
본 포스트는 박재호님의 유튜브 강의(링크)를 보고 일부 발췌하여 정리한 내용입니다.
사용된 자료, 샘플 데이터 등은 모두 SQLite Tutorial에서 확인할 수 있습니다.
1. 윈도우 함수
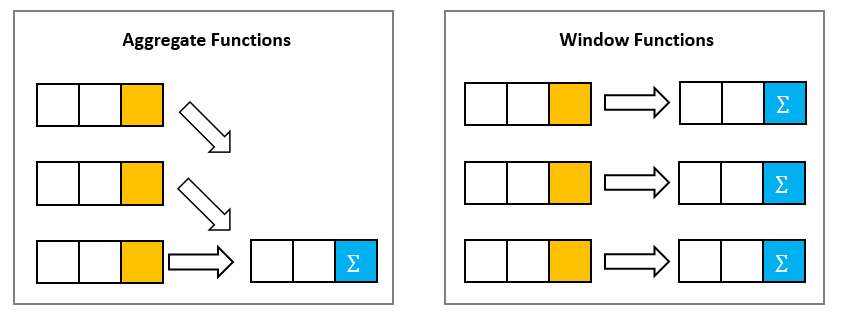
기존의 집계함수 (SUM, MIN, MAX 등)는 결과물이 반드시 한 행에만 나오게 된다.(사진 왼쪽)
하지만 행마다 계산한 값을 같이 보여주는 것이 필요한 경우(사진 오른쪽)도 있어, 이를 위해 윈도우 함수가 존재한다.
sqlite에서 제공하는 윈도우 함수는 아래와 같다.
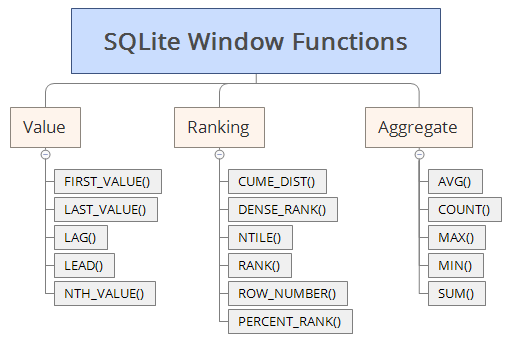
그럼 차례대로 각 함수에 대해 알아보기 전에, 실습과 관련하여 기존의 SQLite Tutorial에서는 윈도우함수를 사용할 수 없다.
대신 SQLite Online에서 실습을 진행할 것이다.
또한 몇몇 예제의 경우 SQLite Online에 데이터를 넣기가 어려워 SQLite Tutorial의 문서를 읽거나 직접 데이터를 넣어야 한다.
1-1. CUME_DIST
CUME_DIST함수는 윈도우/파티션의 값의 누적분포를 계산하는 함수이다.
여기서 윈도우/파티션은 컬럼의 여러 행을 하나로 묶은 것을 뜻한다.
누적분포는 정렬한 결과를 기준으로 보여주기 때문에, ORDER BY에 따라 결과도 달라진다는 점에 유의해야 한다.
CUME_DIST()
OVER (
[PARTITION BY partition_expression]
[ORDER BY order_list]
)그러면 실제로 어떻게 결과가 나오는지 확인하기 위해 테이블을 생성하고 데이터를 입력하자.
CREATE TABLE CumeDistDemo(
Id INTEGER PRIMARY KEY,
value INT
);
INSERT INTO CumeDistDemo(value)
VALUES(1000),(1200),(1200),(1400),(2000);데이터가 있는 것을 확인했으면 CUME_DIST 함수를 실행한다.
SELECT
Value,
CUME_DIST()
OVER (
ORDER BY value
) CumulativeDistribution
FROM
CumeDistDemo;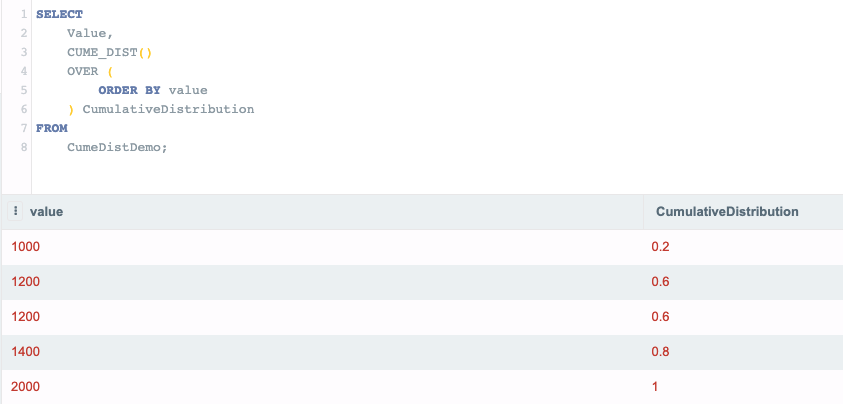
각 숫자의 비율이 나온 것을 알 수 있다.
1-2. DENSE_RANK
DENSE_RANK 함수는 순서 있는 집합에서 각 행의 순위를 구하는 함수이다.
순위는 1부터 시작하는 연속적인 정수인데, 행의 값이 같다면 같은 순위를 받게 된다. 또한 동점인 경우 순위 값들은 건너뛰지 않고 연속적으로 나타나게 된다.
함수의 구조는 다음과 같다.
DENSE_RANK() OVER (
PARTITION BY expression1, expression2,...
ORDER BY expression1 [ASC | DESC], expression2,..
)테이블 생성 및 데이터 입력
CREATE TABLE DenseRankDemo (
Val TEXT
);
INSERT INTO DenseRankDemo(Val)
VALUES('A'),('B'),('C'),('C'),('D'),('D'),('E');DENSE_RANK 함수 실행
SELECT
Val,
DENSE_RANK () OVER (
ORDER BY Val )
ValRank
FROM
DenseRankDemo;결과

위에서 설명한대로, 행의 값이 같다면 같은 순위를 받고, 동점인 경우 순위 값들은 건너뛰지 않고 연속적으로 나오는 것을 볼 수 있다.
1-3. FIRST_VALUE
FIRST_VALUE 함수는 말 그대로 윈도우 프레임에서 가장 첫번째 행을 가져오는 함수이다.
FIRST_VALUE(expression) OVER (
PARTITION BY expression1, expression2,...
ORDER BY expression1 [ASC | DESC], expression2,..
frame_clause
)형태가 위의 두 함수와는 약간 다른데, expression과 frame_clause가 기존과 다른점이다.
우선 이에 대해 설명하자면
-
expression
exporession은 윈도우 프레임의 첫번째 행인지 평가하는 표현식이다. 표현식은 하나의 값만을 리턴하며, 서브쿼리나 윈도우 함수를 사용할 수 없다. -
frame_clause
frame_clause는 현재 파티션의 프레임을 정의한다. 여기서 프레임은 파티션의 행의 범위라고 할 수 있다.
ORDER BY를 사용한 예제이다.
SELECT
Name,
printf('%,d',Bytes) Size,
FIRST_VALUE(Name) OVER (
ORDER BY Bytes
) AS SmallestTrack
FROM
tracks
WHERE
AlbumId = 1;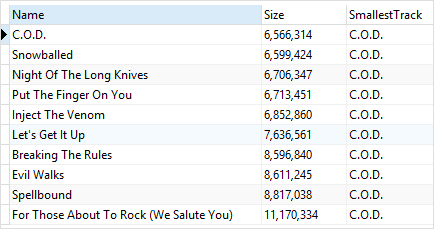
albumid=1인 데이터에 대해서만 수행했기 때문에 한 종류만 나온 것을 볼 수 있다.
다음은 PARTITION BY를 사용한 예제이다.
SELECT
AlbumId,
Name,
printf('%,d',Bytes) Size,
FIRST_VALUE(Name) OVER (
PARTITION BY AlbumId
ORDER BY Bytes DESC
) AS LargestTrack
FROM
tracks;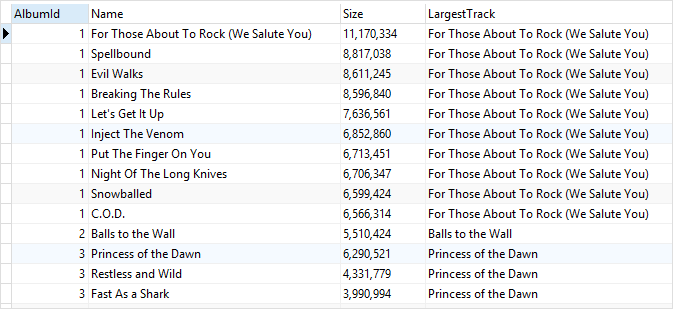
이번에는 모든 앨범에 대해서 수행했기 때문에 albumid마다 FIRST_VALUE가 나온 것을 볼 수 있다.
1-4. LAG
LAG 함수는 파티션의 현재 행에서 물리적으로 떨어진, 선행하는 행의 데이터를 가져오는 함수이다.
이걸 어디에 쓰나 싶지만 예제를 통해 어떻게 쓸 수 있는지 알아보자.
우선 함수의 형태는 다음과 같다.
LAG(expression [,offset[, default ]]) OVER (
PARTITION BY expression1, expression2,...
ORDER BY expression1 [ASC | DESC], expression2,...
)
-
expression
지정한 offset을 기반으로, offset만큼 선행하는 행의 값을 평가하는 표현식이다. 반드시 하나의 값만 리턴해야 한다. -
offset
현재 행에서 몇개 앞에 있는 행의 값을 가져올지 결정한다. 기본값은 1이다. -
default
만약 offset의 표현식이 NULL일 경우의 값을 정하는 부분이다. 만약 이를 생략하면, 표현식이 NULL일 경우 NULL을 리턴한다.
ORDER BY를 사용한 예제이다.
SELECT
CustomerId,
Year,
Total,
LAG ( Total, 1, 0 ) OVER (
ORDER BY Year
) PreviousYearTotal
FROM
CustomerInvoices
WHERE
CustomerId = 4;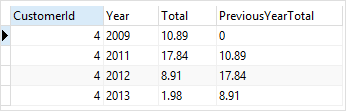
customerid=4인 데이터에 대해서만 설정했고, Total 컬럼의 현재 행보다 1행 앞에 있는 데이터를 가져오도록 했기 때문에 첫 행의 데이터는 0이 되는 것을 알 수 있다.
다음은 PARTITION BY를 사용한 예제이다.
SELECT
CustomerId,
Year,
Total,
LAG ( Total,1,0) OVER (
PARTITION BY CustomerId
ORDER BY Year ) PreviousYearTotal
FROM
CustomerInvoices;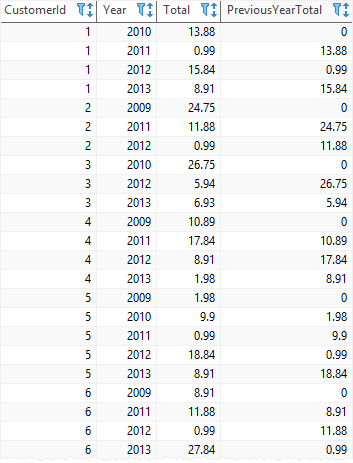
customerid로 파티션을 만들었기 때문에 모든 customerid에 대해 함수를 실행하게 된다.
각 파티션의 첫 행은 아까와 마찬가지로 0이 되는 것을 볼 수 있다.
1-5. LAST_VALUE
LAST_VALUE 함수는 말 그대로 윈도우 프레임에서 마지막 행을 가져오는 함수이다.
함수에 대한 설명은 FIRST_VALUE와 차이가 없어 바로 예제로 들어가겠다.
SELECT
Name,
printf ( '%.f minutes',
Milliseconds / 1000 / 60 )
AS Length,
LAST_VALUE ( Name ) OVER (
ORDER BY Milliseconds
RANGE BETWEEN UNBOUNDED PRECEDING AND
UNBOUNDED FOLLOWING
) AS LongestTrack
FROM
tracks
WHERE
AlbumId = 4;RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING은 현재 행을 기준으로 처음에서 끝까지의 데이터를 뜻한다.
이렇게 정한 범위 사이에서 가장 마지막 값(여기서는 Milliseconds 기준으로 오름차순이므로 가장 큰 값)의 트랙 이름을 가져오게 된다.
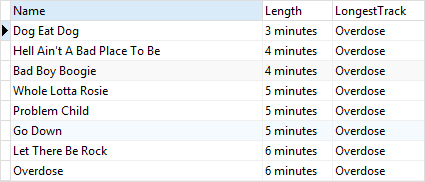
albumid=4인 것만 가져왔으므로 그 중에서 Milliseconds가 가장 큰 것의 트랙 이름만 나온 것을 볼 수 있다.
다음은 PARTITION BY를 사용한 예제이다.
SELECT
AlbumId,
Name,
printf ( '%.f minutes',
Milliseconds / 1000 / 60 )
AS Length,
LAST_VALUE ( Name ) OVER (
PARTITION BY AlbumId
ORDER BY Milliseconds DESC
RANGE BETWEEN UNBOUNDED PRECEDING AND
UNBOUNDED FOLLOWING
) AS ShortestTrack
FROM
tracks;이번에는 Milliseconds를 내림차순 정렬했으므로 마지막 값은 가장 Milliseconds가 가장 작은 값이 될 것이다.
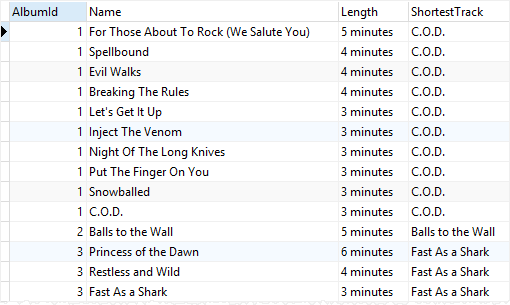
albumid로 파티션을 만들었기 때문에 모든 albumid에 대해 함수를 실행하게 된다.
파티션마다 Milliseconds가 가장 짧은 데이터의 이름이 나온 것을 볼 수 있다.
1-7. LEAD
LEAD함수는 위에서 본 LAG 함수와 반대로 후행하는 행의 값을 가져오는 함수이다.
함수의 형태는 LAG 함수와 동일하므로 생략하겠다.
예제로 들어가서, 우선 테이블의 뷰를 생성해야 한다.
먼저 ORDER BY를 사용한 예제이다.
CREATE VIEW CustomerInvoices
AS
SELECT
CustomerId,
strftime('%Y',InvoiceDate) Year,
SUM( total ) Total
FROM
invoices
GROUP BY CustomerId, strftime('%Y',InvoiceDate);그리고 이 뷰에 대해서 LEAD함수를 사용한다.
SELECT
CustomerId,
Year,
Total,
LEAD ( Total,1,0) OVER ( ORDER BY Year ) NextYearTotal
FROM
CustomerInvoices
WHERE
CustomerId = 1;
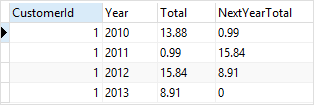
CustomerId=1인 데이터의 Total에 대해 후행하는 행의 값을 가져오도록 했기 때문에 마지막 데이터는 0이 된 것을 알 수 있다.
다음은 PARTITION BY를 사용한 예제이다.
SELECT
CustomerId,
Year,
Total,
LEAD ( Total, 1, 0 ) OVER (
PARTITION BY CustomerId
ORDER BY Year
) NextYearTotal
FROM
CustomerInvoices;
CustomerId로 파티션을 만들었기 때문에 모든 CustomerId에 대해 함수를 실행하게 된다.
각 파티션의 마지막 행은 아까와 마찬가지로 0이 되는 것을 볼 수 있다.
1-8. NTH_VALUE
NTH_VALUE 함수는 이름그대로 N번째 값을 가져오는 함수이다.
NTH_VALUE(expression, N)
OVER (
PARTITION BY expression1, expression2,...
ORDER BY expression1 [ASC | DESC], expression2,..
frame_clause
)형태도 지금까지의 함수들과 큰 차이가 없고 N만 차이가 있는데, 이도 몇 번째 값을 가져올지 정하는 부분이라 이해하기에 어려움이 없을 것이다.
ORDER BY를 사용한 예제이다.
SELECT
Name,
Milliseconds Length,
NTH_VALUE(name,2) OVER (
ORDER BY Milliseconds DESC
) SecondLongestTrack
FROM
tracks;딱 봐도 두 번째로 긴 트랙의 이름을 가져오라는 함수인 것을 알 수 있다.
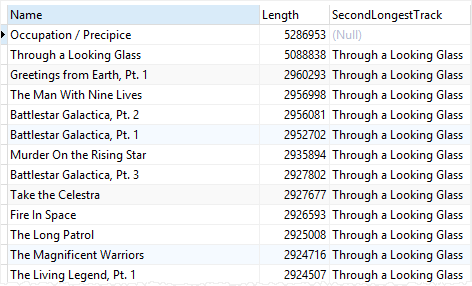
결과도 의도에 맞게 나왔다.
다음은 PARTITION BY를 사용한 예제이다.
SELECT
AlbumId,
Name,
Milliseconds Length,
NTH_VALUE ( Name,2 ) OVER (
PARTITION BY AlbumId
ORDER BY Milliseconds DESC
RANGE BETWEEN
UNBOUNDED PRECEDING AND
UNBOUNDED FOLLOWING
) AS SecondLongestTrack
FROM
tracks;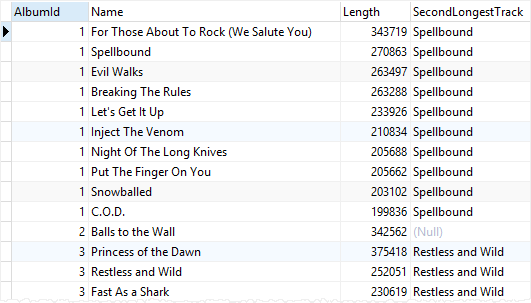
Milliseconds로 파티션을 만들었기 때문에 모든 Milliseconds에 대해 함수를 실행하게 된다.
1-9. NTILE
NTILE 함수는 결과셋을 설정한 갯수만큼의 버킷에 순서대로 나누어 넣는데, 최대한 균등하게 넣도록 하는 함수이다.
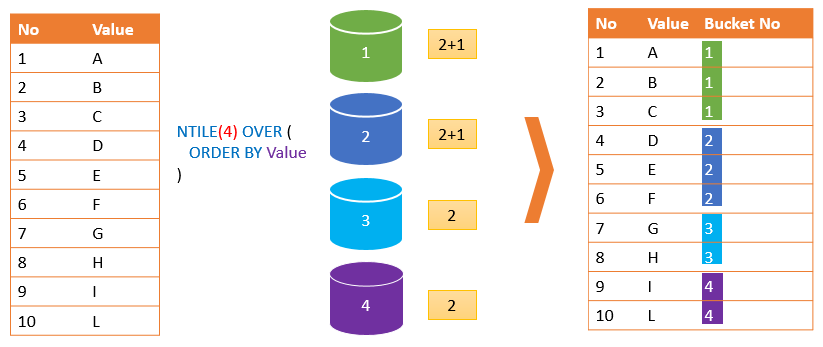
10개의 데이터를 4개의 버킷에 나누어 넣게 되면 우선 각각 2개의 데이터를 넣고, 나머지 2개를 1번, 2번 버킷에 나누어 넣는 방식이다.
NTILE(expression) OVER (
PARTITION BY expression1, expression2,...
ORDER BY expression1 [ASC | DESC]expression2,
)expression에는 버킷의 개수를 설정한다.
ORDER BY를 사용한 예제이다.
SELECT
Name,
Milliseconds,
NTILE ( 4 ) OVER (
ORDER BY Milliseconds ) LengthBucket
FROM
tracks
WHERE
AlbumId = 1;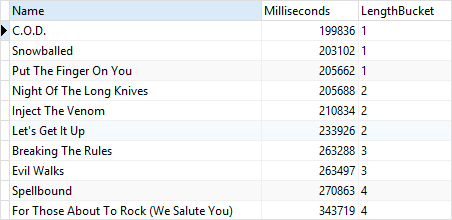
예상한대로 4개의 버킷에 데이터가 최대한 균등하게 들어간 것을 볼 수 있다.
다음은 PARTITION BY를 사용한 예제이다.
SELECT
AlbumId,
Name,
Milliseconds,
NTILE ( 3 ) OVER (
PARTITION BY AlbumId
ORDER BY Bytes ) SizeBucket
FROM
tracks;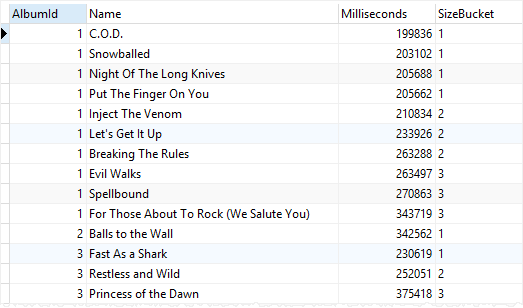
간과할 수 있지만 버킷에 들어간 데이터의 개수를 확인해 보면 뭔가 이상한 것을 눈치챘을 것이다.
NTILE 함수는 모든 데이터를 균등하게 넣는다기보다는 파티션별로 균등하게 넣는 것이기 때문이다.
따라서 파티션이 바뀌면 버킷 순서도 초기화되어 다시 1번 버킷부터 데이터를 넣기 시작한다.
1-10. PERCENT_RANK
PERCENT_RANK 함수는 각 행의 백분율의 순위를 구하는 함수이다.
PERCENT_RANK()
OVER (
[PARTITION BY partition_expression]
[ORDER BY order_list]
)함수의 인자는 필요 없지만 괄호()는 반드시 들어가야 한다.
ORDER BY를 사용한 예제이다.
SELECT
Name,
Milliseconds,
printf('%.2f',PERCENT_RANK() OVER(
ORDER BY Milliseconds
)) LengthPercentRank
FROM
tracks
WHERE
AlbumId = 1;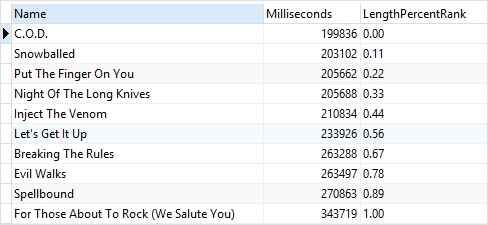
다음은 PARTITION BY를 사용한 예제이다.
SELECT
AlbumId,
Name,
Bytes,
printf('%.2f',PERCENT_RANK() OVER(
PARTITION BY AlbumId
ORDER BY Bytes
)) SizePercentRank
FROM
tracks;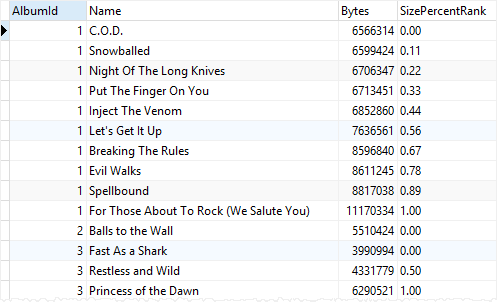
1-11. RANK
RANK 함수는 이름 그대로 각 행의 순위를 보여주는 함수이다.
특징으로는 여러 개의 행이 같은 순위인 경우, 다음 랭크는 이어진 숫자(+1)가 아니다.
1등인 행이 2개 있다면 다음 행은 3등이 되는 것이다.
위에서 다룬 DENSE_RANK 함수와는 정반대라는 것을 알 수 있다.
간단한 예를 통해 결과를 확인해 보자.
CREATE TABLE RankDemo (
Val TEXT
);
INSERT INTO RankDemo(Val)
VALUES('A'),('B'),('C'),('C'),('D'),('D'),('E');
SELECT
Val,
RANK () OVER (
ORDER BY Val
) ValRank
FROM
RankDemo;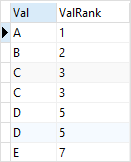
같은 랭크가 여러개 있다면 다음 순위는 뛰어넘는 것을 알 수 있다.
1-12. ROW_NUMBER
ROW_NUMBER 함수는 이름처럼 쿼리한 결과의 행에 번호를 매기는 것이다.
ROW_NUMBER() OVER (
[PARTITION BY expression1, expression2,...]
ORDER BY expression1 [ASC | DESC], expression2,...
)행 번호의 특징은 각 파티션이 연속적인 정수를 할당받기 때문에, 파티션이 바뀔 때마다 번호가 초기화되고 파티션 안에서는 번호가 중복되지 않는다는 점이다.
이걸 어디다 쓰나 싶지만 의외로 쓰이는 곳이 있는데, 바로 페이징(pagination)이다.
SELECT * FROM (
SELECT
ROW_NUMBER () OVER (
ORDER BY FirstName
) RowNum,
FirstName,
LastName,
Country
FROM
customers
) t
WHERE
RowNum > 20 AND RowNum <= 30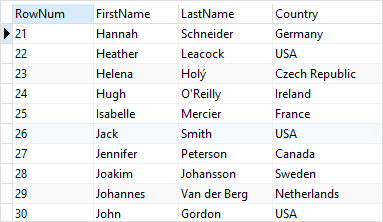
결과를 보면 행 번호가 21~30인 데이터만 추출한 것을 알 수 있다.
이를 이용해 표에서 페이지를 구현할 수도 있다.
또한 번호가 중복되지 않고 하나만 불러온다는 특성을 이용해, 같은 값이 존재하는 그룹에서 n번째로 큰 값을 하나만 쿼리할 수 있다.
예를 통해 살펴보자. 우선 뷰를 하나 생성한다.
CREATE VIEW Sales
AS
SELECT
CustomerId,
FirstName,
LastName,
Country,
SUM( total ) Amount
FROM
invoices
INNER JOIN customers USING (CustomerId)
GROUP BY
CustomerId;뷰의 데이터는 다음과 같다.
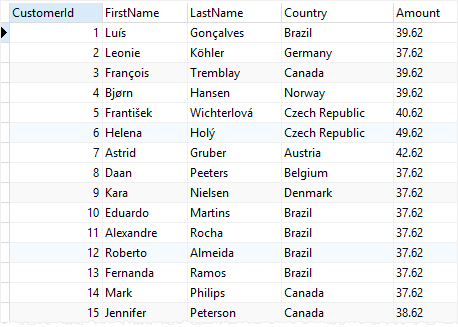
Amount는 같은 값이 여러개가 존재할 수도 있어보인다.
이 안에서 country로 파티션을 나눴을 때 행 번호가 N인 데이터만 가져오려면 다음과 같이 함수를 사용하면 된다.
SELECT
Country,
FirstName,
LastName,
Amount
FROM (
SELECT
Country,
FirstName,
LastName,
Amount,
ROW_NUMBER() OVER (
PARTITION BY country
ORDER BY Amount DESC
) RowNum
FROM
Sales )
WHERE
RowNum = 1;
각 파티션에서 Amount가 가장 큰 데이터만 불러온 모습이다.
