
Relation Extraction(관계 추출)이란?
:비구조적인 문장에서 구조적인 트리플(triple)를 추출하는 태스크이다. 트리플이란 두 개체 간의 관계(relation)를 <주어, 관계, 목적어>으로 나타낸 구조이다.
text: 대한민국의 수도는 서울이다.
triple: <대한민국, 수도, 서울>
Relation Extraction을 연구 하는 이유
- 구조적으로 표현된 정보는 자연어로 표현된 정보보다 기계가 해석하기 수월하기 때문이다.
- 방대한 자연어 데이터를 RDF(Resource Description Framework) 형식인 트리플로 표현하여 연결데이터(Linked Data)를 구축하기 위해서이다.
- 기계가 해석하고 처리할 수 있는 정보의 활용가치가 높기 때문이다.
- 질의응답을 비롯한 다양한 분야에서 유용하게 사용될 수 있다.
Relation Extraction SOTA 모델
TACRED 데이터에서 1위~3위의 논문들을 가져왔다. 추후에는 더 다양한 논문을 읽어 보고 싶다. 시간관계상 3개의 논문만 읽어 보았다. (SpanBERT도 추후에 추가하겠다.)
1 | RECENT+SpanBERT : Relation Classification with Entity Type Restriction
(LYU, Shengfei; CHEN, Huanhuan. Relation Classification with Entity Type Restriction. arXiv preprint arXiv:2105.08393, 2021.)
: 논문의 주요 키워드는 Entity Type restriction이다. 기존의 모델들은 relation classification을 진행할 때 두 개의 entity가 형성할 수 있는 모든 relation을 염두에 두기 때문에 부적절한 relation 또한 부여받을 가능성이 있다. RECENT는 entity pair에 해당하지 않는 관계들을 제한한다. RECENT는 어떠한 모델에도 적용가능하며 본 논문은 TACRED에서 RECENT+SpanBERT 모델로 F1-score 75.2%fh SOTA를 달성했다.
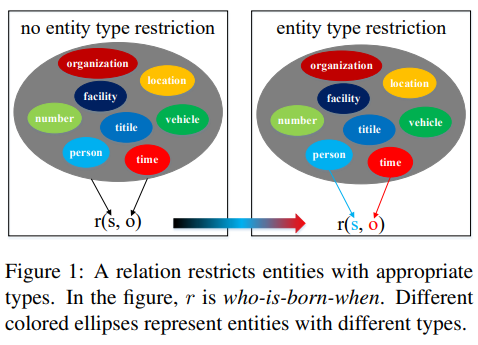
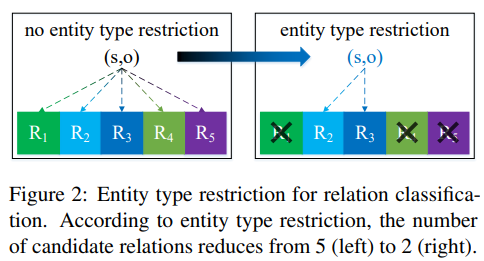
간단하면서 좋은 아이디어 인듯하다. 특정 relation에 오는 subject와 object이 정해져있다 라는 부분이 인상적이다.
2 | EXOBRAIN : Improving Sentence-Level Relation Extraction through Curriculum Learning
(PARK, Seongsik; KIM, Harksoo. Improving Sentence-Level Relation Extraction through Curriculum Learning. arXiv preprint arXiv:2107.09332, 2021.)
: 데이터를 난이도별로 분할하여 학습에 활용하는 커리큘럼 학습 기반 관계 추출 모델을 제안한다. 커리큘럼 학습 과정에서 쉬운 예제를 통해 관계 추출을 위한 일반적인 매개 변수를 학습하고 어려운 예제를 점차적으로 학습하면서 높은 수준의 추론이 가능하게 된다. 본 논문에서는 cross review 방법을 사용하여 자동으로 난이도 분류를 수행하였다. 또한 효과적인 관계 추출을 위해 dependency graphs를 사용하는 graph attention network(GAT)를 사용한다. GAT는 두 엔터티 간의 구문 구조 정보를 인코딩하고 GAT의 출력과 인코딩 벡터를 연결하여 쌍선형 분류기를 통해 적절한 관계 레이블을 예측한다. 모델은 RoBERTa large model를 사용한다. TACRED와 Re-TACRED를 이용한 실험에서 제안한 방법은 F1-score 75.0%와 91.4% 성능을 낸다. Re-TACRED에서는 SOTA이다.
GAT라는 용어를 여기에서 처음 봤다. 아직도 부족하다는 걸 느낌. GAT에 대해서도 나중에 공부해야겠다. 다른 방식은 이해가는데 GAT는 좀 이해가 안간다.
3 | Relation Reduction : Relation Classification as Two-way Span-Prediction
(COHEN, Amir DN; ROSENMAN, Shachar; GOLDBERG, Yoav. Relation Classification as Two-way Span-Prediction. arXiv preprint arXiv:2010.04829, 2020.)
: relation classification(RC)을 QA(질문 응답)와 유사한 SP(스팬 예측) 문제로 해결하자고 주장하는 논문이다. (추후 추가할 예정)
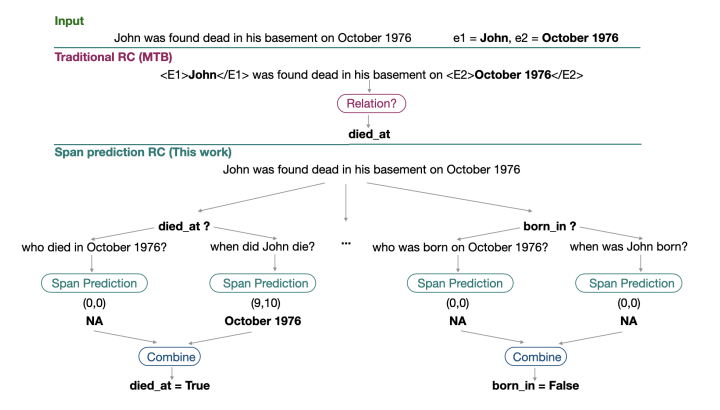
느낌점
- RE라고 알았던것이 대부분의 논문에서는 RC로 표현되어있다. 그도 그럴것이 정확히 말하면 추출이 아닌 분류이기 때문이다.
- 인간과 유사한 방식으로 설계한 모델들이 뛰어난 성능을 보인다. RE관련하여 논문을 읽어보니 새로운 아이디어들이 조금씩 생겨난다. 좋은 경험이 었다.
- 오늘따라 논문이 잘 읽힌다.
- 그래프와 관련된 nlp 연구 논문은 잘 안 읽어봤는데 더 공부를 해야겠다는 생각을 했다.
Reference
