어지니까 더 어려워지는 것 같기도 하고,, 오늘 마지막 두 문제 같은 문제들이 실제 테스트에서 나온다고 생각하니 아찔,, 더 열심히 하자,,, 그리고 죠르디,, 무지에 이어 너도 아웃이야 

3개의 댓글

안녕하세요 알고리줌입니다...
오늘은 문제가 너무 어려워서 우울하네여
index알아내는 내장함수가 잇는지 몰랏는데 좋은 정보 감사합니다
오늘 너무 고생많으셧습니다!

끝까지 풀어내셨군요...
저도 여기저기 힌트를 얻었는데도...한번에 이해가 안되더라구요..
개념복습한 것까지 올려주시니 저도 여기서 복습하고 갑니다:)
안녕하세요, 김덕우입니다! '죠르디,, 무지에 이어 너도 아웃이야' --> 이부분 읽고 진짜 많이 웃었어요ㅋㅋㅋㅋㅋㅋㅋ 오늘 문제가 많이 어려워서 힘들었는데, 웃음을 주셔서 감사합니다! 코드가 길어지더라도 포기하지 않고 끝까지 푸시는 게 항상 대단한 것 같아요. 그 시간들이 모여 웃음님의 실력이 될 거라고 확신합니다. 오늘 너무 고생하셨습니다!!!