
프로젝트 개요
가상의 음악 스트리밍 사이트에서 발생하는 이벤트 로그를 안정적으로 수집해 전처리 후 저장하고, 저장한 데이터를 대시보드를 통해 확인할 수 있는 전체적인 데이터 파이프라인을 구축하는 프로젝트
목표
- 사용자 수 변화 없이 매일 같은 시간에 로그가 파일 형태로 제공되는 경우
- 사용자 수가 시간에 따라 증가하면서, 실시간으로 로그가 제공되는 경우
목표는 크게 2가지이다. 우선 첫번째 목표를 달성 후, 2번째 목표에 대해 진행하려 한다.
시스템 아키텍처
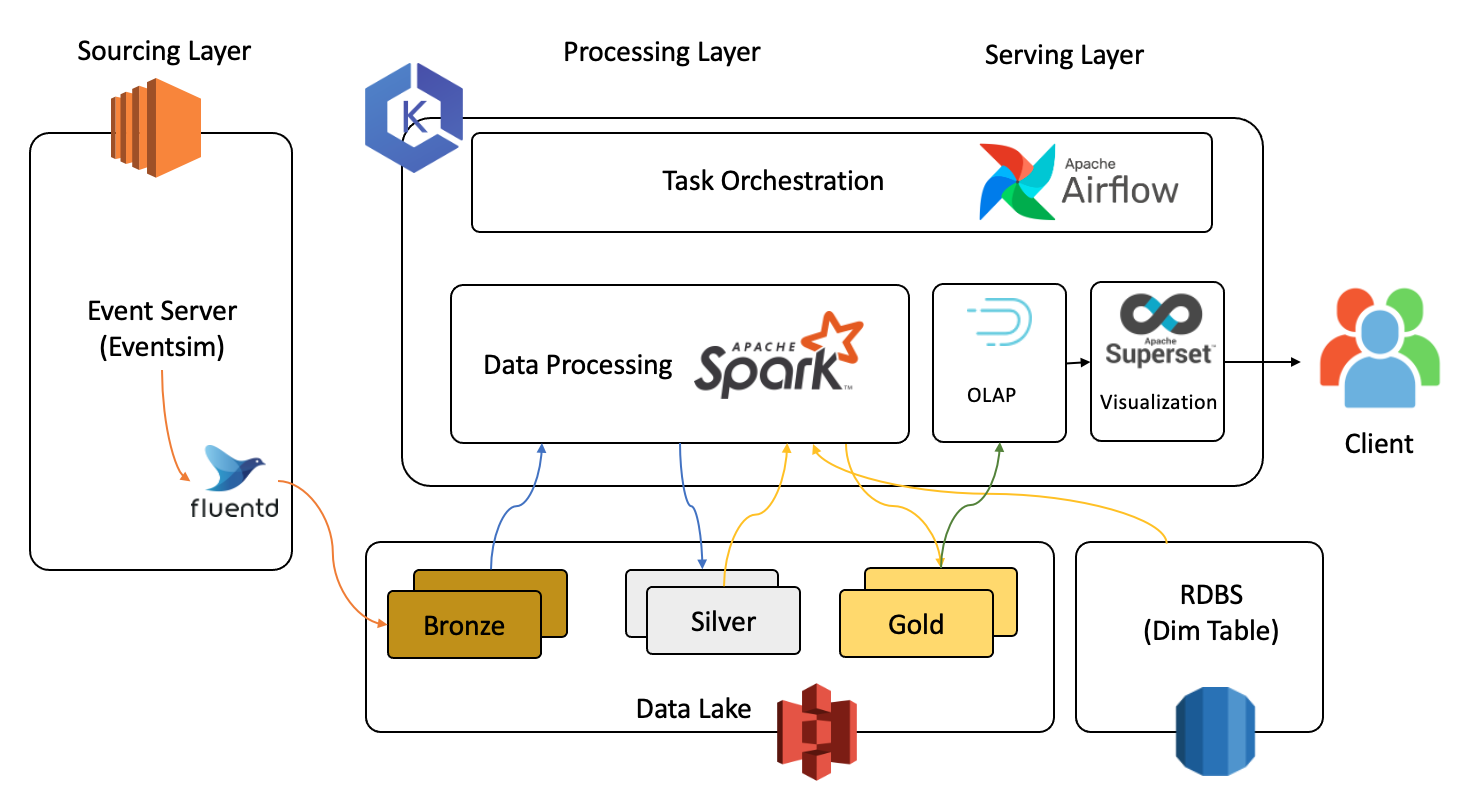
1번 목표를 달성하기 위한 시스템 아키텍처이다. 크게 3부분으로 나눠 설명할 수 있다.
- 이벤트 서버에서 생성된 로그들을 수집해 DataLake에 저장
- Spark를 이용해 DataLake와 RDBMS의 데이터 처리 및 집계 수행
- Druid를 이용해 적재하고 쿼리를 수행해 Superset을 이용해 결과 시각화
스트리밍 데이터를 처리할 땐 이벤트 서버와 Spark 서버 사이에 Kafka를 두고 처리하게 되지 않을까 싶다. 이부분은 아직 구체적인 계획을 세우지 않아서 to be continued.
1. Data Extract
Data는 가상의 이벤트 로그를 생성하는 Eventsim 이라는 프로그램을 이용해 생성하였다. 이를 로그 수집기인 Fluentd를 이용해 수집하였으며, 이를 json 포맷으로 그대로 Object Storage에 전송하게 하였다.
2. Data Transform
우선 Data Lake에 저장된 원본 데이터를 불러와 전처리 작업을 수행하였다. 이후, Dimension Table의 정보까지 불러와 두 테이블에 join 연산을 수행하고 OLAP Database에 입력하기 적절한 형태로 만들어 주었다.
3. Data Load
Data Lake에 저장된 모든 정보가 담긴 table(Gold table)을 불러와 이후 원하는 인사이트를 도출하기 위한 쿼리를 수행하고 Superset을 이용해 시각화하였다.
참고로 모든 작업들은 Airflow를 이용하여 주기적으로 자동으로 실행되도록 설정하였다.

Today I learned...