
본 포스트는 박재호님의 유튜브 강의(링크)를 보고 일부 발췌하여 정리한 내용입니다.
사용된 자료, 샘플 데이터 등은 모두 SQLite Tutorial에서 확인할 수 있습니다.
1. 인덱스란
관계형 데이터베이스에서는 데이터의 양, 즉 행의 개수가 늘어날수록 하나의 데이터를 찾는데 걸리는 시간이 늘어나게 된다.
이 때, rowid와 같이 특수한 값을 사용하면 그 값의 위치를 기억했다가 호출되면 순차적으로 찾지 않고 바로 위치로 찾아갈 수 있기에 탐색 속도가 빨라진다.
그런데 항상 rowid로 검색할 수 있는 것은 아니기 때문에, 설정한 필드와 거기에 rowid를 매칭시킨 인덱스를 만들어 탐색 속도를 빠르게 할 수 있다.
인덱스를 생성하는 방법은 다음과 같다.
CREATE [UNIQUE] INDEX index_name
ON table_name(column_list);인덱스를 생성할 때 설정한 필드의 값이 같은 것들이 있다면 어떻게 될까?
실습을 통해 알아보자.
CREATE TABLE contacts (
first_name text NOT NULL,
last_name text NOT NULL,
email text NOT NULL
);
CREATE UNIQUE INDEX idx_contacts_email
ON contacts (email);
INSERT INTO contacts (first_name, last_name, email)
VALUES('Johny','Doe','john.doe@sqlitetutorial.net');테이블, 인덱스를 생성하고 데이터를 넣었다.
이 때 contacts 테이블의 email필드는 UNIQUE제약이 걸려있지 않다.
따라서 email 주소를 같은 것을 넣어도 에러가 발생하지 않을 것이라 생각할 수 있다.
하지만 데이터를 넣어 보면
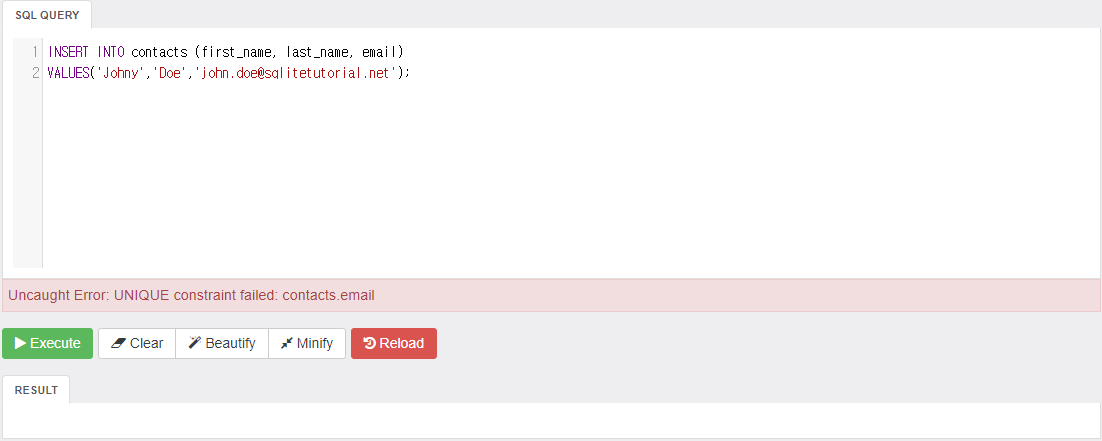
설정하지 않은 UNIQUE 제약으로 인한 에러가 발생한 것을 볼 수 있다.
sqlite에서는 인덱스 설정 시 unique한 값들로만 이루어진 컬럼에 대해 설정해야 한다.
인덱스는 여러 컬럼에 대해서도 설정할 수 있다.
CREATE INDEX idx_contacts_name
ON contacts (first_name, last_name);그렇다면 여러 컬럼을 인덱스로 설정했을 때, 일부 컬럼만 가지고 검색을 하게 되면 인덱스를 사용할까?
CREATE INDEX idx_contacts_name
ON contacts (first_name, last_name);아까와 같은 테이블에서 인덱스만 새로 추가했다.
first_name만 사용해서 쿼리한 결과는 다음과 같다.
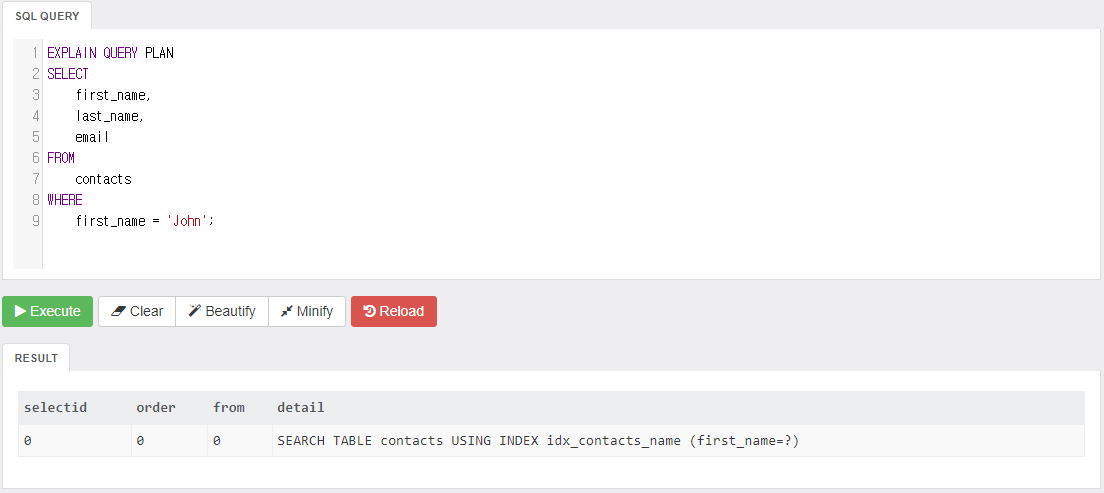
인덱스에서 first_name만 사용했다.
first_name, last_name 모두 사용해 쿼리한 결과는 다음과 같다.
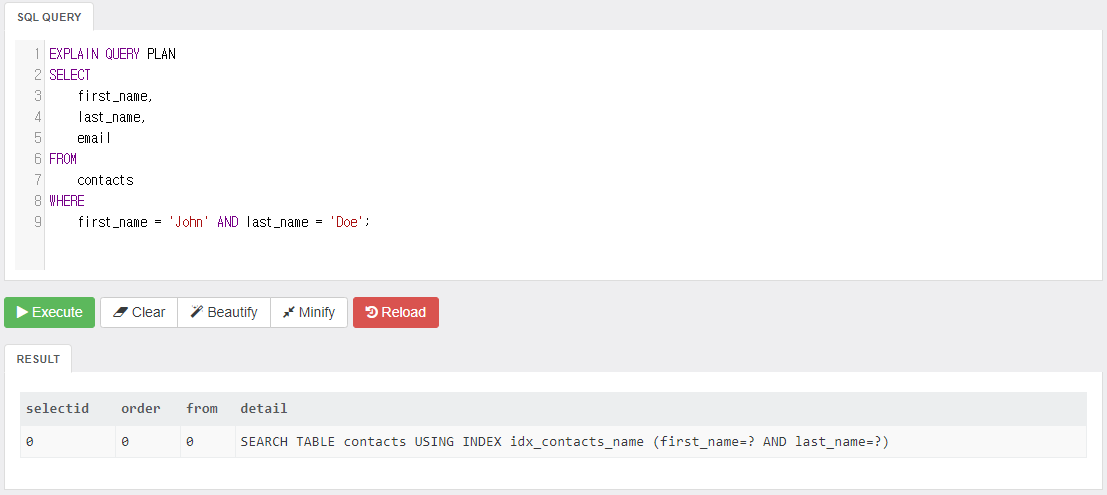
인덱스에서 first_name, last_name 모두 사용했다.
그런데 last_name만 가지고 쿼리하면 어떻게 될까?
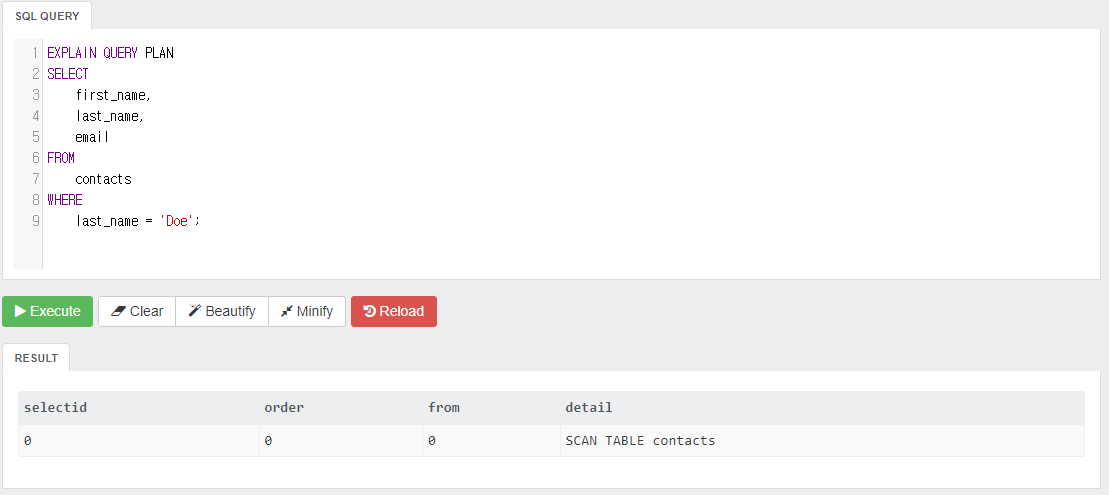
인덱스를 사용하지 않은 것을 볼 수 있다.
또한 first_name, last_name 모두 사용하되, 순서를 바꾸고 OR로 쿼리한 결과는 다음과 같다.
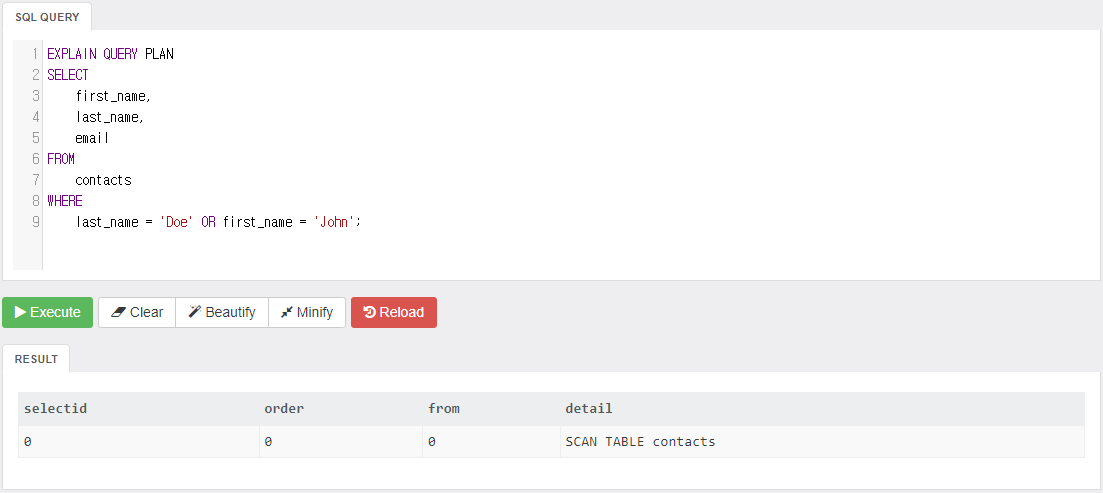
마찬가지로 인덱스를 사용하지 않았다.
sqlite의 경우 인덱스에는 순서가 있어서 그 순서대로 사용하지 않으면 안 된다.
다 사용할 필요는 없지만 중간부터 시작해서는 안 된다는 뜻이다.
또한 인덱스는 AND 조건으로 이어져 있기 때문에 OR 조건으로 쿼리할 때도 사용할 수 없다는 사실에 유의하자.
인덱스를 생성했는데, 내가 어떤 인덱스들을 생성했는지도 알고 싶을 것이다.
테이블명을 넣어 인덱스의 목록을 볼 수 있고,
PRAGMA index_list('table_name');인덱스 이름을 넣어 인덱스의 자세한 정보를 볼 수 있다.
PRAGMA index_info('idx_contacts_name');마지막으로 인덱스를 생성했다면 삭제해야 할 때도 있을 것이다.
DROP INDEX [IF EXISTS] index_name;