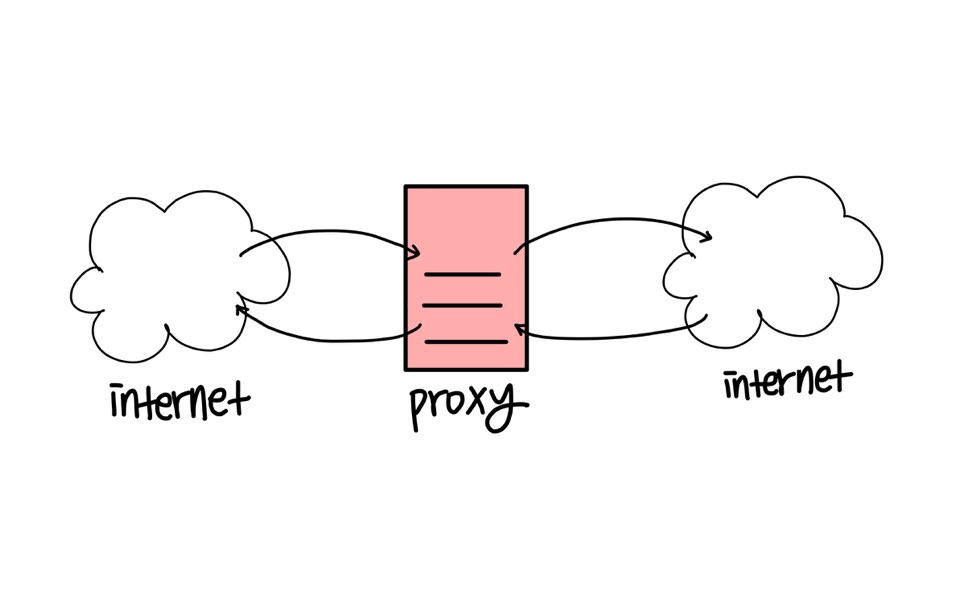
프록시와 리버스 프록시
대용량 처리를 위해서 서버를 병렬화하는 방법에 대해 공부하다가, 그 과정에 리버스 프록시나 로드밸런서에 대해서 어떻게 구현할까 - 와 같은 고민을 하다 프록시와 리버스 프록시에 대한 정리를 한번 하고 넘어가야겠다고 마음 먹었다.
프록시란?
프록시의 사전적 의미는 대리하다, 대신하다 이다. 두 PC가 통신을 할 때 직접하지 않고 중간에서 대리로 통신을 하고, 중계 역할을 하는 것이다. 그러니까 클라이언트와 서버 사이의 중계 서버이다. 보통 캐싱 등의 기능이나, 보안 목적으로 사용된다.

프록시는 서버의 위치(?)에 따라 포워드, 리버스 프록시로 나뉘는데, 일반적으로 프록시라고 하면 포워드 프록시를 의미한다.
포워드 프록시란?
클라이언트에서 서버로 리소스를 요청할 때 직접 요청하지 않고 프록시 서버를 거쳐서 요청한다. 이 경우 서버에서 받는 IP는 클라이언트의 IP가 아닌 프록시 서버의 IP이기 때문에 서버는 클라이언트가 누군지 알 수 없다. 즉, 서버에게 클라이언트가 누구인지 감춰주는 역할을 한다.
그러니까 로컬망에서 외부망으로 나갈때, 누가 요청했는지를 감추기 위해서 프록시라는 우회서버를 통해서 트래픽을 내보내는거다. 그리고 내보낸 것에 대한 회신을 받고 요청한 곳에 되돌려주는 중개인이다.
프록시의 역할
포워드 프록시의 특징/역할
-
캐싱 : 첫 번째 요청 이후부터는 동일한 요청이 들어올 경우, 프록시 서버에 캐싱된 내용을 전달해줌으로써 성능을 향상시킬 수 있다.
웹 서비스에서 요청이 발생할 때마다 1) 요청 → 2) 요청 전송 → 3) 요청 접수 → 4) 응답 생성 → 5) 응답 전송 → 6) 응답 수신 과 같은 과정을 반복해서 거친다. 요청이 한 번 뿐일 때는 괜찮지만, 중복되는 요청을 매번 처리하기에는 심한 자원낭비가 생기고, 웹 서버의 부하가 증가할 것이다.
이를 위해 포워드 프록시는 정적 데이터를 저장해두고 동일한 요청의 경우 웹서버 까지 가지 않고 포워드 프록시에서 처리할 수 있는 캐싱 역할을 수행한다. -
IP 우회 : 위에 언급했듯이 클라이언트 측에서 프록시 서버를 거쳐 웹 서비스를 이용할 경우, 서버 측에서는 요청을 받을 때 클라이언트의 IP가 아닌 프록시 서버의 IP를 전달받게 된다. 즉, 서버 측에 클라이언트의 정보를 숨길 수 있게 되는 것이다.
-
제한 : 보안이 중요한 사내망에서 정해진 사이트에만 연결 할 수 있도록 설정하는 등 웹 사용 환경을 제한할 수 있다.
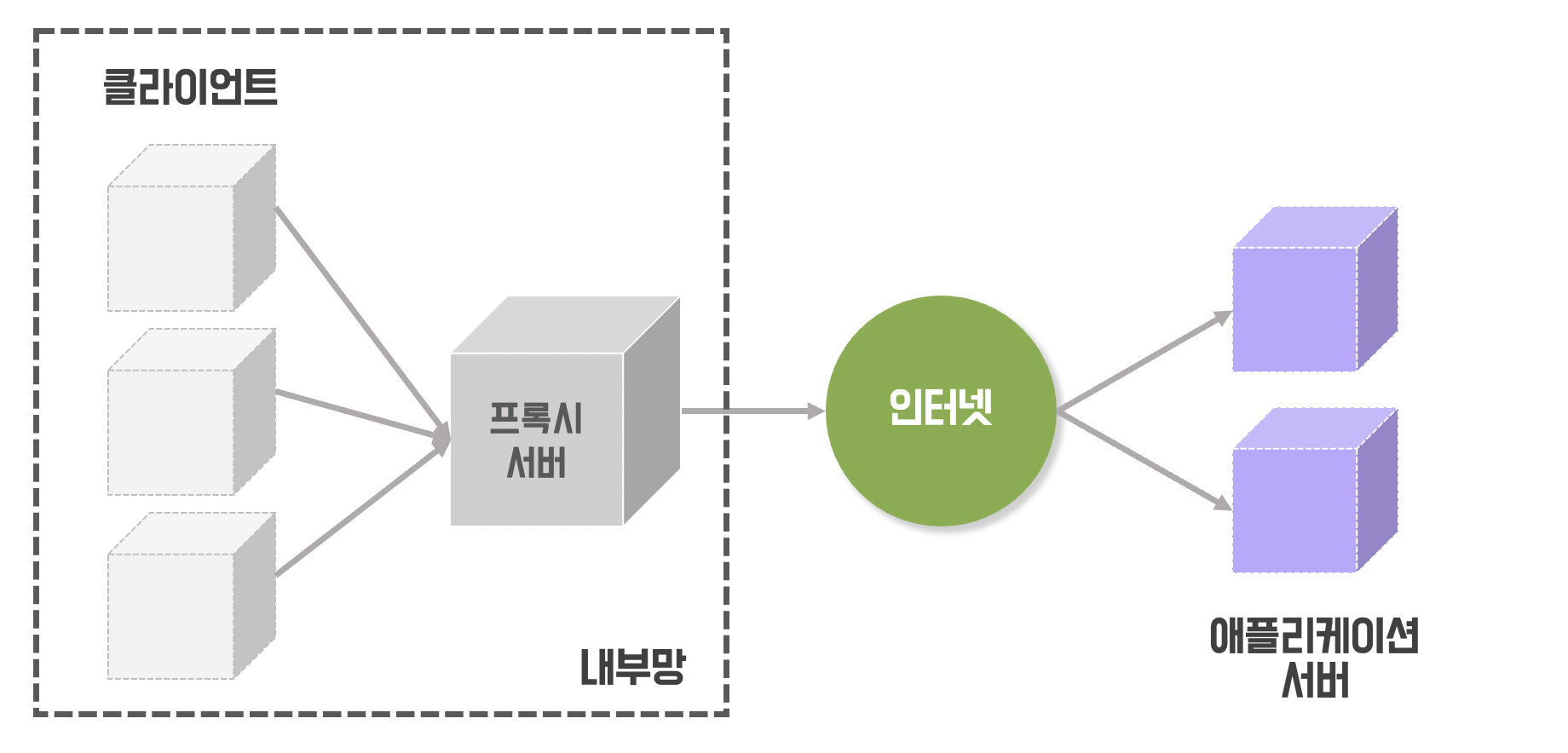
그럼 리버스 프록시란?
리버스 프록시는 포워드 프록시와 반대 개념이다. 애플리케이션 서버의 앞에 위치하여 클라이언트가 서버를 요청할 때 리버스 프록시를 호출하고, 리버스 프록시가 서버로부터 응답을 전달받아 다시 클라이언트에게 전송하는 역할을 한다.
이 경우, 클라이언트는 애플리케이션 서버를 직접 호출하는 것이 아니라 프록시 서버를 통해 호출하기 때문에 리버스 프록시는 애플리케이션 서버를 감추는 역할을 하게 된다.
그러니까 들어온 트래픽에 대해서 내부적으로 별도 방식으로 통신하고 그 결과를 외부로 돌려주는 것이다.
리버스 프록시의 역할
- 보안 : 보안 상의 이유로 서버에 직접 접근하는 것을 막기 위해 DMZ같은 네트워크에 리버스 프록시를 구성하여 접근하도록 한다.
- 로드밸런싱 : 로드밸런서와 업무 방식이 비슷하다.
리버스 프록시? 로드밸런서?
다음 포스팅에서 로드밸런서를 주제로 다룰 것인데, 내가 이해한 내용을 내맘대로일단 그대로 쓰자면
로드밸런서는 서버 그룹이 대상이다. 그리고 그 그룹에 대해서 스케줄링이나 부하를 관리한다.
이 두가지의 개념을 정리하는데 혼동이 많이 와서, 정리를 함에 있어 이해한 바로만 써본다.
리버스 프록시에 대한 정리를 위해 여러 사이트들을 검색했을 때 리버스 프록시가 로드 밸런서의 기능을 한다는 식의 설명이 많은데, 리버스 프록시는 대상의 대한 규정이 없다. 스케쥴링이나 밸런싱에 대한 개념을 정의하지 않은 더 원초적인 정의다. 로드밸런서가 아니다. 프록시는 프록시고 로드밸런서는 로드밸런서로써 엄연히 구분되는 정의이다.
프록시 자체는 게이트웨이 하나가 중개하는것이고, 단지 방향성이나 목적이 방향별로 다른것 뿐이다. 외부냐 내부냐 같은 게이트웨이를 두고도 리버스 프록시로 썼냐, 거기에 스케줄러나 추가 개념을 달아서 로드밸런서로 썼냐, 그 개념없이도 기능을 수행해서 로드밸런서로 부르냐 그건 다 상황에 따라 지칭하는 것이다.
프록시는 상위 그룹이라면 로드밸런서는 더 구체적인 세부/부가적인 기능이 달려있는 것이라고 보면 된다.
그러니까 보안 등의 문제로 개인이나 서버가 직접 공개돼서 정보가 공개되거나 공격 대상이 되는 일이 생기기 때문에, 프록시 서버를 써서 개개인의 트래픽을 프록시 서버의 이름으로 외부 서버에 접속하도록 하고, 답을 받으면 돌려주고 <-여기까지의 개념만 리버스/프록시라고 한다.
그게 한개인지 그룹인지 그런 내용은 프록시 개념에서는 특정하지 않는다.
근데 그 리버스 프록시에 부가기능을 넣으면 리버스 프록시이긴 하지만 실질적인 동작은 로드밸런서로 돌아가게 할 수 있다는 것이다. 그니까 1차원적으로 한 개면 리버스 프록시고 그룹이나 다수라서 로드밸런서로 구분되는게 아니란 것이다.
기능별로 목적지 별로 내부서버에 도달하게 된다는 점만 같은거지, 병렬화해서 그 그룹 내부에 통신을 통제한다는 것은 다른 것이다.
내 얘기
그래서 내 목표는 이 개념을 어떻게 설계할건지 고민하는 것이다.
url을 어떻게 규정할건지, 모든 도메인을 만들어서 등록할건지, 어디서 어디라는 개념을 어떻게 규정할건지... 서비스를 병렬화해서 그룹화했는데 그거 어떻게 주소화해서 지칭하고 그 서버에 트래픽을 보낼건지...
에 대한 제너럴한 처리가 쿠버네티스에 되어 있는건 알지만, 내가 고민을 안하고 그냥 쿠베가 옳다고 그대로 쓴다기 보단 고민을 해야 서비스의 개념같은 것을 이해할 것 같아서!
뭔가 머릿속에 있는 내용을 글로써 옮기려니 부족한 점도 많아 보이네요. 혹시 보시는 분이 계시다면 댓글로 무수히 많은 훈수부탁드립니다...!!
