TensorFlow.js를 이용하여 컴퓨터에게 분류를 학습시켜서 붓꽃의 품종을 분류하는 방법에 대한 글입니다.
Regression
Regression, 회귀는 독립변수와 종속변수가 숫자의 형태일 때 학습이 가능한 방법이다.
독립변수와 종속변수는 여러개가 될 수 있으며, 회귀 방법으로 독립변수와 종속변수 사이의 관계를 찾아내는 것을 머신러닝이라고 한다.
| 독립변수 | 종속변수 |
|---|---|
| 20 | 40 |
| 21 | 42 |
| 22 | 44 |
| 23 | 46 |
그런데 만약 아래와 같은 독립변수와 종속변수 관계가 있다면?
- 종속변수 값이 숫자가 아닌 범주형이다.
- 문자는 머신러닝에서 직접적으로 처리 할 수 없다.
이럴 때는 어떻게 학습을 시켜야 할까?
| 독립변수 | 종속변수 |
|---|---|
| 20 | 붓꽃 |
| 21 | 장미 |
| 22 | 붓꽃 |
| 23 | 장미 |
먼저 앞서 포스팅에서 설명한 회귀의 과정에 대해 다시 살펴보자.

분류의 경우는 위 그림과 같이 결과가 범주인데 이것을 범주형 데이터(e.g. 0,1,2,3...)로 바꿔서 머신러닝이 가능한 데이터 형태로 변환해주면 된다.
붓꽃 품종 분류하기

아이리스는 여러 품종이 있다. 꽃은 꽃잎(Petal)과 꽃받침(Sepal)으로 이루어져 있는데 품종에 따라 꽃잎과 꽃받침의 길이, 폭이 다르다.
이를 관찰해서 기록한 표가 아래와 같다고 가정해보자.
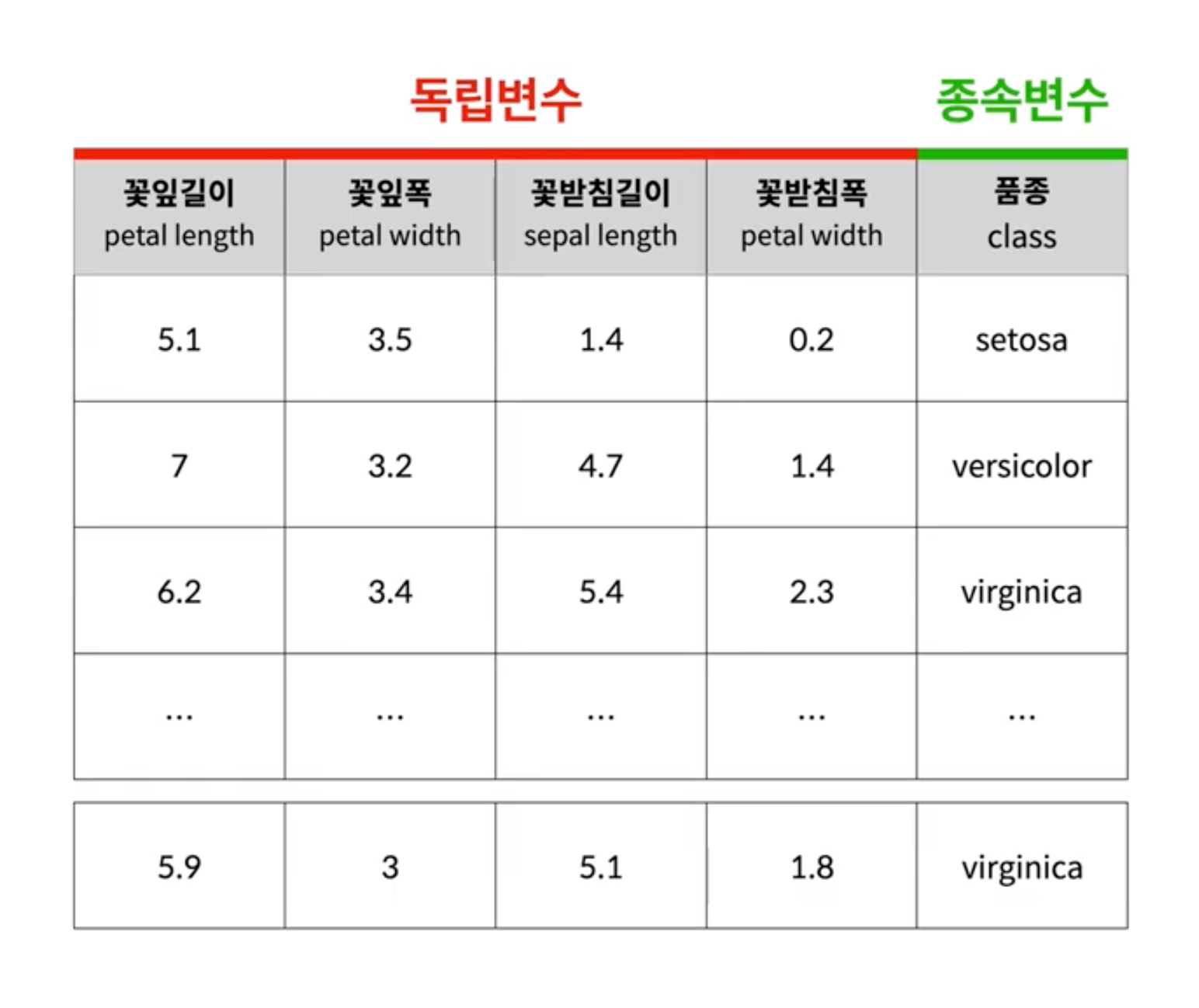
종속변수가 품종이므로 범주를 나타낸다.
학습을 위해서는 이를 숫자로 바꿔주여야 한다.
예를 들면, 다음과 같다.
- 0 : setosa
- 1: versicolor
- 2: virginica
여기서 숫자가 의미하는 바는 각 분류를 나타내는 것이며 숫자의 순서나 크고 작음은 관계가 없다.
그 다음으로는 대소 관계를 없애고 각각의 분류를 독립적인 값으로 만들어야 한다.
- 각각의 값을 행렬의 형태로 나타낼 수 있다.
- 각 row에 숫자가 의미하는 것은 column이다.
- 해당하는 칸은 1, 나머지 칸은 0으로 채운다.

이러한 데이터 변환 방법을 데이터 과학에서 유명한 One Hot Encoding이라고 한다. One Hot Encoding은 사람이 이해할 수 있는 데이터를 컴퓨터에게 주입시키기 위한 가장 기본적인 방법이다.
분류를 위한 데이터 변환 방식을 살펴보았으니 이제 직접 코딩으로 표현 해보자.
코딩하기
학습을 위한 아이리스 raw 데이터는 아래 오픈된 링크에서 참고하였다.
https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv
꽃잎길이,꽃잎폭,꽃받침길이,꽃받침폭,품종
5.1,3.5,1.4,0.2,setosa
4.9,3.0,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5.0,3.6,1.4,0.2,setosa
5.4,3.9,1.7,0.4,setosa
4.6,3.4,1.4,0.3,setosa
5.0,3.4,1.5,0.2,setosa
4.4,2.9,1.4,0.2,setosa
4.9,3.1,1.5,0.1,setosa
5.4,3.7,1.5,0.2,setosa
4.8,3.4,1.6,0.2,setosa
7.0,3.2,4.7,1.4,versicolor
6.4,3.2,4.5,1.5,versicolor
6.9,3.1,4.9,1.5,versicolor
5.5,2.3,4.0,1.3,versicolor
6.5,2.8,4.6,1.5,versicolor
5.7,2.8,4.5,1.3,versicolor
6.3,3.3,4.7,1.6,versicolor
4.9,2.4,3.3,1.0,versicolor
6.6,2.9,4.6,1.3,versicolor
5.2,2.7,3.9,1.4,versicolor
6.3,3.3,6.0,2.5,virginica
5.8,2.7,5.1,1.9,virginica
7.1,3.0,5.9,2.1,virginica
6.3,2.9,5.6,1.8,virginica
6.5,3.0,5.8,2.2,virginica
7.6,3.0,6.6,2.1,virginica
4.9,2.5,4.5,1.7,virginica
7.3,2.9,6.3,1.8,virginica
6.7,2.5,5.8,1.8,virginica
7.2,3.6,6.1,2.5,virginica
...csv 포맷의 파일을 javascript 에서 이해할 수 있는 형태의 데이터로 변환해주기 위해 danfo.js 를 활용하였다. danfo.js는 머신러닝을 기반으로 하는 배열, json, 객체 데이터 등을 테이블 형태로 변환해주는 라이브러리이다.
<html>
<head>
<!-- 버전에 따라서 예제가 동작하지 않는 경우가 있습니다. 아래 버전을 권장합니다. -->
<script src="https://cdn.jsdelivr.net/npm/danfojs@0.1.2/dist/index.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.4.0/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis"></script>
</head>
<body>
<script>
/* 1. 과거의 데이터를 준비 */
dfd.read_csv('https://raw.githubusercontent.com/blackdew/tensorflow1/master/csv/iris.csv').then(function(data){
//callback으로 전달되는 data는 danfo.js로 만들어진 data frame
console.log(data);
data.print();
//data frame을 독립변 컬럼만 분리
독립변수 = data.loc({columns:['꽃잎길이','꽃잎폭','꽃받침길이','꽃받침폭']});
독립변수.print();
//one hot encoding
var encoder = new dfd.OneHotEncoder();
종속변수 = encoder.fit(data['품종']);
data['품종'].print(); //인코딩전
종속변수.print(); //인코딩후
/* 2. 모델의 모양을 만든다. */
var X = tf.input({ shape: [4]});
var H = tf.layers.dense({ units: 4, activation:'relu'}).apply(X); //종속변수:4
var Y = tf.layers.dense({ units: 3}).apply(H); //딥러닝을 위해 히든레이어를 추가
//var Y = tf.layers.dense({ units: 3, activation:'softmax'}).apply(H); //학습할 때 컴퓨터가 데이터를 잘 이해할 수 있는 확률로 표현
model = tf.model({ inputs: X, outputs: Y });
//모델을 컴파일
var compileParam = { optimizer: tf.train.adam(), loss: tf.losses.meanSquaredError} //회귀에서 사용
//var compileParam = { optimizer: tf.train.adam(), loss: 'categoricalCrossentropy', metrics:['accuracy'] } //분류에서 사용
model.compile(compileParam);
//모델을 시각화
tfvis.show.modelSummary({name:'요약', tab:'모델'}, model);
/* 3. 데이터로 모델을 학습시킨다. */
_history = [];
var fitParam = {
epochs: 100, //학습 횟수
callbacks:{
onEpochEnd: //학습마다 상태 확인
function(epoch, logs){
console.log('epoch', epoch, logs, 'RMSE=>', Math.sqrt(logs.loss));
_history.push(logs); //그래프 출력을 위해 로그 정보 저장
tfvis.show.history({name:'loss', tab:'역사'}, _history, ['loss']); //그래프에 loss 출력(값이 작아질 수록 학습이 잘 이루어짐)
//tfvis.show.history({name:'accuracy', tab:'역사'}, _history, ['acc']); //그래프에 accuracy 출력(1에 가까울수록 정확)
}
}
}
model.fit(독립변수.tensor, 종속변수.tensor, fitParam).then(function (result) {//danfo.js으로 tensor 표현
// 4. 모델을 이용합니다.
// 4.1 기존의 데이터를 이용
예측한결과 = new dfd.DataFrame(model.predict(독립변수.tensor));//danfo.js으로 tensor 표현
예측한결과.print();
종속변수.print();
});
})
</script>
</body>
</html>loss 계산을 meanSquaredError로 epochs 100번으로 학습시킨 후 예측한 결과는 다음과 같다.
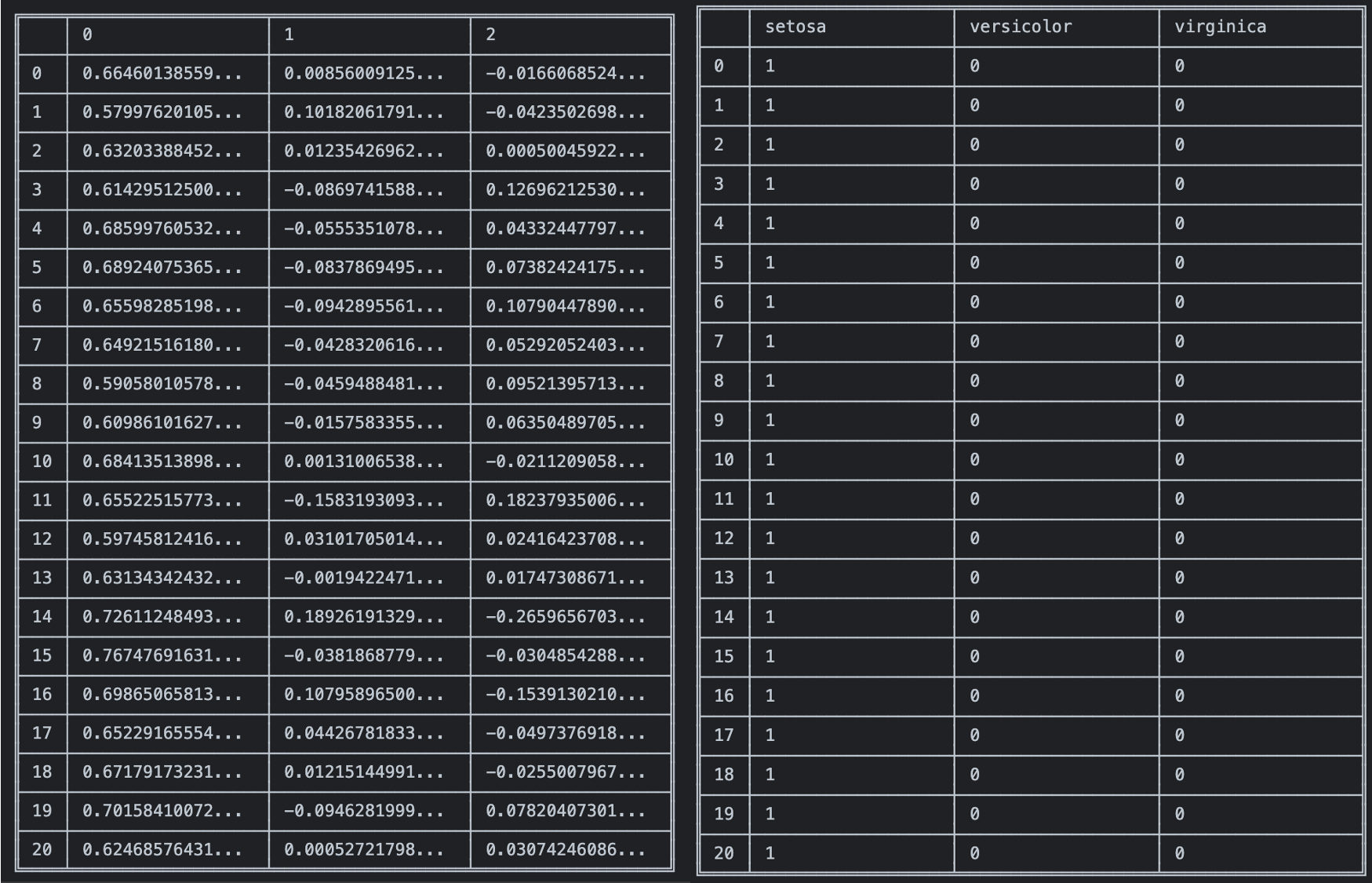
실제 종속변수와 비교해보면 어느정도 가까워지고 있으나 만족스러운 결과를 얻지는 못하였다.
더욱 정확한 결과를 얻기 위해 다음의 방법들로 변경하여 학습시켜 보자.
- Hidden layer에 activation function으로 softmax를 사용한다.
- 특정 데이터들을 모든 값의 합이 1이되는 0~1 사이의 값으로 변환
- softmax([1.04, -0.02, -0.027]) => [ 0.5915427493782479, 0.20494342258071094, 0.2035138280410411 ]
function softmax(arr) {
return arr.map(function(value,index) {
return Math.exp(value) / arr.map( function(y /*value*/){ return Math.exp(y) } ).reduce( function(a,b){ return a+b })
})
}- 분류에서는 loss 측정에 categoricalCrossentropy을 사용한다.
- Wiki 에 수식이 나와있다.... 뭐 아무튼 그렇다고 한다....
아래는 activation function과 loss 측정 방법을 변경하고 500번 정도 학습한 결과 값이다.
첫 번째 학습한 결과보다는 조오금 더 예측이 잘 된 것을 확인할 수 있다.

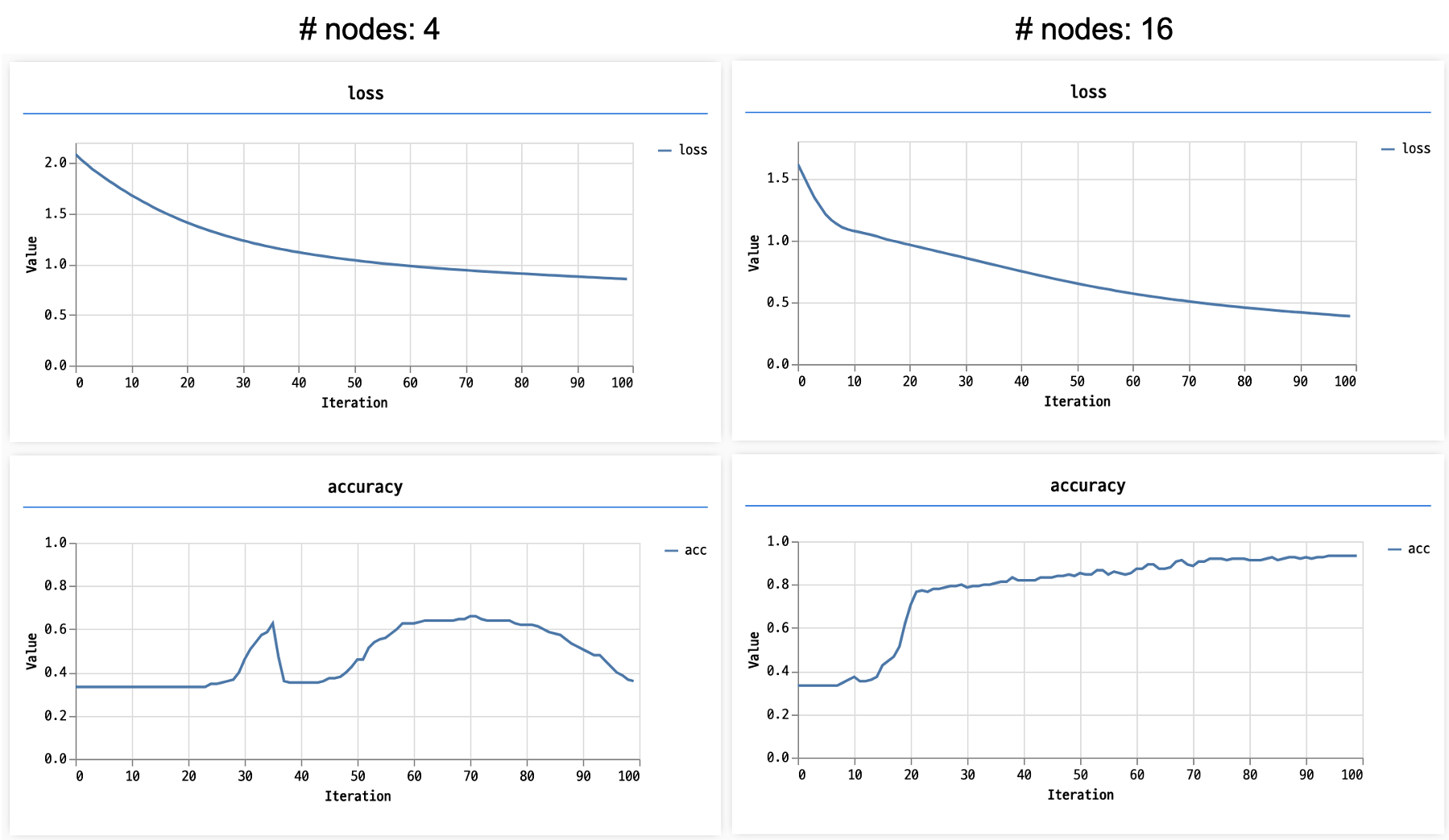
또한 Hidden Layer의 노드 수가 학습의 속도에 영향을 미친다. 따라서 적당한 노드 수(Hyper Parameter)를 찾는 노가다가 필요하다.
보통 노드 수는 2의 제곱 수를 많이 사용한다. (근데 꼭 그렇지만은 않다고 한다.)
- 노드 수에 따른 loss와 accuracy 비교