
데이터베이스
데이터베이스란 무엇일까? 이것을 알아보기전에 쉽게 이해해보자, 우리의 세상은 정말 많은 데이터가 존재하고있다.
오늘 몇교시의 수업은 무엇이 있는지, 버스 노선도에는 무엇이있는지 이 모든게 데이터베이스이다. TV의 편성표조차도 데이터베이스에서
나온다. 즉, 용도와 목적에 맞게 서로 같은 데이터끼리 저장해 놓은것을 데이터베이스라고한다.
관계형 데이터베이스
흔히 RDB(Relational Database) 라고 불리는 관계형 데이터베이스는 말 그대로 관계형 데이터 모델에 기초를 둔 DB이다.
RDBMS(Relational Database Management System) 이라는 것이 있는데, 이것은 RDB를 관리 하기위한 툴이다.
MySQL이나 Oracle같은 데이터베이스 저장툴들이 이에 속한다.
TABLE
테이블이란 뭘까? 우리는 관계형 데이터베이스를 2차원 테이블로 표현한다. 이는 쉽게 말해 엑셀표 같은거다!
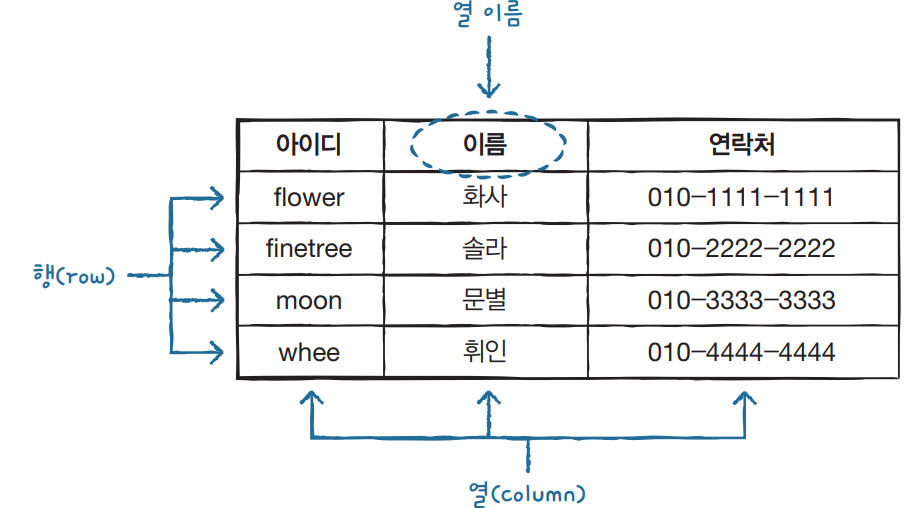
이런거다 데이터를 같은 항목끼리 묶어주면 되는것이다. 테이블은 관계형 DB의 기본 단위이고 여러개의 테이블을 묶는다.
이렇게 우리는 데이터를 저장하는 주된 목적은 데이터를 활용하는 데에 있고 우리는 그것으로 테이블 조회 삭제등을 하는거다.
SQL(Structured Query Language)
SQL은 관계형 데이터베이스에서 데이터를 다루기 위해 사용하는 언어다. 우리는 데이터를 변경하고 싶다면,,
무엇무엇을 이렇게 변경해줘~!! 라고 해야한다. 하지만 데이터베이스는 오케이 구글이나, 빅스비가 아니다. 그래서 데이터베이스의 언어인
SQL로 명령어를 실행시켜주어야한다.
모든 사람들이 같은 수준의 어휘력과 표현력을 갖지 못하는것 처럼 SQL도 작성 수준에 따라 한번에 알아듣거나, 아니면 몇번에 걸쳐 알아듣거나이다.
ㅠㅠ.. SQL은 사실 작성 방법이 어렵지않기때문에 누가 작성하든 별반 다를 것이 없지만, 어떻게 작성하느냐에 따라 성능이 확 갈린다.
SQL의 기본 문법
SQL을 사용하기 위한 기본 문법이다. 하나씩 설명을 작성하려고 한다.
1) SELECT
저장되어 있는 데이터를 조회하고자 할 때 사용한다. 그냥 조회이다.SELECT 컬럼1, 컬럼2.. 이렇게 간다.
컬럼을 따로 명시하지않고 * 를 사용하게 되면 모든 컬럼이 조회가 된다.
컬럼의 순서는 테이블의 컬럼 순서와 동일하다. WHERE절이 없으면 모든 row가 조회된다.
테이블명이나, 별도의 별칭도 붙여줄 수 있다. 우리가 줄임말 쓰는것과 비슷하게 말이다. 여러개의 테이블을 JOIN하거나 서브쿼리가 있을때
컬럼명 앞에 테이블을 같이 명시해야하는경우 코드가 길어져 앞에 별명을 붙이고 사용한다.

이런것이다. employees 를 A로 해놔서 밑에 A로 사용이 가능하다 Where절에서,
산술 연산자는 1. () 2. * 3. / 4. + 5. - 6. % 이렇게 6개가 있다 우선순위는 순서대로이다.
그냥 수학이랑 같다고 보면된다.
1 - 2)합성 연산자
문자와 문자를 연결할때 사용하는것이다. || 이런식으로 사용하면된다.
SELECT 'S'||'Q'||'L' AS SQL
FROM TABLE
SQL컬럼으로 SQL이 출력나머지 함수들이 정말 많지만 길어져 생략합니다.
2) WHERE
INSERT를 제외한 DML문을 수행할 때 데이터만 골라 수행하는것, 쉽게 말해 그냥 원하는 데이터만 딱 가져오는것이다.
NAME이 이지은 이라면 그 사람만 불러올수도 있고, 그 사람만 안불러올수도 있다.
SELECT * FROM TABLE WHERE 조건, 이렇게 흘러간다.
비교 연산자는 1. = 2. < 3. <= 4. > 5. >= 이다.
부정 비교 연산자는 1. != 2. ^= 3. <> 4. not 컬럼명 = 5. not 컬럼명 > 이다.
SQL 연산자
- BETWEEN A AND B
- A와 B 사이를 가르킨다. A B 둘다 포함한다.
- LIKE '비교 문자열'
- 여기에는 %, _ , 등이 있다.
- IN(LIST)
- List중 하나와 일치하면 된다.
- IS NULL
- NULL의 값이다.
3) GROUP BY, HAVING 절
그룹바이는 말 그대로 데이터를 그룹별로 묶는것 이다. GROUP 뒤에 수단의 전치사인 BY가 붙었기 때문에 GROUP BY뒤에는
그룹핑의 기준이 되는 컬럼이 오게된다. 컬럼은 하나가 될 수도 있고, 여러개가 될 수도 있다.
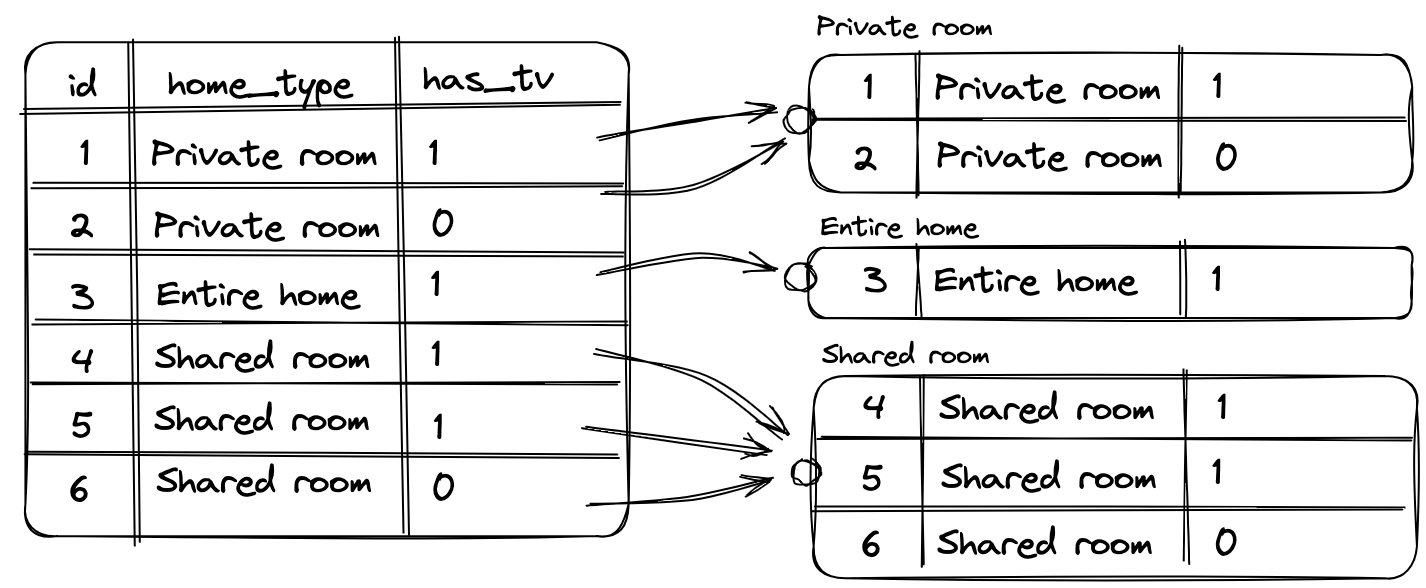
이런 형태로 묶어버린다.
3-2) 집계함수
데이터를 그룹별로 나누면 집계 데이터를 도출하는것이 가능해진다. 예를 들어 유튜브 이용자 수를 국가별로 그룹핑한다고 했을 때 나라별로
얼마만큼의 일용자가 있는지 확인이 가능하다. COUNT, SUM, AVG, MIN, MAX같은것들이 있다.
3-3) HAVING
HAVING은 GROUP BY절을 사용할 때 WHERE절 처럼 사용하는 조건문이다. 주로 데이터를 그룹핑한 후 특정 그룹을 골라낼 때 사용한다.
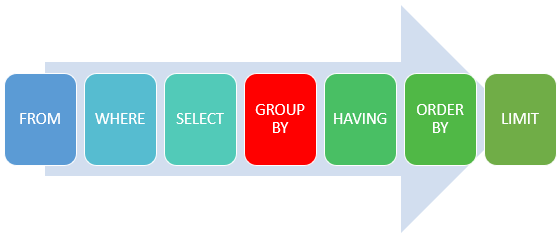
SQL문을 읽을때의 순서이다. HAVING은 논리적으로 GROUP BY절 이후에 수행되기 때문에 집계함수로 조건을 부여할 수 있다.
WHERE절을 사용할 것까지 HAVING으로 처리하면 성능상 불리할 수 있다. 물론 오류가 나지는 않는다. 그룹바이는 비교적 많은
비용이 드는 작업이므로 수행전에 데이터량을 최소!로 줄여놔야한다.
4) ORDER BY 절
ORDER BY절은 SELECT 문에서 논리적으로 맨 마지막에 수행된다.
이 문법을 사용해서 SELECT 데이터를 정렬 할 수 있다. 따로 명시하지않으면 임의의 순서대로 출력된다.
정렬 기준의 컬럼은 하나가 될 수도 있고, 여러개일수도 있다.
ASC : 오름차순
DESC : 내림차순
옵션 생략시 ASC가 기본값이다.
마치며
이렇게 기본적인 문법들을 알아보았다. 검색같은거나, 조건을 거는 것까지 알아보았고, Table을 넘어가면서 데이터를 불러오는건 Join이다.
그건 다음에 다루도록 하겠다. 읽는 순서가 중요하고, 기본적인 함수들을 암기해두면 좋다.
