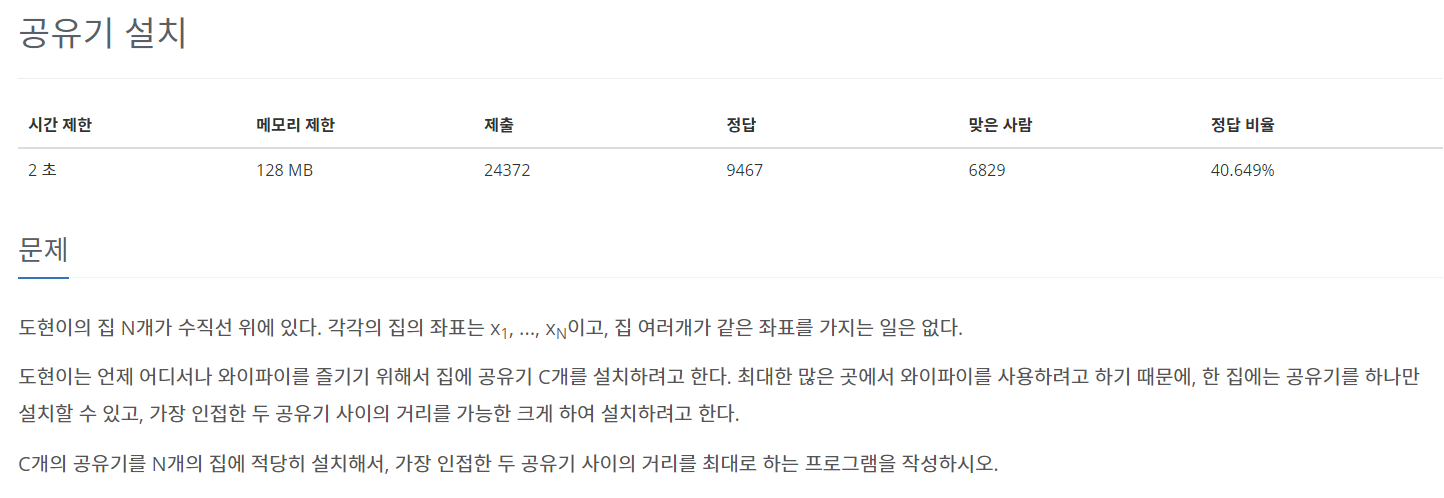
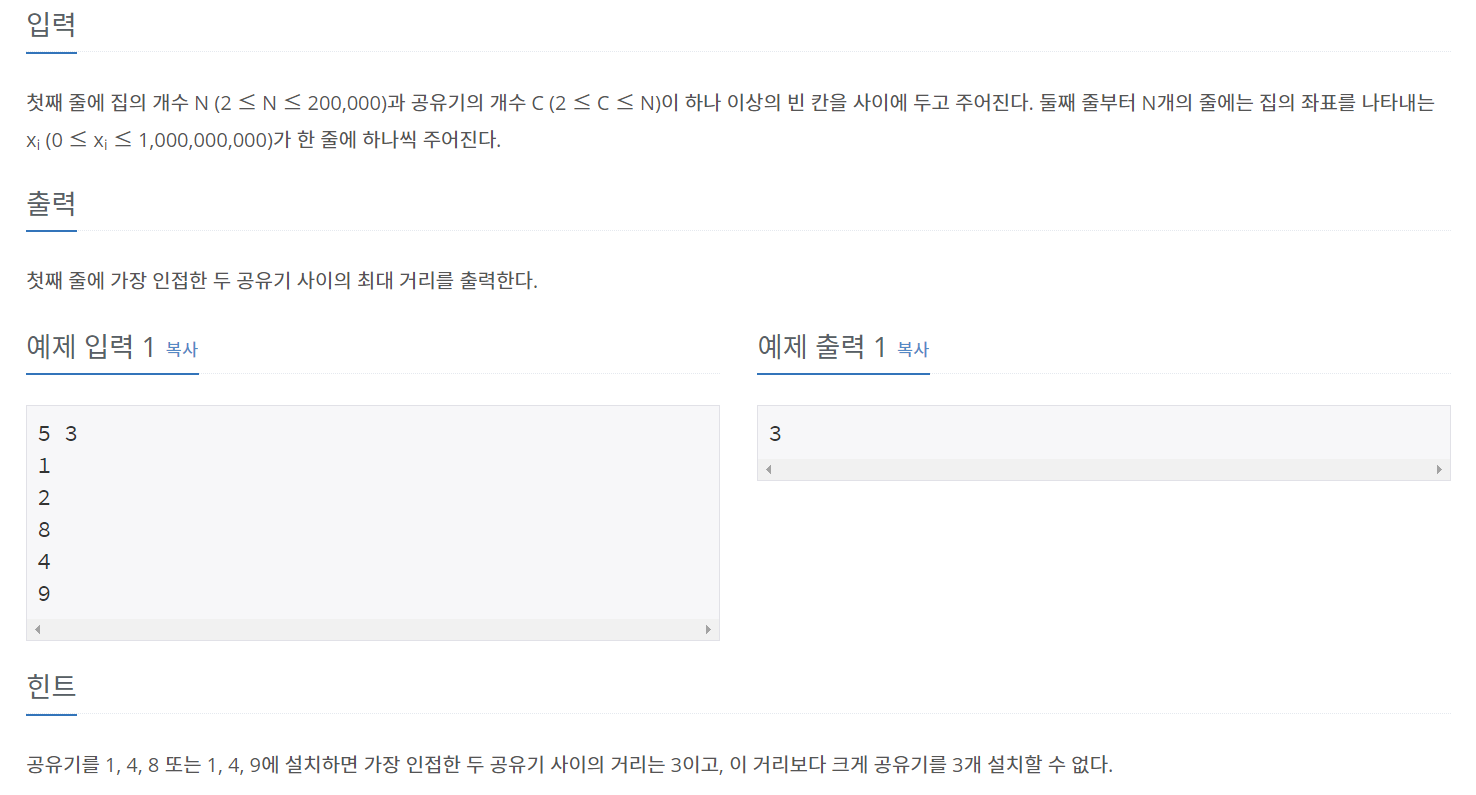
📝문제1. 백준 2110번(공유기 설치)
- 문제
https://www.acmicpc.net/problem/2110
- 나의 코드💻
코드를 입력하세요- 정답 코드💻
1. 블로그 참고
from sys import stdin
# n : 집의 개수 / c : 공유기의 개수
n, c = map(int, stdin.readline().split())
house = []
for _ in range(n):
house.append(int(stdin.readline()))
house.sort()
# 해당 거리를 유지하며 공유기가 몇 개 설치될 수 있는가?
def router_counter(distance):
count = 1
cur_house = house[0] # 시작점
for i in range(1, n): # 모든 집을 돈다
if cur_house + distance <= house[i]: # 이전 집에서 해당거리보다 멀리 떨어진 집이라면
count += 1
cur_house = house[i] # 공유기가 설치된 집 갱신
return count
# start : 첫집, end : 첫집과 끝집의 차이
start, end = 1, house[-1] - house[0]
while start <= end:
mid = (start + end) // 2
if router_counter(mid) >= c:
answer = mid
start = mid + 1
else:
end = mid - 1
print(answer)
-> 쉽게 설명이 되어 있는데 내가 아직 부족해서 그런지 뭔가 100프로 이해가 가지는 않는다. 그래서 책의 풀이를 참고했다.
출처 : https://claude-u.tistory.com/448
- 이코테 책 예시 코드
n, c = list(map(int, input().split()))
array = []
for _ in range(n):
array.append(int(input()))
array.sort()
start = array[1] - array[0] # 집의 좌표 중에 가장 작은 값
end = array[-1] - array[0] # 집의 좌표 중에 가장 큰 값
result = 0
while(start <= end):
mid = (start + end) // 2 # mid는 가장 인접한 두 공유기 사이의 거리(gap)을 의미
value = array[0]
count = 1
# 현재의 mid값을 이용해 공유기를 설치
for i in range(1, n): # 앞에서부터 차근차근 설치
if array[i] >= value + mid:
value = array[i]
count += 1
if count >= c: # c개 이상의 공유기를 설치할 수 있는 경우, 거리를 증가
start = mid + 1
result = mid # 최적의 결과 저장
else: # c개 이상의 공유기를 설치할 수 없는 경우, 거리를 감소
end = mid - 1
print(result)- 비교 분석📖
이 문제는 '가장 인접한 두 공유기 사이의 거리'의 최댓값을 탐색해야 하는 문제로 이해할 수 있다. 이때 각 집의 좌표가 최대 10억이므로 이진 탐색을 이용하면 문제를 해결할 수 있다. 따라서 이진 탐색으로 '가장 인접한 두 공유기 사이의 거리'를 조절해가며, 매 순간 실제로 공유기를 설치하여 c보다 많은 개수로 공유기를 설치할 수 있는지 체크하여 문제를 해결할 수 있다.
다만, '가장 인접한 두 공유기 사이의 거리'의 최댓값을 찾아야 하므로, c보다 많은 개수로 공유기를 설치할 수 있다면 '가장 인접한 두 공유기 사이의 거리'의 값을 증가시켜서, 더 큰 값에 대해서도 성립하는지 체크하기 위해 다시 탐색을 수행한다. 이 문제는 '떡볶이 떡 만들기' 문제와 유사하게 이진 탐색을 이용해 해결할 수 있는 파라메트릭 서치 유형의 문제로 이해할 수 있다.
예를 들어 5개의 집이 있고, 각 좌표를 담은 수열이 {1, 2, 4, 8, 9}와 같다고 해보자. 또한 설치할 공유기의 최소 개수 c = 3이라고 하자. 이때 가장 인접한 두 공유기 사이의 거리(gap)는 1부터 8까지의 수가 될 수 있다.

step1. 범위가 1부터 8까지이므로, gap의 값을 중간에 해당되는 4로 설정한다. 다만, 이 경우, 공유기를 2개밖에 설치할 수 없다. 따라서 c = 3보다 작기 때문에, gap을 좀 더 줄일 필요가 있다. 따라서 범위가 [1, 8]이었으므로, 범위를 [1,3]으로 수정한다. (공유기를 앞에서부터 차례로 설치할 때, 공유기가 설치되는 위치는 하늘색으로 색칠하였다.)

=> gap이 뭔지 잘 모르겠다.. gap이 4인데 왜 1이랑 8에 공유기가 설치되는 거지? gap이 공유기 사이의 거리라고 했는데 그럼 7 아닌가?
step2. 범위가 1부터 3까지이므로, gap의 값을 중간에 해당하는 2로 설정한다. 이 경우, 공유기를 3개 설치하게 된다. 따라서 c = 3 이상의 값이기 때문에, 현재의 gap을 저장한 뒤에 gap의 값을 증가시켜서 gap이 더 커졌을 때도 가능한지 확인할 필요가 있다. 따라서 범위가 [1, 3]인 상태에서 범위를 [3,3]으로 수정한다.

step 3. 범위가 3부터 3까지이므로, gap의 값을 중간에 해당하는 3으로 설정한다. 이 경우, 공유기를 3개 설치하게 된다. 따라서 c = 3 이상의 값이기 대문에, 현재의 gap을 저장한 뒤에 gap의 값을 증가시켜서 gap이 더 커졌을 때도 가능한지 확인할 필요가 있따. 하지만 현재 범위가 [3,3]이므로, 더이상 범위를 변경할 수 없다. 따라서 gap = 3이 최적의 경우이다.

=> 이해해보려고 책 해설의 그림을 ppt로 옮겨봤는데 그래도 여전히 잘 모르겠다.. gap에 대한 이해가 잘 안간다. 나중에 다시 확인해야겠다. 머리가 안굴러가는 느낌..😥 조금만 어려워지면 문제들이 잘 이해가 가지 않는 것 같다.. 좀 더 머리를 굴려봐야겠다.
📝문제2. 프로그래머스 60060번(가사 검색)
- 문제
https://programmers.co.kr/learn/courses/30/lessons/60060
- 나의 코드💻
코드를 입력하세요- 정답 코드💻
from bisect import bisect_left, bisect_right
# 값이 [left_value, right_value]인 데이터의 개수를 반환하는 함수
def count_by_range(a, left_value, right_value):
right_index = bisect_right(a, right_value)
left_index = bisect_left(a, left_value)
return right_index - left_index
# 모든 단어를 길이마다 나누어서 저장하기 위한 리스트
array = [[] for _ in range(10001)]
# 모든 단어를 길이마다 나누어서 뒤집어 저장하기 위한 리스트
reversed_array = [[] for _ in range(10001)]
def solution(words, queries):
answer = []
for word in words: # 모든 단어를 접미사 와일드카드 배열, 접두사 와일드카드 배열에 각각 삽입
array[len(word)].append(word) # 단어를 삽입
reversed_array[len(word)].append(word[::-1]) # 단어를 뒤집어서 삽입
for i in range(10001): # 이진 탐색을 수행하기 위해 각 단어 리스트 정렬 수행
array[i].sort()
reversed_array[i].sort()
for q in queries: # 쿼리를 하나씩 확인하며 처리
if q[0] != '?': #접미사에 와일드카드가 붙은 경우
res = count_by_range(array[len(q)], q.replace('?', 'a'), q.replace('?', 'z'))
else: # 접두사에 와일드카드가 붙은 경우
res = count_by_range(reversed_array[len(q)], q[::-1].replace('?', 'a'), q[::-1].replace('?','z'))
# 검색된 단어의 개수를 저장
answer.append(res)
return answer- 비교 분석📖
먼저 각 단어를 길이에 따라서 나눈다. 이후에 모든 리스트를 정렬한 뒤에, 각 쿼리에 대해서 이진 탐색을 수행하여 문제를 해결할 수 있다. 예를 들어 문제의 예시와 같이 전체 단어가 ["frodo", "front", "frost", "frozen", "frame", "kakao"]로 구성되어 있다고 해보자. 이때 각각의 리스트를 길이에 따라서 나누면 다음과 같다.
- 길이가 5인 단어 리스트 : ["frodo", "front", "frost", "frame", "kakao"]
- 길이가 6인 단어 리스트 : ["frozen"]
이후에 각 리스트를 정렬하면 다음과 같다.
- 길이가 5인 단어 리스트 : ["frame", "frodo", "front", "frost", "kakao"]
- 길이가 6인 단어 리스트 : ["frozen"]
이때 "fro??"라는 쿼리가 들어왔다고 가정하면 "fro??"는 길이가 5이므로 길이가 5인 단어 리스트에서 "fro"로 시작되는 모든 단어를 찾으면 된다. 이때 구체적으로 이진탐색을 이용해서 "fro"로 시작되는 마지막 단어의 위치를 찾고, "fro"로 시작되는 첫 단어의 위치를 찾아서 그 위치의 차이를 계산하면 될 것이다. 이처럼 이진 탐색을 수행하는 경우 특정한 단어가 등장한 횟수를 계산할 수 있다.
혹은 "fro??"라는 쿼리가 들어왔을 때, count_by_range() 함수를 이용하여 "froaa"보다 크거나 같으면서 "frozz"보다 작거나 같은 단어의 개수를 세도록 구현하면 매우 간단하다. 이는 '정렬된 배열에서 특정 수의 개수 구하기' 문제와 유사한 접근 방법이다.
다만, 이 문제에서는 와일드카드 "?"가 접두사에서도 등장할 수 있다고 했다. 만약 "????o"라는 쿼리가 들어왔다고 가정해보자. 이는 기존의 리스트인 ["frame", "frodo", "front", "frost", "kakao"] 를 이용해 처리할 수 없을 것이다. 따라서 접두사에 와일드카드가 등장하는 것을 처리하기 위해 기존 단어를 뒤집은 단어를 담고 있는 리스트 또한 별도로 선언해야 한다. 현재 예시에서는 길이가 5인 뒤집힌 단어 리스트는 ["emarf", "oakak", "odorf", "tnorf", "tsorf"]이다. 결과적으로 접두사에 와일드카드가 등장하는 경우, 뒤집힌 단어 리스트를 대상으로 이진 탐색을 수행하면 된다.
=> 이코테 책의 해설 풀이를 그대로 옮겨적으며 이해했다. 이해는 가는데 이 생각을 어떻게 떠올릴 수 있는지 잘 모르겠다..
*참고 문법
replace : 문자열 변경 함수. 문자열 안에서 특정 문자를 새로운 문자로 변경. '변수. replace(old, new, [count])' 형식으로 사용.
-
old : 현재 문자열에서 변경하고 싶은 문자
-
new: 새로 바꿀 문자
-
count: 변경할 횟수. 횟수는 입력하지 않으면 old의 문자열 전체를 변경한다. 기본값은 전체를 의미하는 count=-1로 지정되어있다.
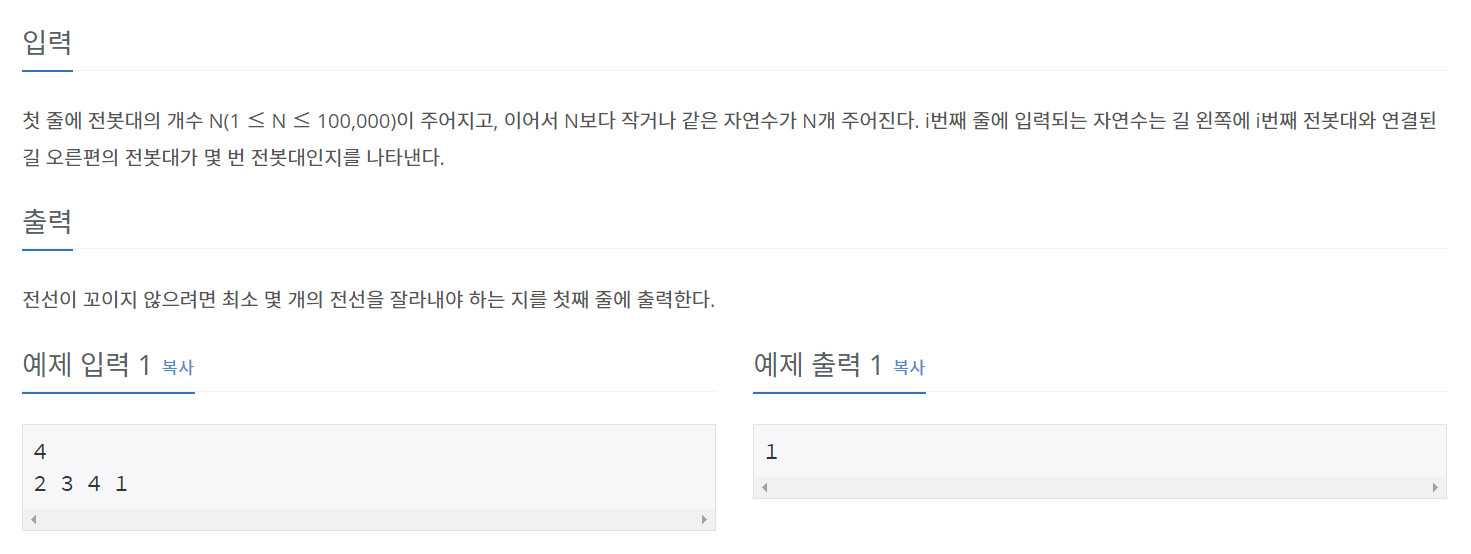
📝문제3. 백준 1365번(꼬인 전깃줄)
- 문제
https://www.acmicpc.net/problem/1365

- 나의 코드💻
코드를 입력하세요- 정답 코드💻
코드를 입력하세요- 비교 분석📖
앞의 문제들에 시간을 너무 많이 할애해서.. 꼭 나중에 다시 풀어야지.. 어제의 반도체 설계 문제와 비슷한 유형이라고 하는 것 같다.
'이것이 코딩 테스트다 with 파이썬(나동빈)' 책을 기반으로 작성한 글입니다.



저도 이번 문제들 너무 어려워서 블로그 참고 많이 했어요..
꾸준히 열심히 하시는 모습이 정말 멋지십니다
고생하셨습니다!!