Threading
1. 정의와 멀티스레딩
하나의 스레드는 프로그램 속에서 하나의 실행 흐름이다. 그렇다면 멀티스레딩(multithreading)은 스레드 여러개를 사용한다는 말이고, 이는 한 프로세스 안에서 여러 스레드가 자원을 공유하여 처리한다는 것을 뜻한다. 결국 스레드를 여러개 사용하면 실행 속도도 빨라지겠구나 생각하겠지만, 전혀 그렇지 않다. 오히려 느려질 수도 있다.
왜 이와 같은 비상식적인 일이 발생한 것일까? 이는 파이썬의 GIL(Global Interpreter Lock)에 기인한 것으로, 자세한 내용은 이곳을 참조하고 여기서는 간단히 설명하겠다. 파이썬에서는 GIL이 여러개의 스레드가 동시에 실행되는 것을 막아놓았다. 그렇기 때문에 여러 스레드를 동시에 실행시키도록 코드를 짜도, 같은 시간대에 실행되는 스레드는 언제나 하나이다.
2. 예제
그러면 실제로 멀티 스레드를 구현해보자.
import threading
import time
shared_number = 0
def thread_1(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(50000000,) )
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(50000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")구현을 위해 필요한 메소드만 간단히 설명하자면
import threading: 이거 안하면 스레딩을 사용할 수 없다.threading.Thread(target=호출할 객체, args=(인자), kwargs=(키워드 인자)): 스레드를 호출하여 어떤 작업을 시킬지 정한다. 여기서 constructor는 반드시 keyword argument 형식으로 호출해야 한다.thread.start(): 이름처럼 스레드에게 작업을 시작하라고 명령하는 메소드이다. 스레드 객체 안에서 반드시 한 번만 실행해야 하고, 그 이상 실행할 시 RuntimeError가 발생한다.thread.join(): 스레드가 작업을 종료할 때까지 기다리게 하는 메소드이다. 그리고 이 메소드가 실행된 스레드가 종료되기 전까지는 호출되는 것을 막는다.
그런데 이 코드를 실행해 보면 알겠지만 심각한 문제가 있다.
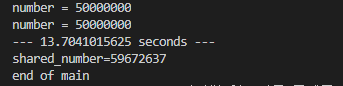
바로 위와 같이 shared_number가 각 number=50,000,000을 더한 100,000,000이 나와야 하는데 이상한 숫자가 나와버렸다. 그 이유에 대해서는 밑에서 확인하겠다.
3. 스레드 동기화
멀티스레딩을 할 때 각 스레드는 다른 스레드가 어디서 무엇을 하는지 전혀 알지 못한다. 그리고 각 스레드 간에는 메모리가 겹치는 영역이 존재하기 때문에, 공유 리소스에 동시에 접근하는 경우가 발생한다. 동시에 접근하게 되면 아래와 같이 사용자가 의도하지 않은 결과가 나타나게 되고, 그것이 위에서 나타난 결과이다.
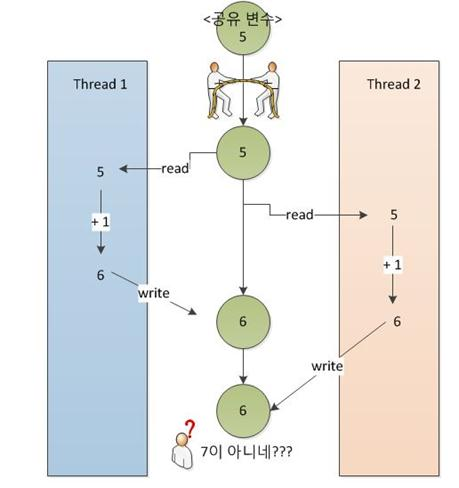
이러한 상황을 방지하기 위해서 스레드를 동기화(Syncronization)하여 한 스레드가 이미 사용하고 있는 자원을 다른 스레드는 사용하지 못하게 하는 것이 필요하다. 스레드 동기화를 위한 여러 방법이 있는데 그 중 몇가지를 알아보자.
3-1. Lock
Lock은 다른 언어에서는 MutEx(Mutual Exclusion=상호배제)라고도 부른다. 말 그대로 둘이 같은 공간에 있으면 안된다는 뜻이다. 파이썬에서는 이를 Lock이라고 정의해, 스레드가 공유자원을 사용하고 있으면 그곳의 lock을 얻게 되고, 스레드는 lock이 반환되지 않는 이상 그 자원을 사용하지 못한다. Lock을 사용하기 위해서는, lock=threading.Lock()으로 Lock을 불러오고, 작업이 시작하는 곳에서 lock.acquire()를 실행해 Lock을 획득하고, 작업이 끝나는 곳에서 lock.release()를 실행해 Lock을 해제한다. 이를 적용해 예제를 고치면
import threading
import time
shared_number = 0
lock=threading.Lock() # Lock 객체 실행
def thread_1(number):
global shared_number
print("number = ", end=""), print(number)
lock.acquire() # Lock 획득
for i in range(number):
shared_number += 1
lock.release() # Lock 해제
def thread_2(number):
global shared_number
print("number = ", end=""), print(number)
lock.acquire() # Lock 획득
for i in range(number):
shared_number += 1
lock.release() # Lock 해제
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
[...]이 함수를 실행하면 shared_number가 100,000,000이 되어 각 스레드가 동시에 실행되지 않고 접근한 순서대로 실행되었음을 알 수 있다. (number 위치가 이상해진 것은 신경쓰지 말자)
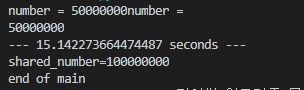
문제점
Lock을 사용하면 모든 동시 접근 문제가 해결될 것 같았지만 현실은 그렇지 않다. Lock 에도 문제가 있는데, 바로 공유 자원에 대해 오직 하나의 스레드만 접근 가능하다는 점이다. 얼핏 들으면 다른 스레드가 접근 못하니 좋은 것 아닌가 싶겠지만, 문제는 다른 스레드에 Lock을 가진 스레드 자신도 포함된다는 점이다. Lock을 반환하지 않는 이상, Lock을 가진 스레드가 접근을 요청하는 스레드가 동일한 스레드인지 알지 못하기 때문에 자기 자신이 사용하고 있는 자원에 접근할 수가 없다.
3-2. Semaphore
동기화를 위한 다른 방법은 세마포어이다. 이름도 생소하지만 어쨌든 요점은 신호를 통해 자원에 접근을 통제한다는 점이다. 세마포어를 선언하면 기본적으로 값을 설정해야 한다.(default=1) 그래서 이 값이 0이 되면 작업을 중지하고 Lock이 해제된다. 숫자는 1보다 크게 설정할 수 있기 때문에 횟수 등의 제한이 있는 작업에서 한계를 설정하기 위해 세마포어를 사용하기도 한다.
Multiprocessing
1. 정의
위의 멀티스레딩에서 실행 속도에 차이가 없음을 보고 실망했다면, 멀티프로세싱을 보자.
멀티프로세싱이란 스레딩 모듈과 유사한 API를 사용하여 프로세스 생성을 지원하는 패키지이다. 멀티프로세싱은 멀티스레딩과 다르게 GIL의 제약을 피할 수 있기 때문에 복수의 프로세서를 활용할 수 있다.
그렇다면 멀티스레딩과 멀티프로세싱의 차이는 다음으로 요약할 수 있다.
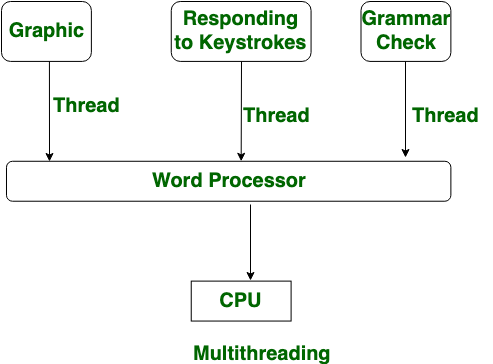
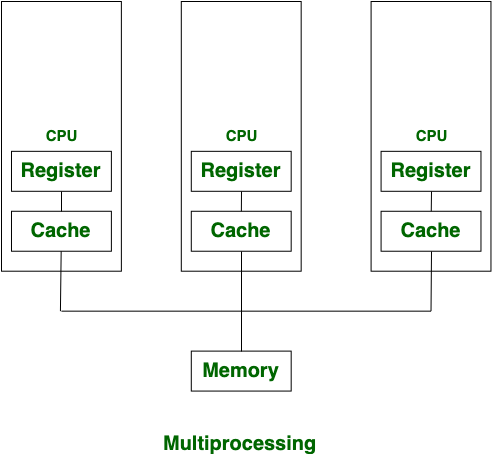
- 멀티스레딩은 하나의 프로세스 안에서 여러 스레드가 동시에 작업하지만 멀티프로세싱은 CPU가 추가된다.
- 멀티스레딩은 프로세스에 비해 단위가 작기 때문에 생성이 쉽지만 멀티프로세싱은 프로세스 생성에 시간이 걸린다.
2. 멀티프로세싱에서 객체를 교환하는 방법
멀티프로세싱 모듈에서는 프로세스가 의사소통하기 위한 통로로써 Queue()와 Pipe()를 제공한다.
2-1. Queue()
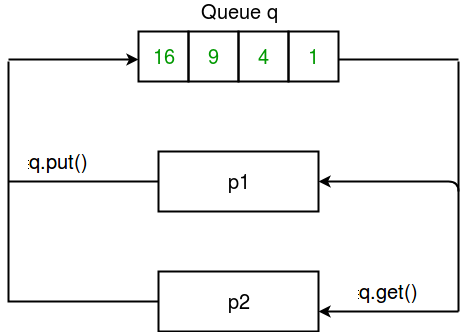
멀티프로세싱에서의 큐는 일반적인 큐의 복제판이라고 공식 문서에 쓰여 있는 만큼, 기능이 유사하다. 프로세스가 작업을 실행하여 큐에 넣는 것을 반복하다가, 작업이 모두 끝나면 넣은 순서대로 다시 빼는 과정(FIFO)을 실행한다. 큐는 여러 방향의 의사소통이 필요할 때 주로 사용한다.
위에서 스레드로 만들었던 코드를 멀티프로세싱의 큐로 다시 구현하면 다음과 같다.
from multiprocessing import Process, Queue
import time
def worker(id, number, q):
increased_number = 0
for i in range(number):
increased_number += 1
q.put(increased_number)
return
if __name__ == "__main__":
start_time = time.time()
q = Queue()
th1 = Process(target=worker, args=(1, 50000000, q))
th2 = Process(target=worker, args=(2, 50000000, q))
th1.start()
th2.start()
th1.join()
th2.join()
print("--- %s seconds ---" % (time.time() - start_time))
q.put('exit')
total = 0
while True:
tmp = q.get()
if tmp == 'exit':
break
else:
total += tmp
print("total_number=",end=""), print(total)
print("end of main")
실행 결과를 멀티스레딩과 비교해 보면 시간이 반 이상 줄어든 것을 볼 수 있다.
그리고 구현에 있어서도 Queue를 생성하여 Queue.put()으로 큐에 데이터를 넣고, Queue.get()으로 데이터를 가져오는 과정만 추가해주면 간단하게 구현할 수 있다.
2-2. Pipe()
파이프는 생김새에서 유추할 수 있듯, 양 끝에만 출입구가 존재하고 그로 인해 양방향 의사소통에 사용될 때 더 적합하다. Pipe()함수를 실행할 때는 연결 쌍을 리턴하기 때문에 보통 parent_conn, child_conn 등으로 리턴값을 할당한다. 그리고 각각의 연결은 send()와 recv()메소드를 가지고 있으므로 한 쪽에서는 메시지를 보내기만 하고 다른 한 쪽에서는 메시지를 받기만 하도록 설정한다.
(번외)Thread-/Process-safe
위의 큐로 작성된 코드를 다시 한번 보고 Lock을 사용한 스레드의 실행 코드에서 다른점을 비교해보자. 큐에서는 Lock과 관련된 lock.acquire()/lock.release()를 사용하지 않았다는 것을 알 수 있을 것이다.
스레드나 프로세스가 동기화되지 않아 작업이 꼬이는 것을 thread-/process-unsafe 라고 한다. 그리고 이것을 방지하기 위해 만든 것이 Lock이라는 사실은 이미 알고 있다. 그런데 왜 큐에서는 Lock을 쓰지 않았는데도 제대로 동작하는 것일까?
이는 큐와 파이프의 동작 원리와 관련이 있다. 큐는 여러 생산자/사용자가 있더라도 FIFO원리를 통해 순서대로 작업을 진행한다. 그렇기 때문에 Lock을 획득하는 과정 없이도 순서가 꼬이지 않을 수 있다.
파이프는 양방향 의사소통일 경우 사용되는데, 스레드/프로세스가 한 곳에서 동시에 읽기, 쓰기를 하지 않는 이상 작업이 겹치지 않으므로 알아서 동기화가 된다고 할 수 있다.
3. Shared Memory
멀티프로세싱에서 큐와 파이프가 프로세스간의 의사소통을 위해 사용되었다면, 이번에 소개할 공유 메모리(shared memory)는 프로세스간의 의사소통 매개체를 사용하지 않고 프로세스가 다른 프로세스에 직접 접근할 수 있도록 하는 모듈이다. 전통적으로 프로세스는 자신의 메모리에만 접근할 수 있었지만, 공유 메모리를 사용하면 프로세스간에 메시지를 보내지 않고도 데이터를 공유할 수있다.
공유 메모리를 생성하기 위해서는 multiprocessing.shared_memory.SharedMemory(name=None, create=False, size=0) SharedMemory 메소드를 실행하는데, 새로 생성할 때와 기존 메모리에 붙일 때의 인자가 약간 다르다. 새로 공유 메모리를 생성할 때는 create=True와 size=크기를 지정해 줄 필요가 있고, 기존 메모리에 붙인다면 기존 메모리의 name을 명시해 주어야 한다.
또한 공유 메모리를 사용할 때는 반드시 close()와 unlink()를 실행해야 한다. 모든 개체들은 개체를 사용하고 나면 close()를 통해 공유 메모리로의 접근을 차단해야 한다. 다만 close()는 공유 메모리를 완전히 없애는 것은 아니므로, 사용한 공유 메모리를 완전히 삭제하기 위해서는 unlink()를 실행해 주어야 한다.
두 프로세스에서 50,000,000씩 더해 100,000,000이 되게 하는 코드를 세마포어와 공유 메모리로 구현하면 아래와 같다.
from multiprocessing import Process, Semaphore,shared_memory
import numpy as np
import time
def worker(id, number, a, shm, sema):
increased_number = 0
for i in range(number):
increased_number += 1
# 세마포어 획득
sema.acquire()
# 밑에서 생성해 놓은 공유 메모리 블록에 붙임
existing_shm=shared_memory.SharedMemory(name=shm)
b=np.ndarray(a.shape, dtype=a.dtype, buffer=existing_shm.buf)
b[0]+=increased_number
# 세마포어 방출
sema.release()
if __name__ == "__main__":
sema=Semaphore(1)
start_time = time.time()
a=np.array([0])
# nbyes=저장된 만큼의 크기
# 공유메모리를 생성
shm=shared_memory.SharedMemory(create=True, size=a.nbytes)
# .shape=배열의 차원을 튜플 형식으로 돌려줌 .dtype=데이터 타입 출력
# 공유 메모리로 동작하는 numpy 배열 생성
c=np.ndarray(a.shape, dtype=a.dtype, buffer=shm.buf)
th1 = Process(target=worker, args=(1, 50000000, a, shm.name, sema))
th2 = Process(target=worker, args=(2, 50000000, a, shm.name, sema))
th1.start()
th2.start()
th1.join()
th2.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("total_number=",end=""), print(c[0])
shm.close()
shm.unlink()
print("end of main")