Seq2Seq Learning
Sequence to Sequence(Seq2Seq)
이름 그대로 sequential data를 Input으로 받은 후 일련의 처리과정을 거쳐 sequential output으로 반환하는 방법이다.
특징:
1. 입력과 출력의 sequence 수는 같지 않아도 된다.
2. Encoder과 Decoder로 이루어져 있다.
- Encoder: 입력된 정보를 어떻게 처리해서 저장 할 것인지?
- Decoder: 입력 Encoder로부터 압축된 정보를 어떻게 풀어 낼 것인지?
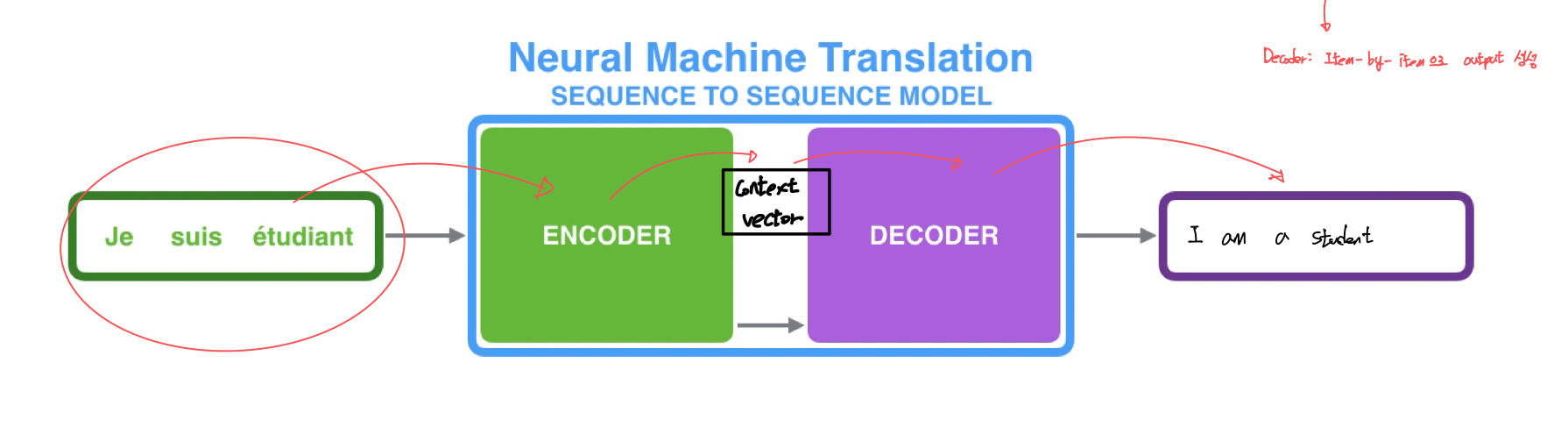
Encoder가 input sequence를 context vector로 compile 한다.
(Context vector: 모든 input sequence에 대한 정보를 받아드려 처리, Encoder는 context vector를 decoder에 넘긴 후 Decoder는 output 생성한다)
이제 RNN에서의 작동 방식을 확인해보자.
Context Vector는 그 자체가 vector로 표현된다.
이때 RNN에서 각각의 입력이 들어갈 때 마다 hidden state가 없데이트 되고 가장 마지막의 hidden state가 context vector가 된다.
하지만 RNN, LSTM, GRU는 Long Term Dependency를 완벽하게 해결하기 힘들다.
Context vector 자체가 아주 긴 long sequence를 처리하는데 어려움이 있다.
Attention
Attention은 model이 각각의 input sequence 중 현재 output item이 주목해햐하는 부분에 바로 연결(가중치)시켜 해당 부분을 더 잘 활용하도록 한다.
Attention 구조
1. Bahdanau: Attention score 자체를 학습하는 NN 모델
2. Luong: 현재의 current state, 과거의 hidden state들에 대한 유사도 측정 후 attention score 만든다.
1,2번 모두 비슷한 성능이 나타난다 >> 모델 학습이 필요 없는 Luong 실용적으로 사용한다.
Attention이 Seq2Seq과 다른점
-
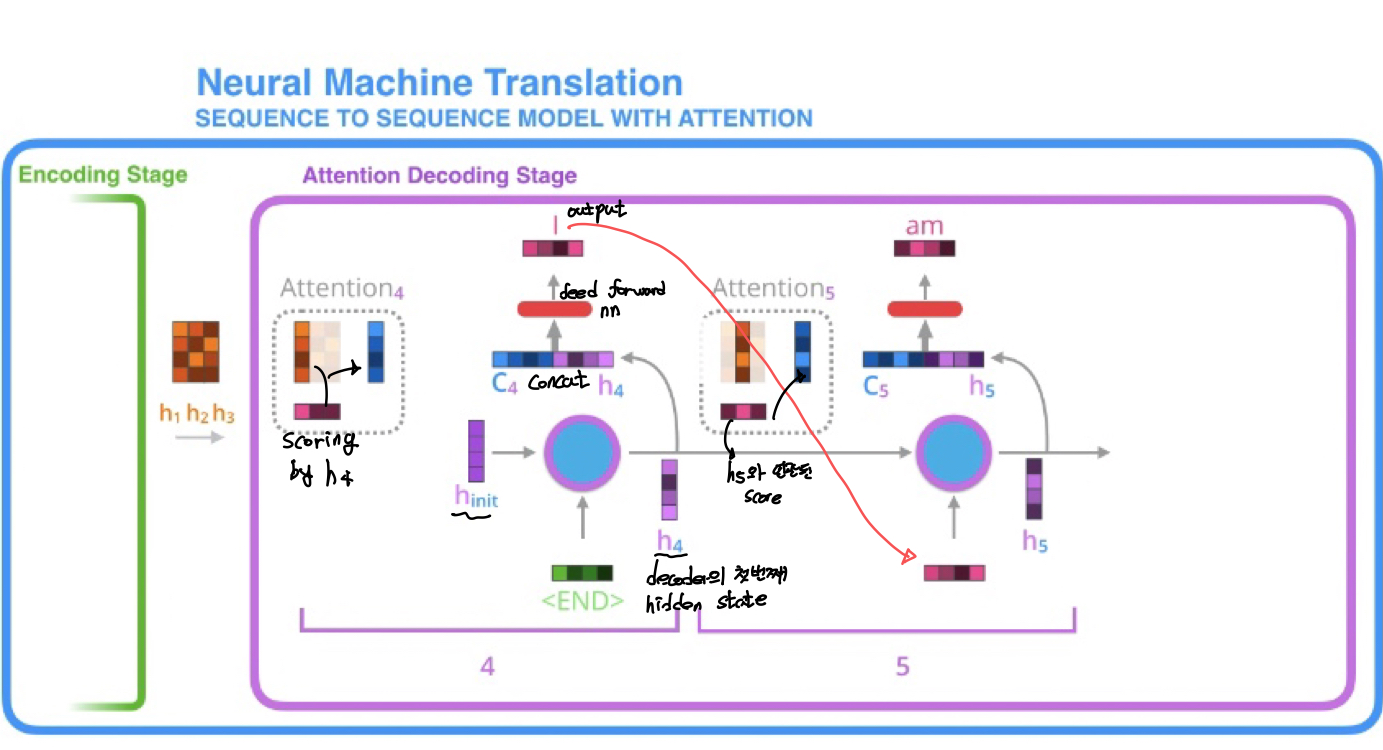
Encoder가 final hidden state 뿐 아니라 전체 hidden state를 전부를 Decoder로 전달해 Decoder에 많은 정보가 전달된다. Output 추출 시 모든 hidden state를 고려하게 된다.
-
Attention Decoder은 Encoder가 전달해주는 여러개의 hidden state를 가지고 extra step, 즉 output 생성 전 추가적인 작업을 지시한다.
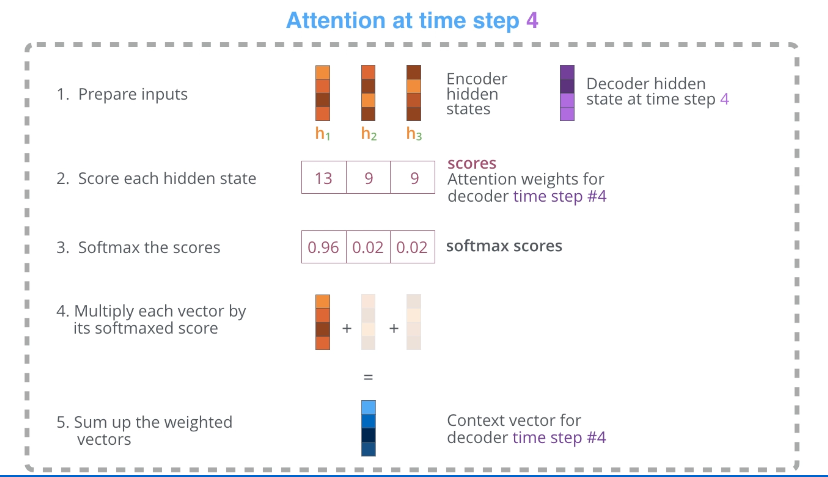
- Encoder가 보내준 hidden state를 전부 확인한다.(기본적 가정: 각 hidden state는 해당 연결된 단어의 sequence에 영향을 가장 많이 받는다.예를 들어 hidden state #3은 3번째 입력단어의 단어에 대한 정보를 가장 많이 가지고 있다.)
- 각 hidden state에 점수 부여 (점수는 Encoder hidden state와 해당 Decoder의 hidden state의 내적이라 생각해도 무방하다)
- 점수마다 softmax 적용 후 해당값을 전부 결합한다. 이 값이 Context vector이다. Score 값이 클수록 현재 Decoding 관점에서 중요한 정보이다.
- Context vector와 hidden state concat 후 fnn 통과하면 output 도출
- 반복