
1. BERT란?
- Google에서 만든 사전 훈련된 모델이다.
- 등장 당시 11개의 NLP task에서 SOTA(State-Of-The-Art)를 기록한 어마어마한 모델이다.
- BERT의 모델은 Transformer(인코더-디코더 구조)를 기반으로 하고 있다.
- BERT는 이 중에서도 Transformer의 왼쪽, 즉 인코더만을 사용하는 모델이다.
- 차로 따지면 완전 좋은 슈퍼카 엔진이 나온격 (내 주관적인 생각)
사실 BERT에 대해서 공부하기 전에 사전 지식이 필요하다. 그 중 가장 중요한 Transformer에 대해서 자세히 알아보겠다.
2. Transformer
2-1. Transformer란 무엇인가?
- 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델이다.
- 인코더-디코더 구조를 설계되어있다.
- 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, Attention 만으로 구현한 모델이다.
seq2seq 구조에서의 인코더-디코더는 각각 하나의 RNN이 t개의 time step을 가지는 구조이다. transformer 구조에서는 N개의 인코더-디코더로 이루어진 구조이다. 논문에서는 각각 6개를 사용했음.
- 주요 하이퍼파라미터
- : 입력과 출력의 크기를 의미한다. 즉, seq_len이라고 생각하면 된다.
- num_layer : 인코더와 디코더의 개수
- num_heads : 트랜스포머에서는 어텐션을 사용할 때, 한 번 하는 것 보다 여러 개로 분할해서 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합치는 방식을 택했습니다. 이때 이 병렬의 개수를 의미합니다.
- : 트랜스포머 내부에 피드 포워드 신경망이 존재한다. 신경망의 은닉층의 크기를 의미한다.
2-2. Positional Encoding
- RNN은 단어를 순차적으로 입력받아서 처리하는 특성으로 각 단어의 위치 정보(position information)를 가질 수 있다.
- 하지만 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니다. positional encoding은 단어의 위치 정보를 알려줄 수 있다.
- 임베딩 벡터들이 Transformer의 입력으로 사용되기 전에 positional encoding의 값이 더해진다.
- positional encoding을 사용하면 같은 단어라고 하더라도 문장 내의 위치에 따라서 Transformer의 입력으로 들어가는 임베딩 벡터의 값이 달라집니다. 이에 따라 Transformer의 입력은 순서 정보가 고려된 임베딩 벡터가 된다.
2-3. Attention
- Transformer에서 사용되는 attention 3가지가 있습니다.
(1. Encoder Self-Attention, 2. Masked Decoder Self-Attention, 3. Encoder-Decoder Attention) - 1,2번인 경우 Self-Attention은 본질적으로 Query, Key, Value가 벡터들의 출처가 동일하다.
- 3번에서는 Query가 디코더의 벡터이고, Key와 Value가 인코더의 벡터이므로 Self-Attention이라고 부르지 않습니다.
<요약>
인코더의 셀프 어텐션 : Query = Key = Value
디코더의 마스크드 셀프 어텐션 : Query = Key = Value
디코더의 인코더-디코더 어텐션 : Query : 디코더 벡터 / Key = Value : 인코더 벡터
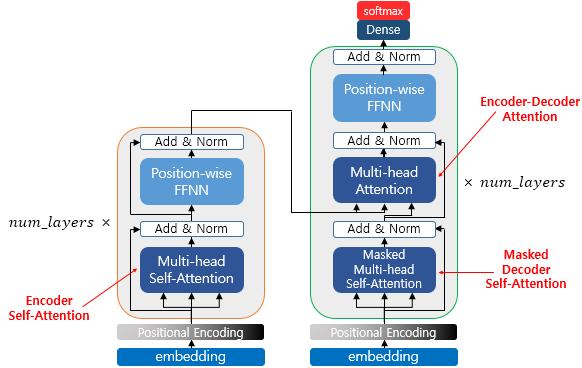
2-4. Encoder
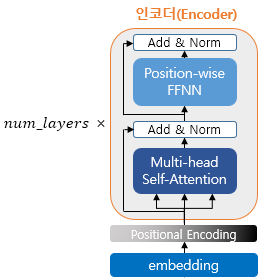
- Transformer은 num_layer 개수 만큼 인코더 층이 있다.
- 하나의 인코더 층은 크게 총 2개의 서브층(sublayer)으로 나뉘어진다. (셀프 어텐션, 피드 포워드 신경망)
2-4-1. 인코더의 Self-Attention (셀프 어텐션)
2-4-1. 인코더의 Position-wise FFNN (포지션-와이즈 피드 포워드 신경망)
<참고 자료>
1) https://wikidocs.net/31379

NLP 공부하는 사람