참고링크
✅Index란 ?
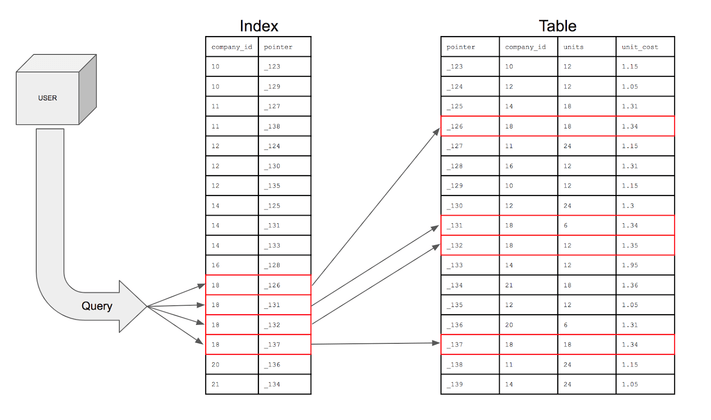
- 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
- 인덱스는 index field와 해당 field 값을 포함하는 모든 disk block을 가리키는 pointer를 저장함
- Primary Index : PK로 정렬
- Clustering Index : key가 아닌 필드로 정렬
- Secondary Index : 정렬이 안된 필드로 index 만들기. 여러개 가능
Primary Index
- PK값에 의해 physical ordering of the file (물리적 정렬)
- PK에 대한 인덱스
- 기본 키를 정의하면 자동으로 생성됨
- 테이블 당 하나만 가질 수 있음
- 특정 레코드를 검색할 때 빠른 속도로 찾을 수 있음
- 데이터 삽입, 갱신, 삭제의 성능이 약간 저하될 수 있음
- 데이터 파일의 구조를 유지하기 위해 인덱스를 갱신해야 하기 때문임
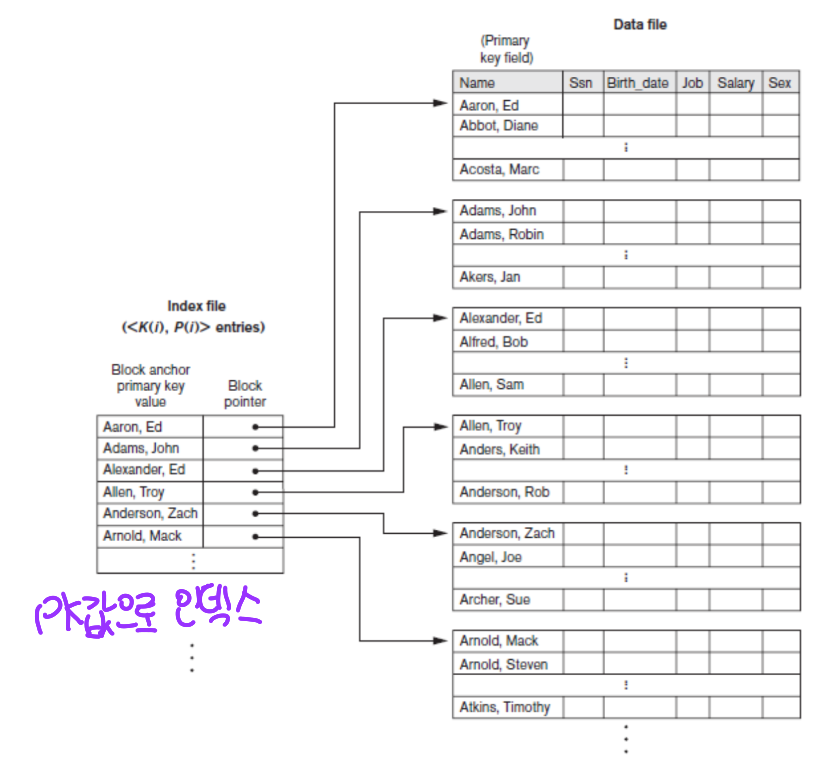
- data file의 block 수만큼 인덱스 값 존재
Clustering Index
- nonkey 값에 의해 physical ordering of the file
- 테이블의 물리적인 순서를 지정하는 인덱스
- 테이블의 레코드를 특정 컬럼들의 값에 따라 정렬하여 저장할 수 있다
- 키가 아닌 값으로 테이블을 물리적으로 정렬할 수 있다
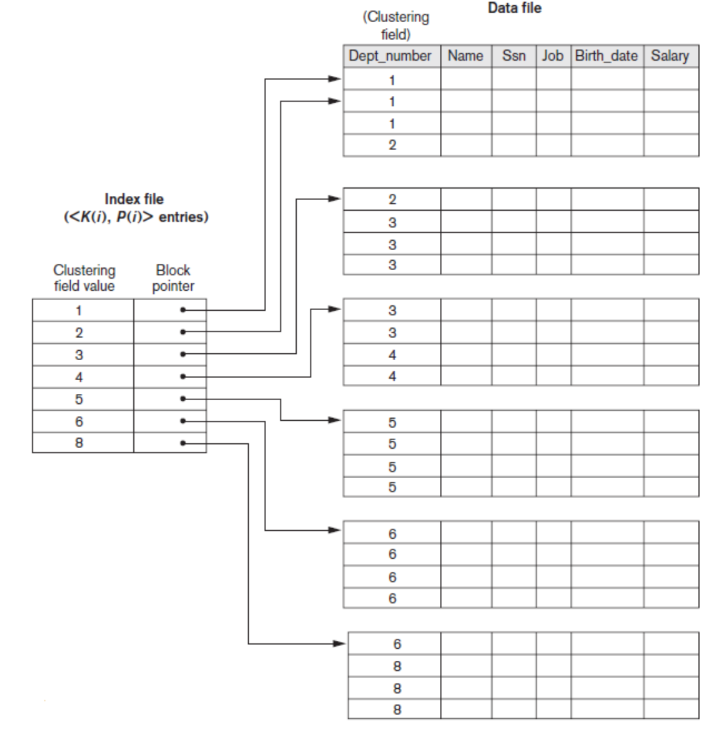
- 서로 댜ㅏ른 index 필드의 값의 수만큼 인덱스 값 존재
Secondary Index
- key나 nonkey값을 활용한 인덱스, 물리적으로 정렬하지 않음
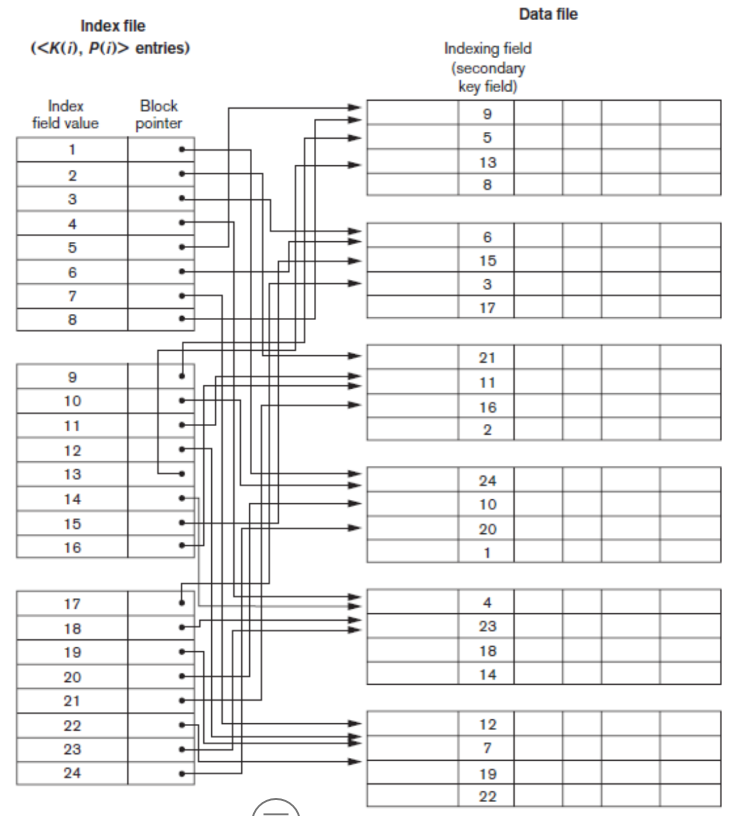
- key를 사용하는 경우 : data file의 레코드 수만큼 인덱스 값 존재
- nonkey를 사용하는 경우 : record의 수나 서로 다른 index field의 값의 개수만큼 인덱스 값 존재
Dense Key
- 인덱스나 키의 값이 연속적으로 분포되어 있는 경우를 의미함
- 날짜, 일련 번호 등
Nondense Key (Sparse)
- 연속적으로 분포되지 않고 빈 공간이 있는 경우를 의미함
- 사용자 ID 등
Second Level Index
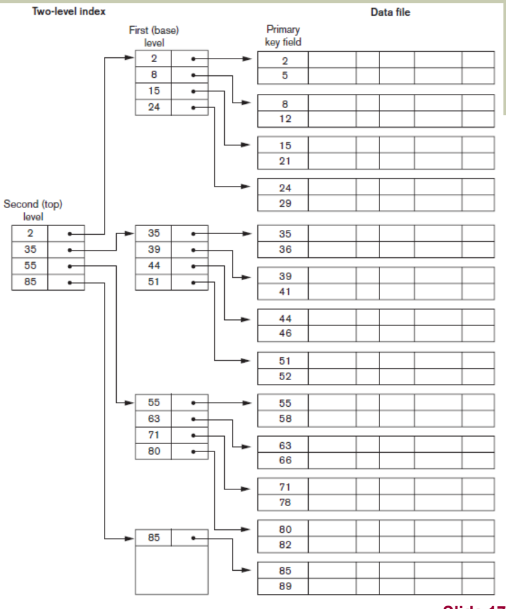
- 인덱스 구조를 계층화해서 더 효율적인 데이터 검색을 지원하기 위함
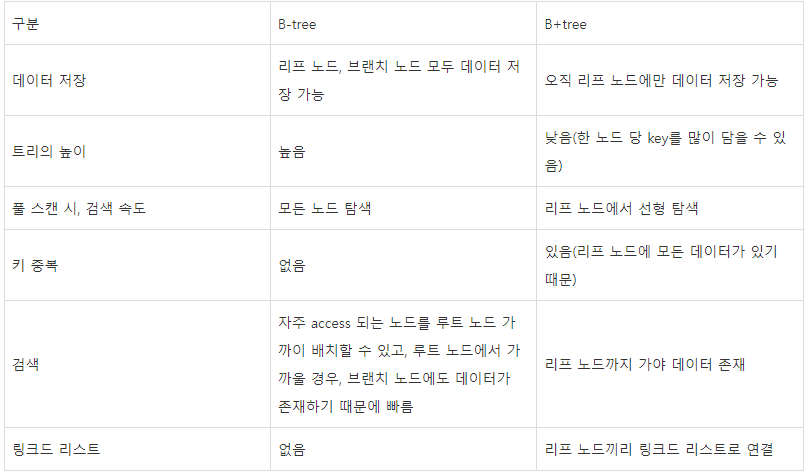
✅ B-Tree
참고1
참고2
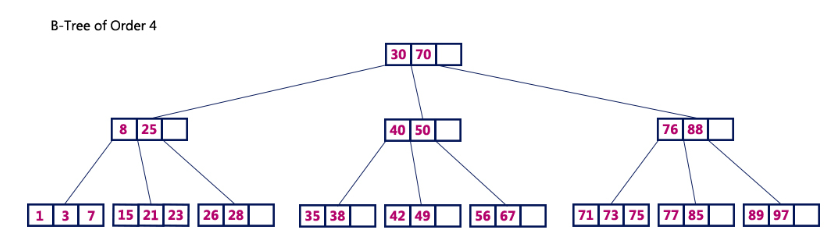
- 이진 탐색 트리와 유사하지만 한 노드당 자식 노드가 3개 이상 가능함
- key 값을 이용해 찾고자 하는 데이터를 트리 구조를 이용해 찾는다
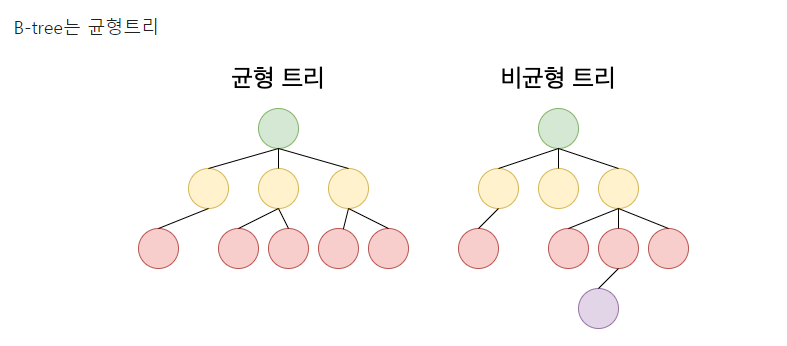
- 균일성 : 어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다 (O(logN))
- always balanced
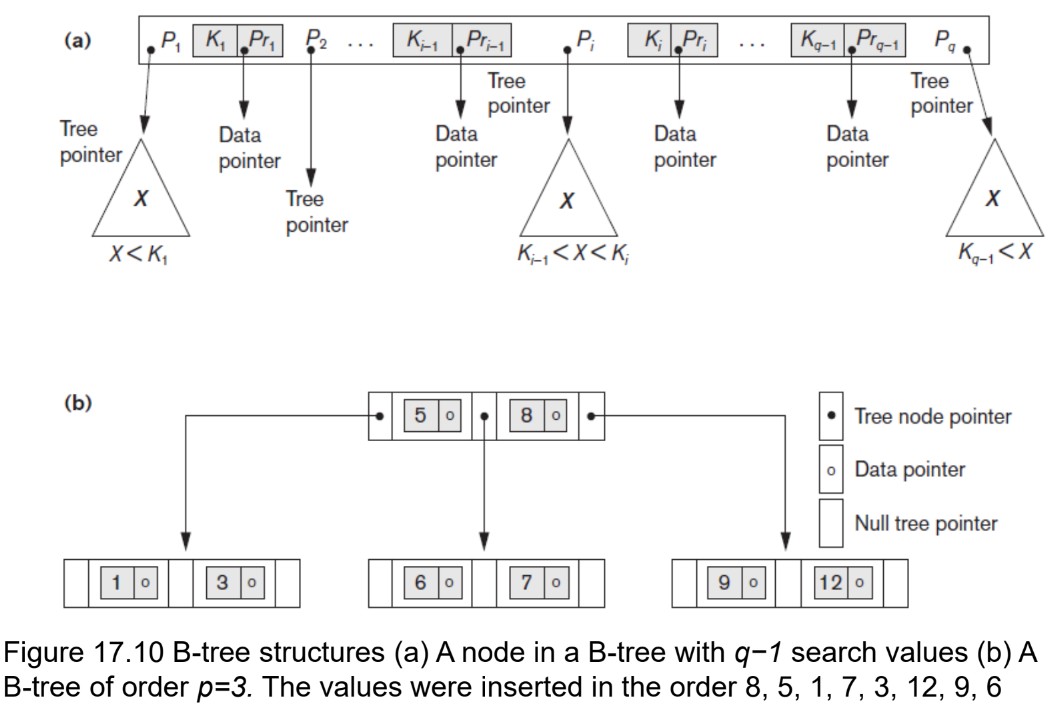
- multileve access structrue
- deletion으로 낭비된 공간은 다시 접근할 수 없게 됨
- B-tree의 p레벨에 있는 노드는 최소 p-1개의 search values를 가질 수 있다
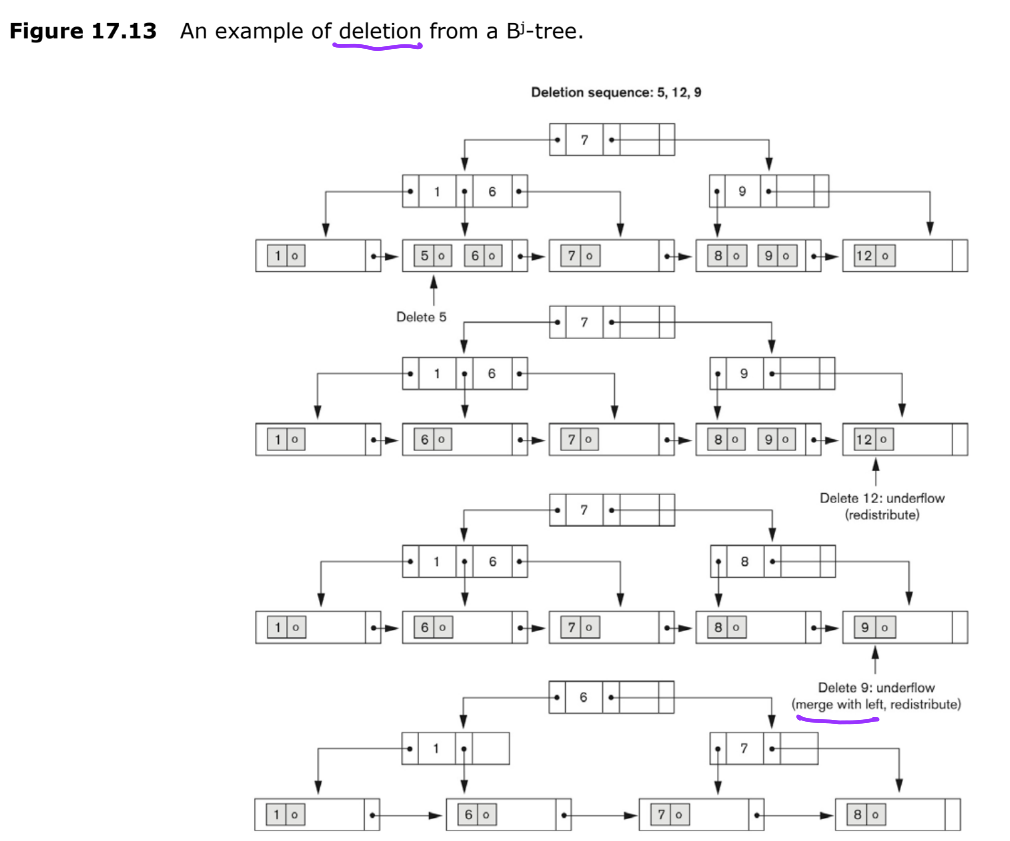
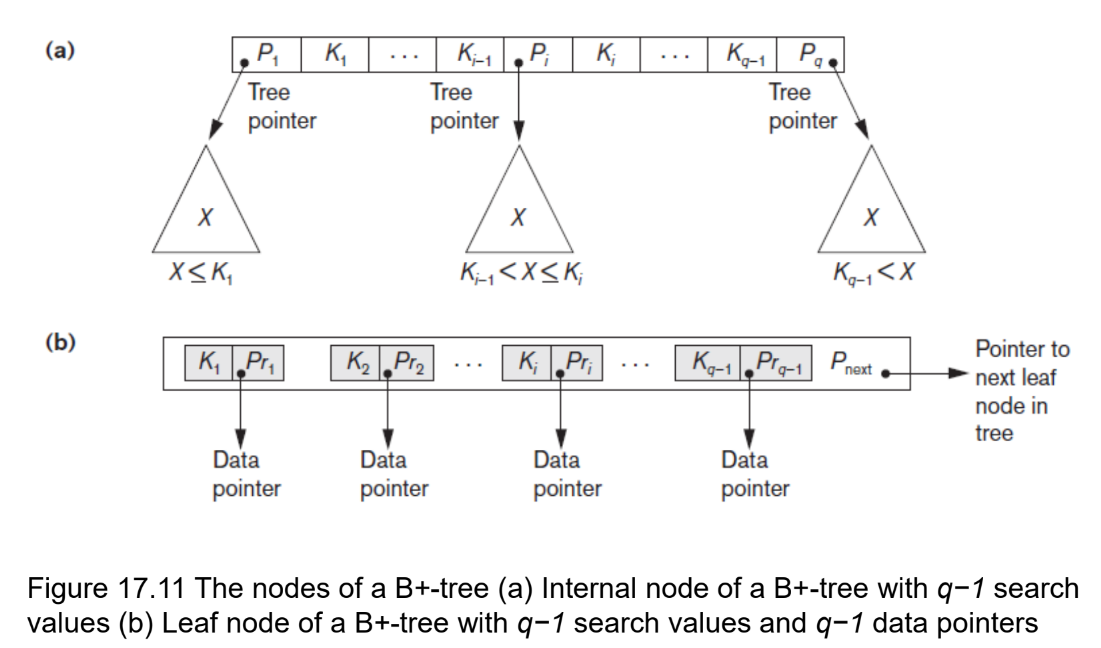
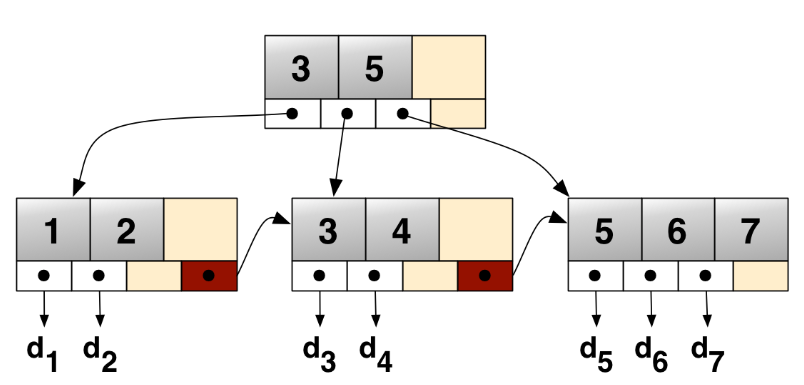
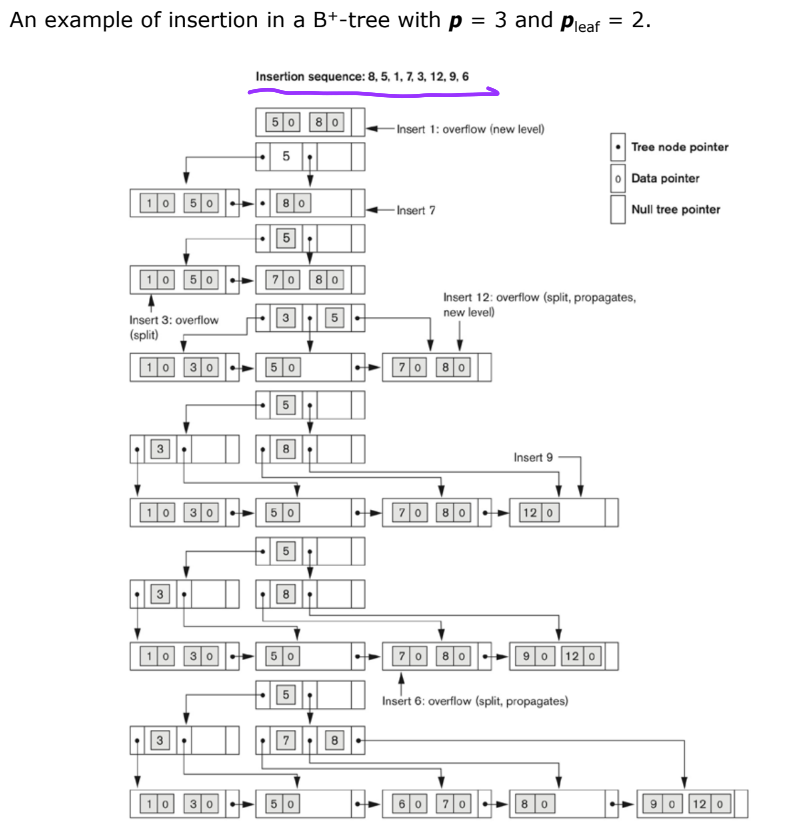
✅ B+Tree
- B-Tree의 확장개념
- B-Tree는 internal 또는 branch 노드에 key와 data를 담음
- B+Tree는 브랜치 노드에 Key만 담아두고 data는 담지 않음
- 오직 Leaf node에만 key와 data를 저장함
- Leaf node끼리 linked list로 연결되어 있음
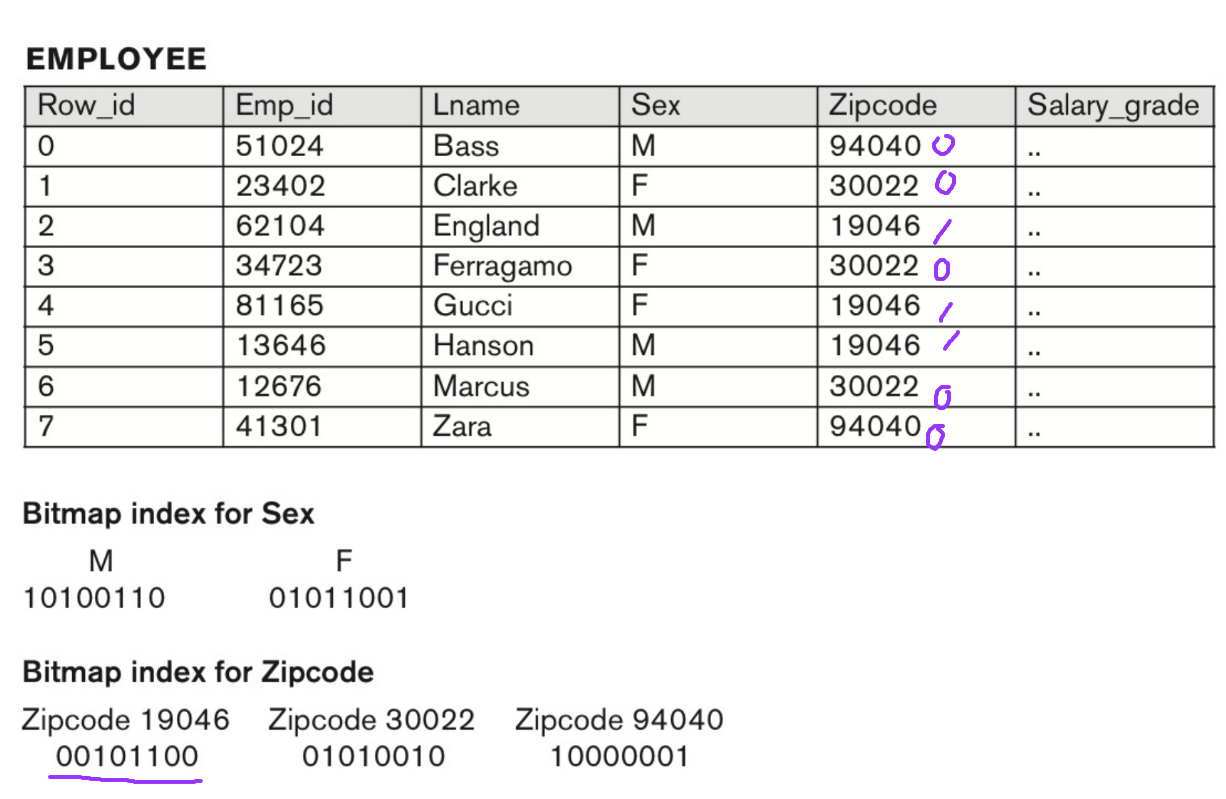
Bitmap Index
참고