
여기도 결론부터 말하자면, Spark를 이용해 추출된 데이터 전처리 및 통합을 수행하였다.
이 과정은 Medallion Architecture의 Silver Layer과 Gold Layer 단계의 데이터를 생성하는 과정에 해당한다.
Data Lake에 저장된 json 포맷의 raw 데이터를 전처리하고, 이 데이터와 관련된 외부 데이터를 수집해 최종적으로 모든 데이터들을 합친 테이블을 만드는 과정을 진행한다.
진행과정은 아래와 같다.
-
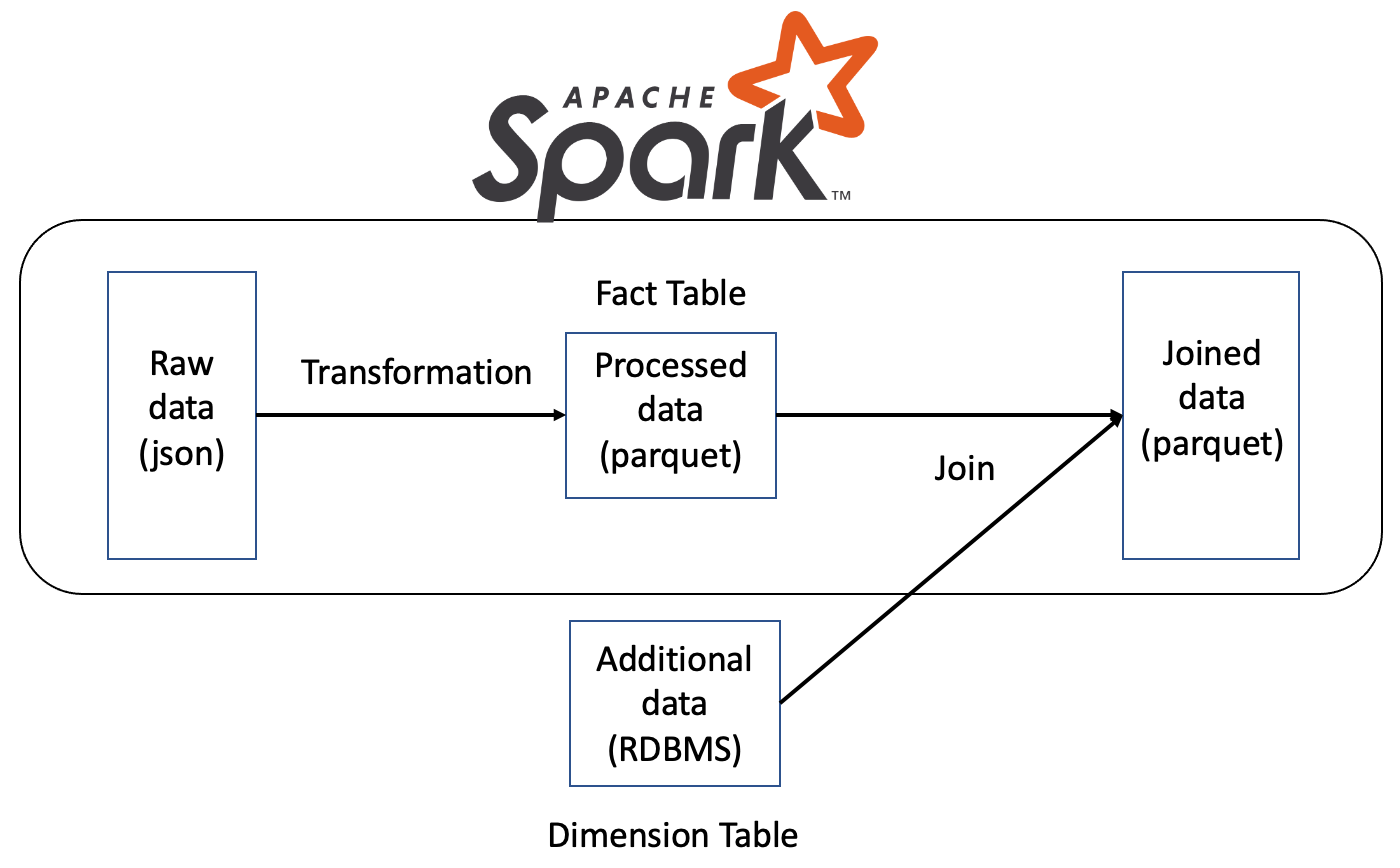
데이터 전처리 (Silver layer)
Spark를 이용하여 대규모 데이터에 대한 전처리를 수행한다. 또한 외부 데이터를 추가적으로 수집한다. 최종적으로 Star Schema 형태의 데이터 구조로 저장하게 된다.
-
데이터 합치기 (Gold layer)
데이터를 분석에 이용하기 위해, Star Schema에서 서로 관련 있는 Fact Table과 Dimension Table에 대한 join을 수행하여 저장한다.
1. 데이터 전처리
프로젝트에서 생성된 데이터들의 관계를 Star schema를 이용해 정의해 보기로 하였다.
Star schema는 이벤트 발생 기록을 담은 Fact table, 이벤트 기록에서는 수집되지 않은 관련 정보가 담긴 Dimension table로 구성된다.
이전 데이터 구성 확인 에서 데이터의 구성 상황에 대해 한번 설명을 했는데, 사실 Event server에서 이미 필요한 대부분 담아 넘겨주고 있다. 오히려 빼야할 정도
그래도 음악과 관련된 추가 정보를 구할 수 있었고, 이를 Dimension table로 구성하여 RDBMS에 저장해 주었다.
그래서 구성한 Star schema는 아래와 같다. 구조 자체는 매우 간단해 보인다.
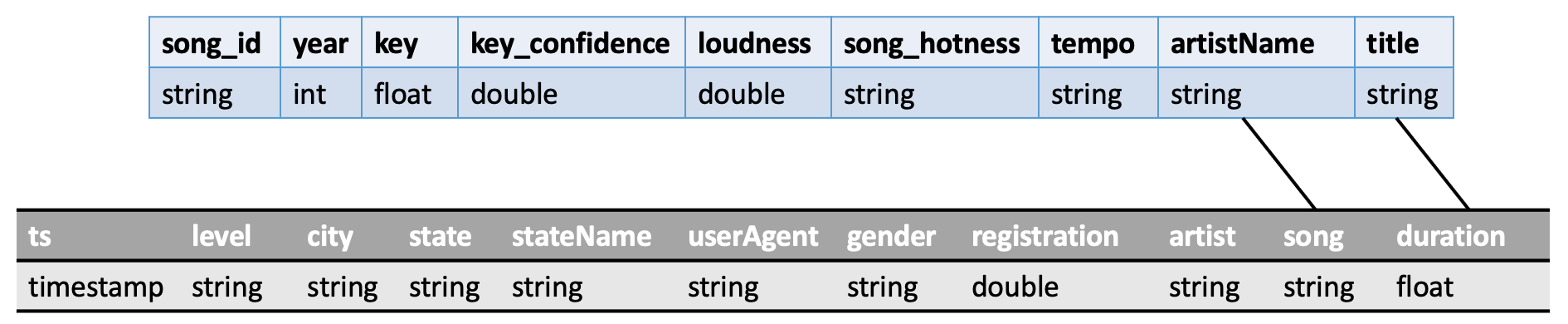
Fact Table
Star schema의 중심에 있는 테이블이다. 이름 그대로 발생한 사실이 기록된 테이블이며, Dimension Table과 관련된 foreign key 혹은 숫자 측정 값 등을 포함한다.
Listen_event 데이터를 예를 들어 어떻게 진행했는지 아래에 설명하였다.
1. Raw data 불러와 파악 하기
| ts | level | city | state | stateCode | userAgent | gender | registration | artist | song | duration |
|---|---|---|---|---|---|---|---|---|---|---|
| timestamp | string | string | string | string | string | string | int | string | string | float |
| lon | lat | itemInSession | zip | lastName | firstName |
|---|---|---|---|---|---|
| float | float | string | int | string | string |
전달되는 데이터를 보면 이미 분석에 필요한 데이터들이 모두 포함되어 전달되는 것을 확인할 수 있었다.
user 정보나 location 정보 등을 dimension table로 구성해 분리할 수도 있겠으나, 결국에는 다시 해당 데이터들을 key 값을 기준으로 join해야 하니 굳이 테이블을 구분하지 않기로 하였다.
2. 데이터 전처리
- 컬럼 삭제: 유저의 상세 위치 정보(lon, lat, zip), 이름 정보(lastName, firstName)와 같은 개인 정보 그리고 itemSession 정보는 분석이 이용하지 않을 예정이기에 삭제해 주었다.
- 추가 정보 포함: state 컬럼의 경우 'CA', 'NY'와 같이 code로 입력되어 있는데, 전체 이름(California, New York)을 담은 컬럼(stateName)을 추가해 주었다.
| ts | level | city | state | stateName | userAgent | gender | registration | artist | song | duration |
|---|---|---|---|---|---|---|---|---|---|---|
| timestamp | string | string | string | string | string | string | double | string | string | float |
3. 데이터 저장
전처리를 마친 데이터는 parquet 포맷으로 저장하였다.
그 외에, Auth, Page view, Status change 도 위 단계를 거쳐 전처리를 진행하였다.
Dimension Table
Dimension Table에는 Event Server에서 수집되지 않는 음악과 관련된 추가적인 데이터(발매 년도, 템포, 시끄러운 정도 등)를 수집하여 RDBMS에 저장하였습니다.
| artist_name | title | key | key_confidence | loudness | song_hotnesss | tempo | song_id | year |
|---|---|---|---|---|---|---|---|---|
| string | string | float | double | double | double | string | string | int |
2. 데이터 합치기
Fact table에 관련된 Dimension table의 데이터를 합해 OLAP Database에 넣기 위한 형태로 만드는 작업이다.
그 외에도 간단한 집계를 수행해 데이터를 압축해 저장할 수 있도록 하였다. 사실 데이터에서 수치와 관련한 metric이 없다 보니 row 수가 많이 줄거라 생각하진 않았다.
Medallion Architecture의 단점 중 하나가 같은 데이터를 3번이나 저장하기 때문에 공간을 많이 차지한다는게 있었는데 이런 부분의 문제를 조금이나마 완화해 줄 것이라 생각하였다.
어쨌든 본 프로젝트에서는 정확한 수치를 파악하기 보다는, 사람들의 이용 경향 등의 트렌드와 관련된 정보들을 빠르게 실시간으로 파악하려는 복적이 크기 때문에 데이터의 크기를 조금이라도 줄이는게 유리하다고 판단하였다.
진행 단계는 아래와 같다.
- 데이터 읽어들이기
Object Stroage에 parquet포맷으로 저장된 Fact Table과 RDBMS에 저장된 Dimension Table을 읽어 들였다. - Data 집계하기
count column을 생성하여, 1분 사이에 같은 이벤트가 발생한 경우에는 해당 항목의 count를 +1을 해주어 하나의 row만 남길 수 있게 하였다. (이부분에 대한 계획은 최근에 추가되어 아직 구현중이다!) - 데이터 Join 하기 (이 부분은 Listen events 데이터에 대해서만 진행)
Listen events와 Dimension Table의 artist 명과 곡 제목 컬럼을 기준으로 Fact Table에 대해 inner join을 수행하였다. - 데이터 저장
최종적으로 결과 데이터를 다시 Object Storage에 Parquet 포맷으로 저장해 주었습니다.
