DML
DML은 데이터 조작어이다. Data Manipulation Language

SELECT
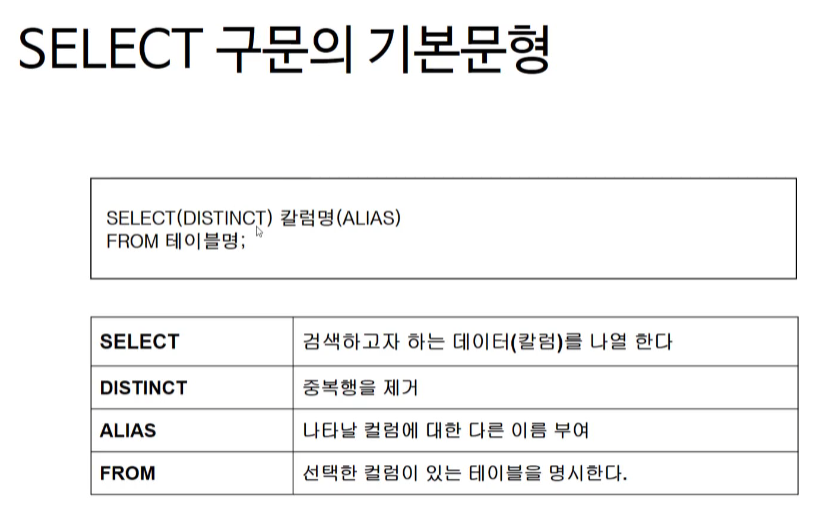
() 안에 있는것은 필수가 아님
칼럼명을 여러개 쓸때는 ,로 구분가능
ALIAS는 결과를 보여줄 때 컬럼명 대신 보여줄 별칭
= 테이블명에서 칼럼명에 대한 내용을 보여달라

별표를 이용해서 모든 컬럼명을 다 보여달라는 의미로 사용 가능하다
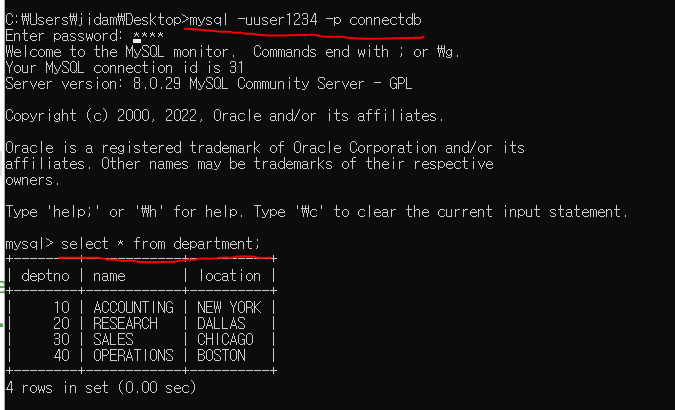
department 테이블의 모든 내용을 보여달라는 뜻
3개의 컬럼(모든 컬럼)의 데이터를 보여줌
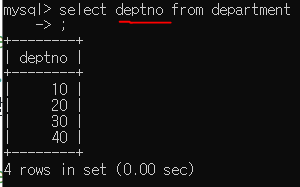
이렇게 내가 원하는 컬럼만 검색해서 볼 수 있다.
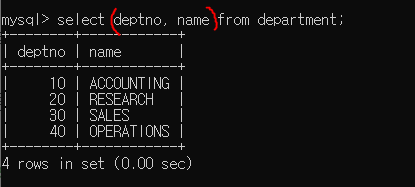
,를 이용해서 2개 이상의 컬럼을 한번에 검색할 수 있다.
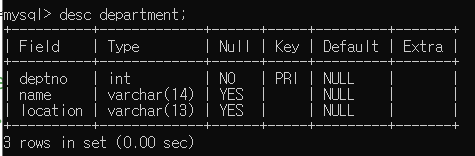
desc 테이블명; 을 통해서 테이블의 컬럼명들을 확인할 수 있다.
이렇게 desc를 이용해서 확인하는 작업은 꼭 해주는게 좋다.
department라는 테이블에 deptno, name, location이란 컬럼이 있는데 그것들을 보여주는 것임
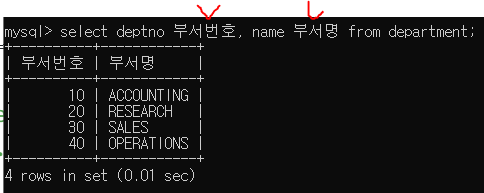
ALIAS를 지정해서 컬럼을 원하는 이름으로 출력할 수 있다.

ALIAS를 지정할 때 as를 사이에 넣을 수도 있다. 그런데 굳이 쓰지 않아도 공백 하나 주고 써도 인식한다.
그리고 ALIAS를 ' ' 로 감싸도 되고 안 감싸도 된다
단! ALIAS에 공백이 있으면 반드시 ' '로 감싸줘야 한다.

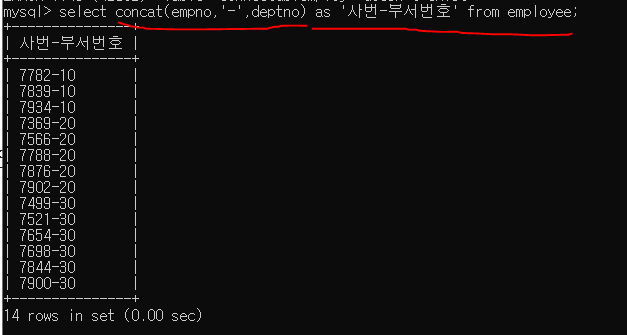
concat은 위 예제를 보면 이해가 된다
컬럼 두개를 -로 연결해서 출력한다
ALIAS가지 사용해서 사번-부서번호 라는 이름으로 출력해준다
employee 테이블에서.

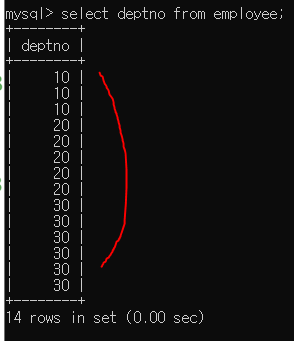
employee 테이블의 deptno 컬럼에 중복되는 값이 있다.
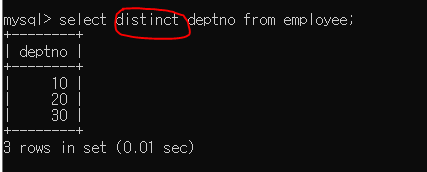
distinct를 사용하면 중복된 값에 대해서는 표시하지 않는다.

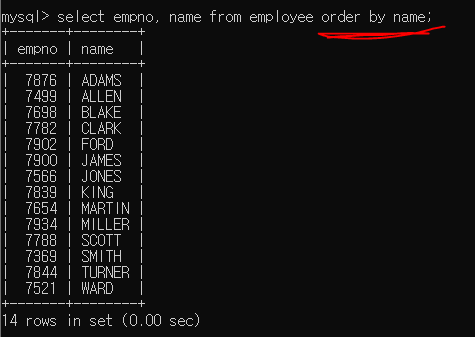
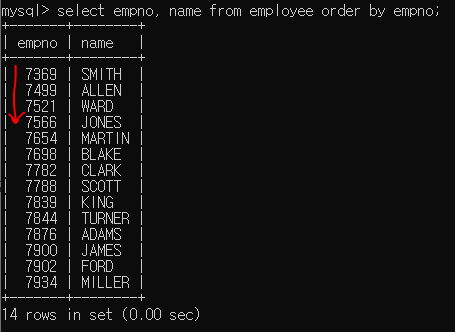
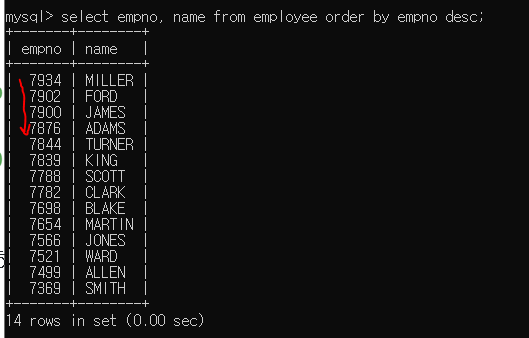
뒤에 order by 컬럼명;을 붙여주면 해당 컬럼의 값을 기준으로 정렬해서 표시해준다.
기본적으로는 오름차순으로 정렬된다
내림차순으로 하고 싶으면 desc를 뒤에 붙여주면 된다.
WHERE

WHERE 를 이용하면 컬럼 검색할 때 조건을 부여할 수 있다.

employee 테이블에서 deptno 컬럼의 값이 10인 데이터들을 보여준다.

where 절에서는 논리연산자 사용 가능하다.

employee 테이블에서 deptno가 10또는 30인 데이터의 name과 deptno를 표시해달라


in 키워드를 쓰지 않고 or를 이용해서도 작성 가능하다.

이런식으로 and, or 같은 논리연산자 사용 가능

like 키워드도 사용할 수 있다.
% 와 _ 두개의 와일드카드를 사용할 수 있다. 예시를 통해 이해하자.
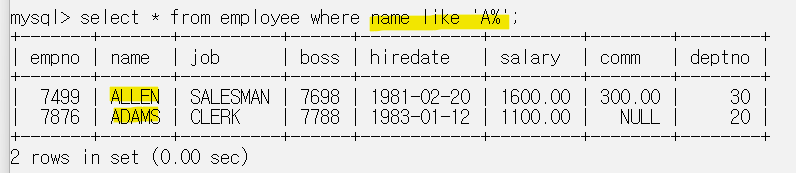
이름이 A로 시작하는 사원들을 찾고 싶을때 where name like 'A%';
로 입력하면 맨 앞 A만 일치하면 나머지는 상관없다는 뜻이다.
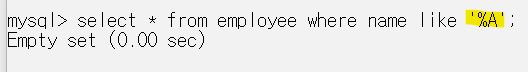
반대로 이렇게 작성하면 이름이 'A'로 끝나는 사람을 찾을 수 있다.
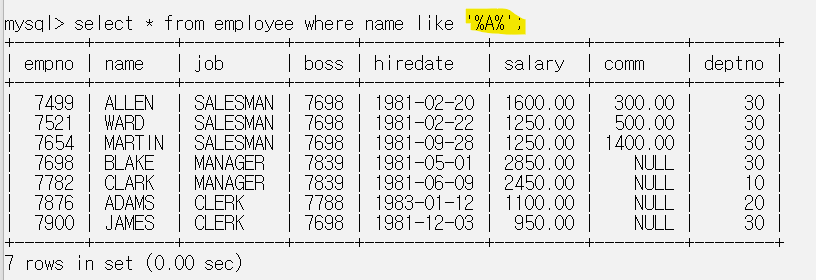
이렇게 입력하면 이름 안에 A가 들어가는 사람은 다 표시해준다.
즉 % 와일드카드는 아무것도 없는것부터 무언가 있는것까지 표현 가능하다.
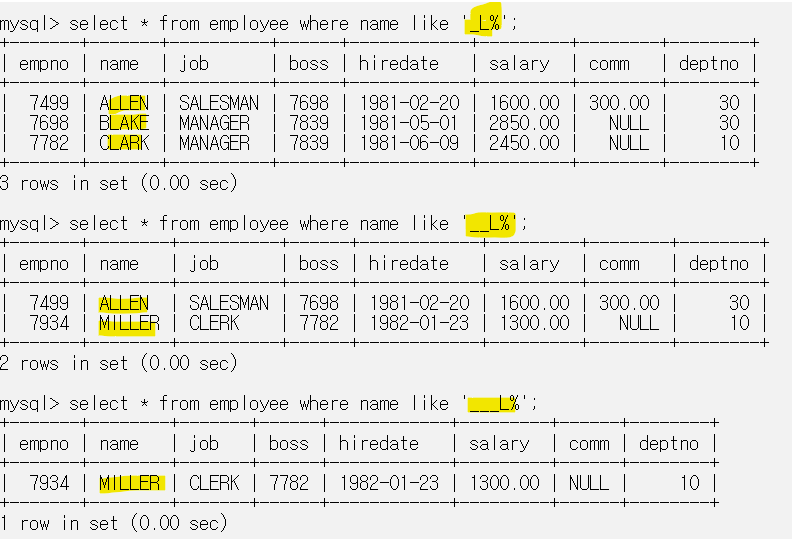
_ 와일드카드는 위처럼 그냥 한 자리 무언가를 표현한다. 아무것도 없는것은 안된다. 즉 두번째로 검색한 것은 L 앞에 무언가 숫자 2개가 있고 그 뒤에는 상관없다는 뜻이다.
이런 식으로 값을 검색할 일이 많으니 꼭 기억하자
함수
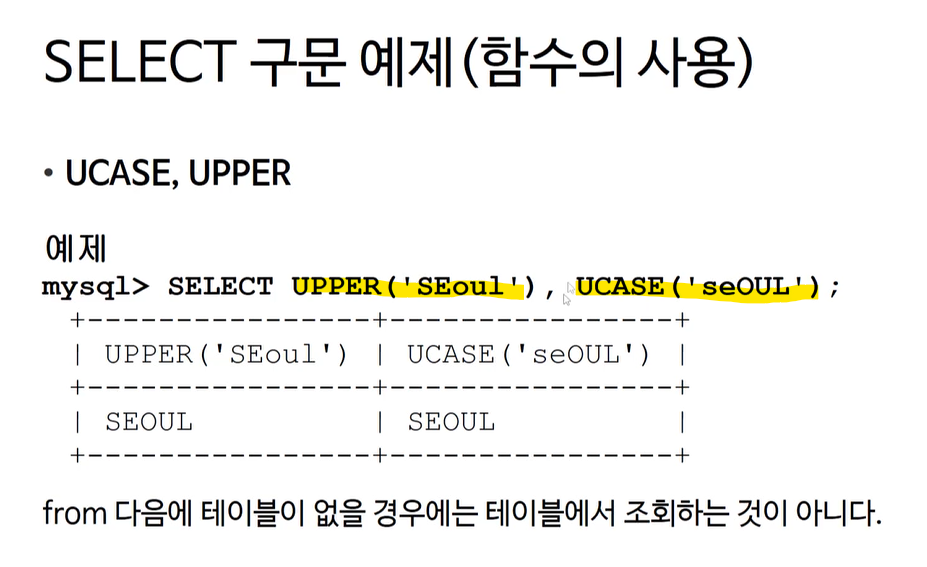
함수에 값을 넣어서 출력할 수도 있다.
UPPER, UCASE는 인자를 대문자로 바꿔서 표시한다
그리고 뒤에 from ~~ 가 없기 때문에 테이블에서 조회하는 것이 아니다.

LCASE, LOWER는 인자를 소문자로 바꿔서 출력한다.
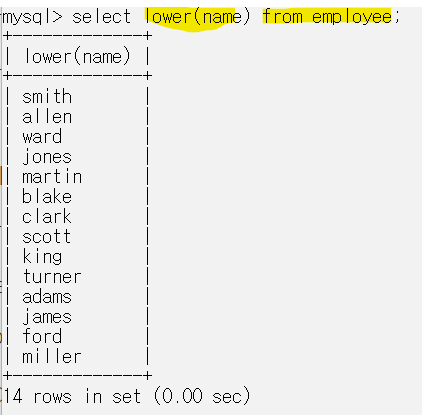
이런 식으로 함수(컬럼) from 테이블 의 형태로 사용할 수도 있다.

SUBSTRING은 문자열에서 시작인덱스와 길이를 받아 시작인덱스로부터 길이만큼 끊어서 표시해준다.
데이터베이스는 인덱스 시작이 1부터 하는 경우가 많다. mysql도 마찬가지로 1부터 시작한다.

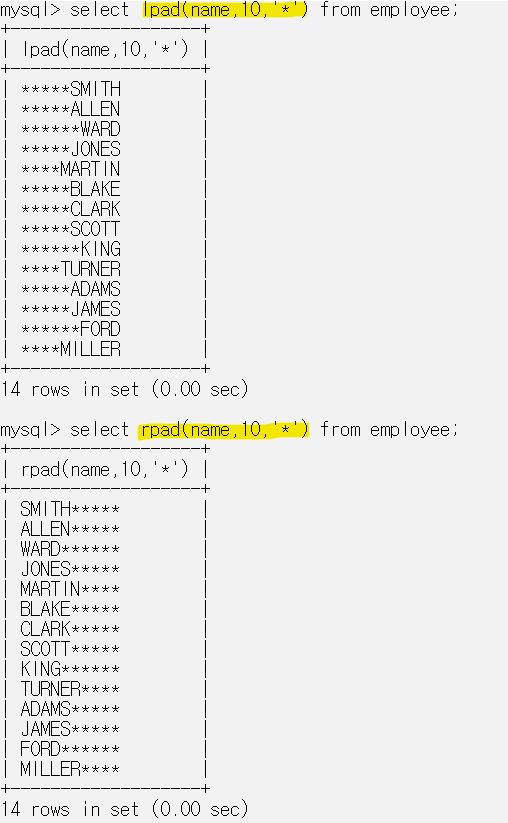
LPAD, RPAD는 문자열을 출력할 때 사용한다.
LAPD('HI',5,'?')는 HI를 출력할 때 5칸을 확보하는데 5칸 확보했을때 빈칸이 남으면 공간을 왼쪽에 ?로 채우는 것이다.
L, R은 ?를 문자열 기준 어디다 채우는지의 차이다.

TRIM은 공백을 없애주는 함수다.
LTRIM, RTRIM은 왼쪽, 오른쪽의 공백만 없애준다.
클라이언트로부터 데이터를 받아오거나 할 때 클라이언트가 이상하게 공백을 넣어서 데이터를 제공하면 검색이 안되거나 할 수 있다.
TRIM을 적절히 사용하면 이러한 문제를 해결할 수 있다.



위와 같이 다양한 함수들이 있다.
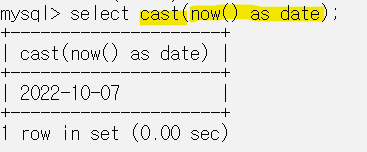
CAST 형변환

형변환을 하기 위해 CAST 또는 CONVERT를 사용할 수 있다.
CAST(expression AS type)
CONVERT(expression,type)
expression 값을 type 형으로 변환한다
CONVERT(expr USING transcoding_name)
charset을 바꿀 수 있다.
형변환 한 결과는 MySQL 타입에 명시되어 있는 type으로만 가능하다.
그룹함수
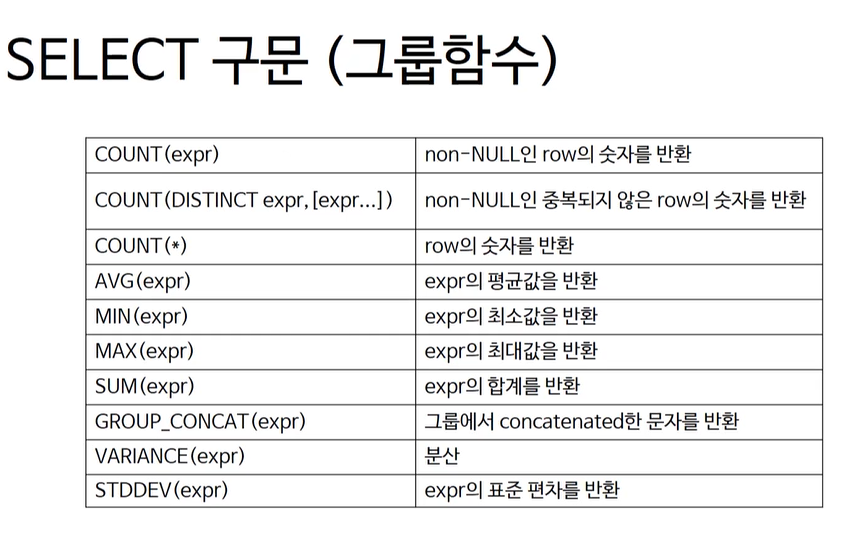
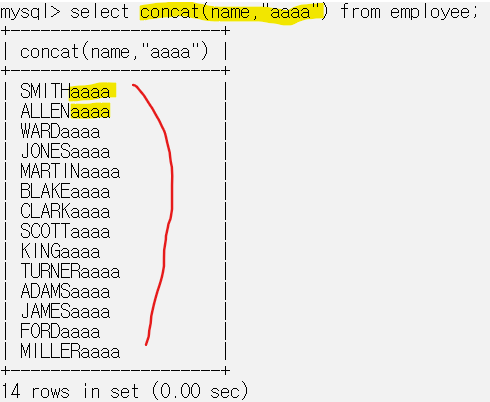
지금까지 다룬 내용들은 단일함수이다.
위와 같이 컬럼의 각 단일 데이터에 대해 모두 함수를 적용하는 것을 단일함수라고 한다.
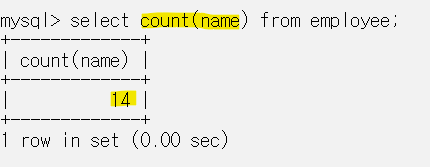
그룹함수는 컬럼 데이터들로 하나의 결과를 얻는 함수다.
count는 employee 테이블의 name 컬럼의 데이터 개수를 세서 14라는 하나의 값을 결과로 얻었다.
count 함수는 null값을 제외하고 개수를 센다.
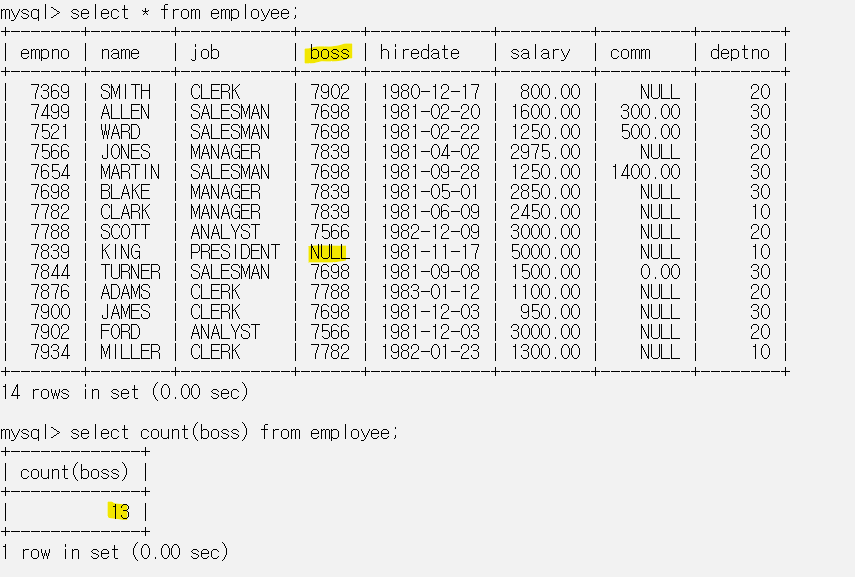
boss 컬럼의 값 하나가 NULL이어서 boss 컬럼으로 count를 하자 결과가 13이 나왔다.
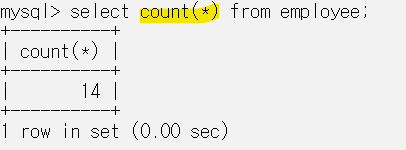
그런데 나는 NULL도 포함해서 전체의 개수를 알고 싶다면 * 를 활용하면 원하는 결과를 얻을 수 있다.
예제
- employee 테이블에서 부서번호가 30인 직원의 급여 평균과 총합계를 출력
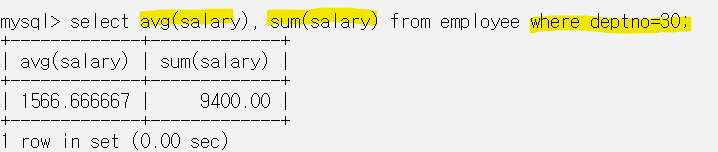
- employee 테이블에서 부서별 직원의 부서번호, 급여 평균과 총합계를 출력

group by 그룹을 나눌 대상
group by를 이용해서 deptno가 10인 그룹, 20인그룹, 30인그룹 마다 각각 급여 평균과 총합계를 출력했다.
INSERT

필드명을 먼저 인자로 전달하고 값들을 하나씩 전달할 수 있다.
이 경우 필드에 디폴트 값이 지정되어 있으면 생략할 경우 디폴트 값으로 설정된다.
필드명을 생략할 경우 첫번째 필드부터 순서대로 값이 전달된다.
필드명을 생략하면 모든 필드 값을 입력해야 한다.

desc 테이블명; 명령어로 테이블의 필드들을 확인했을 때 나오는 필드 순서대로 입력해주면 된다.
그리고 필드와 입력한 데이터 값이 제대로 매핑이 되어야 한다 (데이터 타입 등)
예제
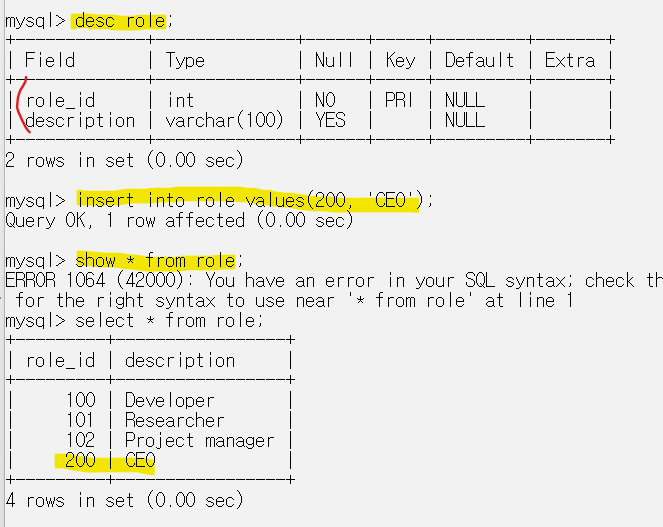
먼저 role 테이블에 desc role;로 필드들을 확인해준다.
그리고 role에 데이터를 넣기 위해 insert into role values(200, 'CEO');로 값을 삽입해줬다.
그리고 나서 select를 이용해 확인해보면 role 테이블에 데이터가 추가된 것을 확인할 수 있다.

description 필드에만 값을 넣고 싶어서 위와 같이 작성하자 오류가 발생했다.
이유는 role_id 필드는 프라이머리 키인데 값을 입력하지 않으면 디폴트로 NULL이 된다. 그런데 프라이머리 키는 NULL을 입력하면 안된다.

반대로 role_id에 110을 넣자 description은 NULL이 가능하기 때문에 자동으로 NULL값이 들어가고 값이 추가된 것을 확인할 수 있다.
UPDATE

WHERE는 생략가능하지만 생략하면 전체 데이터가 바뀐다

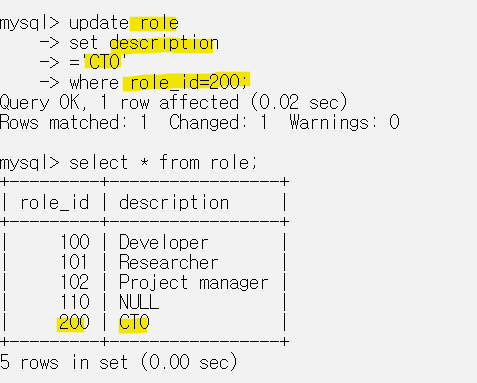
where를 이용해서 role_id가 200인 row에 대하여 업데이트를 적용했다.
DELETE

DELETE 문은 데이터 삭제에 사용한다.
마찬가지로 WHERE로 조건식을 주지 않으면 전체 row가 삭제된다.


다음과 같이 where를 이용해서 role_id=200인 row를 선택해서 삭제했다.
