
US Stock Price Data를 전처리하는 과정을 Pyspark를 이용하여 진행해 보겠습니다.
해당 튜토리얼은 Beginners Guide to PySpark 를 참고하여 진행하였습니다.
Requirements
- PySpark 3.0.1
- pyy4j 0.10.09
1. Creating SparkSession
SparkSession은 Pyspark의 entrypoint로 해당 세션을 통해 Pyspark의 기능을 사용할 수 있습니다.
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark_Tutorial')\
.getOrCreate()builder(): SparkSession Buildermaster(): 클러스터에서 실행중인 경우 마스터 이름을 사용해야 합니다. local mode에서 실행할 경우local[x]형태로 사용합니다. 이때 x 값은 CPU의 코어 수이며, RDD, DataFrame 및 Dataset을 사용시 생성해야 하는 파티션 수 나타내는 0보다 커야 합니다.appName(): 어플리케이션 이름을 지정합니다.getOrCreate(): 현재 존재하는 SparkSession이 있다면 그것을 반환하고 없다면 새로운 SparkSession을 생성합니다.
2. Reading Data
Pyspark의 Read method 이용하여 CSV, JSON 등 다양한 포맷의 데이터들을 읽어들일 수 있습니다.
# Before changing schema
b_data = spark.read.csv(
'data/stocks_price_final.csv',
sep = ',',
header = True,
)
b_data.printSchema()실행 결과

이후 각 컬럼의 데이터 타입을 변경해 줍니다.
from pyspark.sql.types import *
data_schema = [
StructField('_c0', IntegerType(), True),
StructField('symbol', StringType(), True),
StructField('data', DateType(), True),
StructField('open', DoubleType(), True),
StructField('high', DoubleType(), True),
StructField('low', DoubleType(), True),
StructField('close', DoubleType(), True),
StructField('volume', IntegerType(), True),
StructField('adjusted', DoubleType(), True),
StructField('market.cap', StringType(), True),
StructField('sector', StringType(), True),
StructField('industry', StringType(), True),
StructField('exchange', StringType(), True),
]
final_struc = StructType(fields=data_schema)
data = spark.read.csv(
'data/stocks_price_final.csv',
sep = ',',
header = True,
schema = final_struc
)
data.printSchema()spark.read.csv에서 schema를 추가하여 읽어오는 과정에서 데이터를 타입에 맞게 읽어들입니다.
실행 결과

3. Inspect Data
불러온 데이터에 대한 검사를 진행합니다.
1) schema: 데이터의 스키마를 반환합니다.
data.schema2) dtypes: 데이터의 타입을 반환합니다.
data.dtypes
3) head(n): 제일 위에서 부터 n개의 데이터를 반환합니다.
data.head(3)
4) show(n): 제일 위에서 부터 n개의 데이터를 깔끔한 형태로 보여줍니다.
data.show(5)
5) first(): 제일 첫번째 데이터를 반환합니다.
data.first()
6) describe(): 데이터의 행마다 통계를 내서 반환합니다.
data.describe().show()
7) columns: 데이터의 행 이름들을 반환합니다.
data.columns
8) count(), distinct().count(): count는 데이터의 개수, distinct는 유일한 데이터의 개수를 반환합니다.
data.count()
data.distinct().count()
# Result
# 17290344. Columns Manipulation
1) withColumn(): 열 추가
data열과 똑같은 데이터를 가진 date열을 추가합니다.
data = data.withColumn('date', data.data)
data.show(5)
2) withColumnRenamed(): 열 업데이트
열 이름 date를 date_changed로 저장합니다
data = data.withColumnRenamed('date', 'data_changed')
data.show(5)
3) drop(): 열 삭제하기
지정한 열을 버립니다.
data = data.drop('data_changed')
data.show(5)
5. Querying Data
1) Select
선택한 열들에 대한 통계를 출력합니다
data.select(['open', 'high', 'low', 'close', 'volume', 'adjusted']).describe().show()
2) groupBy
sector행의 값 별로 분류해 특정 값이 나온 개수를 구합니다
data.groupBy('sector').count().show()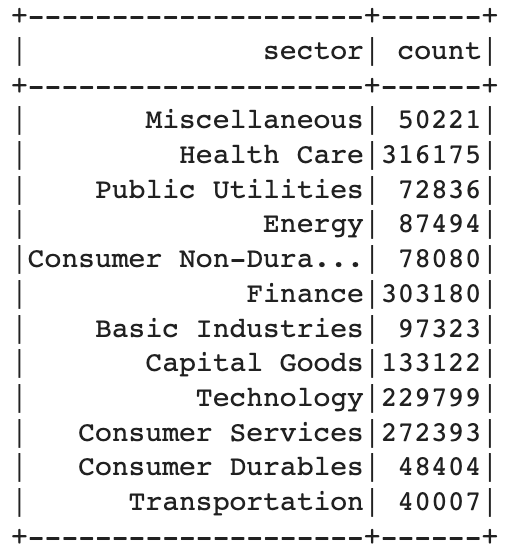
3) filter
data열에서 2020년 1월 1일에서 2020년 1월 31일 사이 값 중 위 5개만 출력합니다.
from pyspark.sql.functions import col, lit
data.filter( (col('data') >= lit('2020-01-01')) & (col('data') <= lit('2020-01-31')) ).show(5)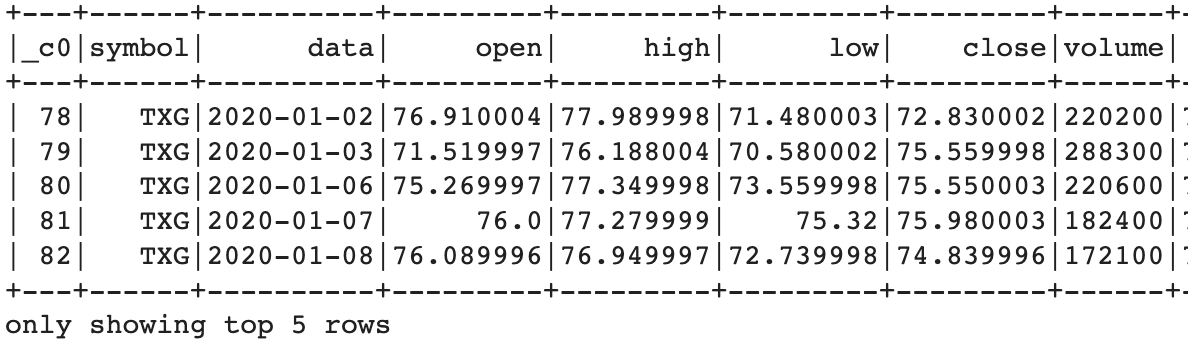
4) between
adjusted 열의 값이 100과 500인 행들 중에서 위에서 5개만 출력합니다.
data.filter(data.adjusted.between(100.0, 500.0)).show(5)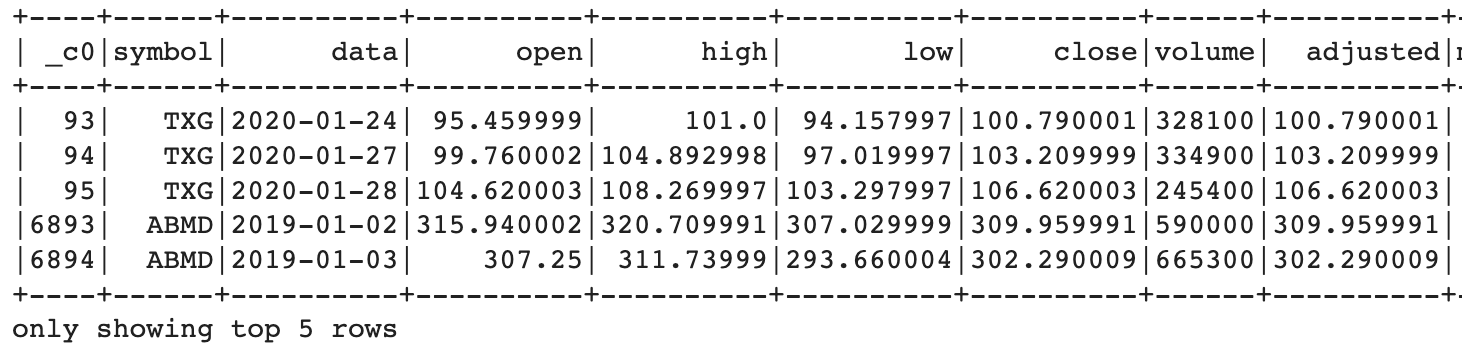
5) when
open, close열과 함께 해당 행의 adjusted 값이 200이 넘는지 확인해 넘는다면 1, 아니면 0을 출력합니다.
data.select('open', 'close', f.when(data.adjusted >= 200.0, 1).otherwise(0)).show(5)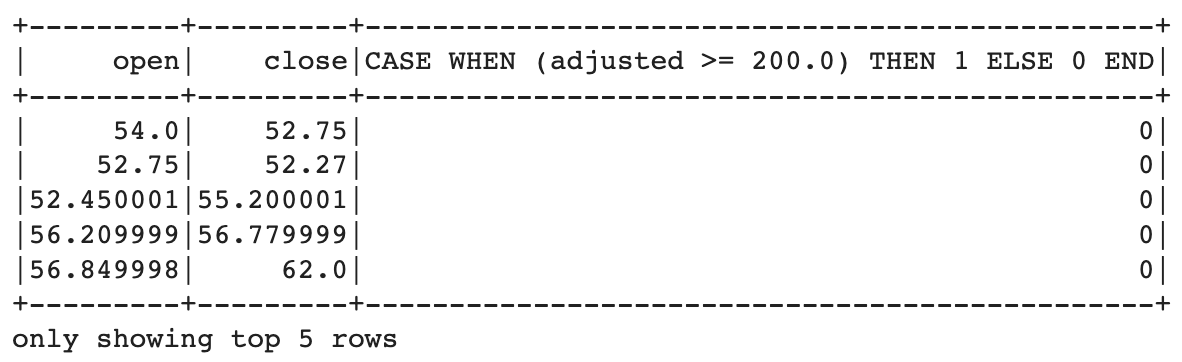
6) aggregation
sector열에서 같은 값을 가진 것들끼리 행을 분류해서 data열에서 처음 시작과, 끝을 찾고, open 열에서 최소, 최대, 평균 시작 값 구하고, close 열에서도 최대, 최소, 평균 끝 값을 구합니다. 또한 adjusted 열에 대해서도 최소, 최대, 평균 값을 집계합니다.
data.filter( (col('data') >= lit('2019-01-02')) & (col('data') <= lit('2020-01-31')) )\
.groupBy("sector") \
.agg(min("data").alias("From"),
max("data").alias("To"),
min("open").alias("Minimum Opening"),
max("open").alias("Maximum Opening"),
avg("open").alias("Average Opening"),
min("close").alias("Minimum Closing"),
max("close").alias("Maximum Closing"),
avg("close").alias("Average Closing"),
min("adjusted").alias("Minimum Adjusted Closing"),
max("adjusted").alias("Maximum Adjusted Closing"),
avg("adjusted").alias("Average Adjusted Closing"),
).show(truncate=False)
6. Visualzation
1) 산업 별로 평균 시가, 평균 종가, 조정 가격 시각화
q = industries_x[(industries_x.industry != 'Major Chemicals') & (industries_x.industry != 'Building Products')] # 두 산업은 값이 너무 커서 다른 산업들의 값을 잘 확인할 수 가 없음
q.plot(kind = 'barh', x='industry', y = q.columns.tolist()[1:], figsize=(10, 50), xlabel='Stock Price', ylabel = 'Industry')
plt.show()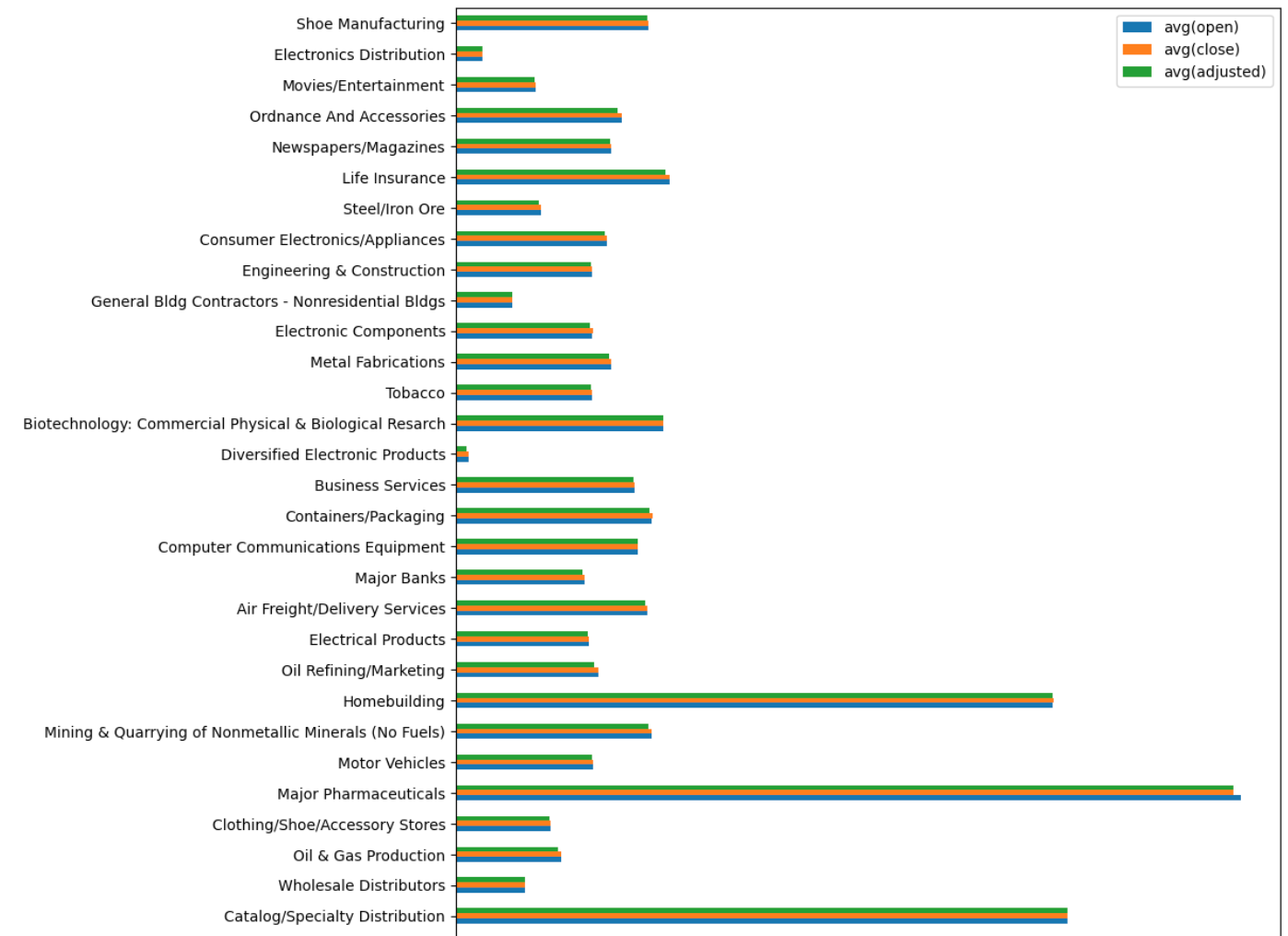
2) Technology 분야의 시가, 종가, 조정가 시간 별로 출력
tech = data.where(col('sector') == 'Technology').select('data', 'open', 'close', 'adjusted')
fig, axes = plt.subplots(nrows=3, ncols=1, figsize =(60, 30))
tech.toPandas().plot(kind = 'line', x = 'data', y='open', xlabel = 'Date Range', ylabel = 'Stock Opening Price', ax = axes[0], color = 'mediumspringgreen')
tech.toPandas().plot(kind = 'line', x = 'data', y='close', xlabel = 'Date Range', ylabel = 'Stock Closing Price', ax = axes[1], color = 'tomato')
tech.toPandas().plot(kind = 'line', x = 'data', y='adjusted', xlabel = 'Date Range', ylabel = 'Stock Adjusted Price', ax = axes[2], color = 'orange')
plt.show()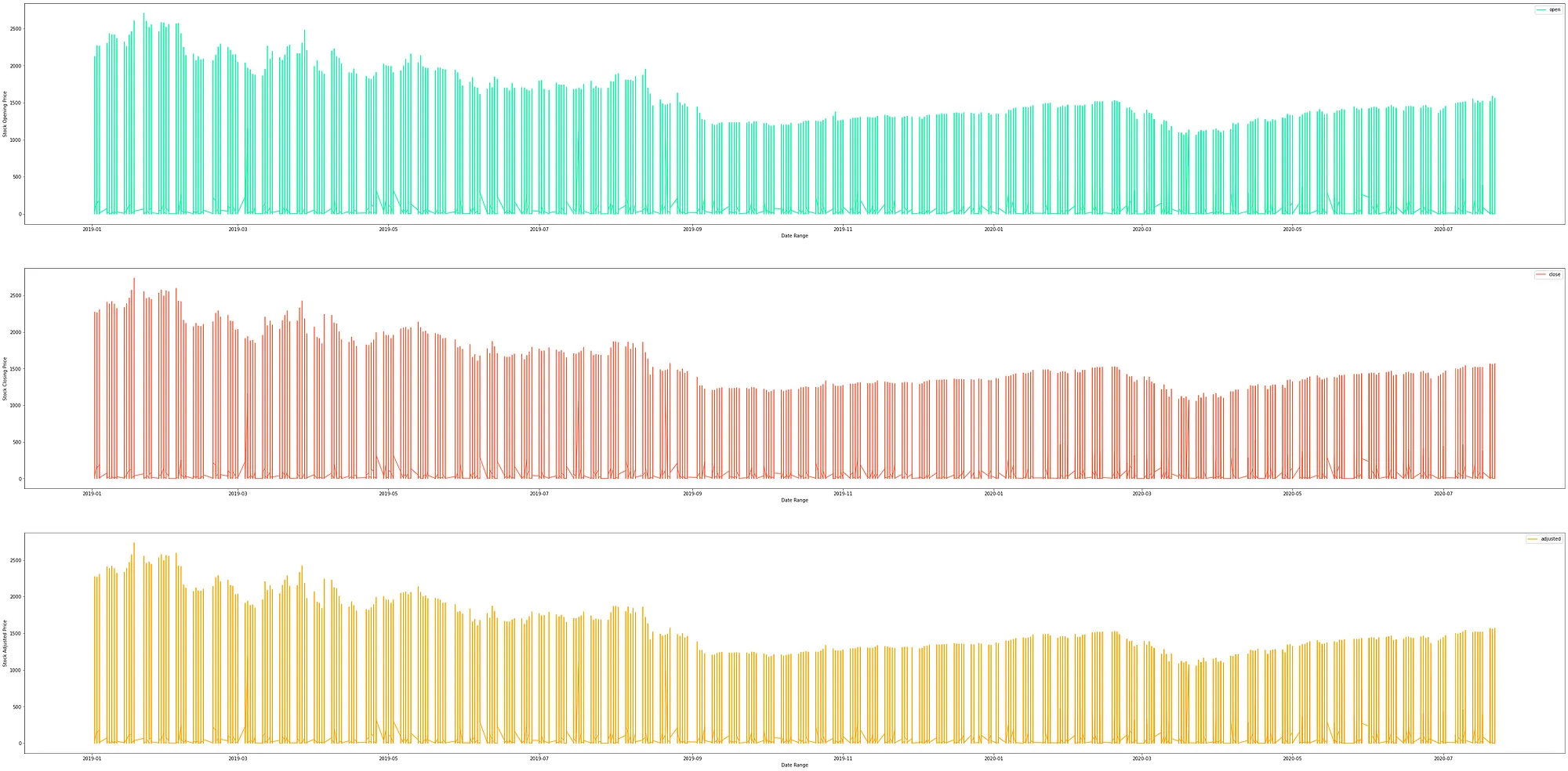
Reference
[1] https://github.com/syamkakarla98/Beginners_Guide_to_PySpark
[2] https://spark.apache.org/docs/3.2.0/api/java/org/apache/spark/sql/SparkSession.Builder.html#master-java.lang.String-
[3] https://towardsdatascience.com/beginners-guide-to-pyspark-bbe3b553b79f
