Transformer 논문인 'Attention Is All You Need'에 대한 리뷰입니다.
1~2. Introudction & Background
Transformer 이전의 문제점
Long-Term Dependency Problem
- Sequence data를 처리하기 위해 기존에는 recurrent model이 가장 많이 쓰였다. t번째 output을 위해 t번째 input과 t-1번째 hidden state를 이용하는 것이다. recurrent model은 순차적인 특성을 유지시킬 수 있으나, 문장의 길이가 길어질 경우 거리가 먼 단어끼리는 영향력이 감소한다는 단점이 있다.
Parallelization
- recurrent model은 학습 시 이전 결과를 순차적으로 입력 받는다. t번째 hidden state를 얻기 위해 t-1번째 hidden state가 필요했기 때문에 병렬처리가 불가능 하여 속도가 느렸다.
- 이를 해결하기 위해 transformer에서는
해결방안
- encoder에서 position에 대해 attention을 하고, decoder에서 maksing 기법을 이용해 병렬 처리를 해주었다.
3. Model Architectrue
- 논문 속 Transformer의 모델 구조
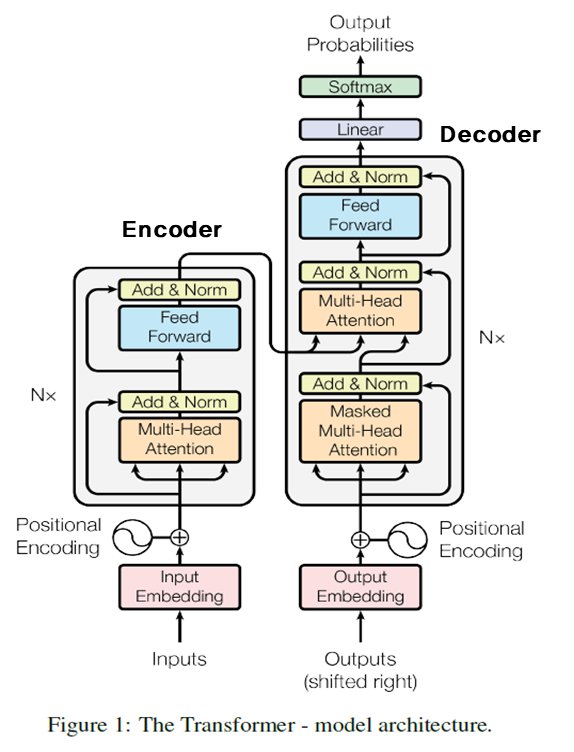
3.1 Encoder and Decoder Stacks
Encoder
-
6개의 동일한 layer의 stack으로 구성.
-
하나의 Layer에는
(1) multi-head self-attention layer
(2) position-wise fully connected feed-forward layer
두 개의 sub-layer로 구성되며, 각각의 sub-layer는 normalization을 거쳐 residual connection이 된다. -
residual connection하기 위해 모든 sublayer의 출력은 embedding layer 의 크기와 같은 512차원으로 생성된다.
-
코드로 이해하기
# 하나의 Layer를 코드로 이해해보자.
Stage1_out = Embedding512 + TokenPositionEncoding512 #w2v결과 + pos정보
Stage2_out = layer_normalization(multihead_attention(Stage1_out) + Stage1_out)
Stage3_out = layer_normalization(FFN(Stage2_out) + Stage2_out)
out_enc = Stage3_out
Decoder
-
Encoder와 마찬가지로 6개의 동일한 layer의 stack으로 구성.
-
하나의 Layer에는
(1) Masked multi-head self-attention layer
(2) multi-head self-attention layer (with encoder output)
(3) position-wise fully connected feed-forward layer
세 개의 sub-layer로 구성되며, 각각의 sub-layer는 normalization을 거쳐 residual connection이 된다. -
residual connection하기 위해 모든 sublayer의 출력은 embedding layer 의 크기와 같은 512차원으로 생성된다.
-
코드로 이해하기
# 하나의 Layer를 코드로 이해해보자.
Stage1_out = OutputEmbedding512 + TokenPositionEncoding512
# i보다 작은 위치의 시퀀스 요소에 대해서만 어텐션 메커니즘이 동작할 수 있도록 마스킹한 어텐션
Stage2_Mask = masked_multihead_attention(Stage1_out)
Stage2_Norm1 = layer_normalization(Stage2_Mask) + Stage1_out
Stage2_Multi = multihead_attention(Stage2_Norm1 + out_enc) + Stage2_Norm1
Stage2_Norm2 = layer_normalization(Stage2_Multi) + Stage2_Multi
Stage3_FNN = FNN(Stage2_Norm2)
Stage3_Norm = layer_normalization(Stage3_FNN) + Stage2_Norm2
out_dec = Stage3_Norm3.2 Attention
- Attention은 Query vector, Key vector, Value vecotr 쌍을 output으로 maaping하는 과정이다.
- Transformer에서 사용된 Attention에 대해 알아보자.
Scaled Dot-Product Attention
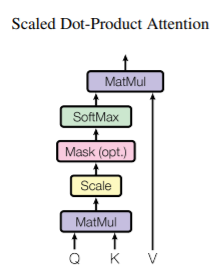
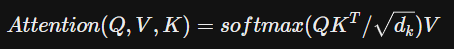
-
입력: dk 차원의 query, key, value. (이하, Q, K, V)
1. encoder-decoder attention일 때, Q: Decoder의 이전 layer hidden state k: Encoder의 output state V: Encoder의 output state 2. self-attention일 때, Q=K=V= Encoder의 output state
-
dot_product(Q,K) 이후, 로 나눈다.
(로 나누는 이유는 dot 값이 너무 크면 softmax의 기울기 값이 작아지기 때문에 scale하는 것.) -
그 값을 softmax를 적용하며, 이것이 V의 weight가 되는 것이다.
-
즉, Q, K에 맞게 V에 attention을 주는 방식이다.
Multi-Head Attention
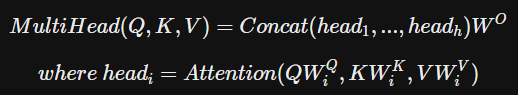
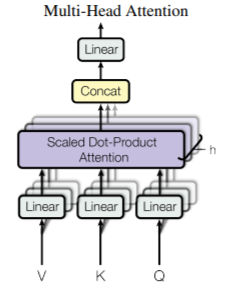
-
Sclaed dot-product attention을 복수(h)번 수행.
-
각각의 head 즉 K, V, Q를 h개로 나눈 값들의 attention을 수행하고 concat.
-
벡터의 크기를 줄이고 병렬 처리가 가능.
3.3 Position-wise Feed-Forward Networks
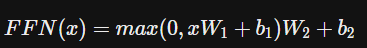
-
encoder와 decoder의 각각의 layer는 마지막 단계에서 fully connected feed-forward network를 포함한다.
-
position 마다, 즉 개별 단어마다 적용되기 때문에 position-wise이다.
-
x에 linear transformation을 적용하고 -> ReLU를 거쳐 -> 다시 한 번 linear transformation을 적용한다.
3.4 Embedding and softmax
- input token과 output token을 변환하는 과정에서 learned embedding을 사용한다. decoder의 output이 FNN을 거친 후 softmax를 통해 각 token의 확률값으로 표현된다.
3.5 Positional Encoding
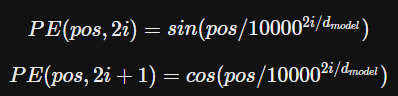
-
RNN이나 CNN파트를 사용하지 않기 때문에 순서 즉, 시퀀스의 위치 정보를 알려줘야 한다.
-
encoder 및 decoder의 input embedding에 positional encoding을 더한다.
4. Why Self-Attention
- layer당 계산량이 줄어든다.
- 병렬처리가 가능한 계산이 늘어난다.
- 문장의 길이가 길어져도 학습이 잘 된다.
출처
- https://velog.io/@veonico/%EB%85%BC%EB%AC%B8-%EC%9A%94%EC%95%BD-Attention-is-All-You-Need
- https://hipgyung.tistory.com/entry/ATTENTION-IS-ALL-YOU-NEED-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
- https://pozalabs.github.io/transformer/
- https://dalpo0814.tistory.com/49
- https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)
- https://3.bp.blogspot.com/-aZ3zvPiCoXM/WaiKQO7KRnI/AAAAAAAAB_8/7a1CYjp40nUg4lKpW7covGZJQAySxlg8QCLcBGAs/s1600/transform20fps.gif