JPA에서 연관관계 매핑을 할 때 @OneToMany, @ManyToOne 등 등 다양하게 존재한다.
근데 내가 조회를 하면서, @OneToMany 관계로 매핑된 엔티티들을 가져오려고 하면, 오류가 발생한다.
예를 들어보자.
나는 지금 커뮤니티 라고 쓰고 지금은 블로그랑 비슷한 무언가를 만드는 중이다.
게시글에는 대부분의 커뮤니티가 그렇듯, 댓글을 달고 좋아요를 누를 수 있다.
한 개의 게시글은 여러개의 댓글과 여러개의 좋아요를 받을 수 있다. 즉, 게시글과 댓글 및 좋아요는 @OneToMany 이다.
이걸 그냥 join 하면 N+1 문제가 발생하는 것은 백엔드를 공부하는 사람들 대부분이 아는 상식이고, 당연히 fecth join을 통해 문제를 해결해야 한다.
(나는 spring data jpa를 사용하므로, EntityGraph를 이용하였다.)
@EntityGraph(attributePaths = {"commentList", "postLikeList"})
Optional<Post> findPostById(UUID postId); 그러면, 이렇게 된다.

에러가 발생한다. 여러개의 bag을 한번에 fetch join 할 수 없다는 뜻이다.
이것에 대해 본질적으로 완벽하게 해결하는 방안은 없지만,
각각의 케이스에 따라서 어느정도의 해결책은 있다.
그 중 가장 유명한 것이 default_batch_fetch_size 를 이용하는 것이다.
spring:
jpa:
properties:
hibernate.default_batch_fetch_size: 1000이렇게 할 경우, 지정된 수 만큼, in 절에 부모key를 사용하게 해준다.
where절에서 부모의 key를 바탕으로 자식 entity를 조회하게 되는 것이다.
아까 위에서 들었던 예시 케이스에선, 1000개의 게시글의 key를 in절에 넣어서 댓글과 좋아요를 조회할 것이다.
실제로 지금 Post, Comment와 PostLike로 이루어진 개인 프로젝트의 사례를 보자면
public class Post{
//...
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL)
private List<Comment> commentList = new ArrayList<>();
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL)
private List<PostLike> postLikeList = new ArrayList<>();
//...
}이런 식으로, 두 개 이상의 @OneToMany 매핑이 되어 있을 때,
위에 default_batch_fetch_size = 1000을 적용하면
조회 시 쿼리가 이렇게 나가게 된다.
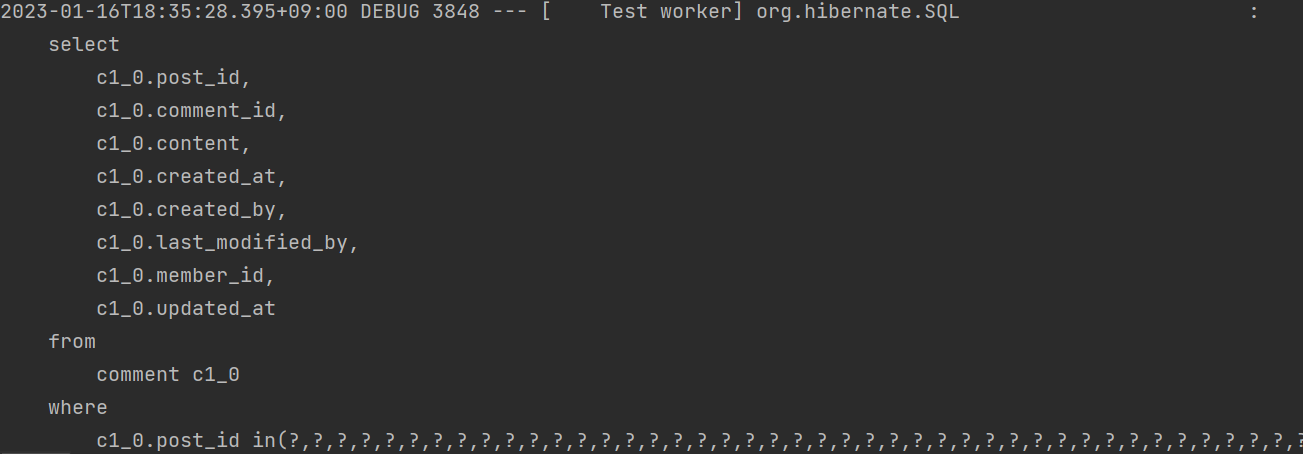
댓글을 조회할 때 아래 where 절을 보면, in절에 수많은 ?들이 있다.
이 ? 들은 default_batch_fetch_size로 인해 넘어간
1000개의 post_id이다.
성능 개선 정도
즉 부모 키 1000개씩을 끊어서 댓글 및 좋아요를 가져온다는 점에서, 부모 엔티티의 갯수에 따라 쿼리의 수 또한 결정된다는것을 알 수 있다.
즉,부모 엔티티인 게시글이 1000개 이하 존재한다면 댓글과 좋아요를 조회하기 위한 쿼리가 각각 1번씩 나갈 것이고, 부모 엔티티가 100만개 존재한다면, 각각 1000000 / 1000 = 1000번의 조회 쿼리가 수행될 것이다.
결론
꽤나 규모 있는 커뮤니티에서는 몇 십만~ 몇 백만 단위의 게시글이 존재한다. 이러한 커뮤니티의 게시글을 전부 조회한다고 했을 경우, 100만개의 게시글을 조회하는 쿼리 하나와, 100만개 게시글 각각의 댓글, 좋아요를 조회하는 쿼리가 나갈것이므로 발생하는 총 쿼리 수는 2000001개일 것이다.
하지만, default_batch_fetch_size를 통해 1000개씩 부모 엔티티를 where의 in에 넣어서 조회를 함으로써, 이보다 훨씬 적은 수의 쿼리를 수행하게 하여 성능을 개선할 수 있게 되었다.
