문제만 풀고 글을 안올렸네요...상상으로 글을 올렸나 분명 올렸다고 생각했는데 죄송합니다😭😭
2751 수 정렬하기2
import sys
n=int(input())
data=[int(sys.stdin.readline()) for _ in range(n)]
data.sort()
for i in data:
print(i)
# def quick_sort(data):
# if len(data)<=1:
# return data
# pivot=data[0]
# tail=data[1:]
#
# left_side=[x for x in tail if x<=pivot]
# right_side=[x for x in tail if x>pivot]
#
# return quick_sort(left_side)+[pivot]+quick_sort(right_side)
#
#
# print(quick_sort(data))
#
# # 삽입 정렬로 풀면
# for j in range (len(data)):
# min_index=j
# for k in range (j+1,len(data)):
# if data[min_index]>data[k]:
# min_index=k
# data[j],data[min_index]=data[min_index],data[j]
#
# print(data)
처음에 연습겸 선택정렬과 퀵정렬을 작성햇는데 시간초과가 나왔다.
그래서 그냥 sort와 sys 이용했다.
10989 수정렬하기3
import sys
n = int(sys.stdin.readline())
data = [0] * 10001
for i in range(n):
data[int(sys.stdin.readline())] += 1
for i in range(10001):
if data[i] == 0:
continue
for j in range(data[i]):
print(i)
이거는 메모리 초과가 나왔다
문제에 조건이 있었는데 10000보다 작거나 같은 수가 들어온다고 했다.
그렇기 때문에 메모리를 제한해서 구해줘야한단다...
사실 왜 저렇게 하는지는 아직 이해가 안간다!
중앙값
2108 통계학
from collections import Counter
n = int(input())
data = [int(input()) for _ in range(n)]
data.sort()
print(round(sum(data) / len(data)))
print(data[len(data) // 2])
count = Counter(data)
modes = count.most_common()
if len(data) > 1:
if modes[0][1] == modes[1][1]:
print(modes[1][0])
else:
print(modes[0][0])
else:
print(modes[0][0])
print(data[-1] - data[0])
또 시간초과 저주걸렸다...
너무 화나서 그냥 pypy 제출했더니 됐다
최빈값 구하는 부분은 Counter를 이용해 구했다.
디버그해보니
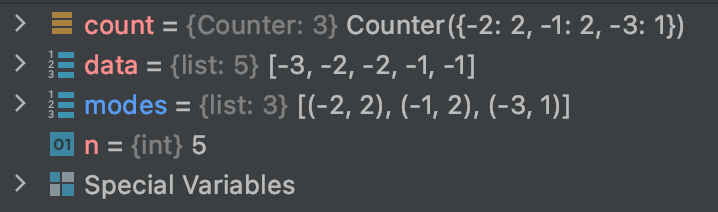
이런식으로 표시해준다.
편리한 라이브러리인것같다

3개의 댓글

2021년 7월 25일
안녕하세요 😊입니다~ 저도 이번주에 시간초과 메모리초과 계속 나와서 당황했습니다,, 디버그하는 방법은 처음 알아서 신기하네요,,! 하나 더 배워가네요~ 이번주 수고 많으셨어요~~
답글 달기

안녕하세요, 김덕우입니다! 저도 시간초과 저주 걸려서 pypy로 제출했어요,,,, 하핳 저도 메모리초과 나오고 난리나서 많이 공감이 갔습니다,, 이번주도 너무 수고하셨습니다!!