출처 : 열혈 java 프로그래밍
컬렉션 프레임워크란 ?
- 제네릭 기반의 클래스와 메소드로 자료구조와 알고리즘을 구현해놓은 것
List 인터페이스 구현
List<E> 인터페이스를 구현하는 컬렉션 클래스
ArrayList<E>배열 기반LinkedList<E>리스트 기반
List<E> 인터페이스를 구현하는 클래스의 특징
- 인스턴스의 저장 순서 유지
- 동일한 인스턴스의 중복 저장 허용
import java.util.*;
public class Main {
public static void main(String[] args){
//컬렉션 인스턴스 생성
List<String> list = new ArrayList<>();
//저장
list.add("hello");
list.add("bye");
//삭제
list.remove(0);
//참조
String s = list.get(0);
System.out.println(s);
}
}기본적 기능들은 위와 같음
ArrayList는 내부적으로 배열을 생성함. 필요하면 배열의 길이를 스스로 늘림
List<Integer> list2 = new ArrayList<>(10);성능에 신경을 써야 한다면 생성자의 인자로 미리 공간을 확보할 수 있음
LinkedList도 ArrayList와 같은 방법으로 사용한다.
LinkedList는 연결 리스트 자료구조를 사용한다.
따라서 저장 공간을 계속 추가할 수 있어 미리 할당할 필요는 없다.
ArrayList vs LinkedList
ArrayList
장점
- 저장된 인스턴스의 참조가 빠름
단점
- 저장 공간을 늘리는 과정에서 시간이 많이 소요됨
- 인스턴스 삭제 과정에서 연산이 많이 발생할 수 있음
LinkedList
장점
- 저장공간을 늘리는 과정이 간단하다
- 저장된 인스턴스의 삭제 과정이 간단하다
단점
- 참조 과정이 ArrayList에 비해 복잡하다
컬렉션 클래스를 생성할 때 다른 컬렉션 인스턴스를 생성자로 받아서 생성할 수 있다.
= 다른 컬렉션 인스턴스에 저장된 데이터를 복사해서 새로운 컬렉션 인스턴스 생성가능
List<Integer> list = Arrays.asList(1,2,3,4,5);
//다른 컬렉션 인스턴스를 생성자로 받아서 생성
list = new ArrayList<>(list);
list.add(6);
for (Integer i : list){
System.out.println(i);
}위 방식과 같이 ArrayList를 사용하다가 LinkedList가 필요하면 단순히 이렇게 해주면 된다.
list = new LinkedList<>(list);Iterator
Collection이 Iterable를 상속함
제네릭 클래스들은 Collection을 구현함
따라서 Iterator의 추상 메소드들을 구현함
import java.util.*;
public class Main {
public static void main(String[] args){
List<Integer> list = new ArrayList<>();
for (int i=1;i<=3;i++){
list.add(i);
}
//반복자
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()){ //next 메소드로 참조할 값이 있는지 확인
System.out.println(iterator.next()); //다음 인스턴스의 참조값 반환
iterator.remove(); //next 메소드 호출을 통해 반환했던 인스턴스 삭제
}
}
}반복자는 생성과 동시에 첫번째 인스턴스를 가리킴. next가 호출될 때마다 뒤로 이동한다.
반복자를 다시 처음 위치로 되돌릴 수는 없다.
반복자를 다시 얻어야 처음 위치에서 재시작 할 수 있다.
양방향 반복자
연결 리스트만 양방향 반복자인 ListIterator를 사용할 수 있음
Iterator를 상속하는 클래스이고 양쪽 방향으로 이동 가능하다.
previous()
hasPrevious()
add, set 등을 추가로 호출할 수 있다.
- next 후에 add 호출 : 앞서 반환된 인스턴스 뒤에 삽입
- previous 호출 후에 add 호출 : 앞서 반환된 인스턴스 앞에 삽입
Set 인터페이스 구현
Set<E> 인터페이스를 구현하는 제네릭 클래스의 특징
- 저장 순서가 유지되지 않음
- 데이터 중복 저장 불허
= Set (집합) 의 특성과 같음
import java.util.*;
public class Main {
public static void main(String[] args){
Set<String> set = new HashSet<>();
set.add("Toy");
set.add("Joy");
set.add("Enjoy");
set.add("Happy");
set.add("Happy");
Iterator<String> it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}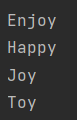
저장순서가 유지되지 않고, 중복저장이 허용되지 않음을 확인할 수 있다.
중복저장이 허용되지 않는다 -> 같은 인스턴스로 판단하는 기준은 ?
Object 클래스에 정의된 두 메소드의 호출 결과를 근거로 판단한다
public boolean equals(Object obj)
public int hashCode()
자세한 내용은 책 568p 참고
먼저 hashCode 메소드의 반환값을 통해 분류된 위치 비교, 분류된 그룹 내에서 equals를 호출해서 동등 비교
hashCode와 equals를 오버라이딩해서 원하는 대로 비교하게 바꿀 수 있다.
특정 인스턴스에 대해 HashMap을 사용할 때마다 hashCode 메소드를 새로 정의하기는 번거롭다.
java.utils.Objects에서 제공하는
pulic static int hash(Object...values)
를 사용하면 쉽게 오버라이딩 할 수 있다.
가변 인자로 선언된 메소드로 메소드 호출 시마다 인자 수를 달리 할 수 있다. 하나 이상의 인자를 조합해 해쉬값을 만들어 반환하기 떄문에 특별한 경우가 아니면 이 메소드를 사용하면 된다.
TreeSet
TreeSet<E>는 트리 자료구조를 기반으로 인스턴스를 저장한다.
트리 자료구조를 활용하기 때문에 정렬된 상태가 유지되면서 인스턴스가 저장된다.
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<>();
set.add(3);
set.add(4);
set.add(2);
set.add(1);
Iterator<Integer> it = set.iterator();
while(it.hasNext()){
System.out.println(it.next()); // 1 2 3 4 오름차순 순서
}
}
}Integer의 경우 오름차순이 기본이지만, 다른 클래스들의 경우 프로그래머가 정해줘야 한다.
public interface Comparable<T> 인터페이스의 추상 메소드
int compareTo(T o) 를 구현해야 한다.
정렬 기준은 Comparable 인터페이스의 compareTo와 같다
TreeSet에서 사용할 객체가 Person 이라면 Comparable<Person>을 구현하도록 하고 compareTo(Person p) 를 구현해주면 된다.
스택 , 큐 , 맵
스택, 큐, 맵은
자바 코테용 함수
여기를 참고하자.
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1);
stack.peek();
stack.pop();
Queue<Integer> queue = new LinkedList<>();
queue.offer(1);
queue.peek();
queue.poll();
HashMap<Integer,Integer> map = new HashMap<>();
map.put(1,1);
map.put(2,2);
map.get(1);
map.values();
map.keySet();
map.entrySet();
}컬렉션 기반 알고리즘
Collections 클래스에는 다양한 알고리즘을 구현한 메소드가 존재한다.
정렬
public static <T extends Comparable<T>> void sort(List<T> list)
List<E>를 구현한 컬렉션 클래스들을 정렬하는 데 사용하는 메소드이다.
- 인자로
List<T>의 인스턴스는 모두 전달 가능 - T는
Comparable<T>인터페이스를 구현한 상태여야 함
다음과 같이 사용한다
Collections.sort(list);
Comparartor 기반 정렬
호출 시 정렬의 기준을 정할 수 있도록 정의된 메소드도 있다.
public static <T> void sort(List<T> list, Comparator<? super T> c)
import java.util.*;
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(Arrays.asList(5,3,4,1,2,6));
Collections.sort(list,(a,b)->b-a);
Iterator<Integer> it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}사용 예시는 위와 같다.
