OSI 7계층
네트워크에서 통신이 일어나는 과정을 7단계로 나눈 것을 말한다.
7단계로 나눈 이유는?
통신이 일어나는 과정이 단계별로 파악할 수 있기 때문이다.
흐름 파악, 이해 도움, 장애가 생기면 계층을 확인해 해당 계층만 손보면 되는 장점
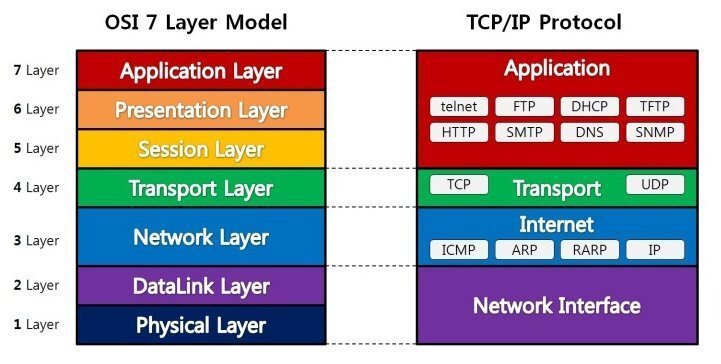
1계층 - 물리계층(Physical Layer)
- 주로 전기적, 기계적, 기능적인 특성을 이용해서 통신 케이블로 데이터를 전송하는 물리적인 장비
- 단지 데이터 전기적인 신호(0,1)로 변환해서 주고받는 기능만 할 뿐 데이터가 무엇인지, 어떤 에러가 있는지 신경쓰지 않음
- 이 계층에서 사용되는 통신 단위 : 비트(Bit)이며 이것은 1과 0으로 나타내어지는, 즉 전기적으로 On, Off 상태
- 장비 : 통신 케이블, 리피터, 허브 등
2계층 - 데이터 링크계층(DataLink Layer)
- 물리계층을 통해 송수신되는 정보의 오류와 흐름을 관리하여 안전한 통신의 흐름을 관리
- 프레임에 물리적 주소(MAC address)를 부여하고 에러검출, 재전송, 흐름제어를 수행
- 이 계층에서 전송되는 단위 : 프레임(Frame)
- 장비 : 브리지, 스위치, 이더넷 등(여기서 MAC주소를 사용)
-> 브릿지나 스위치를 통해 맥주소를 가지고 물리계층에서 받은 정보를 전달함.
3계층 - 네트워크 계층(Network Layer)
- 데이터를 목적지까지 가장 안전하고 빠르게 전달
- 라우터(Router)를 통해 경로를 선택하고 주소를 정하고(IP) 경로(Route)에 따라 패킷을 전달 > IP 헤더 붙음
- 이 계층에서 전송되는 단위 : 패킷(Packet)
- 장비 : 라우터
4계층 - 전송 계층(Transport Layer)
- port 번호, 전송방식(TCP/UDP) 결정 > TCP 헤더 붙음
- TCP : 신뢰성, 연결지향적 -> 보통 TCP 프로토콜 이용
- UDP : 비신뢰성, 비연결성, 실시간, 단순함
- 두 지점간(양끝단)의 신뢰성 있는 데이터를 주고 받게 해주는 역할
- 신호를 분산하고 다시 합치는 과정을 통해서 에러와 경로를 제어
- 연결 기반으로 패킷들의 전송이 유효한지 확인하고 전송 실패한 패킷은 다시 전송
5계층 - 세션 계층(Session Layer)
- 데이터가 통신하기 위한 논리적인 연결 (대문이랑 비슷)
- 주 지점간의 프로세스 및 통신하는 호스트 간의 연결 유지
- 동시 송수신 방식(duplex), 반이중 방식(half-duplex), 전이중 방식(Full Duplex)
- TCP/IP 세션 체결, 포트번호를 기반으로 통신 세션 구성
- API, Socket
6계층 - 표현 계층(Presentation Layer)
- 전송하는 데이터의 표현방식을 결정(ex. 데이터변환, 압축, 암호화 등)
- 파일인코딩, 명령어를 포장, 압축, 암호화 -> 결과를 포장하는 느낌
- JPEF, MPEG, GIF, ASCII 등
7계층 - 응용 계층(Application Layer)
- 최종 목적지로, 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행(ex. explore, chrome 등)
- HTTP, FTP, SMTP, POP3, IMAP, Telnet 등과 같은 프로토콜이 있다.
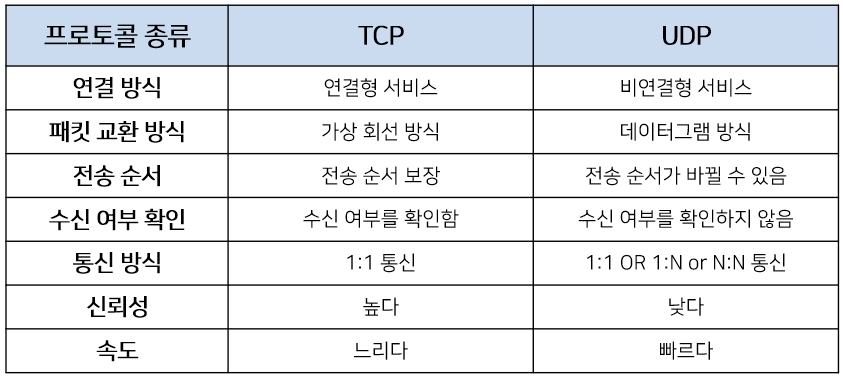
TCP와 UDP
트랜스포트 계층에서 가장 중요한건
신뢰성 : 데이터를 순차적, 안정적인 전달
전송 : 포트 번호에 해당하는 프로세스에 데이터를 전달
TCP (Transmission Control Protocol)
- 신뢰성 있는 데이터 통신을 가능하게 해주는 프로토콜
- 특징 : connection 연결 (3 way-handshake) - 양방향 통신
- 데이터의 순차 전송을 보장
- Flow Control (흐름 제어)
- Congestion Control(혼잡제어)
- Error Detection(오류 감지)
보통 Internet Protocol인 IP와 함께 쓰이고 흔히 TCP/IP라고 칭한다.
TCP는 데이터 조각(세그멘트)를 신뢰성 있게 전송하기 위한 프로토콜이고, IP는 데이터(패킷)을 빠르게 목적지까지 전송하기 위한 프로토콜이다.
TCP는 데이터를 나눠서 TCP HEADER를 추가한게 세그멘트
TCP 헤더는 포트 번호(위 전송에중요한 요소)에 해당하는 정보와 신뢰성을 위한 sequence number와 ACK SYN FIN과 같은 플래그 비트가 저장되어 있다.
UDP (User Datagram Protocol)
- 데이터를 데이터그램 단위로 처리하는 프로토콜
- UDP는 비연결형 프로토콜이다. 각 패킷은 독립적인 경로와 독립적으로 처리됨
- UDP헤더의 CheckSum 필드를 통해 최소한의 오류만 검출한다.
- 신뢰성이 낮다
- TCP보다 속도가 빠르다
- 연속성이 중요한 실시간 서비스(스트리밍)에 좋다.
데이터 전송과정 sender -> receiver가 패킷 송신 이 끝이다.
TCP vs UDP
TCP 3-way-handshake & 4-way-handshake
TCP의 3-way-handshake란 TCP 통신을 시작하기 전에 논리적인 경로 연결을 수립 (Connection Establish) 하는 과정이며, 4-way-handshake는 논리적인 경로 연결을 해제 (Connection Termination) 하는 과정이다. 이러한 방식을 Connect Oriented 방식이라 부르기도 한다.
TCP 3-way-handshake : Connection Establish
3-way-handshake 과정을 통해 양쪽 모두 데이터를 전송할 준비가 되었다는 것을 보장한다. 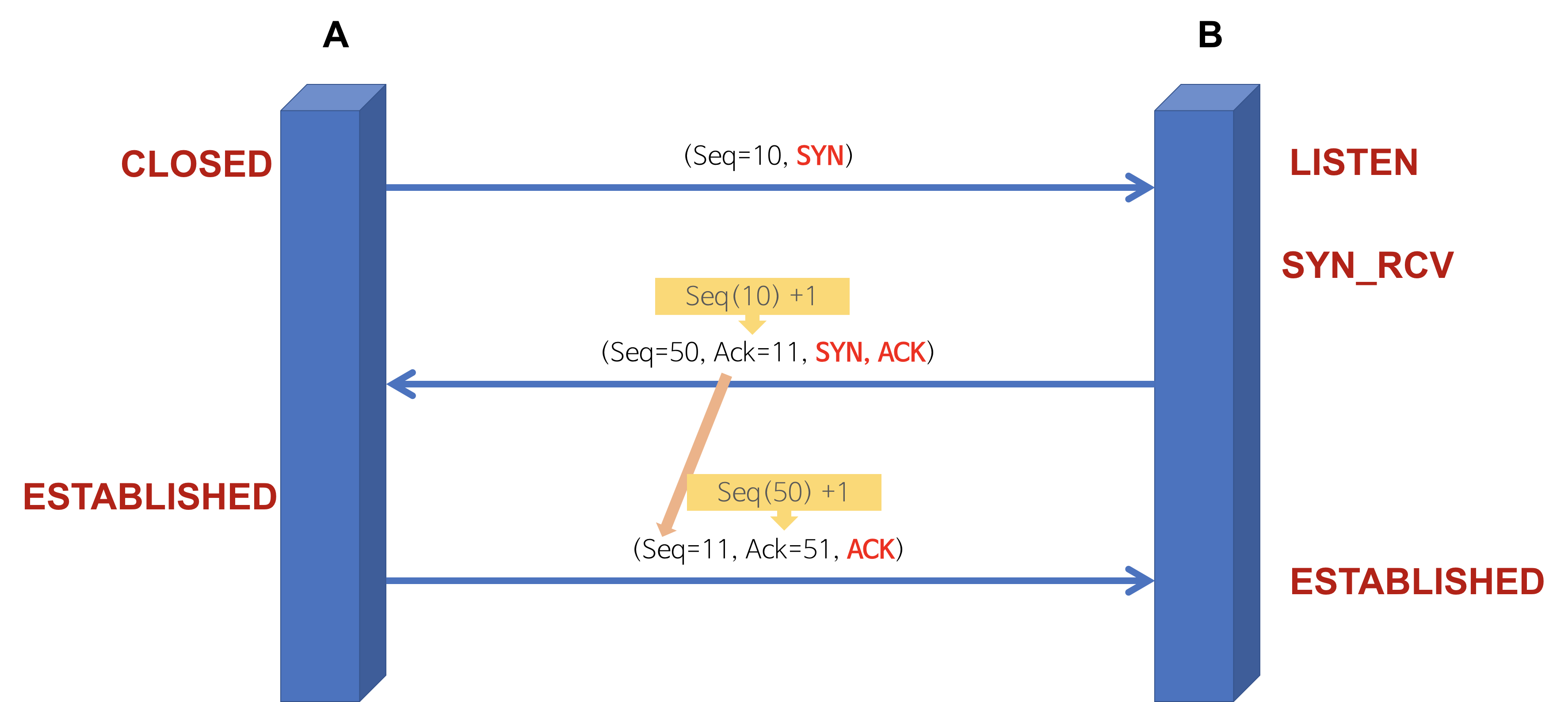
A 프로세스(Client)가 B 프로세스(Server)에 연결을 요청
- A(CLOSED) → B(LISTEN) : SYN(a)
- 프로세스 A가 연결 요청 메시지 전송 (SYN)
- 이 때 Sequence Number를 임의의 랜덤 숫자(a)로 지정하고, SYN 플래그 비트를 1로 설정한 segment를 전송한다.
- B(SYN_RCV) → A(CLOSED) : ACK(a+1), SYN(b)
- 연결 요청 메시지를 받은 프로세스 B는 요청을 수락(ACK)했으며, 요청한 A 프로세스도 포트를 열어달라(SYN)는 메시지 전송
- 받은 메시지에 대한 수락에 대해서는 Acknowledgement Number 필드를 (Sequence Number + 1)로 지정하여 표현한다. 그리고 SYN과 ACK 플래그 비트를 1로 설정한 segment를 전송한다.
- A(ESTABLISHED) → B(SYN_RCV) : ACK(b+1)
- 마지막으로 프로세스 A가 수락 확인을 보내 연결을 맺음 (ACK)
- 이 때, 전송할 데이터가 있으면 이 단계에서 데이터를 전송할 수 있다.
-> 최종 PORT 상태 : A-ESTABLISHED, B-ESTABLISHED (연결 수립)
TCP 4-way-handshake : Connection Termination
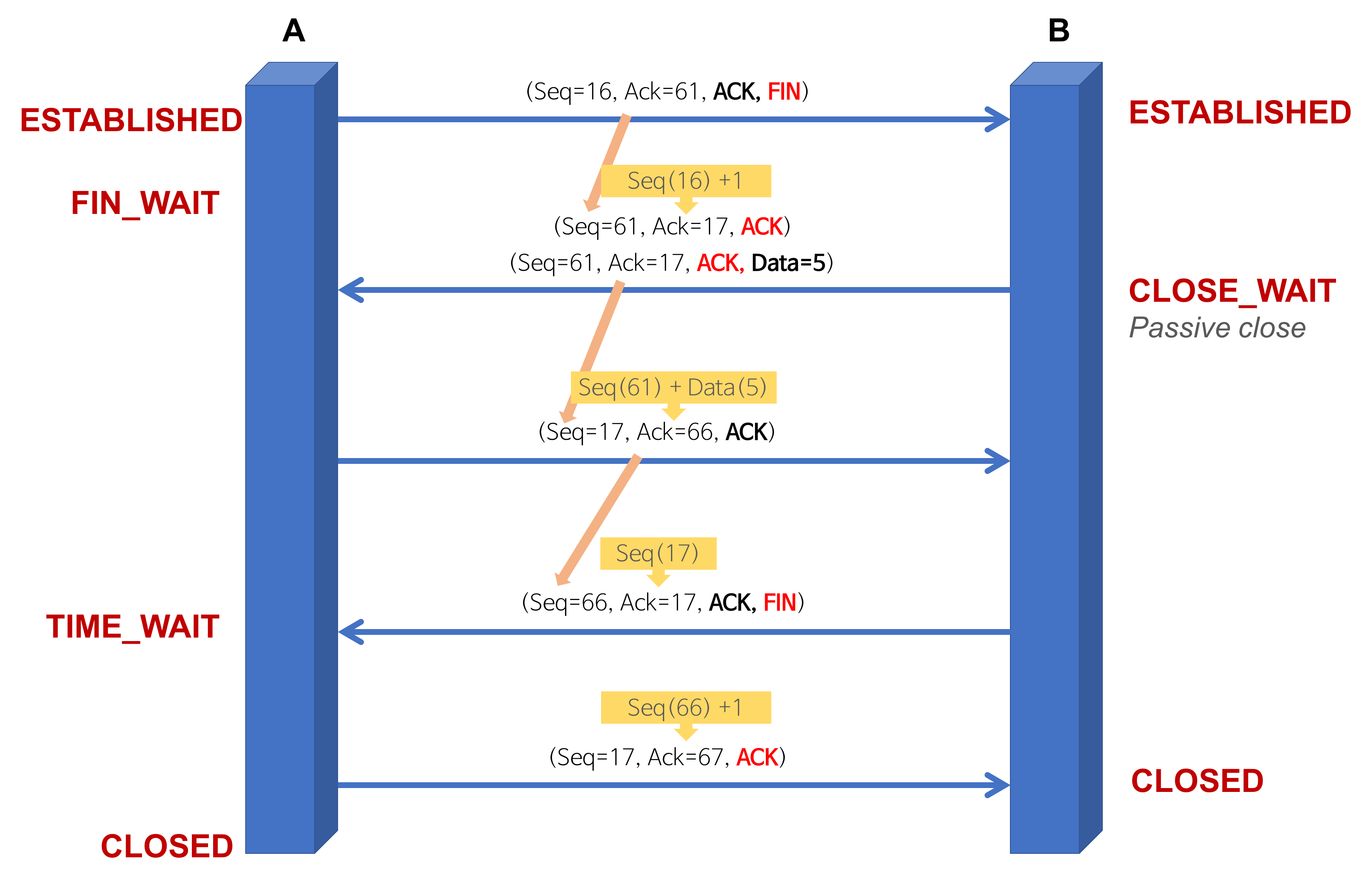
A 프로세스(Client)가 B 프로세스(Server)에 연결 해제를 요청
- A(ESTABLISHED) → B(ESTABLISHED) : FIN
- 프로세스 A가 연결을 종료하겠다는 FIN 플래그를 전송
- 프로세스 B가 FIN 플래그로 응답하기 전까지 연결을 계속 유지
- B(CLOSE_WAIT) → A(FIN_WAIT_1) : ACK
- 프로세스 B는 일단 확인 메시지(ACK)를 보내고 자신의 통신이 끝날 때까지 기다린다.
- Acknowledgement Number 필드를 (Sequence Number + 1)로 지정하고, ACK 플래그 비트를 1로 설정한 segment를 전송한다.
- 그리고 자신이 전송할 데이터가 남아있다면 이어서 계속 전송한다. (클라이언트 쪽에서도 아직 서버로부터 받지 못한 데이터가 있을 것을 대비해 일정 시간동안 세션을 남겨놓고 패킷을 기다린다. 이를 TIME_WAIT 상태라고 한다.)
- B(CLOSE_WAIT) → A(FIN_WAIT_2) : FIN
- 프로세스 B의 통신이 끝나면 이제 연결 종료해도 괜찮다는 의미로 프로세스 A에게 FIN 플래그를 전송한다.
- A(TIME_WAIT) → B(LAST_ACK) : ACK
- 프로세스 A는 FIN 메시지를 확인했다는 메시지를 전송 (ACK)
- 프로세스 A로부터 ACK 메시지를 받은 프로세스 B는 소켓 연결을 해제한다.
-> 최종 PORT 상태 : A-CLOSED, B-CLOSED (연결 해제)
HTTP VS HTTPS
HTTP
Hypertext Transfer Protocal
서로 다른 시스템들 사이에서 통신을 주고받게 하는 가장 기본적인 프로토콜이고 서버에서 브라우저로 데이터를 전송ㅎㅏ는 용도로 가장 많이 사용한다.
http는 전송되는 정보가 암호화되지 않는다는 문제점을 가지고 있다.
HTTPS
http의 문제를 해결하기 위해 SSL(보안 소켓 계층)을 사용하여 https가 나왔다.
SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결을 만들 수 있게 도와주고, 서버와 브라우저가 민감한 정보를 주고받을 때 해당 정보가 도난당하는 것을 막아준다.
HTTPS를 사용해야하는 이유!
1. 보안성 2. SEO-검색엔진(구글 등)에서 가산점을 준다.
SSL/TLS
SSL 업그레이드 버전이 TLS이다.
SSL은 Secure Sockets Layer로 웹서버와 웹 브라우저간의 보안을 위해 만든 프로토콜이다. 공개키/개인키, 대칭키 기반으로 사용한다.
대칭키는 암호화 복호화 키가 똑같아 암호하는 연산이 간단하고 빠르지만 대칭키가 털리면 암호를 쉽게 노출되는 단점을 가진다.
공개키는 암호화와 복호화 키가 달라 암호 연산이 느리지만 공개키를 뺏겨도 암호를 풀 수 없는 보안이 강하다는 장점을 가지고 있습니다.
각 공개키와 대칭키의 장단점이 상반되기 때문에 SSL은 두가지를 혼용해서 사용합니다.
SSL 통신 과정
A 시스템에서 B 시스템으로 접속 요청을 보내면 B는 ㅇA에게 자신의 공개키를 전달하고 A는 자신의 대칭키를 공개키로 암호화하고 B로 보낸다. B는 전달받은 암호문을 자신의 개인키를 이용해 복호화하여 A의 대칭키를 얻어낸다. 얻은 대칭키를 활용해 안전하게 통신한다.
사용자가 접속한 사이트가 유효안 사이트인지 확인하는 방법
-> 사이트 인증서를 이용한다. 인증기관에서 데이터를 검증하면 인증서를 발급하고 사이트의 공개키와 묶어 사이트 인증서가 발급된다. 사이트는 자신의 개인키를 이용하여 서명을 하여 사이트 인증서를 생성합니다. 사용자는 인증기관으로 부터 공개키를 전달받고 사이트에 접속 요청을 하면 사이트에서 사이트 인증서를 전달한다. 전달받은 사이트 인증서를 인증기관에서 받은 공개키를 활용하여 사이트 정보와 사이트 공개키를 얻는다. 공개키는 위에서 설명한 SSL 통신에 사용됩니다.
HTTP 1.1 VS HTTP 2.0
http 는 애플리케이션 계층에 해당하는 프로토콜로 클라이언트와 웹서버간의 통신을 위한 프로토콜 중 하나이다. http로 통신을 하려면 전송 계층을 거쳐야하는데 이론상으로는 신뢰성 있는 전송(뭐 거의 TCP이다...)이 가능하다면 어떤 프로토콜을 쓰던지 상관없다고 한다.
1.0버전부터 http 헤더가 생겨 다양한 type의 데이터 전송이 가능하였고 커넥션 하나당 하나의 응답이랑 하나의 요청만 처리할 수 있기 때문에 매번 새로운 연결로 성능이 저하되고 서버 부하비용이 높아졌다.
HTTP 1.1
이를 극복하기 위해 http1.1은 persistent concection을 도입한다.
persistent concection은 지정한 timeout 동안 커넥션을 닫지 않는 방식으로여러 요청이 커넥션을 사용할 수 있어 이전 단기 커넥션과 비교했을떄 네트워크 사용시간이 줄었다.
http는 순차적으로 응답을 받아야하는데 이전 http의 경우 1요청 1응답 2요청 2응답 이런식으로 응답을 기다리고 요청을 보낼 수 있었는데 1.1부터는 pipelining을 도입하여 하나의 커션에서 응답을 기다리지 않고 순차적인 여러 요청을 연속적으로 보내 그 순서에 맞춰 응답을 받는 방식으로 지연 시간을 줄였다.
단점
- pipelining에 의한 단점 Head of Line Blocking
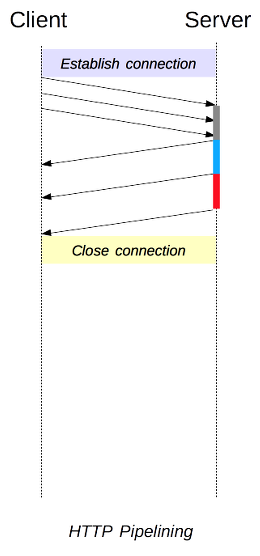
첫번째 요청을 처리하기 전까지 다른 요청을 처리 못한다는 문제가 있었다. - http 1.1 헤더의 구조의 중복으로 전송하려는 데이터보다 헤더의 값이 더 큰 경우도 발생함
- RTT(Round Trip time)
연결하려면 계속해서 3way handshaking
http 2.0
2015년 등장 기존 http 1.1 성능향상을 위해 확장된 프로토콜
기존 문제를 해결하기 위해 도입된 변화를 살펴보자.
- http 메시지 전송 방식의 변화
- 바이너리 프레이밍 계층을 사용하여 이전에는 text형식으로 헤더와 데이터를 보냈는데 헤더와 데이터 프레임을 나눠 바이너리으로 전송해 파싱과 전송 속도가 빨리지고 오류 발생 가능성을 줄였다.
-request and response multiplexing -> HOL해결
- 프레임으로 쪼개지니깐 순서없이 전송이 가능하다 인터리빙으로 끼어듦도 가능해지며 다중화 -> 순서대로 응답되어서 생기는 HOL문제 해결 - Stream Prioritization(요청 리소스간 의존관계를 설정)
먼저 전송해야 겠다는 스트림에 가중치를 주어 리소스간 우선 순위를 설정 가능 - Server Push(HTML문서상에 필요한 리소스를 클라이언트 요청없이 보내줄 수 있음)
page.html을 요청하면 script.js style.css파일 모두 같이 전송(어차피 같이 필요한 파일이니깐 또 요청오기 전에 한꺼번에 전송) - Header Compression
입축 알고리즘은 다이나믹 테이블로 중복 찾아 허프만 어쩌구,,,,헤더의 크기를 줄여 페이지 로드 시간 감소
단점은 TCP의 태생적인 한계인 Head of Line Blocking 있음
QUIC
구글에서 만든 전송 계층 프로토콜 UDP기반으로 만들었다. 왜 UDP로 만들었냐면 TCP는 신뢰성을 확보하기 위해 기능 구조가 많고 지연을 줄이기 힘들다. 하지만 UDP의 경우 별도의 기능이 없고 개발자가 원하는 기능을 추가해 지연을 줄이고 신뢰성을 확보할 수 있도록 QUIC을 구현하였다.
장점
전송 속도 향상 - 첫 연결이 성공하면 캐싱해서 핸드쉐이킹 없이 바로 연결이 가능 -> Connection UUID라는 고유한 식별자로 서버와 연결
보안 향상 -> TLS 기본 적용
독립 스트림 -> 향상된 멀티플렉싱 (어떤 스트림에 문제가 생겨도 다른 스트림 장애와 상관없이 전송 수행)
CORS
매번 프론트에서 cors가 터지면 백엔드에서는 안뜨는 오류라 무슨 오류인지 항상 궁금했는데 이제야 찾아보고 정리하게 되었따.
리소스 요청 정책으로 cors와 sop 두가지가 존재하는데
CORS는 Cross-Origin Resource Sharing의 줄임말로, 교차 출처 리소스 공유라고 직역되고 풀어말하면 다른 출처간의 리소스 공유이다. 추가 HTTP 헤더를 사용하여, 한 출처에서 실행 중인 웹 애플리케이션이 다른 출처의 선택한 자원에 접근할 수 있는 권한을 부여하도록 브라우저에 알려주는 체제이다. SOP는 반대로 같은 출처 리소스 공유 정책이다.
출처(Origin)는 서버의 위치를 찾아가기 위해 필요한 기본적인 것들로 url을 보면 여러개의 구성요소로 이루어져있는데 프로토콜부터 포트가 동일해야 같은 출처로 판단된다.
CORS의 동작 방식
기본적인 흐름은
요청 헤더에 Origin이라는 필드에 요청을 보내는 출처를 함께 담아서 보내고 서버가 이 요청을 응답할때 응답 헤더의 Access-Control-Allow-Origin이라는 값에 이 리소스를 접근하는 것이 허용된 출처를 보내고 브라우저는 다시 origin과 Access-Control-Allow-Origin를 비교해 유효한 응답인지 결정한다.
CORS의 세가지 시나리오
- 단순 요청
본 요청을 보내고 서버가 응답 헤더에 Access-Control-Allow-Origin 보내주면 브라우저가 CORS 정책 위반 여부를 검사하는 방식 - 프리플라이트 요청
예비 요청 preflight를 Options메서드를 통해 다른 도메인의 리소스에 요청이 가능한지 확인 작업을 한다. 굳이 예비 요청을 보내는 이유는 서버를 안전하게 지키기 위해서이다. 예비 요청으로 CORS가 터지면 본 요청을 보내지 않는다. - 인증정보 포함 요청
인증 헤더를 포함할 때 사용하는 요청이다
REST API
REST API는 REST를 기반으로 만들어진 API를 의미한다.
REST란?
REST(Representational State Transfer)의 약자로 자원을 이름으로 구분하여 해당 자원의 상태를 주고받는 모든 것을 의미합니다.
1. HTTP URI를 통해 자원을 명시하고
2. HTTP METHOD를 통해
3. 해당 자원에 대한 CRUD을 적용하는 것을 의미한다.
REST 구성 요소는
- 자원 HTTP URI 2. 자원에 대한 행위 HTTP METHOD 3. 자원에 대한 행위의 내용 HTTP Message pay Load
REST 특징
1) Uniform (유니폼 인터페이스)
Uniform Interface는 URI로 지정한 리소스에 대한 조작을 통일되고 한정적인 인터페이스로 수행하는 아키텍처 스타일을 말한다.
2) Stateless (무상태성)
REST는 무상태성 성격을 갖는다. 다시 말해 작업을 위한 상태정보를 따로 저장하고 관리하지 않습니다. 세션 정보나 쿠키정보를 별도로 저장하고 관리하지 않기 때문에 API 서버는 들어오는 요청만을 단순히 처리하면 된다. 때문에 서비스의 자유도가 높아지고 서버에서 불필요한 정보를 관리하지 않음으로써 구현이 단순해진다.
3) Cacheable (캐시 가능)
REST의 가장 큰 특징 중 하나는 HTTP라는 기존 웹표준을 그대로 사용하기 때문에, 웹에서 사용하는 기존 인프라를 그대로 활용이 가능하다. 따라서 HTTP가 가진 캐싱 기능이 적용 가능하다. HTTP 프로토콜 표준에서 사용하는 Last-Modified태그나 E-Tag를 이용하면 캐싱 구현이 가능하다.
4) Self-descriptiveness (자체 표현 구조)
REST의 또 다른 큰 특징 중 하나는 REST API 메시지만 보고도 이를 쉽게 이해 할 수 있는 자체 표현 구조로 되어 있다.
5) Client - Server 구조
REST 서버는 API 제공, 클라이언트는 사용자 인증이나 컨텍스트(세션, 로그인 정보)등을 직접 관리하는 구조로 각각의 역할이 확실히 구분되기 때문에 클라이언트와 서버에서 개발해야 할 내용이 명확해지고 서로간 의존성이 줄어들게 된다.
6) 계층형 구조
REST 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 계층을 추가해 구조상의 유연성을 둘 수 있고 PROXY, 게이트웨이 같은 네트워크 기반의 중간매체를 사용할 수 있게 한다.
Cookie Session && token
Session / Cookie 방식
기본적으로 세션 저장소가 필요하고 세션 저장소에는 로그인 시 사용자 정보를 저장하고, key로 사용할 수 있는 세션 ID를 만든다. 세션 ID는 클라이언트에게 보내 브라우저에서 세션 ID를 쿠키에 저장한다. 인증이 필요한 경우 쿠키를 끼워 서버에 요청을 보낸다.
쿠키에 민감한 정보를 담으면 해커가 뺏어 정보가 노출될수있기 때문에 서버에 데이터베이스를 두고 세션 id를 둬서 쿠키에서 세션 id가 오면 데이터베이스에서 사용자의 정보(로그인 정보나,,)를 보낸다. 쿠키에 민감한 정보를 안담는다면 보안과 관련없는 장바구니, 자동로그인 설정 같은 경우에 유용하다.
고유한 id값으로 서버 데이터베이스에서 값을 가져오기 때문에 HTTP가 노출되도 유의미한 값이 노출되는것은 아니다. 하지만 세션 하이재킹 공격이나 서버에 추가적인 저장공간이 필요하다는 단점이 있다.
TOKEN
JWT (JSON Web Token) 는 인증에 필요한 정보들을 암호화시킨 토큰을 의미한다. 위의 세션/쿠키 방식과 유사하게 사용자는 Access Token (JWT Token) 을 HTTP 헤더에 실어 서버에 전송한다. 토큰은 임의로 생성된 비밀번호 같이 동작한다. 제한된 수명을 가지고, 새로운 토큰은 한번 만료되면 새로 생성되어야한다.(Refresh Token)
토큰은 헤더(Header),페이로드(payload),서명(signature) 세 파트를 . 으로 구분하는 구조이다.
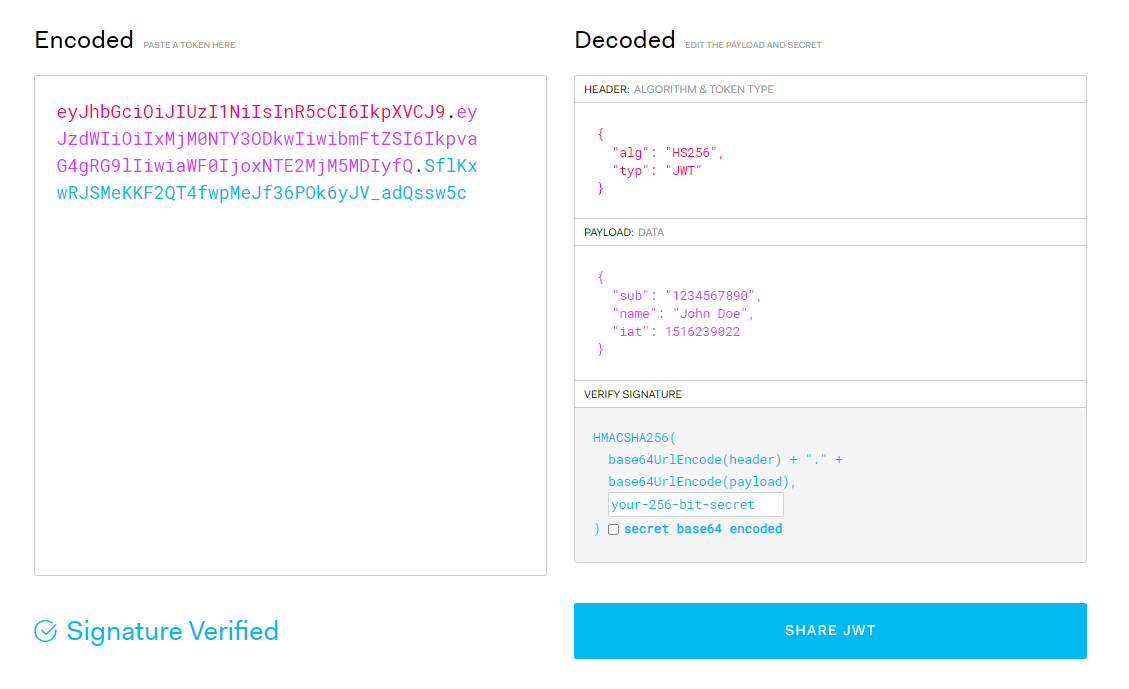
헤더는 jwt를 검증하는데 필요한 정보를 담고있다. 서명시 사용하는 알고리즘과 키를 식별하는 값을 담고있다.
payload는 jwt릐 내용으로 클라이언트와 서버간에 주고받는 데이터(사용자 정보)등을 담고있다
signature는 헤더와 페이로드를 합친 문자열을 서명한 값이다.
간편하고 확장성이 뛰어난(소셜로그인) 서버의 별도의 저장소가 필요없다는 장점을 가진다.
유효기간안으로는 토큰을 계속 사용이 가능하기 때문에 access토큰의 유효기간을 짧게하고 refresh token의 유효기간을 길게해 피해를 줄일 수 있다.
페이로드 정보가 제한적이다. 디코딩하여 정보가 노출될 수 있어 민감한 정보는 담지 못한다.
jwt길이가 길어질수록 네트워부하가 심해진다.
로드밸런서
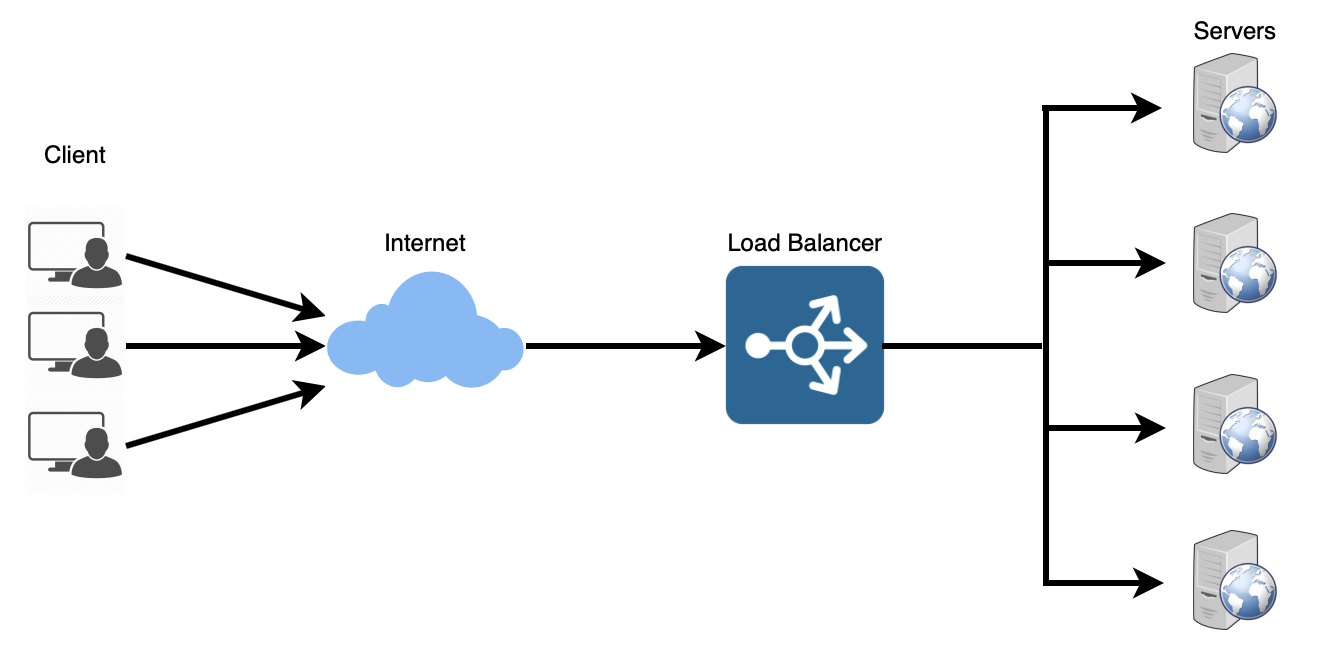
트래픽을 관리하기 위한 방법은 일반적으로 2가지가 있다.
- 하드웨어의 성능을 올리는 Scale-up
- 여러대의 서버가 나눠서 일하도록 만드는 Scale-out
여러대의 서버로 나눈다면 무중단 서비스를 제공하는 환경 구성에 용이하므로 scale-out이 효과적이다. 이때 여러 서버에게 균등하게 트래픽을 분산시켜주는 것이 바로 로드밸런싱이다.
로드 밸런싱은 분산식 웹 서버로, 여러 서버에 부하를 나누어주는 역할을 한다. 클라이언트와 서버 사이에 두고, 부하가 일어나지 않도록 요청을 여러 서버에 분산시켜준다. 요청이 많아지면 서버를 추가 증설함으로 로드 밸런서를 관리해주면 서버 부하 해결이 가능하다.
로드 밸런서가 서버를 선택하는 방식
라운드 로빈(Round Robin) : CPU 스케줄링의 라운드 로빈 방식 활용
Least Connections : 연결 개수가 가장 적은 서버 선택 (트래픽으로 인해 세션이 길어지는 경우 권장)
Source : 사용자 IP를 해싱하여 분배 (특정 사용자가 항상 같은 서버로 연결되는 것 보장)
로드 밸런서 장애 대비
서버를 분배하는 로드 밸런서에 문제가 생길 수 있기 때문에 로드 밸런서를 이중화(active와 passive)하여 대비한다.
DNS - round robin 방식
DNS
원래 서버는 고유의 IP주소를 갖는다. (473.123.421.321 와 같은 숫자 나열) 이 고유의 IP주소를 통해 서버에 접근할 수 있는데 IP를 통째로 외우기 힘드니깐 이를 도메인 네임으로 변환해주는 시스템이 DNS이다.
사람이 읽을 수 있는 도메인 이름(www.naver.com) -> 기계가 읽을 수 있는 ip 주소
또는
IP -> 도메인 반환
네이버로 예를 들면 네이버에 접근할래!! 하는 온갖 요청들을 DNS 서버가 처리를 해주는데 엄청난 트래픽 -> 서버 망가짐의 지름길
->따라서! 부하분산 필요
round robin
라운드 로빈은 공평하게 task에 일을 나눠주는 방식이다.
DNS를 이용하여 부하분산을 한다.
DNS 서버에서 하나의 도메인명에 여러 개의 IP 주소를 등록시켜두고 클라이언트로부터 요청이 있으면 등록되어있는 IP주소를 순서대로 반환하는 방식이다.
반환되는 IP 주소가 바뀌므로 클라이언트의 행선지도 바뀌어 결과적으로 커넥션이 분배된다.
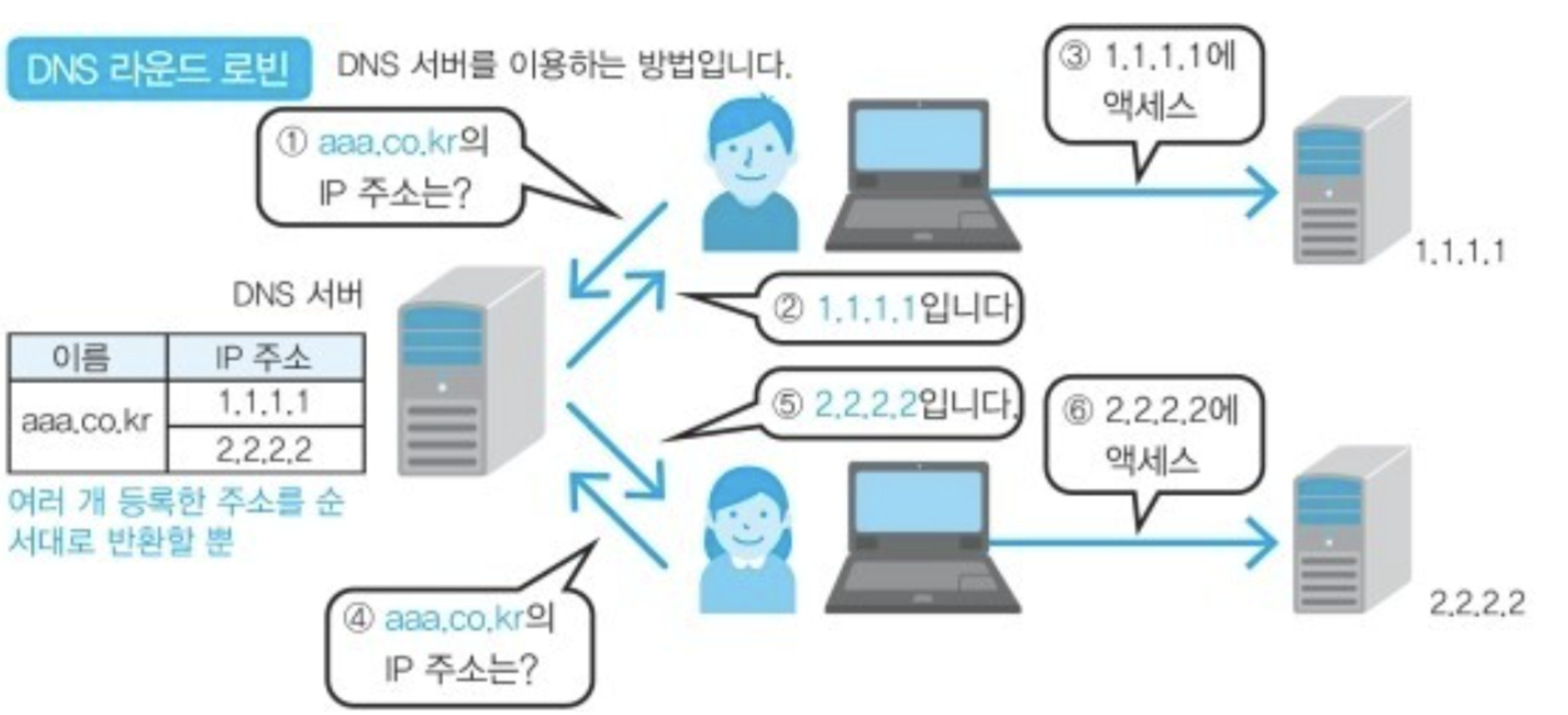
문제점
-
DNS에서 서버에 따라 여러개의 IP 주소 등록 -> 서버의 수 만큼 공인 IP 주소 필요하다.
-
균등하게 분산되지 않는다.
-
DNS 서버의 역할은 해당 요청을 확인한 후 IP 주소를 반환하는 일 -> 해당 IP 주소의 서버가 다운돼도 확인 불가
보완점
- Weighted round robin (WRR)
각 웹 서버에 가중치를 가미해서 분산 비율을 변경한다.
-> 성능 좋은 서버 가중치를 높게 잡아 빈번하게 선택 - Least connection
접속 클라이언트 수가 가장 적은 서버를 선택
-> 로드밸런스 장치(부하분산 트래픽 관리 서버)를 추가해 실시간으로 connection 수를 관리하거나 각 서버에서 주기적으로 알려주는 것 필요.
Blocking/Nonblocking&Synchronous/Asynchronous
https://velog.io/@jifrozen/java-Blocking-vs-Non-Blocking-Sync-vs-Async
웹 통신의 큰 흐름
- www.google.com 에 접속할 때 일어나는 일
1. www.google.com 을 브라우저 주소창에 친다
RFC 1738에 따라 유효한 URL인지 확인한다.
구글은 http 프로토콜을 사용하여 통신하기 때문에 http 프로토콜에 맞는 메시지를 만들어 줘야한다.
http 메시지를 작성하기 위해 구글의 ip 주소를 알아야한다. 사용자가 아는건 www.google.com이기 때문에 IP 주소는 DNS lookup 작업을 진행한다.
2. Domain의 IP 주소를 찾기 위해 DNS Lookup과정을 수행한다.
DNS lookup 과정에서 크롬 브라우저의 경우 브라우저 -> hosts 파일 -> DNS cache 순서로
1) 브라우저 캐시를 확인한다.
브라우저는 일정 기간동안 DNS 기록을 저장하고있다.
2) 브라우저는 OS 캐시를 확인한다.
브라우저 캐시에서 웹사이트 이름의 ip주소가 발견 안될 경우, 브라우저는 systemcall을 통해 OS가 저장하는 DNS 기록들의 캐시에 접근한다.
3) Router 캐시를 확인한다.
컴퓨터. DNS 기록을 찾지 못하면, 브라우저는 DNS 기록을 캐싱하는 라우더와 통신하여 찾는다.
4) ISP 캐시를 확인한다.
브라우저는 DNS 서버를 구축하고 있는 ISP에서 DNS기록을 찾는다.
많은 곳에서 캐시를 저장하는 이유!
캐시는 네트워크 트래픽을 조절하고, 데이터 전송 시간을 줄인다.
3. 요청한 URL 캐시가 없으면. ISP의 DNS 서버가 www.google.com을 호스팅하고 있는 서버의 IP 주소를 찾기 위해 DNS query를 날린다.
- DNS query
- 여러 다른 DNS서버들을 검색하여 특정 사이트의 IP주소를 찾는 것이다.
- IP 주소를 찾을 때 까지 DNS 서버에서 다른 DNS 서버를 오가면서 반복적으로 검색하던지, 찾지 못해서 에러가 발생할 때 까지 검색을 진행한다.
- ISP의 DNS서버
- DNS recursor라고 부른다
- 인터넷을 통해 다른 DNS 서버들에게 물어 도메인 이름의 올바른 IP 주소를 찾는 책임을 가진다
- 다른 DNS 서버 : name server라 부른다. 웹사이트 도메인 이름의 구조에 기반하여 검색을 하기 때문이다.
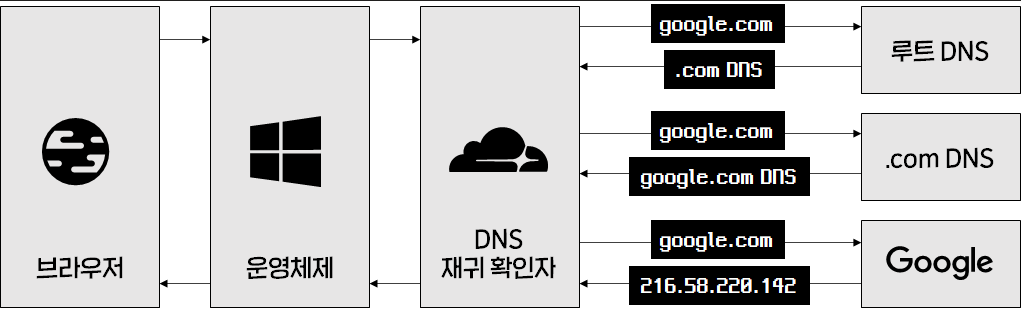
- DNS recursor가 root name server에 연락한다
- root name server는 `.com 도메인 name server로 redirect한다
- .com name server는 google.com name server로 redirect한다
- google.com name server 는 DNS 기록에서 www.google.com 에 매칭되는 IP주소를 찾고, DNS recursor로 보낸다
- 위 모든 요청들은 작은 데이터 패킷을 통해 보내진다.
- 패킷 = 보내는 요청의 내용 + DNS recursor 의 IP 주소 으로 이뤄짐
- 패킷들은 원하는 DNS 기록을 가진 DNS 서버에 도달할 떄까지 클라이언트와 서버를 여러 번 오간다
- 이때 패킷들은 routing table에 기반하여 가장 빠른 경로로 움직인다.
- 도중에 패킷이 loss되면 request fail error가 발생한다
4. 브라우저가 서버와 TCP 연결한다.
📌TCP/IP 3-way handshake
사용자(Client)가 구글(Server)에 연결을 요청
1. A(CLOSED) → B(LISTEN) : SYN(a)
프로세스 A가 연결 요청 메시지 전송 (SYN)
이 때 Sequence Number를 임의의 랜덤 숫자(a)로 지정하고, SYN 플래그 비트를 1로 설정한 segment를 전송한다.
2. B(SYN_RCV) → A(CLOSED) : ACK(a+1), SYN(b)
연결 요청 메시지를 받은 프로세스 B는 요청을 수락(ACK)했으며, 요청한 A 프로세스도 포트를 열어달라(SYN)는 메시지 전송
받은 메시지에 대한 수락에 대해서는 Acknowledgement Number 필드를 (Sequence Number + 1)로 지정하여 표현한다. 그리고 SYN과 ACK 플래그 비트를 1로 설정한 segment를 전송한다.
3. A(ESTABLISHED) → B(SYN_RCV) : ACK(b+1)
마지막으로 프로세스 A가 수락 확인을 보내 연결을 맺음 (ACK)
이 때, 전송할 데이터가 있으면 이 단계에서 데이터를 전송할 수 있다.
-> 최종 PORT 상태 : A-ESTABLISHED, B-ESTABLISHED (연결 수립)
5. 브라우저가 웹 서버에 HTTP 요청을 한다.
Request
클라이언트의 브라우저는 GET 방식으로 www.google.com 웹페이지를 요청한다.
요청 시 다른 부가적인 정보들도 함께 전달된다.
6. 서버가 요청을 처리하고 Response 생성
서버의 웹서버가 브라우저로부터 request를 받고 request handler에게 전달하여 request를 읽고 response를 생성한다.
7. 서버가 http response를 보낸다.
8. 브라우저가 Html content를 보여준다.
브라우저는 단계적으로 HTML content를 보여준다
- HTML skeleton을 rendering한다
- HTML tag들을 체크하고, GET 방식으로 추가적 웹페이지 정적인 요소들 (이미지, css stylesheet, javascript ..)을 요청한다.
- 이 정적인 파일들은 브라우저에 의해 캐싱되어 나중에 해당 페이지 방문시 서버로부터 다시 불러오지 않도록 한다.
- 결과적으로 www.google.com 의 모습이 보인다
IPv4 VS IPv6
https://velog.io/@jung5318/쿠키-세션-토큰의-차이점
https://tofusand-dev.tistory.com/89
https://khj93.tistory.com/entry/네트워크-REST-API란-REST-RESTful이란
https://meetup.toast.com/posts/92
https://www.youtube.com/watch?v=-2TgkKYmJt4&t=34s
https://evan-moon.github.io/2020/05/21/about-cors/
https://nukw0n-dev.tistory.com/10
https://velog.io/@averycode/네트워크-TCPUDP와-3-Way-Handshake4-Way-Handshake
https://github.com/Seogeurim/CS-study/tree/main/contents/network
https://www.youtube.com/watch?v=1pfTxp25MA8
https://lxxyeon.tistory.com/155
https://shlee0882.tistory.com/110
https://www.youtube.com/watch?v=wPdH7lJ8jf0
https://velog.io/@dbstjrwnekd/DNS-Round-Robin
https://velog.io/@guswns3371/네트워크-httpswww.google.com-을-접속할-때-일어나는-일#2-브라우저는-캐싱된-dns-기록을-통해-wwwgooglecom-에-대응되는-ip주소가-있는지-확인한다
https://velog.io/@dbstjrwnekd/웹-통신의-큰-흐름-1

{kind=link}