-
주소 : https://developer.android.com/codelabs/advanced-kotlin-coroutines?hl=ko#1
-
코루틴 플로우를 학습해야 하는데 잘 감이 오지 않아 코드랩을 보며 하나하나씩 따라서 해보려고 합니다.
-
필수조건 : Room, LiveData, Repository, ViewModel사용에 대해 어느정도 이해하고 있어야 합니다.
- 먼저 코드랩을 따라 앱을 실행하면 아래와 같이 식물의 이미지와 이름을볼 수 있습니다.
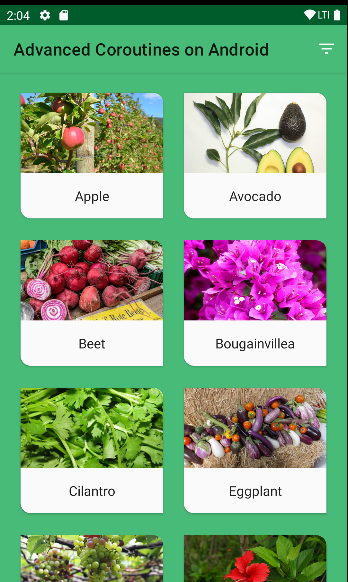
-
우측 상단 필터를통해 각 Plant에 존재하는 식물이 잘 자랄 가능성이 가장 높은 지역을 나타내는 growZoneNumber 속성을 필터링할 수 있습니다.
-
다음으로 ViewModel영역을 보겠습니다.
val plants: LiveData<List<Plant>> = growZone.switchMap { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plants
} else {
plantRepository.getPlantsWithGrowZone(growZone)
}
}- growZone은 영역만을 나타내는 inline클래스입니다. 영역이 없는 경우 NoGrowZone을 사용하며 필터링에만 사용합니다.
inline class GrowZone(val number: Int)
val NoGrowZone = GrowZone(-1)-
switchMap은 일반 map처럼 동작하지만 반환 결과로 LiveData를 return하는 메소드입니다.
-
Room에 사용되는 Data Access Object(DAO)는 아래와 같이 정의되어 있습니다.
@Query("SELECT * FROM plants ORDER BY name")
fun getPlants(): LiveData<List<Plant>>
@Query("SELECT * FROM plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumber(growZoneNumber: Int): LiveData<List<Plant>>- PlantRepository에서 데이터를 아래와 같이 불러옵니다.
val plants = plantDao.getPlants()
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)작업
- 현재 코드랩에서 하려고하는 작업은 알파벳순으로 정렬되어 있는 목록을 오렌지, 해바라기, 포도, 아보카도라는 4가지 식물을 최상단에 표기한 후 나머지 식물을 알파벳순으로 정렬하려고 합니다. 결과는 아래와 같습니다.
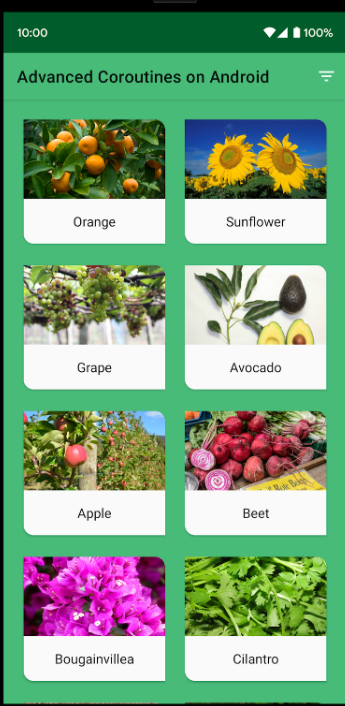
- 이상태에서 필터 버튼을 누르면 GrowZone9에 해당하는 식물만 남고 사라져야 합니다. 오렌지, 해바라기, 아보카도가 그대로 남아있고 마지막 식물인 토마토가 추가되도록 하려고 합니다. 결과는 아래와 같습니다.
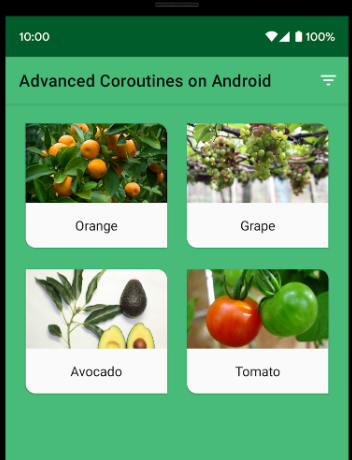
정렬 순서 가져오기
- 네트워크에서 커스텀 정렬 순서를 가져온 다음 메모리에 캐쉬하는 suspend 함수를 repository에 작성합니다.
private var plantsListSortOrderCache =
CacheOnSuccess(onErrorFallback = { listOf<String>() }) {
plantService.customPlantSortOrder()
}- 식물목록에 정렬을 적용하는 로직을 작성합니다.
private fun List<Plant>.applySort(customSortOrder: List<String>): List<Plant> {
return sortedBy { plant ->
val positionForItem = customSortOrder.indexOf(plant.plantId).let { order ->
if (order > -1) order else Int.MAX_VALUE
}
ComparablePair(positionForItem, plant.name)
}
}- 이제 정렬 로직이 준비되었으므로 아래와 같이 plants 및 getPlantsWithGrowZone의 코드를 LiveData 빌더로 바꿉니다.
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map {
plantList -> plantList.applySort(customSortOrder)
})
}
fun getPlantsWithGrowZone(growZone: GrowZone) = liveData {
val plantsGrowZoneLiveData = plantDao.getPlantsWithGrowZoneNumber(growZone.number)
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsGrowZoneLiveData.map { plantList ->
plantList.applySort(customSortOrder)
})
}-
이제 앱을 실행하면 커스텀 정렬된 식물 목록을 확인할 수 있습니다.
-
LiveData 빌더를 사용하면 liveData가 코루틴에 의해 지원되므로 비동기적으로 값을 계산 할 수 있다. 여기에는 데이터베이스에서 식물의 목록을 LiveData 로 가져오는 suspend 함수가 있으며 커스텀 정렬 순서를 가져오기 위해 suspend 함수를 호출하기도 한다. 그런 다음 이 두 값을 결합하여 식물 목록을 정렬하고 값을 모두 빌더 내에서 반환한다.
-
새 값을 내보내고 싶을 때마다 emitSource() 함수를 호출하여 LiveData 에서 여러 값을 내보낼 수 있습니다. emitSource() 를 호출할 때마다 이전에 추가된 소스가 제거됩니다.
-
코루틴은 옵저브 되면 실행을 시작하고 코루틴이 성공적으로 완료되거나 데이터베이스 또는 네트워크 호출이 실패하면 취소됩니다.
-
suspend 함수 호출 중 하나라도 실패하면 전체 블록이 취소되고 다시 시작되지 않으므로 메모리 누수를 방지하는데 도움을 줍니다.
-
이제 각 값이 처리될 때 정지 transform을 구현하도록 PlantRepository를 수정함으로써 LiveData에서 복잡한 비동기 transform을 빌드하는 방법을 알아봅니다. 전제조건으로, 기본 스레드에 안전하게 사용할 수 있는 정렬 알고리즘 버전을 만들어 보겠습니다. withContext를 사용하여 람다 전용의 다른 디스패처로 전환한 후 시작했던 디스패처에서 다시 시작할 수 있습니다.
다음을 PlantRepository에 추가합니다.
@AnyThread
suspend fun List<Plant>.applyMainSafeSort(customSortOrder: List<String>) =
withContext(Dispatchers.Default) {
this@applyMainSafeSort.applySort(customSortOrder)
}- 이제 아래와 같이 메소드를 변경합니다.
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
.switchMap { plantList ->
liveData {
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emit(plantList.applyMainSafeSort(customSortOrder))
}
}- 이제부터 이 코드를 Flow를 사용하는 것으로 변경하겠습니다.
Flow
-
Flow는 Cold 비동기 스트림입니다. 스트림은 Sequence와 마찬가지로 값이 필요할 때마다 요청 시 값을 생성하고 스트림에 포함할 수 있는 값의 수는 무한합니다.
-
Flow는 코루틴을 완벽하게 지원하며 코루틴을 사용하여 Flow를 빌드하고 변환하는 등의 작업이 가능합니다. RxJava는 Cold, Hot 비동기 스트림을 모두 지원했다면 코틀린에서는 Channel을 통해 Hot비동기 스트림을, Flow를 통해 Cold비동기 스트림을 사용할 수 있으며 RxJava와 유사하게 map, flatMapLatest, combine같은 연산자를 사용할 수 이씁니다.
- 기본적인 Flow는 아래와 같이 사용할 수 있습니다.
fun makeFlow() = flow {
println("sending first value")
emit(1)
println("first value collected, sending another value")
emit(2)
println("second value collected, sending a third value")
emit(3)
println("done")
}
scope.launch {
makeFlow().collect { value ->
println("got $value")
}
println("flow is completed")
}결과
sending first value
got 1
first value collected, sending another value
got 2
second value collected, sending a third value
got 3
done
flow is completed- collect와 flow를 오가며 실행되는 방식을 확인할 수 있으며 emit을 호출하면 모든 요소가 처리될때까지 suspend됩니다.
- Flow는 collect연산자가 호출되는 시점에 실행이 시작됩니다. 이 collect를 Flow에서 터미널연산자 라고 합니다.
- 이외에도 RxJava와 유사하게 take연산자를 통해 2개의 요소만 발행할 수 있습니다.
scope.launch { val repeatableFlow = makeFlow().take(2) // we only care about the first two elements println("first collection") repeatableFlow.collect() println("collecting again") repeatableFlow.collect() println("second collection completed") }
결과
first collection
sending first value
first value collected, sending another value
collecting again
sending first value
first value collected, sending another value
second collection completed
### Room With Flow
- 이번 단계에서 Room 에서 Flow 를 사용하고 UI 와 연결한 방법을 사용해보겠습니다.
- Flow의 일반적인 사용은 아래와같은 방식으로 사용합니다. 방식으로 사용하면 Room 에서 Flow 는 LiveData 와 유사한 관찰 가능한 데이터베이스 쿼리로 작동하게 됩니다.
- PlantDao 를 수정해 보겠습니다.
```kotlin
@Query("SELECT * from plants ORDER BY name")
fun getPlantsFlow(): Flow<List<Plant>>
@Query("SELECT * from plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumberFlow(growZoneNumber: Int): Flow<List<Plant>>- LiveData와 유사하지만 Flow는 아래와 같은 특징이 있습니다.
Flow 리턴 타입을 지정하면 Room 은 다음과 같은 특성으로 쿼리를 실행합니다.
-
Main-safety - Flow 리턴 타입을 가진 쿼리들은 항상 Room executor 에서 돌아가므로 항상 main-safe 하다. 메인 스레드에서 실행되도록 코드에서 아무것도 할 필요가 없다.
-
Observes changes - Room 은 자동으로 변화를 관찰하고 Flow 에게 새로운 값을 내보낸다.
-
Async sequence - Flow 각 변경에 대해 전체 쿼리 결과를 내보내고 어떠한 버퍼도 도입하지 않는다. Flow<List> 를 리턴한다면 Flow 는 쿼리 결과의 모든 행을 포함하는 List 를 내보낸다.
-
Cancellable - 이러한 Flow 를 수집하는 scope 가 취소되면 Room 에서 이 쿼리 관찰을 취소한다.
- Flow를 사용하기 위해 PlantRepository에 아래와 같이 코드를 추가합니다.
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
fun getPlantsWithGrowZoneFlow(growZoneNumber: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZoneNumber.number)
}ViewModel 업데이트
- 먼저 간단하게 ViewModel에서 plantsFlow를 표기해 보겠습니다.
val plantsUsingFlow: LiveData<List<Plant>> = plantRepository.plantsFlow.asLiveData()-
현재는 Flow 값을 호출자에 전달하기만 합니다. 이는 이 Codelab을 시작할 때 LiveData를 ViewModel에 전달한 것과 정확히 같습니다.
-
또한 ViewModel에서 init 블록에 캐시 업데이트를 추가합니다. 필수는 아니지만 현재는 캐시를 지우고 이 코드 추가하지 않으면 앱에 데이터가 표시되지 않습니다.
init {
clearGrowZoneNumber() // keep this
// fetch the full plant list
launchDataLoad { plantRepository.tryUpdateRecentPlantsCache() }
}- 프래그먼트의 subsribeUi메소드를 아래와 같이 변경합니다.
private fun subscribeUi(adapter: PlantAdapter) {
viewModel.plantsUsingFlow.observe(viewLifecycleOwner) { plants ->
adapter.submitList(plants)
}
}- 이제 Flow 연산자를 이용하여 정렬을 진행해 보겠습니다.
- Plant Repository에 customSortFlow라는 flow를 정의합니다.
private val customSortFlow = flow { emit(plantsListSortOrderCache.getOrAwait()) }또는 이 Flow는 단일 값만 내보내므로 아래와 같이 asFlow메소드를 사용할 수도 있습니다.
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()- 이제 combine연산자를 통해 두 flow를 결합해보겠습니다.
- plantsFlow에 combine연산자를 추가합니다.
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
// When the result of customSortFlow is available,
// this will combine it with the latest value from
// the flow above. Thus, as long as both `plants`
// and `sortOrder` are have an initial value (their
// flow has emitted at least one value), any change
// to either `plants` or `sortOrder` will call
// `plants.applySort(sortOrder)`.
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}-
combine 연산자는 두개의 Flow 를 결합하며 두 Flow 는 자신들의 코루틴에서 실행되며, 두 Flow 중 하나가 새 값을 생성할 때마다 두 Flow 의 최신 값으로 변환이 되며 호출됩니다.
-
combine 을 사용하여 캐시된 네트워크 조회를 데이터베이스 쿼리와 결합 할 수 있습니다. 둘 다 다른 코루틴에서 동시에 실행되며 이는 Room 이 네트워크 요청을 시작하는 동안 Retrofit 이 네트워크 쿼리를 시작할 수 있음을 의미하며 그런 다음 결과가 두 Flow 에서 사용 가능하자마자 combine 람다를 호출하여 로드된 식물에 로드된 정렬 순서를 적용합니다.
-
combine 은 결합되는 각 flow 에 대해 하나의 코루틴을 시작합니다. 이렇게 하면 두 Flow 를 동시에 결합 할 수 있습니다.
Flow의 Main Safety
- Flow는 여기서 실행하는 것처럼 main-safe한 함수를 호출할 수 있으며 코루틴의 일반적인 기본 안전 보장을 유지합니다. Room과 Retrofit에서는 우리에게 main-safety 를 제공할 것이며 Flow 를 사용하여 네트워크 요청이나 데이터베이스 쿼리를 만들기 위해 다른 작업을 수행할 필요가 없습니다.
Flow는 아래와 같은 스레드를 사용합니다.
-
plantService.customPlantSortOrder가 Retrofit 스레드에서 실행됨(Call.enqueue 호출)
-
getPlantsFlow가 Room Executor에서 쿼리를 실행함
-
applySort가 디스패처(이 경우 Dispatchers.Main)에서 실행됨
-
따라서 Retrofit에서 정지 함수를 호출하고 Room 흐름을 사용했다면 기본 안전성을 우려하여 이 코드를 복잡하게 만들 필요가 없습니다.
-
그러나 데이터 세트의 규모가 커질수록 applySort 호출 시 기본 스레드를 차단할 정도로 속도가 떨어질 수도 있습니다. Flow는 flowOn이라는 선언적 API를 제공하여 흐름이 실행되는 스레드를 제어합니다.
-
아래와 같이 plantsFlow에 flowOn을 추가합니다.
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()- flowOn을 사용하면 flowOn이전에 지정한 연산은 flowOn에서 지정한 Dispatcher로 동작하며 withContext로 디스패처를 전환하는 방식과 유사하지만 flowOn은 버퍼를 도입하여 사용한다는 차이가 있습니다.
- conflate 연산자는 압축된 채널을 통해 flow 방출값을 압축하여 별도의 코루틴에서 콜렉터를 실행합니다. 이로 인해 콜렉터가 느려서 방출자가 일시 중단되지 않지만 콜렉터는 항상 가장 최근의 값을 방출한다는 것입니다.
