
최근 이직한 회사가 주로 로봇틱스를 다루어서 높은 트래픽을 처리할 경험이 드물기 떄문에 따로 공부하지 않으면 경험하기 힘들 것 같아서 최근에 "대규모 시스템 설계 기초"라는 책을 이용한 북스터디를 시작했습니다. 규모에 의한 결정보다는 아마 대규모 서비스에서 해결하는 방법론은 소규모 서비스에도 유용한 정보가 많을 것 같다는 예감도 들어서 열심히 학습해볼 생각입니다.
What?
Chapter 02에서는 "개략적인 규모 추정" 이라는 주제로 짧은 내용을 다루고 있습니다.
이 책에서는 겪어보기 힘든 대규모 시스템을 설계할 때 설계 초기에 어떻게 규모를 측정하고 그게 어떻게 설계에 영향을 끼칠지에 대해 설명해줍니다.
Why?
보통의 기능을 구현할 때 성능은 비기능적 요구사항이라서 구현을 하고 최적화를 하면서 생각하기 마련입니다. 하지만 초기에 과도한 초기 설계 대신 어느정도 대략적인 규모를 예측해보는 것을 뒤에 생길 요구사항 변경에 유연하게 대처하는데 굉장히 많은 도움을 줍니다.
"Power of 2"
핵심적인 부분은 아니지만 2의 제곱수에 익숙해지라는 가볍게 있습니다. 물론 알고 있지만 용어 자체만으로 크기가 상상되도록 익숙해지는게 좋을 것 같습니다. 책에 있는 내용이지만 간단히 표로 기록해두겠습니다.
| count of 2x | Approximation | Name |
|---|---|---|
| 10 | 1천(thousand) | 1KB |
| 20 | 1백만(million) | 1MB |
| 30 | 10억(billion) | 1GB |
| 40 | 1조(trillion) | 1TB |
| 50 | 1000조(quadrillion) | 1PB |
사실 인터넷 통신사 상품을 "100메가 인터넷" 이런 식으로 부르긴 하는데 얼마나 빠르고 내가 어떤 상품을 써야할지 감이 안잡히긴 합니다.
모든 프로그래머가 알아야하는 응답지연 값
구글의 제프 딘이라는 분이 2010년 통상적인 컴퓨터에서 구현된 연산들의 응답지연 값을 공개했었다고 합니다.
- L1 cache reference 0.5 ns
- Branch mispredict 5 ns
- L2 cache reference 7 ns
- Mutex lock/unlock 100 ns
- Main memory reference 100 ns
- Compress 1K bytes with Zippy 10,000 ns
- Send 2K bytes over 1 Gbps network 20,000 ns
- Read 1 MB sequentially from memory 250,000 ns
- Round trip within same datacenter 500,000 ns
- Disk seek 10,000,000 ns
- Read 1 MB sequentially from network 10,000,000 ns
- Read 1 MB sequentially from disk 30,000,000 ns
- Send packet CA->Netherlands->CA 150,000,000 ns
텍스트만으로는 감이 안잡힙니다.
https://colin-scott.github.io/personal_website/research/interactive_latency.html
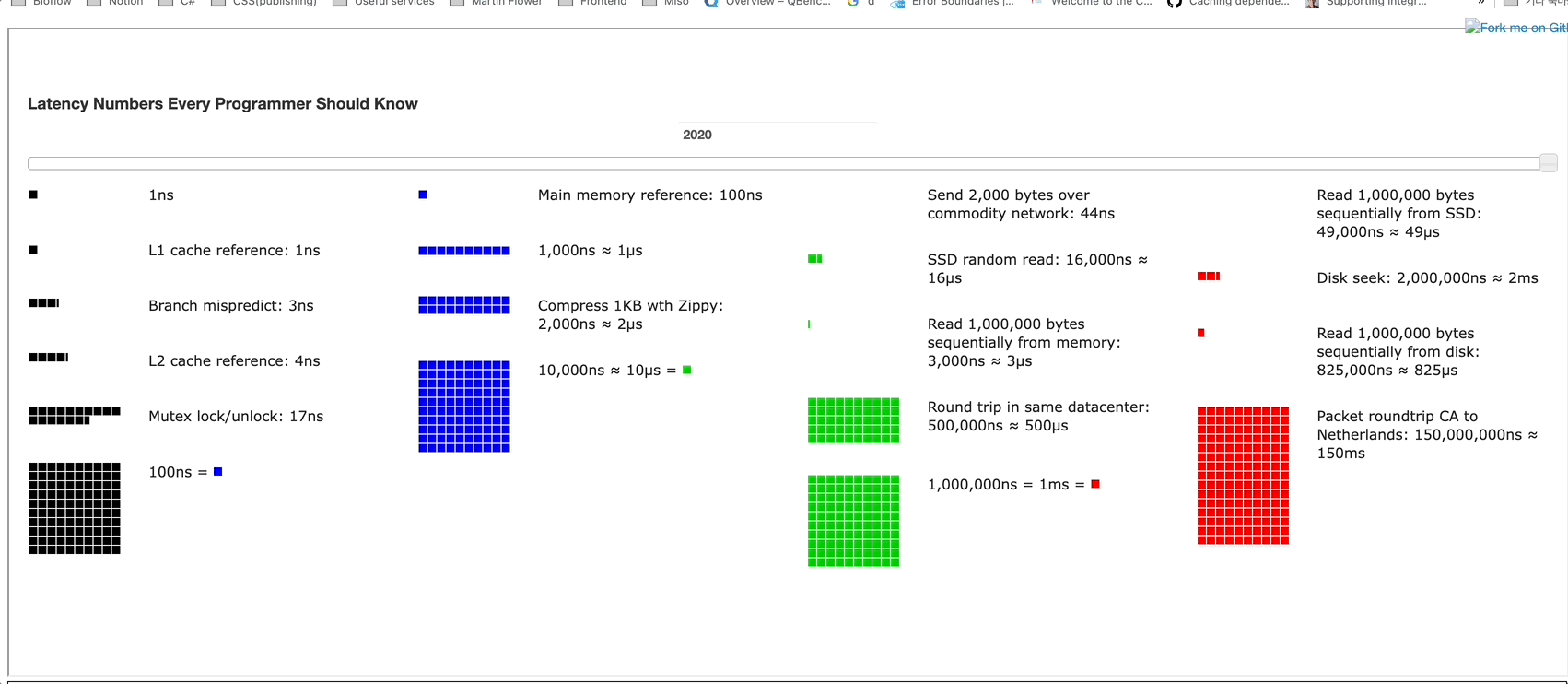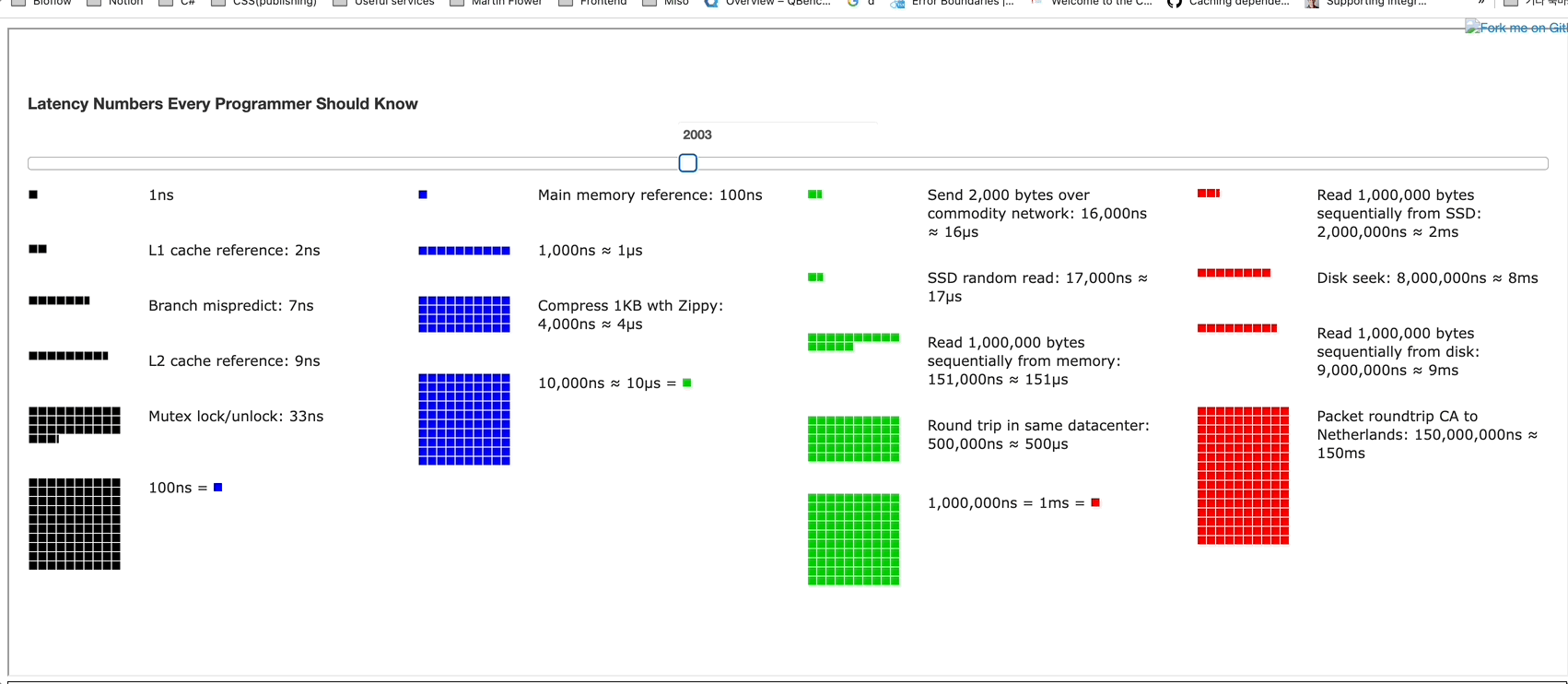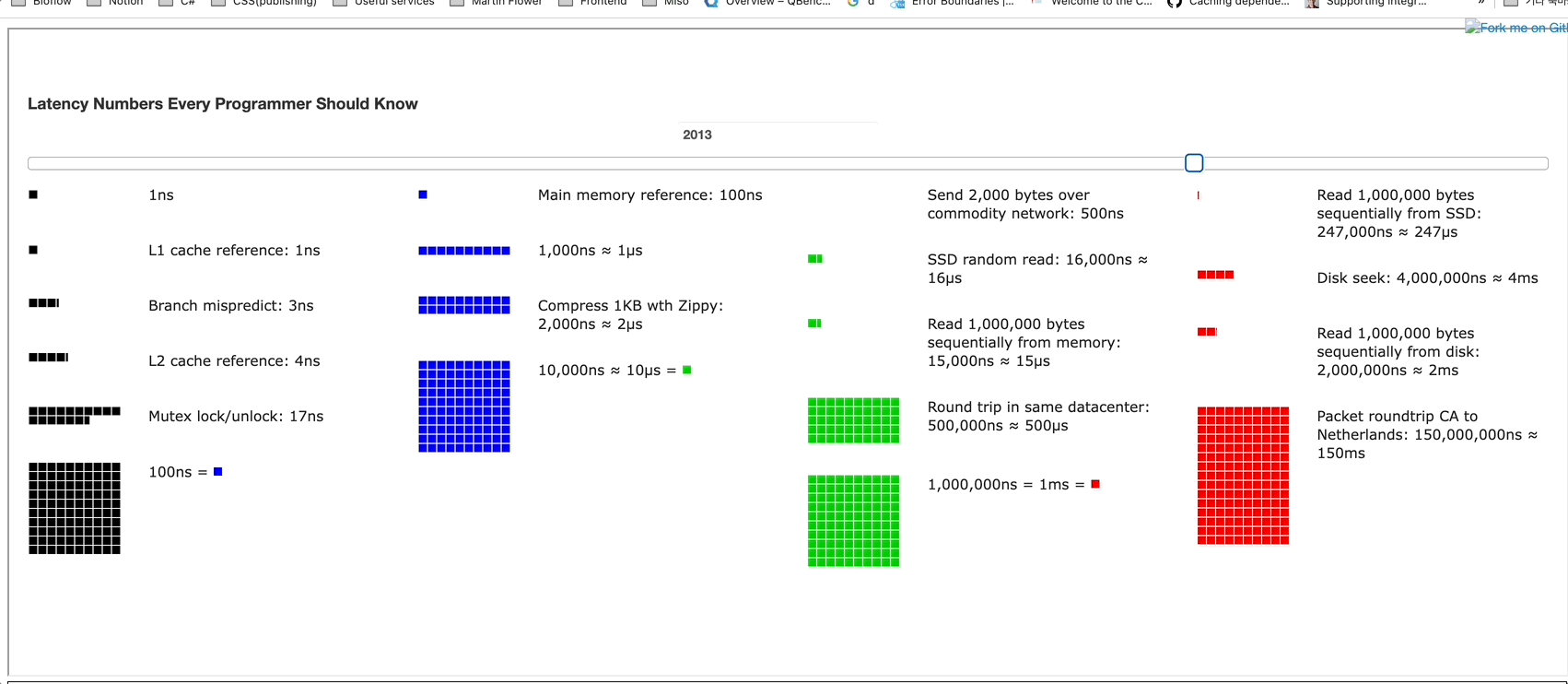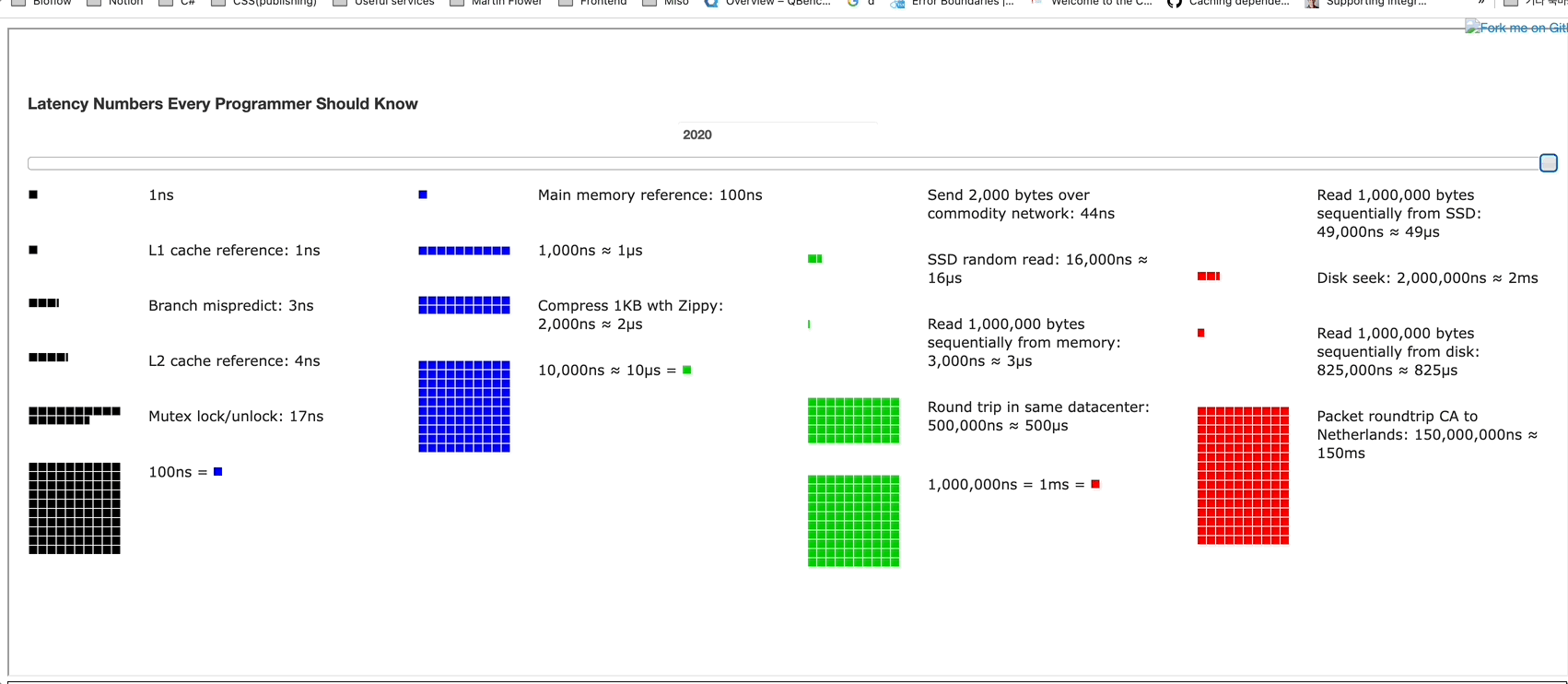
시각적으로 각 속도의 크기를 시대에 따라 어떻게 처리 속도가 달라지는지를 나타내는 홈페이지가 있습니다. Progress Bar로 어떻게 달라지를 볼 수 있습니다. 대학생 시절에 배웠던 "무어의 법칙"이 생각나네요.
위 사이트에서 시대에 따른 변화를 확인해보면
- ~ 2005년 : L1, L2 Cache와 같이 CPU와 메모리 사이의 성능과 데이터 압축 속도가 기하급수로 발전했습니다.
- 2005년 ~ : 그 이후부터는 네트워크 속도와 SSD 읽는 속도만 변화하고 그외의 것들은 변화하지않는 모습을 볼 수 있습니다.
여기서 드는 인사이트는 L1,L2는 이미 발전의 한계에 도달했고 앞으로의 핵심은 네트워크, 데이터베이스의 병목이 문제이지 않을까 개인적인 생각을 하고 있습니다. 어떤 부분에서 최적화를 해가야할지 방향을 잡을 수 있는 인사이트인 것 같습니다.
가용성에 관계된 수치들
High Availability, 사실 소프트웨어 엔지니어로 일하면서 가용성은 항상 고민하는 부분이지만 흔히 일어나는 일도 아니고 테스트를 하기도 어렵고 까다로운 부분이라고 생각합니다.
QPS(Query Per Second) 추정
제게 QPS는 다소 반갑게 느껴집니다. 네트워크의 성능 걱정은 많이 못해봤지만 데이터베이스를 설계하고 쿼리를 설계, 최적화해본 경험이 있습니다. 그리고 앞으로도 이 값을 활용해서 의사 결정을 내릴 때 도움이 되지않을까 생각이 듭니다.
책에서는 예시로 가상의 트위터 QPS와 저장소 요구량 추정을 합니다. Case Study로 아래 정보를 기반으로 대략적인 설계 기준을 만들 수 있습니다. 좋은 템플릿이라고 생각합니다. 토이, 현업 프로젝트를 할 때도 한번 아래 탬플릿으로 서비스를 한번 분석해보는 것은 좋을 것 같습니다.
가정:
- 월간 능동 사용자 (montly active user)는 3억 (300million)명 입니다.
- 50%의 사용자가 트위터를 매일 사용한다.
- 평균적으로 각 사용자는 매일 2건의 트윗을 올린다.
- 미디어를 포함하는 트윗은 10%정도다
- 데이터는 5년간 보관된다.
추정:
QPS (Query Per Second) 추정치
- 일간 능동 사용자(Daily Active User, DAU) = 3억 x 50% = 1.5억 (105million)
- QPS = 1.5억 x 2 트윗/24시간/3600초 = 약 3500
- 최대 QPS(Peek QPS) = 2 x QPS = 약 7000
미디어 저장을 위한 저장소 요구량
- 평균 트윗 크기
- tweet_id에 16바이트
- 텍스트에 140바이트
- 미디어에 1MB
- 미디어 저장소 요구량: 1.5억 x 2 x 10% x 1MB = 30TB/일
- 5년간 미디어를 보관하기 위한 저장소 요구량: 30TB x 365 x 5 = 약 55PB
과거 일자리 관련 매칭 어플리케이션을 개발하는 스타트업에서 일을 할 때 종종 Amplitude(이벤트 서비스)를 통해 어플리케이션의 DAU, 채팅 이용률과 같은 데이터를 대시보드로 만들어 확인했던 적이 있었는데 그 데이터로 채팅, 서버, 데이터베이스 인스터스 비용을 절약할 수 있지 않았을까 생각이 듭니다.
Tip
-
근사치를 황용한 계산 (Rouding and Approximation): 복잡한 계산을 하는 것은 어려운 입니다. 이런 데 시간을 쓰는 것은 낭비입니다. 계산 결과의 정확함을 평가하는게 목적이 아니라면 근사치로 팀원들과 소통하는 것이 도움이 될 것 같습니다.
-
단위를 꼭 붙이자. 단위를 붙이는 습관을 두면 모호함을 방지할 수 있습니다.
-
시스템 설꼐에서 많이 출제되는 개략적 규모 추정 문제는 QPS, 최대 QPS, 저장소 요구량, 캐시 요구량, 서버 수 등을 추정하는 것이다. 면접에 임하기 전에 이런 값들을 계산하는 연습을 미리하도록하자.
- 이 팁이 아마 이 챕터에서 가장 가치있는 부분이라고 느껴집니다!!
어떻게 QPS를 예측할지 마지막으로 따로 리서치를 남기고 글을 마무리를 해보겠습니다.
How to calculate QPS(Query Per Second)?
어떻게 측정하지 생각을 해보면 당장 떠오르는 방법은 아래 방법들이 있을 것 같습니다. 과거 경험에 의하면 특정 시간대에 어플리케이션 사용량이 몰리게 되는 경우가 있습니다. 그 때 데이터를 확인될 것 같습니다.
-
(Client Application) Amplitude, Google Analysis와 같은 사용자 이벤트 추적을 통해 Client 사이드에서 요청하는 주문 건 수와 같은 데이터 수와 주문이 하나 생성될 때 쿼리가 얼마나 호출되는지를 확인해서 대략적인 추정을 한다.
-
(API) 백엔드에 API 호출 수를 확인할 방법을 찾아서 초당 API 호출 수를 찾아서 초당 쿼리 수를 찾는다.
-
(Database) Azure, AWS의 데이터 베이스 Performance 분석을 이용해서 직접적으로 확인할 수 있을 것 같습니다.
위 나열한 3단계 분석할 수 록 후행적 분석에 가까울 것 같습니다. 미래에 새로운 기능들이 QPS를 어떻게 변경할 지는 위에 있을 수록 더 좋은 예측을 가능하게 됩니다. 그러니 유의미한 유저 행동 데이터를 잘 판단해서 미리미리 확보하는게 좋을 것 같습니다.
