TCDCN
Tasks-Constrained Deep Convolutional Network
Abstract
Facial Landmark detection은 pose variation과 occlusion 문제가 있어왔다.
하나의 독립적인 task 로 보는 것 대신에 multi task learning으로 발전시킴
특히 facial landmark detection을 다르지만 연관된 task와 함께 최적화시키고자 한다. ( 예를들어 head pose estimation and facial attribute inference )
-> 이것은 중요함, 다른 task들은 다른 학습어려움과 다른 convergence rate 들을 가지기 때문이다.
이 문제를 해결하기 위해서 새로운 task-constrained deep model을 만들었고
(i) task-constrained learning은 현존하는 방식을 능가한다.
(ii) 모델의 complexity를 줄여준다
1 Introduction
Facial landmark detection은 많은 face analysis task중에 기초적인 요소임
이 분야에서 만들어진 발전을 통해서 facial landmark detection은 어마어마한 challenge 를 남겼다.
facial landmark detection은 전통적으로 하나의, 독립적인 문제였음
많은 approach 는 template fitting approach나 regression 기반의 approach임
예를들어 CNN을 사용한 coarse-to-fine regression을 통해 facial landmark detect를 제안 ==> 이 방법이 뛰어난 정확도를 보여주었음
그럼에도 불구하고 이 방법이 복잡하고 다루기어려움
facial landmark detection이 독립적인 문제라고 생각하지는 않음 , 하지만 그것의 평가는 다르거나 약간 관련이 있는 요소에 영향을 받는다. 예를들어 미소짓고 입을 크게 벌릴때.
효과적으로 발견하고 사용하는 것은 mouth corner를 을 더 정확히 detect 하는데 도움을 줄 것이다.
이러한 포즈 정보는 landmark estimation의 solution space를 제한하기위한 추가적인 정보로 이용될수있다.
연구는 관련있는 task ( head pose estimation, gender classification, age estimation, facial expression recognition ...등 ) 를 가지고 facial landmark detection을 optimizing하는 일의 가능성을 목표로 한다.
몇개의 특별한 challenge들이 있다.
-모든 task들이 input으로 얼굴 사진을 공유함에도 불구하고 그들의 ouput space와
decision boundary가 다르다.
- 다른 task는 본질적으로 학습의 어려움이 다르다.
예를 들어 안경을 썼는지에 대해 알아보는것은 미소를 짓고있는가 보다 쉽다.
-게다가 관련있는 일의 positive/negative 의 similar number가 다르다.
확실한 tasks들은 일찍 오버피팅 되기 쉽다. =>전체 모델을 위태롭게 할수있음.
2 Related Work
Facial landmark detection
facial landmark detection 방식은 두가지로 나뉠수있음
1. regression-based method
2. template fitting method
Regression-based method 는 이미지 feature를 이용한 regression를 가지고 landmark location을 정확하게 측정함
예를들어
Template fitting method는 인풋 이미지에 맞게 face template 을 만든다.
Landmark detection by CNN
가장 비슷한 approach는 cascaded CNN
cascaded CNN은 face를 pre-partition했음
우리의 모델은 pre-partition, cascaded layer이 필요하지 않음=> model complexity가 작아지고 더 나은 정확도를 달성
Multi task learning
현존하는 multi task deep model은 이 문제를 해결하기에 적합하지 않다. 왜냐하면 모든 task에 대해 similar learning difficulties 와 convergence rates를 추정하기 때문
모든 task에 대해 반복적인 학습은 early stopping을 제외하고 일어남
vision learning 문제에서 early stopping은 흔함
신경망 방법들도 오버피팅을 방지하기 위해 사용함
3 Tasks-Constrained Facial Landmark Detection
3.1 Problem Formulation
MTL은 관련이 있는 task들을 함께 학습함으로써 generalization performance를 개선하려고 했음
4 Implementation and Experiments
Network Structure
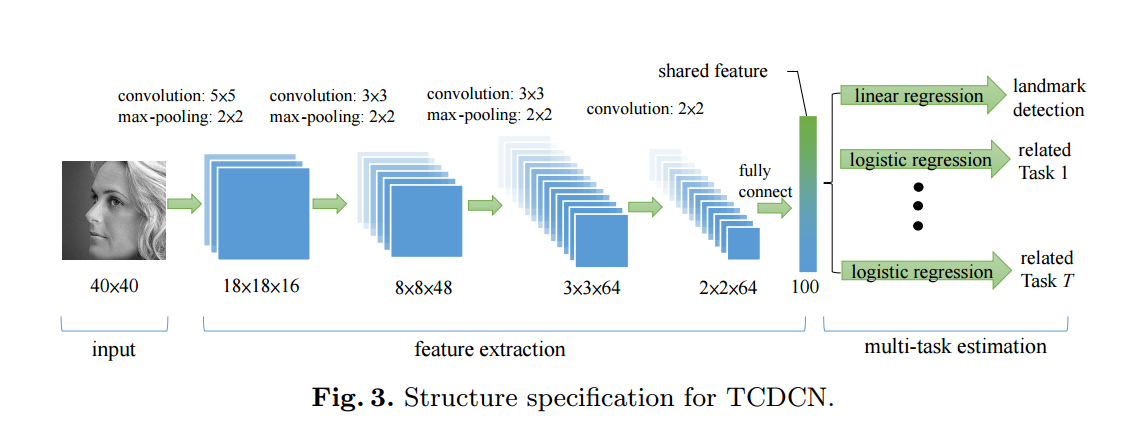
인풋-40x40 그레이스케일
4개의 convolution layer
3개의 pooling layer
fully connected layer
filter의 weight들은 공간적으로 shared되진 않는다 => 다른 filter의 set이 input map의 모든곳에 적용된다
activation function - tangent function
fully connected layer은 feature vector을 생성한다
이 feature vector은 estimation stage에서 여러개 task에 의해 공유된다
Model training
training dataset은 10,000개의 얼굴 이미지로 구성되어있음

각 이미지는 bounding box와 다섯개의 landmark로 annotated 되어있다.
augmentation을 통해 training sample image를 늘렸음
데이터셋 MTFL
Evaluation metrics

mear error- estimated landmark와 ground truth사이의 error
failure error-
4.1 Evaluating the Effectiveness of Learning with Related Task
related task의 영향을 조사하기 위해 제시된 모델의 다섯개의 변수를 평가해보았다.
특히, 첫번째 변수는 facial landmark detection에만 train이 된다.
나머지 네개의 변수는 auxiliary task를 인지
전체 모델은 네개의 task를 모두 이용하여 train된다
변수에 이름을 붙였음
FLD
FLD+pose ( and the related work)

평가를 위해 AFLW를 이용
=> 이 데이터셋은 다른 데이터셋보다 challenging
왜냐하면 AFLW이 더 큰 pose variation, severe partial occlusion
FLD+all 이 FLD를 능가한다
=> pose variation이 모든 landmark의 위치에 전체적으로 영향을 끼침
smiling이나 wear glasses같은 related task는 적은 영향을 줌
=> 얼굴에서 local 한 정보만을 추출하기 때문
FLD vs FLD+smile

=> smiling이 eye 보다 nose, mouth에 더 형향을 끼쳤다
landmark detection은 smiling attribute inference에서 영향을 받음
=> mainly at the nose and corners of mouth
이 관찰은 직감적임
=> smiling이 얼굴에서 lower part를 drive 하기때문
learning of smile attribute이
FLD vs FLD+pose
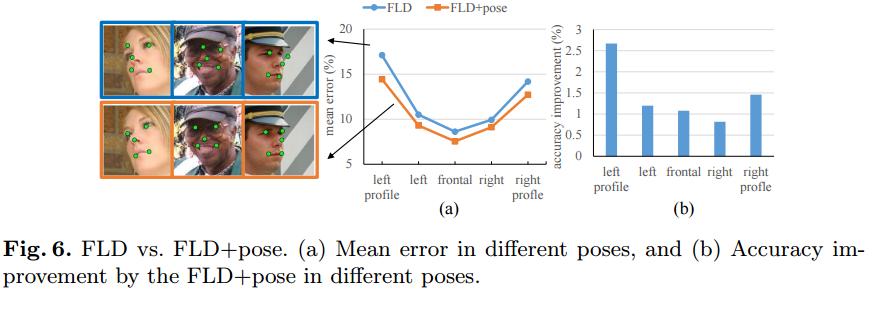
head pose deviation의 정도에 따라 FLD의 detection error가 상승
=> FLD+pose에 의해 회복됨
4.2 The Benefits of Task-wise Early Stopping
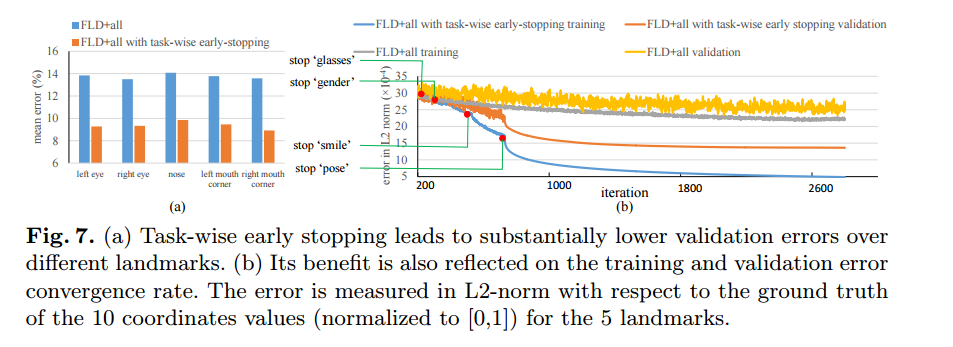
(a) task-wise early stopping이 validation error가 낮음
(b) train, validation error에도 좋아짐
task-wise early stopping이 없으면
=> accuracy가 매우 낮음, training error 가 느리게 수렴, 상당한 진동을 보임 ( 표에서 노란색 / 회색 )
training과 validation 모두 수렴속도가 빨랐고 안정됨
Fig7 에서 언제, 어떤 task가 training 과정에서 멈췄는지?
=> wearing glasses, gender= 250,350 에서 멈춤
pose는 750까지 지속됨 => pose가 다른 task와 비교해서 가장 큰 영향
4.3 Comparison with the Cascaded CNN
TCDCN과 cascaded CNN이 모두 CNN기반이긴 하지만 제시한 모델이
더 낮은 연산비용을 가지고 더 높은 detection accuracy를 달성할 수 있다
FLD+all 과 cascaded CNN을 비교
Landmark localization accuracy
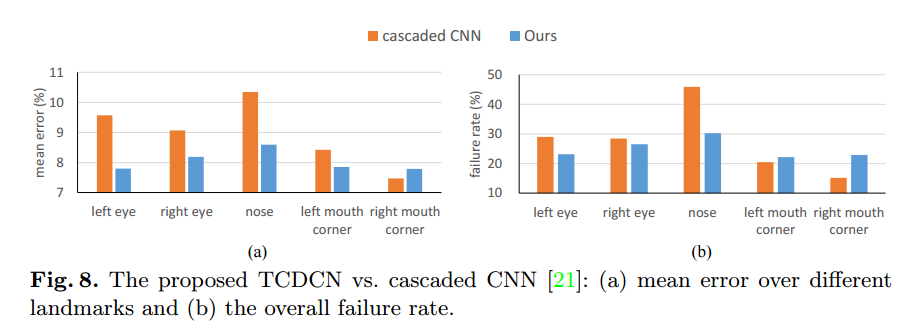
다섯개 중 네개의 landmark에서 더 나은 성능을 보임
전체적으로 정확도가 더 뛰어남
Computational efficiency
4.4 Comparison with other State-of-the-art Methods
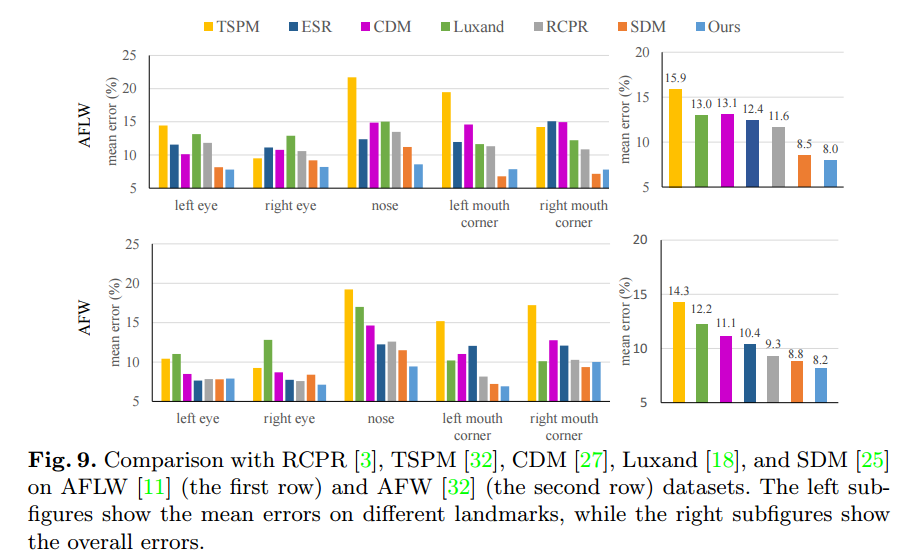
비교
Evaluation on AFLW
TCDCN이 모든 SOTA 를 능가함
제시된 방법이 robust to faces
input 이미지가 40x40 => 모델이 low resolution의 이미지도 다룰수있다는 뜻
Evaluation on AFW
4.5 TCDCN for Robust Initialization
TCDCN이 SOTA를 개선하기 위한 좋은 initialization으로 사용될수 있다 => accuracy, efficiency 때문에
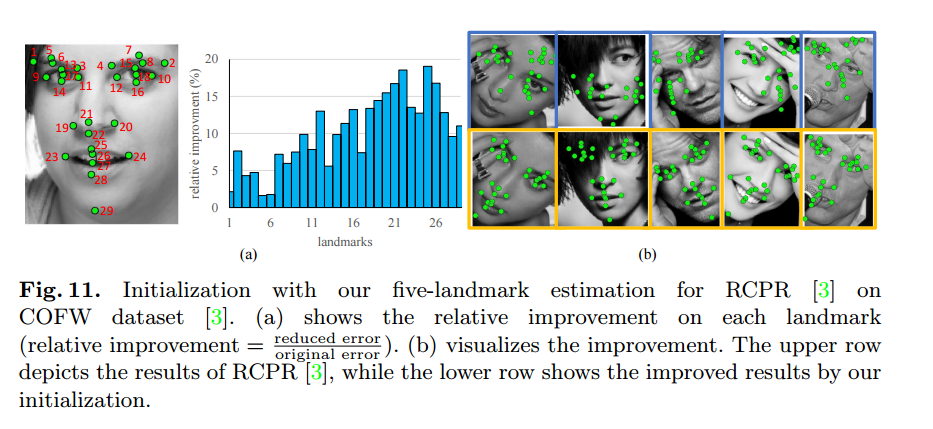
(b) 윗줄- RCPR
아랫줄- 초기화로 인한 향상을 보여줌
예시>
RCPR을 TCDCN을 적용해서 초기화하면 어려운 문제에서 ( rotation, occlusion ) 알고리즘의 향상 가능
5 Conclusion
독립적인 facial landmark detection을 대신하는 강력한 landmark detection
-다르지만 subtly correlated tasks을 통해
task-wise early stopping scheme 은 모델의 convergence를 보장함에 중요
제안된 MTL모델은 존재하던 방식과 비교하여 더욱 강력하다.
-severe occlusion( 폐쇄) 그리고 large pose variation
