경로 표현식
점을 찍어 객체 그래프를 탐색하는 것이다.
- 상태 필드 : 단순히 값을 저장하기 위한 필드
- 연관 필드 : 연관관계를 위한 필드
- 단일 값 연관 필드 :
@ManyToOne@OneToOne대상이 엔티티 - 컬렉션 값 연관 필드 :
@OneToMany@ManyToMany대상이 컬렉션
- 단일 값 연관 필드 :
경로 표현식 특징
상태 필드는 경로 표현식의 끝이라 더이상 탐색이 안된다.
em.createQuery("select m.username from Member m");단일 값 연관 경로는 묵시적 내부 조인이 발생하고 더 탐색할 수 있다.
em.createQuery("select m.team.name from Member m");컬렉션 값 연관 경로는 묵시적 내부 조인이 발생하고 더이상 탐색할 수 없다. 컬렉션 자체를 가리키기 때문에 어떤 필드를 가리킬 수 없다.
Collection result = em.createQuery("select t.members from Team t", Collection.class)
.getResultList();묵시적 내부 조인이라는건 객체 입장에서는 그냥 .을 찍어서 가면 되지만 db 입장에서는 join이 발생하는 것을 말한다.
웬만하면 묵시적인 내부 조인이 발생하도록 짜지 않는게 좋다.
from 절에서 명시적 join을 해서 별칭을 얻으면 추가적으로 탐색할 수 있다.
Collection result = em.createQuery("select m.username from Team t join t.members m", Collection.class)
.getResultList();권장하는 방법은 묵시적 조인을 사용하지 않고 명시적 조인을 사용하는 것이다. 그래야 쿼리를 튜닝하기 편하기 때문이다.
묵시적 조인은 inner join만 가능하다.
페치 조인 (중요)
fetch join은 SQL 조인 종류가 아니다.
JPQL에서 성능 최적화를 위해 제공하는 기능이다.
연관된 엔티티나 컬렉션을 SQL 한번에 함께 조회하는 기능이다.
join fetch 문법을 사용한다

List<Member> result = em.createQuery(
"select m from Member m", Member.class
).getResultList();
for (Member member1 : result) {
member1.getTeam().getName();
}지연로딩으로 설정해놓고 member를 먼저 조회하고 member.getTeam().getName()으로 member의 team을 조회하면 지연로딩이 일어나서 조회할 때마다 쿼리를 날리게 된다.
회원 100명을 조회했는데 회원이 전부 다른 팀일 경우 N+1 의 쿼리 발생
1의 결과만큼 (N번) 쿼리가 발생함
이것을 해결하기 위해 fetch join을 사용한다
List<Member> result = em.createQuery(
"select m from Member m join fetch m.team", Member.class
).getResultList();
for (Member member1 : result) {
member1.getTeam().getName();
}이렇게 하면 쿼리 한방에 Member랑 Team의 데이터를 join 해서 다 들고 온다. 프록시가 아닌 진짜 데이터가 채워져 있게 된다.
지연로딩으로 설정을 해도 페치 조인이 우선순위를 갖는다.
컬렉션 페치 조인도 가능하다. 즉 일대다 관계에서 페치 조인하는 것이다.

주의할 점은 DB 입장에서 일대다 조인하면 데이터가 뻥튀기된다.
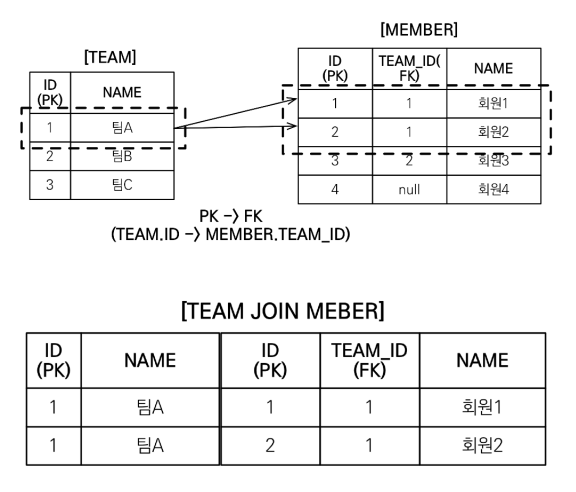
TEAM_ID가 1인 데이터가 Member에 2개 있기 때문에 해당 데이터가 2개로 뻥튀기된다. row가 2개가 되버린다.
팀 A 컬렉션을 가보면 똑같은 회원 1,2가 담겨있다.
이 중복을 제거하기 위해서는 DISTINCT를 사용하면 된다.
em.createQuery(
"select distinct t from Team t join fetch t.members", Team.class
).getResultList();하지만 distinct를 사용해도
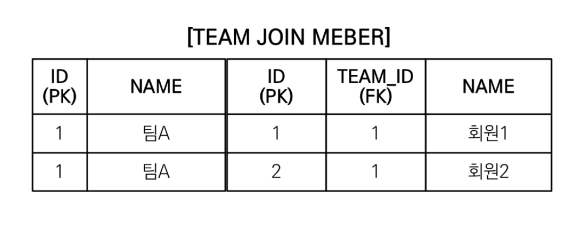
데이터가 완전히 같은게 아니기 때문에 중복 제거가 안된다.
(SQL 쿼리 만으로는 제거가 안됨)
그럼 어떻게 제거되느냐?
추가로 애플리케이션에서 중복 제거를 시도한다.
같은 식별자를 가진 Team 엔티티를 제거한다.
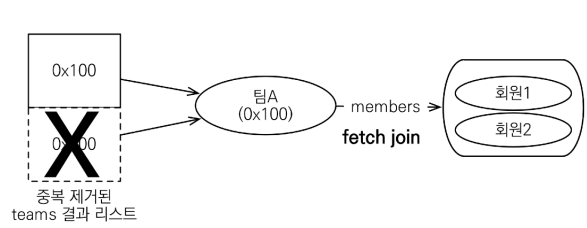
페치 조인과 일반 조인의 차이
일반 조인은 연관된 엔티티를 함께 조회하지 않는다.
데이터가 조회 시점에 로딩이 안되서 루프를 돌리면 쿼리가 또 나간다.
페치 조인은 연관된 엔티티를 같이 로딩한다.
페치 조인의 특징, 한계
페치 조인 대상에는 별칭을 줄 수 없다
select t from Team t join fetch t.members m where m.age>10
과 같이 조인 대상에 별칭을 줄 수 없다
페치 조인은 Team과 연관된 Member를 모두 가져오기 때문에 별칭을 줘서 조작할 경우 이상하게 동작할 수 있다.
위와 같이 조건을 걸어버리면 객체 그래프로 전부 조회할 수 가 없어서 의도한 바와 다르다.
둘 이상의 컬렉션은 페치 조인할 수 없다
일대다에서 데이터 뻥튀기가 되는데 일대다대다이므로 잘못하면 예상하지 못하게 데이터가 막 늘어날 수 있다. 따라서 안 하는게 좋다
컬렉션을 페치 조인하면 페이징 API(setFirstResult, setMaxResult)를 사용할 수 없다.
- 일대일, 다대일같은 단일 값 연관 필드들은 페치 조인해도 페이징이 가능하다
- 일대다 같은 경우 뻥튀기가 되므로 페이징이 안된다.
- 하이버네이트는 경고를 날리고 메모리에서 페이징한다.
- 사용하지 말 것
- 연관된 엔티티들을 SQL 한번으로 조회한다. 성능이 최적화된다.
- 엔티티에 직접 적용하는 글로벌 로딩 전략보다 우선한다.
- 실무에서 글로벌 로딩 전략은 모두 지연 로딩이다.
- 최적화가 필요한 곳에는 페치 조인을 적용한다
- 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 하면 페치 조인 보다는 일반 조인을 사용하고 필요한 데이터들만 DTO로 반환하는 것이 효과적이다.
다형성 쿼리

Item의 자식 Book, Movie라고 할 때 위와 같이 JPQL을 짜면 DTYPE으로 조건을 넣어서 조회한다.
TREAT는 자바의 타입 캐스팅과 유사하다.
부모 타입을 특정 자식 타입으로 다룰 때 사용할 수 있다.

엔티티 직접 사용
JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용한다.
select count(m.id) from Member m : 엔티티의 id를 사용
select count(m) from Member m : 엔티티를 직접 사용
SQL에서는
select count(m.id) as cnt from Member m
두 JPQL에 대해 동일한 SQL으로 번역된다.
엔티티가 db에 넘어가면 db의 PK로 구분하기 때문에 이렇다.
엔티티를 파라미터로 넘길 수도 있다.
외래 키 값인 경우에도 엔티티를 직접 사용할 수 있다.
select m from Member m where m.team = :team
Named 쿼리 애노테이션
@NameQuery 애노테이션을 엔티티에 붙여서 쿼리를 재활용 할 수 있다.
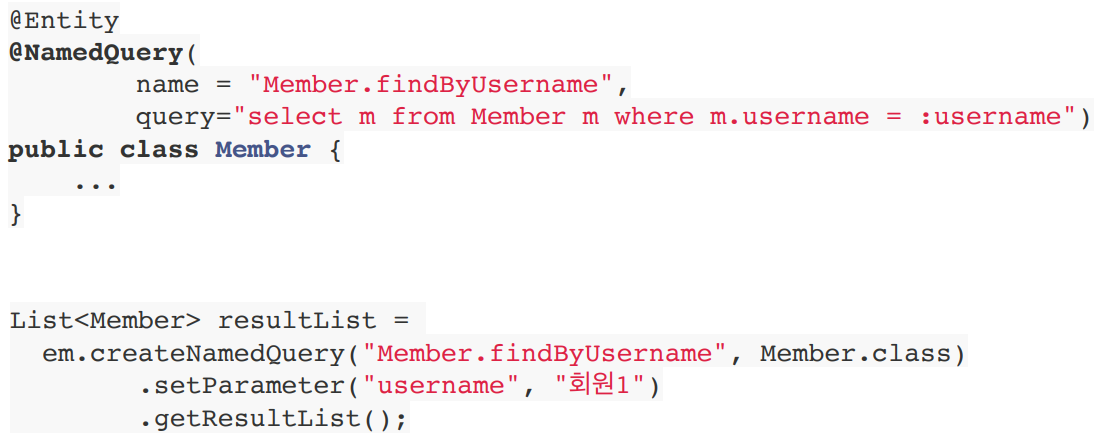
미리 정의해서 이름을 부여해놓고 사용하는 JPQL이다.
정적 쿼리만 가능하다.
애노테이션이나 XML에 정의할 수 있다.
애플리케이션 로딩 시점에 초기화 하고 재사용한다.
- 정적 쿼리라 변하지 않기 때문에 애플리케이션이 파싱해서 SQL로 변환해서 캐시에 들고 있는다
애플리케이션 로딩 시점에 쿼리를 검증할 수 있다.
- 실행하는 시점에 QuerySyntax에러로 확인할 수 있다
- 가장 좋은 컴파일에러로 확인할 수 있다
spring data jpa에서 @Query 애노테이션으로 직접 쿼리를 짜면 NamedQuery로 등록된다.
벌크 연산
SQL의 update랑 delete 문이다.
쿼리 한번으로 여러 테이블의 로우를 변경하는 것이다.
int resultCount = em.createQuery(
"update Member m set m.age=20"
).executeUpdate();모든 멤버의 나이를 20으로 바꾸는 JPQL이다.
executeUpdate()는 영향을 받은 로우의 개수를 반환한다.
하이버네이트는 insert into select도 지원한다.
벌크 연산 주의점
벌크 연산은 영속성 컨텍스트를 무시하고 바로 db에 쿼리한다.
해결하는 방법은 2가지가 있다.
1. 영속성 컨텍스트에 뭘 하기 전에 벌크 연산을 먼저 실행
2. 벌크 연산을 수행 후 영속성 컨텍스트 초기화
- 벌크 연산을 수행하면 flush가 되기 때문
멤버1.persist
멤버2.persist
멤버3.persist
벌크연산(모든 멤버의 나이 20살로)
em.find(멤버1)
멤버1.getAge()이런 식으로 진행을 하면 벌크연산을 하기 전 flush는 자동 호출된다.
그리고 벌크연산을 진행해서 영속성 컨텍스트를 무시하고 db에 바로 쿼리를 날린다.
그리고 나서 멤버1.getAge() 하면 나이가 20살로 나오지 않는다.
이유는 영속성 컨텍스트에 있는 멤버들은 벌크연산의 영향을 받지 않기 때문이다.
멤버1.persist
멤버2.persist
멤버3.persist
벌크연산(모든 멤버의 나이 20살로)
em.clear()
em.find(멤버1) // 영속성 컨텍스트가 초기화되었으므로 db에서 조회함따라서 위와 같이 벌크 연산 수행 후 영속성 컨텍스트를 초기화 해줘야 한다.
