Index
검색 연산을 최적화하기 위해 데이터베이스상에 로우들의 정보를 <키 값, 주소>로 구성한 데이터 구조이다.
📕 용어 정리
Table (= Relation): 관계형 데이터베이스에서 정보를 저장하여 구분하는 기본 단위
Row (= Tuple, Record): 관계된 데이터의 묶음
Column (= Field, Attribute): 가장 작은 단위의 데이터를 의미
Key: 테이블에서 행의 식별자로 이용되는 식별자
👍 장점
-
테이블 검색 속도와 성능 향상
- 기존에는 특정 조건의 데이터를 찾는 Where문과 Full Table Scan 작업이 필요했는데, 인덱스를 이용해 조건에 맞는 데이터를 빠르게 찾을 수 있다.
-
정렬된 데이터
- ORDER BY문, MIN/MAX를 따로 정렬하지 않아도 된다.
-
시스템의 전반적인 부하 감소
👎 단점
-
인덱스 관리를 위한 추가 작업
- 데이터를 정렬된 상태로 유지하기 위해 INSERT, DELETE, UPDATE 작업이 필요하다.
- 인덱스를 제거하는 것이 아닌 사용하지 않음으로 처리하므로 수정 작업이 많으면 성능이 낮아진다.
-
추가 저장 공간 필요
- 데이터베이스 크기의 약 10% 정도의 저장 공간이 필요하다.
-
검색 성능 저하 가능성
- 전체 데이터의 10~15% 이상의 데이터를 처리하는 경우나 데이터 형식에 따라 성능이 낮아질 수 있다.
인덱스를 사용하기 좋은 경우
-
규모가 큰 테이블
-
데이터 중복이 적은 칼럼
-
INSERT, UPDATE, DELETE 작업이 자주 발생하지 않는 칼럼
-
WHERE, ORDER BY, JOIN 등 정렬 작업이 필요한 컬럼
1️⃣ Primary Index
인덱스가 Primary key를 기반으로 하는 경우 Primary Index라고 한다.
-
키는 각각의 레코드에 대해 고유하고, 레코드와 1:1 관계를 갖는다.
-
정렬된 순서로 데이터를 저장한다.
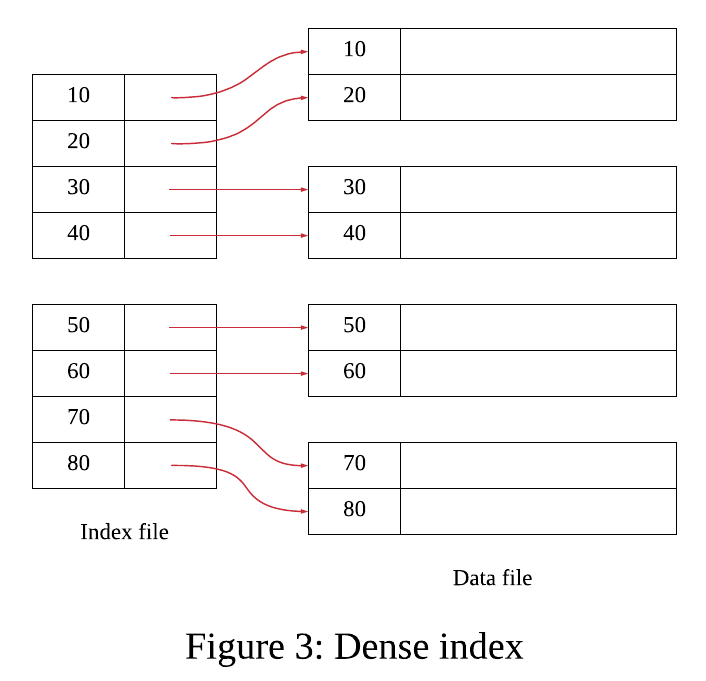
Dense Index
-
데이터의 모든 키가 인덱스에서 표현된다.
-
인덱스가 데이터의 순서와 동일하게 유지되므로 검색 작업이 빠르다.
Sparse Index
-
dence index가 모든 키를 갖고 있어 크다는 단점을 보완하기 위해 설계되었다.
-
데이터 블록마다 하나의 Key-pointer를 보유한다.
-
훨씬 작은 공간을 사용하지만, key를 찾는데는 더 많은 시간이 걸린다.

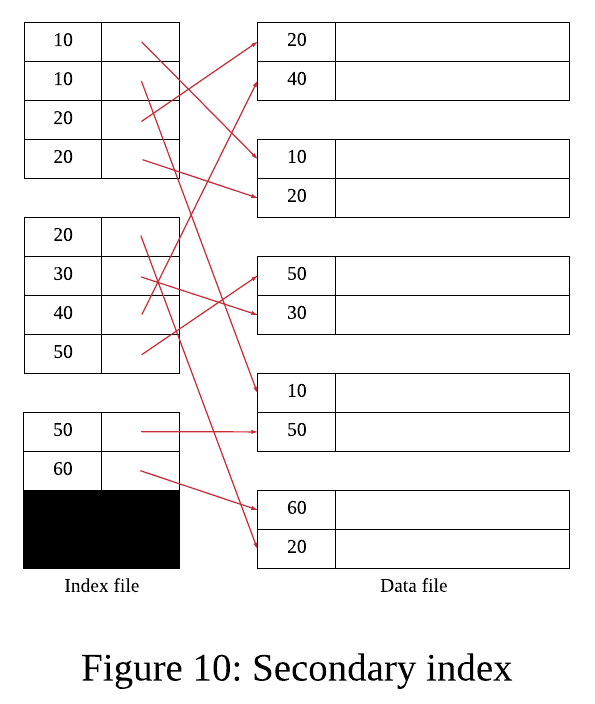
2️⃣ Secondary Index
Secondary Index는 레코드의 위치가 어디인지 알려주는 보조 역할을 하는 인덱스이다.
-
인덱스가 레코드의 위치를 결정짓지 않기 때문에 인덱스에서 명시적으로 언급해야 한다. (dense index 사용)
-
데이터는 정렬되어 있지 않다.
-
중복이 발생할 수 있다.
-
Key-pointer는 search key이며 고유하지 않다.
| Primary Index | Secondary Index | |
|---|---|---|
| 중복 항목 | X | O |
| 데이터 정렬 | O | X |
| 인덱스 수 | 하나 | 여러 개 |
🔢 Composite Index
Composite Index는 인덱스를 생성할 때 두 개 이상의 컬럼을 합쳐서 만드는 인덱스이다.
-
WHERE절에서 AND 조건으로 연결되는 경우 사용한다. (OR 조건은 안됨)
-
인덱스를 생성할 때 순서가 중요하다.
-
빈도수가 적은 인덱스를 첫 번째 조건으로 하면 최대한 많은 데이터를 걸러 검색 효율성을 높일 수 있다.
참고
기본 용어
Index 1
Index 2
Primary Index vs. Secondary Index 1
Primary Index vs. Secondary Index 2
Composite Index
