1. RDBMS(Relational DataBase Management System)
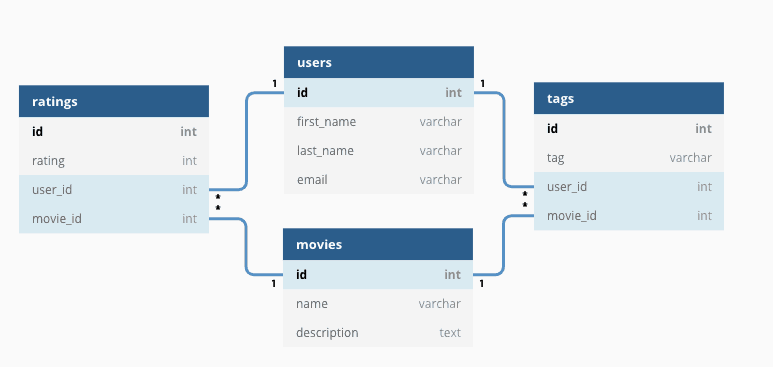
관계형 데이터베이스는 말 그대로 각 데이터가 서로 관계가 있는 데이터베이스이다.
2. TABLE, Col-Row, Primary Key
데이터는 2차원의 테이블로 표현되며, 그 안에는 column row로 구성된다. column(열)은 테이블의 항목, row(행)은 각 항목들의 값에 해당한다. 각 행에는 고유한 primary key가 있어, 이를 사용해 해당 다른 테이블에서 해당 row를 검색할 수 있다. 테이블과 테이블을 연결할 때는 Foreign key(외래키)를 사용하는데, 자신의 테이블 이외의 테이블에 있는 primary key를 foreign key라고 한다.
왜 테이블을 나누어야 하는가
하나의 테이블에 모든 정보를 넣게 되면, 중복되는 정보, 필요없는 정보까지 한꺼번에 저장된다. 이는 용량의 증가와 탐색의 비효율성을 낳게 된다. 따라서 관련된 데이터를 묶고 테이블을 나눈 후, 필요한 테이블끼리만 연결시키면 낭비 없이 데이터를 활용할 수 있다.
3. 1:1, 1:N, N:M 관계
-
1 : 1 관계

테이블 A의 행과 테이블 B의 행이 일 대 일 매칭이 되는 관계. -
1 : N 관계
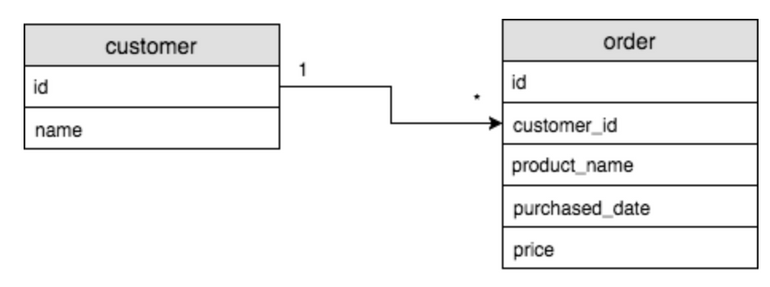
테이블 A의 행은 테이블 B의 여러 행과 연결이 되는 관계. -
N : M 관계

테이블 A의 여러 행이 테이블 B의 여러 행과 연결이 되는 관계. 일반적으로 두 테이블을 직접 연결하지는 않고, 중간에 각 테이블의 공통 속성을 뽑은 테이블을 만들어서 그 테이블과 연결시킨다. 이처럼 데이터 간의 관계를 설정하여 테이블을 작성하는 것을 정규화(normalization)이라고 한다.
4. Transaction & ACID
- 트랜잭션이란 DBMS 안에서 이루어지는, 데이터베이스에 대한 일련의 작업으로 구성된 unit을 뜻하며 다른 트랜잭션에 대해 독립적이다. 트랜잭션의 작업은 하나라도 실패하면 모두 실패하는 것으로 간주되므로, 작업은 모두 성공하거나 모두 실패하게 된다.
- ACID
- Atomicity: all or nothing. 일련의 작업은 모두 성공하거나 모두 실패한다. 중간 단계까지만 실행되지 않는다.
- Consistency: 트랜잭션이 데이터를 변경할 때는 정해진 기준을 따라야 한다. 그리고 데이터를 생성할 때도 규칙에 따라 유효한 데이터를 생성해야 한다.
- Isolation: 트랜잭션이 수행중일 때는 다른 작업이 끼어들지 못한다. 즉, 트랜잭션은 반드시 연속적으로 수행되어야 하므로 중간 단계의 데이터는 밖에서 볼 수 없음을 뜻한다.
- Durability: 수행된 트랜잭션은 영원히 시스템 안에 남아 있어야 함을 의미한다. 일반적으로 트랜잭션 로그를 기록함으로써 달성한다.
5. 관계형<->비관계형 데이터베이스

관계형 데이터베이스
- 데이터를 효율적 체계적으로 저장/관리할 수 있다.
- 저장하는 데이터의 스키마를 미리 정의함으로써 완전성이 보장된다.
- 스키마를 미리 정의하는 특성상, 유연성이 부족하다
- 정형화된 데이터를 저장/관리하는데 사용
- MySQL, PostgreSQL, Oracle 등
비관계형 데이터베이스
- 데이터 구조를 미리 정의할 필요가 없으므로 구조 변화에 유연하게 대응할 수 있다.
- 확장도 쉬우므로 방대한 양의 데이터를 저장하는데 유리하다.
- 데이터의 완전성이 떨어진다.
- MongoDB, Redis, Cassandra 등
6. ERD 구성도 모델링
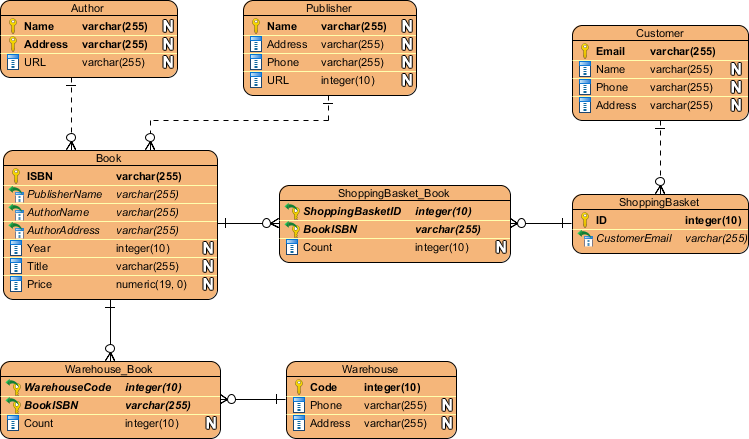
ERD는 데이터베이스의 논리적 모델링에서, 데이터베이스를 표현하는 방법 중 하나이다. 그리고 논리적 모델링을 할 때 수행하는 작업이 정규화인데, 데이터를 정해진 규칙에 따라 규격화하는 것을 뜻한다.
정규화는 여러 단계가 있지만 보통 3단계에 걸쳐 실행하게 된다.
- 1차 정규화: 테이블에 같은 성격과 내용의 컬럼이 계속해서 나타난다면, 컬럼을 제거하여 기존 테이블의 PK를 FK로 추가한 새로운 테이블을 작성한다.
- 2차 정규화: 2차 정규화는 PK가 복합키가 되었을 경우 검토한다. 여기서 복합키란 PK가 둘 이상의 속성으로 구성된 것을 말한다. 복합키가 존재하면서, 속성들 중 복합키의 일부에만 종속되는 속성이 존재할 경우 2차 정규화를 실시한다.
- 3차 정규화: 일반적으로 테이블의 PK가 아닌 컬럼들은 PK에 의존해야 한다. 그런데 PK에 의존하는 것처럼 보이지만 실제로는 그렇지 않은 일반 컬럼들이 존재한다면 이를 분리하는 것이 3차 정규화이다.
