🚀 코코무(COCOMU) 서비스
코코무 코딩 스터디 플랫폼에서 제공하는 서비스는 아래와 같습니다.
스터디
생성, 수정, 필터 기반 조회, 삭제, 참여, 탈퇴
코딩 스페이스
생성, 필터 기반 조회, 삭제, 참여, 입장, 시작, 피드백, 테스트 케이스 추가/제거, 코드 실행/제출
사용자
회원가입, 프로필 관리, 참여한 스터디 확인, 참여한 스페이스 확인
MVP 소개
코코무의 MVP 중 핵심기능을 우선순위 별 4가지로 정리했습니다.
- 코드 실행 및 제출
- 도메인 비즈니스 로직 개발
- OAuth 2.0 로그인
- SSE 알림
이어서, 코코무는 위 기능들에 대해 4주라는 짧은 시간 안에 어떻게 서비스를 구현할 수 있었는지 작성합니다.
1. Code Executor
상황 (Situation)
코코무(Cocomu)는 코딩 스터디 플랫폼으로 클라이언트가 작성한 코드에 대해 실행 및 제출을 할 수 있습니다.
- 실행: 사용자가 작성한 코드의 결과를 보여줍니다.
- 코드에 따라 입력 값이 필요할 수 있습니다.
- 제출: 각 테스트 케이스의 정답 여부를 제공합니다.
- 메트릭 정보: 코드가 처리되는데 사용한 Memory, 소모된 Time을 제공합니다.
이 기능을 동작하기 위한 시스템을 통칭 코드 실행기라고 정의하고 코드 실행기 구현을 하는 것이 목표인 상황입니다.
과제 (Task)
코드 실행기의 경우, 처음 도전하는 과제라서 상세한 설계가 필요했습니다. 저는 시스템 이해를 위해 모든 과정을 도식화하고 구현하는 것을 목표로 진행하게 됐습니다.
코드 실행기 구현 과정은 아래와 같습니다.
- 코드 실행기 구현 (Bash)
- 메트릭 정보 수집
- 코드 실행기 구현 (Server)
- Code Executor 통신 구조 재구성
- Code Executor Parallel Processing
행동 (Action)
기술 스택 포스트에 도입 이유에 대해 따로 작성했기 때문에, 각 구현 과정에서는 따로 이유를 작성하지 않고 글을 작성합니다.
각 구현 과정을 도식화하면서 단계 별로 이해하면서 문제를 해결해나갔습니다.
1. 코드 실행기 구현 (Bash)
코드 실행기는 악의적인 행위에서 보호할 수 있는 Docker Sandbox 환경을 통해 동작이됩니다. docker sandbox를 사용하는 자세한 설명 - 링크 클릭
코드 실행 과정 도식화
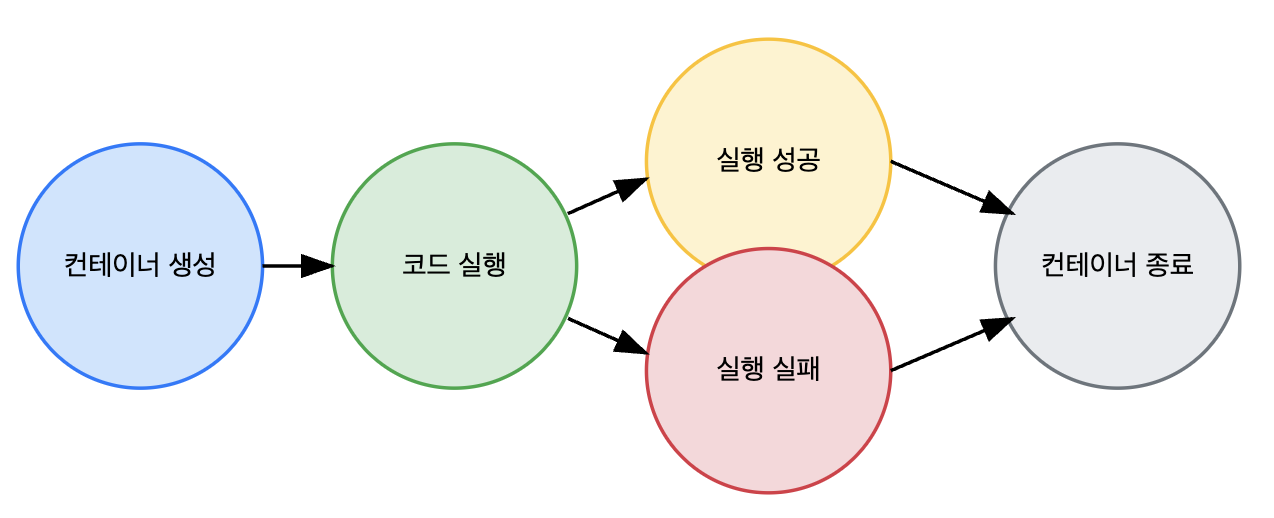 - Docker Sandbox Container Execution Flowchart -
- Docker Sandbox Container Execution Flowchart -
먼저, Docker Sandbox Container에서 코드를 실행하기 위해 컨테이너가 실행되는 과정을 도식화해봤습니다. 가장 기본적인 실행구조라고 생각됩니다. 첫 번째로 도식화 한 내용을 검증하는 단계가 필요했습니다.
코드 실행을 bash에서 직접해보기
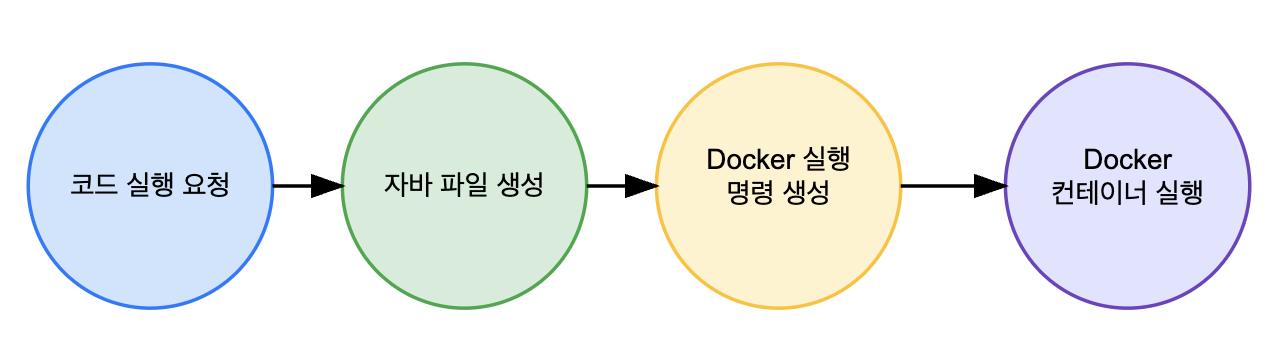 - Code Executor Logic Flowchart -
- Code Executor Logic Flowchart -
생각 포인트: 코드를 자바 코드로 실행하기 전, 먼저 bash에서 직접 실행해본 뒤 이해한 내용을 바탕으로 코드로 옮겨야 한다고 생각했습니다. 그래서 bash에서 직접 실행할 때, flow를 최대한 분할해봤습니다.
제가 선택한 컨테이너 실행 명령 전략은 아래와 같습니다.
1. 샌드박스 환경은 실행이 완료되면 제거되어야 한다.
2. 사용자가 작성한 코드가 Docker로 전달이 되어야한다. -> mount
3. 실행 결과를 식별할 수 있어야한다.
이 과정을 바탕으로 한 번 bash에서 작업했던 내용을 시뮬레이션 하겠습니다.
Sandbox Container 이미지 빌드
$ echo "FROM openjdk:17-slim" > Dockerfile
$ docker build -t executor .- docker 기반 sandbox container를 생성하려면 image가 build 되어 있어야 합니다.
- 컨테이너는 실제 코드 레벨에서 동작할 예정이므로 이미지와 연관된 다른 옵션은 모두 없어도 됩니다.
- 코코무에서 팀원 간 java는 17버전을 지원하기로 약속했습니다.
Test용 Java Code 생성
# Success
echo "import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String input = scanner.nextLine();
System.out.println(input);
}
}" > Main.java- 입/출력에 성공하는 자바 테스트 코드를 작성합니다.
Sandbox Container 실행
docker run --rm -v "$(pwd):/code" -w /code code-executor sh -c 'echo "Hello World" | java Main.java'- 실행이 끝나면 제거 되어야한다: --rm
- volume mount를 해야 된다: -v
- mount된 코드를 실행해야 한다: sh -c
실행 결과 확인
Laboon 🐳 ~/workspace/project/test
docker run --rm -v "$(pwd):/code" -w /code code-executor sh -c 'echo "Hello World" | java Main.java'
Hello World- 실행 결과는 예상한대로 정상적으로 동작했습니다.
실제로 코드를 실행하기 위한 환경은 다 구성되었고 첫 번째 과제를 해결했습니다. 다음 과제를 해결해보겠습니다. 😔
2. 메트릭 정보 수집
메트릭 정보를 수집하기 위해서는 기존의 코드 실행 로직을 개선해야 했습니다. 기존의 방식으로 메트릭 정보를 수집하던 중 2가지의 문제 상황을 직면했습니다.
문제 상황 1) 잘못된 메트릭 정보 측정
GNU time util 설치
우선, 실행 시간을 측정하기 위해서는 Dockerfile부터 수정해야 됩니다.
echo "FROM openjdk:17-slim
RUN apt-get update && apt-get install -y --no-install-recommends \
time \
&& rm -rf /var/lib/apt/lists/*
" > Dockerfile- bash에서 실행되는 명령의 메트릭을 수집 할 수 있는 gnu time util을 설치합니다.
- gnu time은
/usr/bin/time에 위치합니다.
- gnu time은
- sandbox 경량화를 위해 필요한 util 외 데이터는 필요 없으므로 apt 목록을 지웁니다.
메트릭 수집하기
docker run --rm -v "$(pwd):/code" -w /code code-executor sh -c 'echo "Hello World" | java Main.java기존의 실행 코드에서 명령의 메트릭을 수집하는 방법은 간단합니다. 다양한 방법이 있지만, 저는 format 형식으로 진행했습니다. 기존 코드 실행 명령을 /usr/bin/time -f "\n%e\n%M" java Main.java로 수정하면 됩니다.
- %e는 실행 시간 측정
- %M은 사용 메모리 측정
수집 결과 확인
Laboon 🐳 ~/workspace/project/test
docker run --rm -v "$(pwd):/code" -w /code java-code-executor sh -c 'echo "Hello World" | /usr/bin/time -f "\n%e\n%M" java Main.java'
Hello World
0.19
88752당장, 결과만 식별 했을 때는 문제가 없어보일 수 있습니다. 하지만, 저는 BOJ(Baekjoon Online Judge)와 같은 코딩 문제를 해결해 본 경험을 바탕으로 찝찝함이 있었습니다.
단순 HelloWorld 출력에 190ms가 소요된다고?
실제 boj에서 java 코드로 helloworld 문제를 해결하면 96ms가 소요됐습니다. boj는 c4.large, 로컬 환경은 m4인 점을 감안하면 너무 오랜 시간이 소요되는 것을 알 수 있습니다.
문제 상황 1 해결
수집 결과 개선
문제는 interpreter 기반의 언어에서는 컴파일 후 코드를 실행하기 때문에, 컴파일 + 코드 실행 로직이 혼합되었기 때문이였습니다.
docker run --rm -v "$(pwd):/code" -w /code java-code-executor sh -c 'javac Main.java && echo "Hello World" | /usr/bin/time -f "\n%e\n%M" java Main'
Hello World
0.02
39928javac로 compile 과정과 실제 실행 과정에서만 메트릭 정보를 수집하면서 실행 시간: 190ms -> 2ms, 메모리 사용: 88752KB -> 39928KB로 실제 코드 실행 정보에 대한 메트릭 정보만 추출하도록 개선되었습니다.
문제 상황 2) 각 실행 결과에 따른 분기 처리
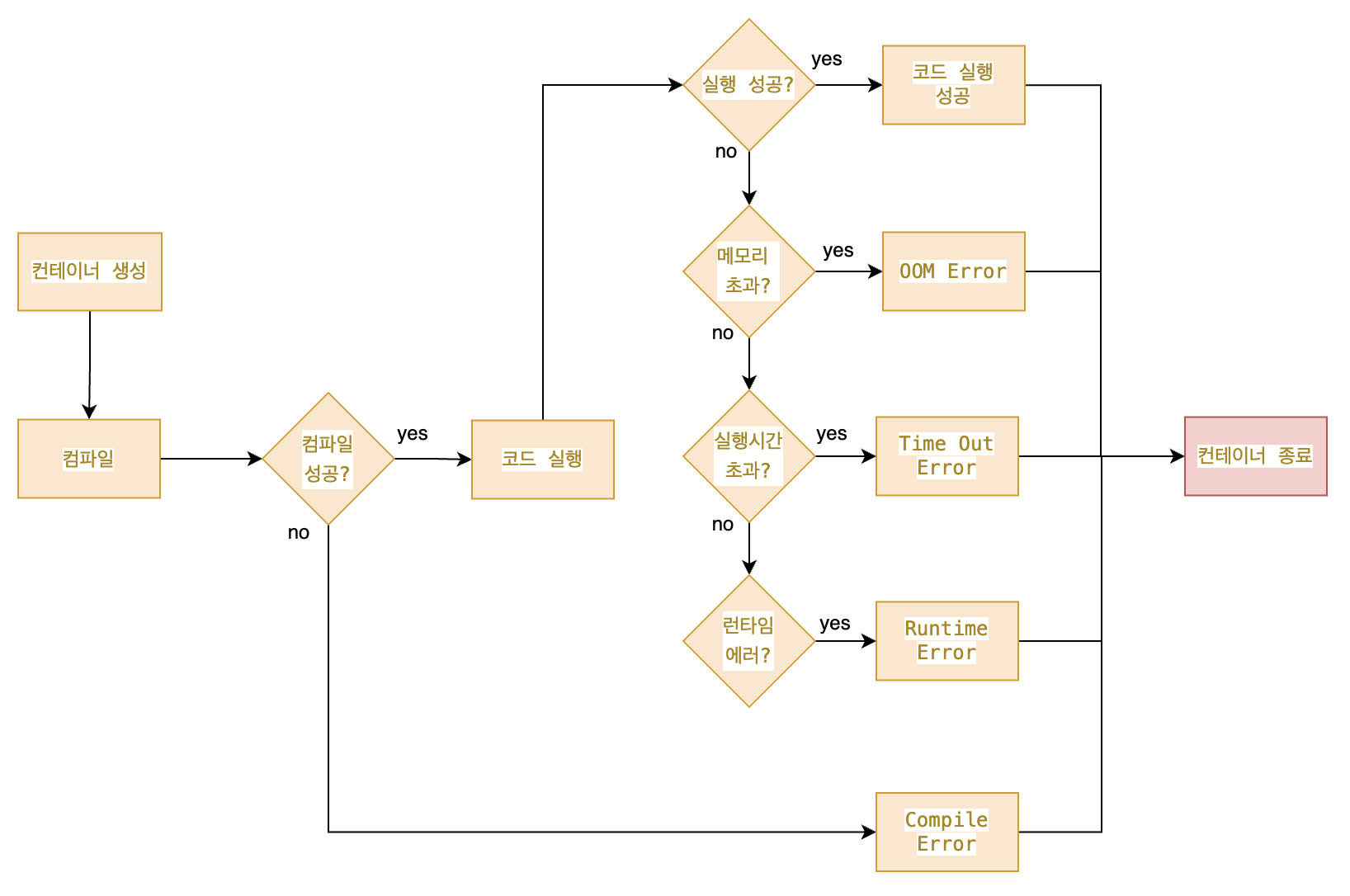 - Code Execute Flow Refactoring -
- Code Execute Flow Refactoring -
컴파일과 실행을 분리하면서 각 결과에 대한 metric 정보를 수집하려고 했지만, 결과적으로 실패했습니다. 원인은 각 결과에 대해 메트릭을 수집하는 방법에서 다양한 이슈가 있었기 때문입니다. 이어서 다양한 이슈에 대해 작성하겠습니다.
실행 결과는 어떻게 구성이 될까?
- 성공: 코드 실행 성공
- 실패: 컴파일, 런타임, 메모리초과, 시간초과 에러
컴파일 에러 이슈
# Compile Error
echo '
public class CompileError {
public static void main(String[] args) {
}
}' > CompileError.java- 메트릭 정보는 런타임 시점에만 확인한다.
- 컴파일 후 실행 될 이유가 없다.
- 런타임과 실행 결과를 확인하는 시점이 다르다.
- 즉, 서버 관점에서 컴파일과 런타임을 구분하는 기준이 필요하다.
- 컴파일 실패 시 종료하는 분기 처리 필요
- 코코무에서 사용하는 모든 언어를 기준으로 exit 코드를 확인한다.
- 컴파일 성공 시
exit:0, 실패 시exit:1
- 컴파일 성공 시
런타임 에러 이슈
# Runtime Error
echo '
public class RuntimeError {
public static void main(String[] args) {
String text = null;
System.out.println(text.length());
}
}' > RuntimeError.java- 컴파일 성공 후 로직 실행
- 코코무에서 사용하는 모든 언어를 기준으로 exit 코드를 확인
- 로직 실행 성공 시
exit:0, 실패 시exit:1 - 컴파일 과정과 같은 exit code 반환.
- 서버에서 식별하기 위한 특별 처리 필요
- 로직 실행 성공 시
# Timeout Error
echo 'public class TimeOut {
public static void main(String[] args) {
while(true) {
System.out.println("Still running...");
}
}
}' > TimeOut.java- timeout 도구를 이용해 명령이 실행되는 time이 초과되면 코드가 종료됩니다.
- 실제 에러로 볼 수 없어서 명확한 에러라고 식별 할 수 없습니다.
# OOM Error
echo 'public class OOM {
public static void main(String[] args) {
int[] array = new int[Integer.MAX_VALUE];
}
}' > OOM.java- java는 jvm을 사용하면서 코드를 실행 할 때 heapMemory를 설정할 수 있습니다.
- 다른 언어는 그렇지 않습니다.
문제 상황 2 해결
Compile 이슈
compile.log와 컴파일 실패 시 출력을 기록합니다.- 그리고 코코무에서 식별할 수 있도록 exit code를 1로 반환합니다.
- 컴파일에 성공하는 경우, 실행 결과는
output.log에 기록합니다.
Runtime 이슈
- 코코무에서 식별할 수 있도록 exit code를 2로 반환합니다.
TimeOut 이슈
- timeout이 되었을 경우, exit code 124 반환
- timeout은 공통 util이므로 일관적으로 처리 가능
OOM 이슈
- timeout 처럼 공통 관점 만들기
- docker의 메모리 제한을 활용 (--memory=?m option)
- JVM은 내부적으로 OOM을 처리하므로 새로운 분기 처리
- 공통된 exit code로 137을 반환
각 이슈를 해결 할 수 있는 Code Execute Script 테스트
# 컴파일 단계
compile_result=$(javac -encoding UTF-8 Main.java 2>&1)
compile_status=$?
if [ $compile_status -ne 0 ]; then
echo "$compile_result" > compile.log
exit 1 # 컴파일 에러
fi
# 실행 단계
output=$(echo helloWorld | timeout 2 /usr/bin/time -f "\n%e\n%M" java -Dfile.encoding=UTF-8 -XX:+UseSerialGC Main 2>&1)
status=$?
echo "$output" > output.log
if echo "$output" | grep -q "java.lang.OutOfMemoryError"; then
exit 137
fi
# 종료 상태 처리
case $status in
0) exit 0 ;; # 성공
124) exit 124 ;; # 타임아웃
137) exit 137 ;; # OOM
1) exit 2 ;; # 런타임 에러
*) exit 3 ;; # 기타 에러
esac-
현재 스크립트는 Java Code만 동작되도록 작성했습니다.
-
✅ 코드 실행 성공
Laboon 🐳 ~/workspace/project/test docker run --rm --memory=128m -v "$(pwd):/code" -w /code java-code-executor sh -c "./script.sh" Laboon 🐳 ~/workspace/project/test $? zsh: command not found: 0 ✘ Laboon 🐳 ~/workspace/project/test cat output.log helloWolrld 0.02 39984 -
❌ OOM Error
Laboon 🐳 ~/workspace/project/test docker run --rm --memory=128m -v "$(pwd):/code" -w /code java-code-executor sh -c "./script.sh" ✘ Laboon 🐳 ~/workspace/project/test $? zsh: command not found: 137 ✘ Laboon 🐳 ~/workspace/project/test cat output.log Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit at Main.main(Main.java:3) Command exited with non-zero status 1 0.01 33744 -
❌ Runtime Error
Laboon 🐳 ~/workspace/project/test docker run --rm --memory=128m -v "$(pwd):/code" -w /code java-code-executor sh -c "./script.sh" ✘ Laboon 🐳 ~/workspace/project/test $? zsh: command not found: 2 ✘ Laboon 🐳 ~/workspace/project/test cat output.log 런타임 에러 테스트 Exception in thread "main" java.lang.ArithmeticException: / by zero at Main.main(Main.java:4) Command exited with non-zero status 1 0.01 34020 -
❌ TimeOut Error
Laboon 🐳 ~/workspace/project/test docker run --rm --memory=128m -v "$(pwd):/code" -w /code java-code-executor sh -c "./script.sh" ✘ Laboon 🐳 ~/workspace/project/test $? zsh: command not found: 124 ✘ Laboon 🐳 ~/workspace/project/test cat output.log 무한 루프 시작... -
❌ Compile Error
Laboon 🐳 ~/workspace/project/test docker run --rm --memory=128m -v "$(pwd):/code" -w /code java-code-executor sh -c "./script.sh" ✘ Laboon 🐳 ~/workspace/project/test $? zsh: command not found: 1 ✘ Laboon 🐳 ~/workspace/project/test cat compile.log Main.java:3: error: ';' expected System.out.println("컴파일 에러 테스트") ^ 1 error
위 과정을 통해 두가지 문제사항을 직면하고 도식화하면서 상황 별로 메트릭 정보 수집에 성공했습니다. 추가로 발생할 수 있는 에러 또한 실제 결과를 보고 분기만 추가하면 되는 확장성있는 구조로 문제 해결에 성공했습니다.
3. 코드 실행기 구현 (Server)
서버에서의 코드 실행기는 Bash를 통해 전체적으로 이해가 완료되었다면 매우 간단합니다. 외부 프로세스(샌드박스 컨테이너)를 실행할 수 있는 ProcessBuilder를 통해 간단히 구현할 수 있습니다. 지금까지 구현한 내용을 바탕으로 코드화를 작성해보겠습니다.
코드화
- 사용자가 입력한 코드를
Main.java와 같은 실행 가능한 파일로 생성한다. - bash에서 작성한 명령으로 container를 생성할 수 있는 docker commander를 추출한다.
- 기존 docker 명령어: docker run --rm --memory=128m -v "$(pwd):/code" -w /code java-code-executor sh -c "./script.sh"
public class DockerCommander { // .. builder, method chaining // run, --rm, --memory, ... }
- Process Builder를 통해 외부 프로세스인 컨테이너를 실행한다.
- process.waitFor()을 통해 exitCode를 반환 받는다.
- exitCode 별로 클라이언트에게 실행 결과를 전달한다.
이 방식을 직접 서버에 코드로 구현하면서 API 요청으로 코드 실행에 성공했습니다 😊
4. Code Executor 통신 구조 재구성
기존 통신 방식의 문제점
현재까지 방식에서 2가지 문제점을 식별
- 메모리 점유: 샌드 박스 환경에서 메모리 점유가 발생 -> OS의 메모리 고갈
- SpringBoot Heap 메모리 고갈
- 타 API 요청에서 Heap Memory 사용시 OOM 문제 발생
- 타 API 요청 또는 Code 실행 요청 유실
- OS가 메모리 확보를 위해 특정 Process를 Kill
- API Server가 Kill 되는 상황이 발생 가능
- API Server Down
- SpringBoot Heap 메모리 고갈
- 스레드 점유: Timeout 코드가 여러개 실행 된다면 ?
- 타 API 응답 속도 저하
- 동기식 처리 방식의 한계
- 코드 실행은 최악의 경우 2s까지 스레드를 점유
- 코드 실행 결과가 응답 될 동안 스레드가 점유시간 추가 발생
- Thread Pool이 모두 코드 실행에 소비 될 가능성
- Thread Blocking
- SandBox 환경을 실행하기 위해 외부 프로세스를 실행
- 메트릭 정보 수집으로 인한 File I/O
- Interrupt 발생 요소가 다수
- 성능 저하의 연쇄
- 계속되는 요청
이 문제점들은 API 서버를 Scale-UP 하더라도 근본적으로 해결할 수 없는 문제라서 다른 API 요청이 유실되거나 클라이언트 입장에서 서버가 다운되는 사용자 경험에 치명적인 문제점을 제공할 수 있습니다. 또, 핵심 기능인 코드 실행 자체가 안되는 문제점을 발생할 수 있습니다.
코드 실행 통신 방식을 재구성
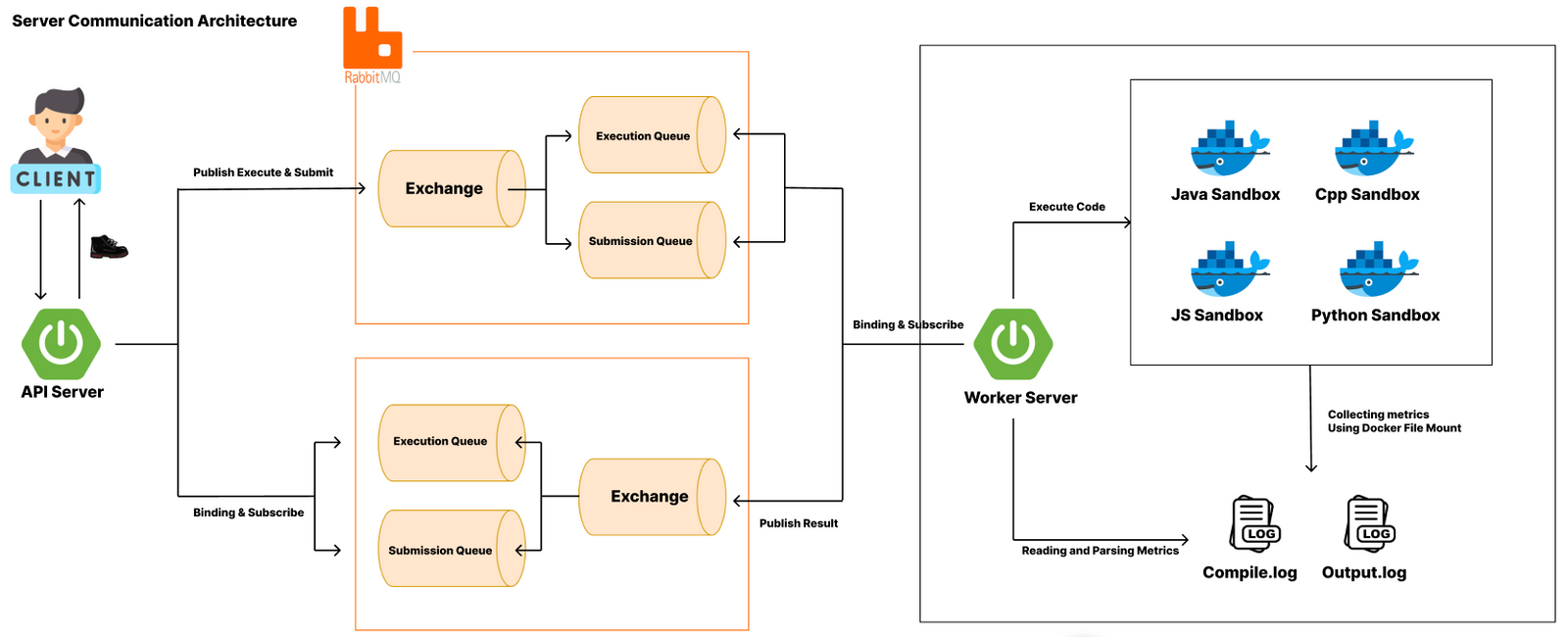 - 서버 통신 아키텍처 -
- 서버 통신 아키텍처 -
- API 서버: 클라이언트의 코드 실행/제출 요청을 받고 메시지 큐에 전달
- RabbitMQ: API 서버와 Worker 서버 간의 비동기 통신을 담당
- Worker 서버: 다양한 언어의 코드를 Docker 샌드박스 환경에서 안전하게 실행하고 결과를 반환
통신 아키텍쳐가 변경되면서 서버에서 코드 실행 처리 과정도 자연스레 변경됩니다.
재구성된 코드 실행 프로세스
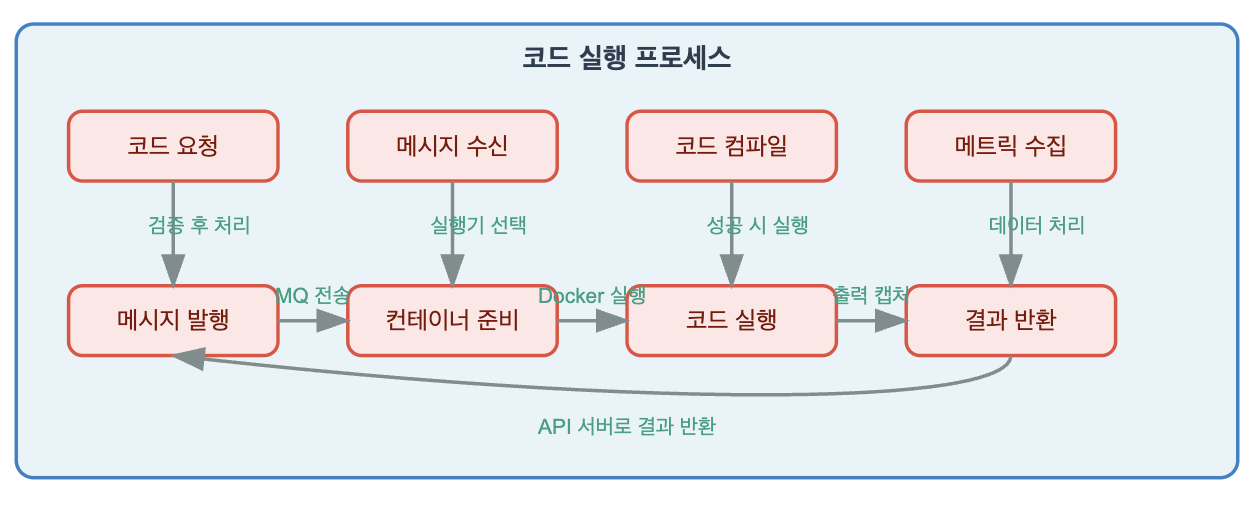 - Code Executor Logic Refactoring -
- Code Executor Logic Refactoring -
기존 API 서버
- 코드 실행 처리 요청을 위한 메시지 발행
- 코드 실행 처리 응답을 위한 메시지 구독
- 코드 실행 결과 Client에게 전달
분리된 Worker 서버
- 코드 실행 처리를 위한 메시지 구독
- 기존의 코드 실행 로직은 그대로
- 코들 실행 결과 전달을 위한 메시지 발행
전체적으로 코드 실행을 위한 아키텍쳐를 재구성하면서 기존의 문제점을 해결했습니다.
문제점 해결
Messaging Queue를 도입해 메세지를 구독하는 방식으로 처리하면서 기존의 문제점을 해결 할 수 있었습니다.
메모리 점유
- Messaging Queue의 특성: FIFO
- 여러 코드 실행 요청 발생: 구독한 메세지를 순차적으로 처리
- 처리되지 않은 코드: Messaging Queue에 저장되어 있음.
- 코드 실행 유실: 큐가 꽉 차지 않는 이상 전혀 없음. 언젠가는 처리
결과적으로 API Server의 OOM, 요청 유실, Down 문제를 모두 해결 가능
스레드 점유
- 동기 처리 방식: 비동기 처리로 개선
- Thread Blocking: Worker Server에서 처리
결과적으로 API 서버는 코드 실행 요청이 많이 발생해도 메시시 발행을 위한 짧은 시간의 스레드를 점유하고, Thread Blocking 요소를 Worker Server로 분리하면서 API 서버의 스레드 점유 문제를 해결했습니다.
✅ 기존의 문제점은 Scale-up으로도 해결 할 수 없었지만, 재구성한 방식은 기존의 문제점을 모두 해결했고 추가적으로 Scale-out을 통해 독립적으로 확장할 수 있는 아키텍처로 개선되었습니다. 다만, 바뀐 방법에서 새로운 문제점을 발견했습니다. 이어서 작성하겠습니다.
5. Code Executor Parallel Processing
새로운 문제점 식별
기존의 코드 실행 방식은 병렬 처리가 되었으나, 아키텍쳐를 변경하면서 병렬 처리가 되지 않는 문제점이 발생했습니다. 문제점의 원인은 Spring Boot의 자동 구성 설정 때문입니다. Messaging Queue의 FIFO 구조이고 Spring Boot의 Rabbit MQ 자동 구성은 하나의 구독 당 하나의 메세지만 처리하도록 설정된 것 입니다.
 - Worker Server Resource (before) -
- Worker Server Resource (before) -
worker server는 t3.small 인스턴스를 사용 중 입니다. top 명령을 통해 자원 사용량을 식별한 결과 CPU의 사용률이 7.8%, idle time 비율이 81.6%인 것을 확인 할 수 있습니다. 즉, CPU를 제대로 활용하지 못하고 있습니다.
해결 방법
해결 방법은 간단했습니다. Spring Boot에서 Rabbit MQ의 메세지 처리 수를 수정하면 되는 것입니다.
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(
final ConnectionFactory connectionFactory,
final MessageConverter messageConverter,
final RabbitProperties rabbitProperties
) {
final SimpleRabbitListenerContainerFactory containerFactory = new SimpleRabbitListenerContainerFactory();
containerFactory.setConnectionFactory(connectionFactory);
containerFactory.setMessageConverter(messageConverter);
final RabbitProperties.SimpleContainer simple = rabbitProperties.getListener().getSimple();
containerFactory.setConcurrentConsumers(simple.getConcurrency());
containerFactory.setMaxConcurrentConsumers(simple.getMaxConcurrency());
containerFactory.setPrefetchCount(simple.getPrefetch());
return containerFactory;
}다양한 방법이 있겠지만, 저는 코드 레벨에서 매번 수정하고 배포하는 것보다는 worker 서버에서 재실행 할 때마다 환경 변수만 수정하면 편할 것 같아 config에서 설정했습니다.
소비자 설정 전략
단순히 rabbit MQ config에서 consumer 설정을 아무 값으로 한다면, 기존 방식과 똑같이 OOM이 발생하면서 일부 코드 실행이 유실되는 문제가 발생하거나 Sandbox가 Kill 되면서 오류가 발생했다는 응답을 받게 될 것 입니다.
값을 어떻게 조정해야 될까요?
- 현재 자원을 먼저 알아보기
- Wokrer 서버 환경: Ec2 T3.small의 단일 인스턴스
- Resource: 2v CPU, 2Gb RAM 지원
- top 명령을 통한 가용 ram 확인
- Avail Mem: 약 1.1GB
- Wokrer 서버 환경: Ec2 T3.small의 단일 인스턴스
- 소비자 수 설정하기
- CPU 관점
- 2vCPU → 이론적으로 스레드 2~4개가 가장 효율적
- 실행기 관점
- 대부분 I/O Bound + 최대 2초 CPU Bound
- Avail Mem: 약 1.1GB
- 실행기 최대 Memory 128MB, maxConcurrency = 8
- CPU 관점 vs 실행기 관점
- compute-intensive 작업이면 maxConcurrency = 2~4가 맞음
- 코드 실행기는 I/O + wait이 대부분 -> 스케줄링 활용
- 정상적인 경우 2초 이내 종료 → 실제 CPU 사용률이 짧고 강하지 않음
- CPU 경합이 적을 것으로 예상 -> maxConcurrency = 8
- 기본 소비자: 4, 최대 소비자: 8개
- CPU 관점
- prefetch는 traffic에 따른 수정이 필요.
- 초기(사용자 적음) - 단일 스레드에서 처리해도 문제 없음.
- 중기(사용자 적당) - prefetch를 통해 mq 통신 감소
- prefetch: 현재는 개인적인 생각으로 2 정도가 적당하다고 판단
 - Worker Server Resource (after) -
- Worker Server Resource (after) -
설정 전
- CPU idle: 81.6% (CPU 대부분 놀고 있음)
- 사용자 프로세스(us): 7.8% (코드 실행이 1개만 되고 있는 것)
- 시스템(sy): 2.0%
- 부하 평균: 0.58, 0.22, 0.07 (낮음)
- 총 메모리: 1910.7 MiB
- 사용 중 메모리: 753.2 MiB
- 버퍼/캐시: 1121.4 MiB
- 여유 메모리: 240.2 MiB
- 가용 메모리: 1157.5 MiB
설정 후
- CPU idle: 0.0% (CPU 완전히 활용됨, 최대 소비자 수 낮추기 고려)
- 사용자 프로세스(us): 80.8% (코드 실행이 전체 다 실행 됨)
- 시스템(sy): 7.3%
- 부하 평균: 1.81, 0.44, 0.15 (더 높아짐)
- 총 메모리: 1910.7 MiB
- 사용 중 메모리: 818.1 MiB (↑ 64.9 MiB 증가)
- 버퍼/캐시: 1162.8 MiB (↑ 41.4 MiB 증가)
- 여유 메모리: 134.1 MiB (↓ 106.1 MiB 감소)
- 가용 메모리: 1092.5 MiB (↓ 65 MiB 감소)
결과적으로 CPU 측면에서 소비자 전략 설정 전에는 서버의 CPU idle 시간이 81.6%로 리소스가 대부분 활용되지 않고 있었습니다. 동시 소비자 수를 조정한 후에는 CPU idle이 0%가 되어 CPU가 전체적으로 활용되고 있음을 확인할 수 있습니다. 특히 사용자 프로세스 사용률이 7.8%에서 80.8%로 크게 증가한 것이 눈에 띕니다.
메모리 측면에서 사용 중인 메모리가 약 65MB 증가했고 더 많은 프로세스가 활성화된 것을 확인할 수 있습니다. 버퍼/캐시도 약간 증가했는데, 이는 더 많은 I/O 작업이 발생하고 있음을 의미합니다.
고민 포인트
하지만, 이대로 사용해도 되는가?를 고민해봐야 합니다. 이론적으로는 이렇게 리소스를 최대한 활용하는 것이 효율적이지만, 실제 운영 환경에서는 몇 가지 고려사항이 있습니다.
- AWS 정책 중 하나인 T3.small 인스턴스의 CPU 크레딧 소진 여부를 고려해 C타입으로 전환이 필요할 수 있습니다. (steal time: 11.8%이 높은 점)
- 코드 실행이 목적인 Worker의 특성상 Time Out으로 인한 Idle Time이 0인 것은 당연할 수 있지만, 이는 Time Out을 바탕으로 확인한 결과이므로 다양한 케이스가 존재합니다.
- 코드 실행 Worker 특성 상 계속 되는 Time Out 코드 실행이 요청 될 때, 메시지 밀림 현상은 불가피합니다.
그럼, 운영 환경을 위해서 어떻게 해야 될까?
- 부하 테스트
- JMeter, Locust의 도입이 필요한 상황입니다.
- 지속 부하테스트를 통해 안정적인지 확인해야 합니다.
- CPU가 전체적으로 사용되고 있으므로 RPS가 느려질 수 있음을 암시합니다.
- 실 사용자 기반 모니터링
- ELK, Prometheus 등 모니터링의 도입이 필요한 상황입니다.
- 모니터링을 통해 Worker의 CPU, Memory를 분석합니다.
- 목표 QPS(Queries Per Second) 설정
- 모니터링을 통해 코드 실행 트래픽을 보고 QPS를 설정합니다.
- 시스템 확장
- 트래픽 증가로 인한 높은 QPS를 필요하다면 확장해야합니다.
- Worker Server는 독립적으로 Scale-out이 가능한 구조입니다.
- 설정한 QPS를 만족하도록 독립적으로 Scale-out합니다.
결과 (Result)
코드 실행기 구현을 진행하면서 다양한 기술적 도전과 문제 해결 과정을 경험했습니다. 결과적으로 목표치 달성과 문제 해결력 증진, 기술 스택에 대한 이해도 증진, 다양한 기술의 도입이 필요한 상황들을 이해하게 되었습니다.
다음과 같은 목표를 달성했습니다.
안전한 코드 실행 환경 구축
- Docker Sandbox 환경을 통해 악의적인 코드로부터 시스템을 보호
- 다양한 코드 실행 결과(성공, 컴파일 에러, 런타임 에러, 타임아웃, OOM)에 대한 견고한 처리 로직 구현
정확한 메트릭 정보 수집
- 실행 시간과 메모리 사용량을 정확히 측정하는 방법 개발
- 컴파일과 실행 과정을 분리하여 더 정확한 메트릭 수집 구현
서버 아키텍처 개선
- API 서버와 Worker 서버 분리를 통한 확장성 확보
- RabbitMQ를 활용한 비동기 메시지 처리로 API 서버 부하 감소
- 코드 실행 요청 유실 문제 해결
병렬 처리 최적화
- Worker 서버의 리소스 활용률 크게 향상 (CPU idle: 81.6% → 0%)
- 동시 소비자 설정을 통한 처리량 증가
- 서버 자원을 효율적으로 활용하는 전략 수립
운영 안정성 확보를 위한 기반 마련
- 부하 테스트, 모니터링 도입 필요성 식별
- 시스템 확장 전략 수립
이 프로젝트를 통해 얻은 가장 큰 교훈은 단순히 기능 구현에서 그치지 않고, 서버 자원의 효율적 활용과 확장성을 고려한 아키텍처 설계의 중요성입니다. 처음에는 단순히 코드를 실행하는 기능을 구현하는 것에 집중했지만, 실제 운영 환경에서의 문제점을 식별하고 해결하는 과정에서 더 견고하고 확장 가능한 시스템을 구축할 수 있었습니다.
향후 계획으로는 더 많은 사용자와 코드 실행 요청을 처리할 수 있도록 부하 테스트를 진행하고, 모니터링 시스템을 도입하여 실시간으로 시스템 상태를 파악할 수 있는 환경을 구축할 예정입니다. 또한 필요에 따라 Worker 서버를 독립적으로 확장하는 자동화 시스템도 고려하고 있습니다.
코드 실행기 구현 과정은 백엔드 시스템 설계 및 최적화에 대한 실질적인 경험을 제공했으며, 특히 부하가 많은 시스템을 어떻게 효율적으로 관리할 수 있는지에 대한 통찰력을 얻을 수 있었습니다.
2. Domain Business Logic
상황 (Situation)
코코무(Cocomu) 프로젝트는 코딩 스터디 플랫폼으로 스터디 관리 및 코딩 스페이스 관리 시스템을 구현해야 했습니다. 사용자들이 스터디를 생성하고, 관리하고, 참여하는 일련의 과정과 코딩 스페이스를 생성하고 참여하는 로직이 필요했습니다. 단순한 CRUD 작업을 넘어서 추가적인 비즈니스 규칙과 상태 관리가 요구되었습니다. 특히 생성자(리더)와 참여자(멤버)의 권한이 명확히 구분되어야 했고, 비즈니스의 상태 변화에 따른 일관성 있는 데이터 처리가 필요했습니다.
과제 (Task)
도메인 비즈니스 로직 구현의 과정은 아래와 같습니다.
- 도메인 설계
- 도메인 응집성을 고려한 비즈니스 로직 구현
- JPA 성능 개선
행동 (Action)
비즈니스 로직의 이해도를 높이는 다이어그램을 작성하면서 문제를 해결해나갔습니다.
1. 도메인 설계
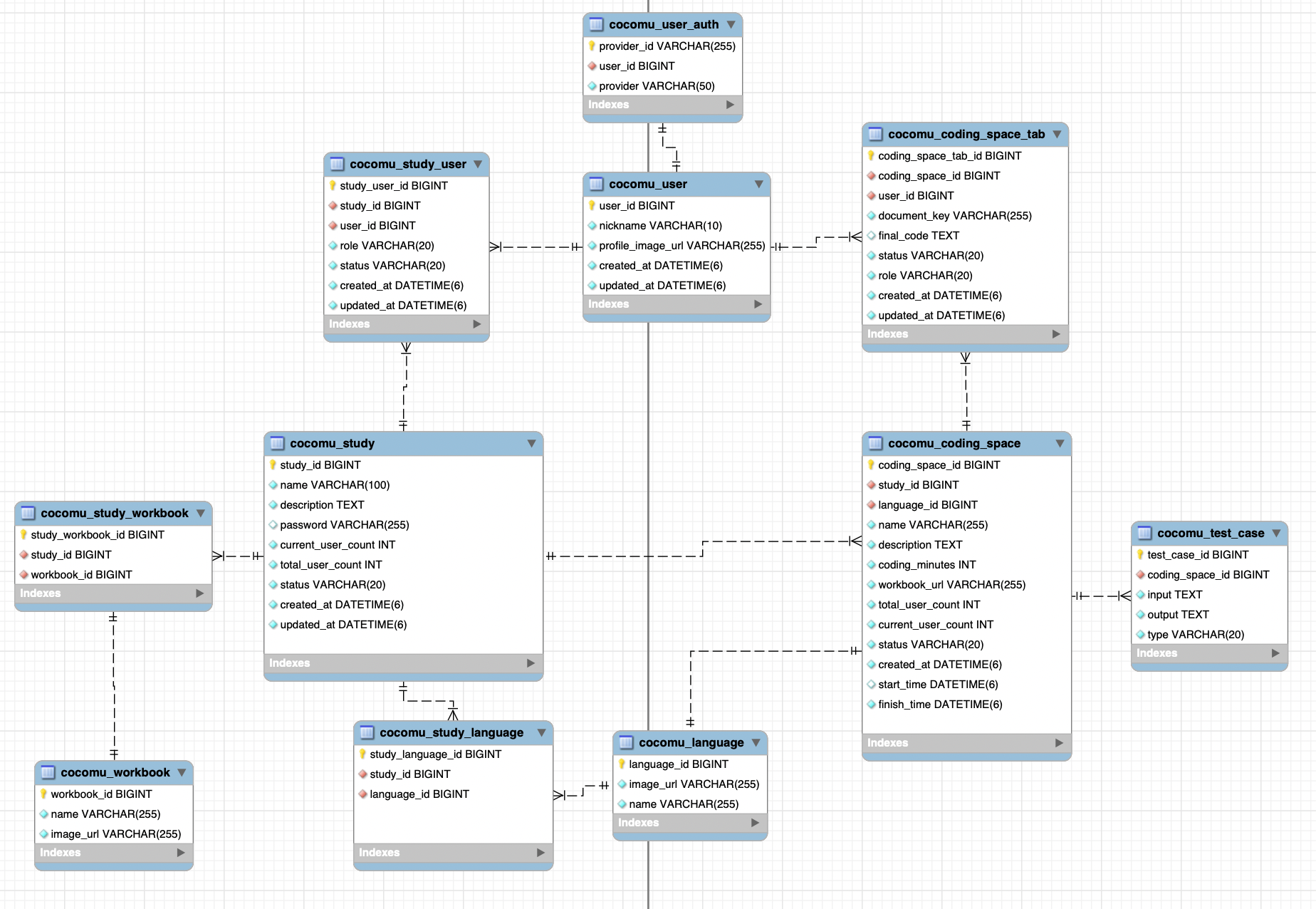 그림 1. 코코무 도메인 ERD
그림 1. 코코무 도메인 ERD
@Entity
@Table(name = "cocomu_study")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor(access = AccessLevel.PROTECTED)
@Getter
public class Study extends TimeBaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "study_id")
private Long id;
@Column(nullable = false)
private String name;
private String password;
@Lob
@Column(nullable = false)
private String description;
@Enumerated(value = EnumType.STRING)
@Column(nullable = false)
private StudyStatus status;
@Column(nullable = false)
private int currentUserCount;
@Column(nullable = false)
private int totalUserCount;
}@Entity
@Table(name = "cocomu_coding_space")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor(access = AccessLevel.PROTECTED)
@EntityListeners(AuditingEntityListener.class)
@Getter
public class CodingSpace {
private static final int MIN_CODING_SPACE_USER_COUNT = 2;
private static final int MAX_CODING_SPACE_USER_COUNT = 4;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "coding_space_id")
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "study_id", foreignKey = @ForeignKey(ConstraintMode.NO_CONSTRAINT))
private Study study;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "language_id", foreignKey = @ForeignKey(ConstraintMode.NO_CONSTRAINT))
private Language language;
@Lob
@Column(nullable = false)
private String description;
private String workbookUrl;
private int codingMinutes;
private int currentUserCount;
private int totalUserCount;
@Enumerated(EnumType.STRING)
@Column(nullable=false)
private CodingSpaceStatus status;
@CreatedDate
@Column(nullable = false)
private LocalDateTime createdAt;
private LocalDateTime startTime;
private LocalDateTime finishTime;
}먼저, 작성한 ERD를 기반으로 도메인 별 Entity를 작성했습니다.
2. 도메인 응집성을 고려한 비즈니스 로직
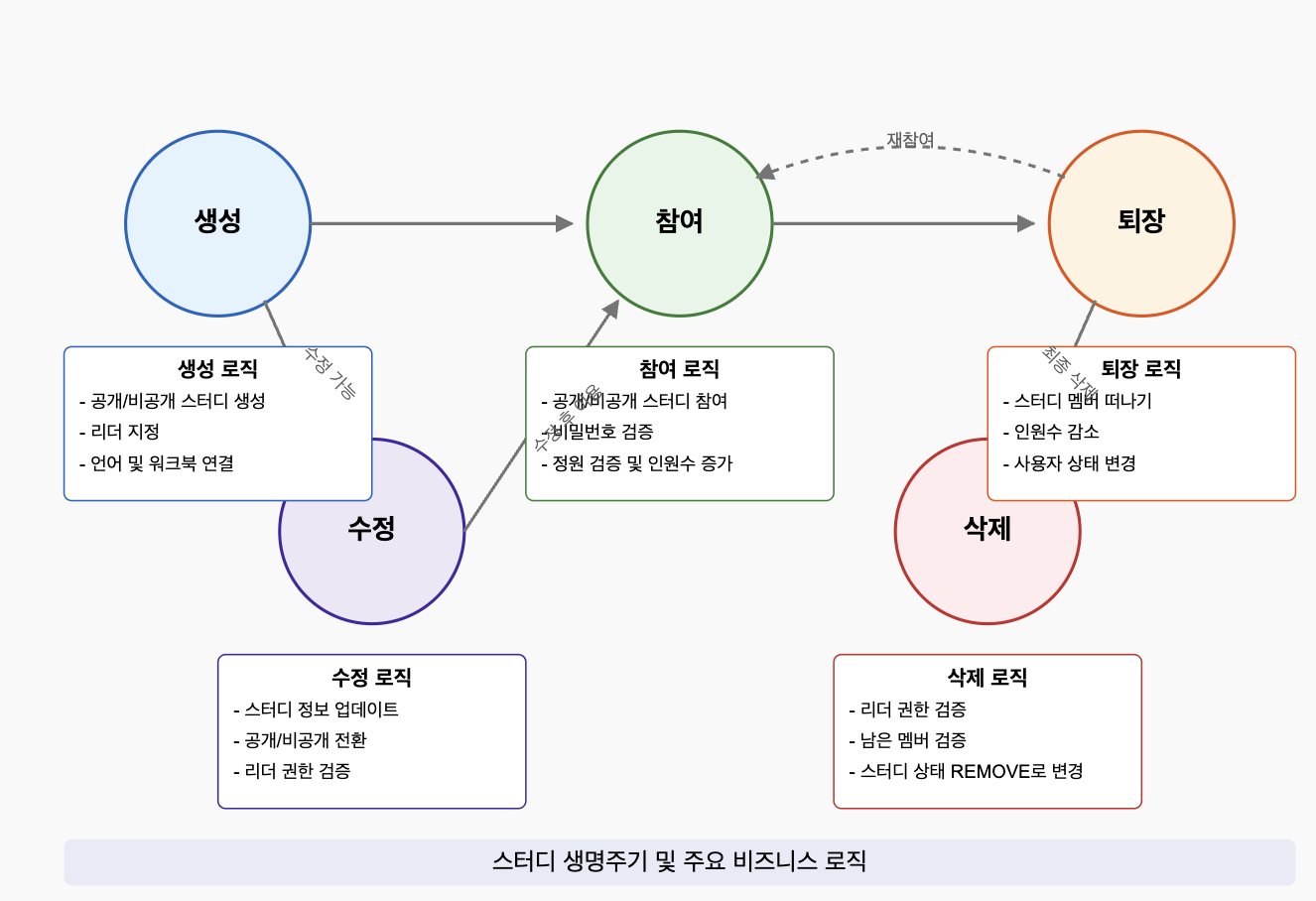 그림 2. Study Life Cycle
그림 2. Study Life Cycle
|
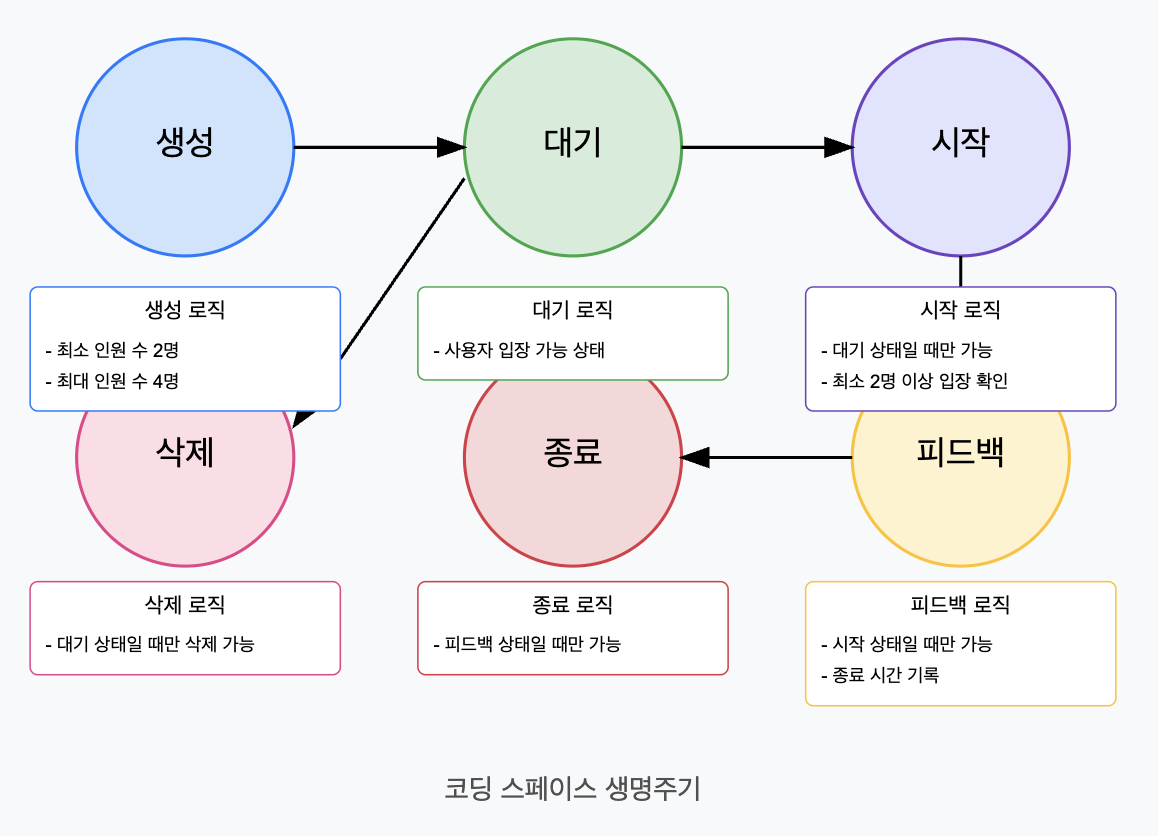 그림 3. CodingSpace Life Cycle
그림 3. CodingSpace Life Cycle
|
먼저, 핵심 도메인 별 정의한 기능에 대해 비즈니스 규칙을 포함한 State Diagram을 작성하고 도메인 별 비즈니스 로직을 작성했습니다.
실제 Study는 StudyMembership과 같은 다양한 애그리게이트 멤버로 구성됩니다. 외부 서비스에 의존하지 않고 순수한 비즈니스 로직만 존재하므로 바운디드 컨텍스트 내 기능 별 상태 변화에 따른 다이어그램을 작성했습니다.
CodingSpace 또한 다른 애그리게이트 멤버가 포함되어 구성되지만, STOMP 기반 SSE 이벤트 발행 로직이 있어 순수한 비즈니스 로직에 대한 상태 변화 다이어그램만 작성했습니다. CodingSpace 알림 시스템에서 추가적으로 작성하겠습니다.
// Study Aggregate
@OneToMany(mappedBy = "study", cascade = CascadeType.ALL, orphanRemoval = true)
private List<StudyUser> studyUsers = new ArrayList<>();
@OneToMany(mappedBy = "study", cascade = CascadeType.ALL, orphanRemoval = true)
private List<StudyWorkbook> workbooks = new ArrayList<>();
@OneToMany(mappedBy = "study", cascade = CascadeType.ALL, orphanRemoval = true)
private List<StudyLanguage> languages = new ArrayList<>();
public void joinMember(final User user) {
validateStudyUserCount(this.totalUserCount);
validateLeaderExists();
studyUsers.stream()
.filter(studyUser -> studyUser.getUser().equals(user))
.findFirst()
.map(StudyUser::reJoin)
.orElseGet(() -> joinNewMember(user));
}
private StudyUser joinNewMember(final User user) {
final StudyUser memberUser = StudyUser.createMember(this, user);
this.studyUsers.add(memberUser);
increaseCurrentUserCount();
return memberUser;
}
// 이외에 비즈니스 로직들현재 작성된 코드는 Study Domain의 비즈니스 로직입니다. 현재 코드를 보면, Study(애그리게이트 루트)가 StudyUser(내부 엔티티)를 처리하므로 애그리게이트 루트를 통해 내부 엔티티를 처리한다는 DDD(Domain Driven Design)의 사상을 바탕으로 작성되었습니다. 양방향 매핑을 활용해 루트에서 애그리게이트 멤버를 처리하면서 높은 도메인 응집성을 고려하고 초기 MVP 구현에 적합한 높은 생산성을 획득했습니다.
//codingSpace Aggregate
@OneToMany(mappedBy = "codingSpace", cascade = CascadeType.ALL, orphanRemoval = true)
private List<TestCase> testCases = new ArrayList<>();
@OneToMany(mappedBy = "codingSpace", cascade = CascadeType.ALL, orphanRemoval = true)
private List<CodingSpaceTab> tabs = new ArrayList<>();
public void start() {
validateStartStatus();
validateEnteredUserCount();
status = CodingSpaceStatus.RUNNING;
startTime = LocalDateTime.now();
}
// 이외에 비즈니스 로직들마찬가지로 CodingSpace 또한 Study와 동일합니다. 결과적으로 도메인에서 너무 많은 책임으로 인해 긴 코드가 작성되었습니다.
우테코 최종테스트 메일에 전달되는 내용 중 동작이 안되는 코드보다 돌아가는 쓰레기 코드가 낫다. 라는 말이 있습니다. 우선은 도메인 별 책임에 의해 동작이 되도록했고 이는 리팩토링 과정에서 개선할 수 있는 부분으로 판단하고 이후에는 예상 범위 내 성능을 개선을 적용했습니다.
3. JPA 성능 최적화
생산성을 높이기 위한 양방향 매핑 방식은 컬렉션 조회에서 악명 높은 JPA의 N+1 문제를 발생시켰습니다.
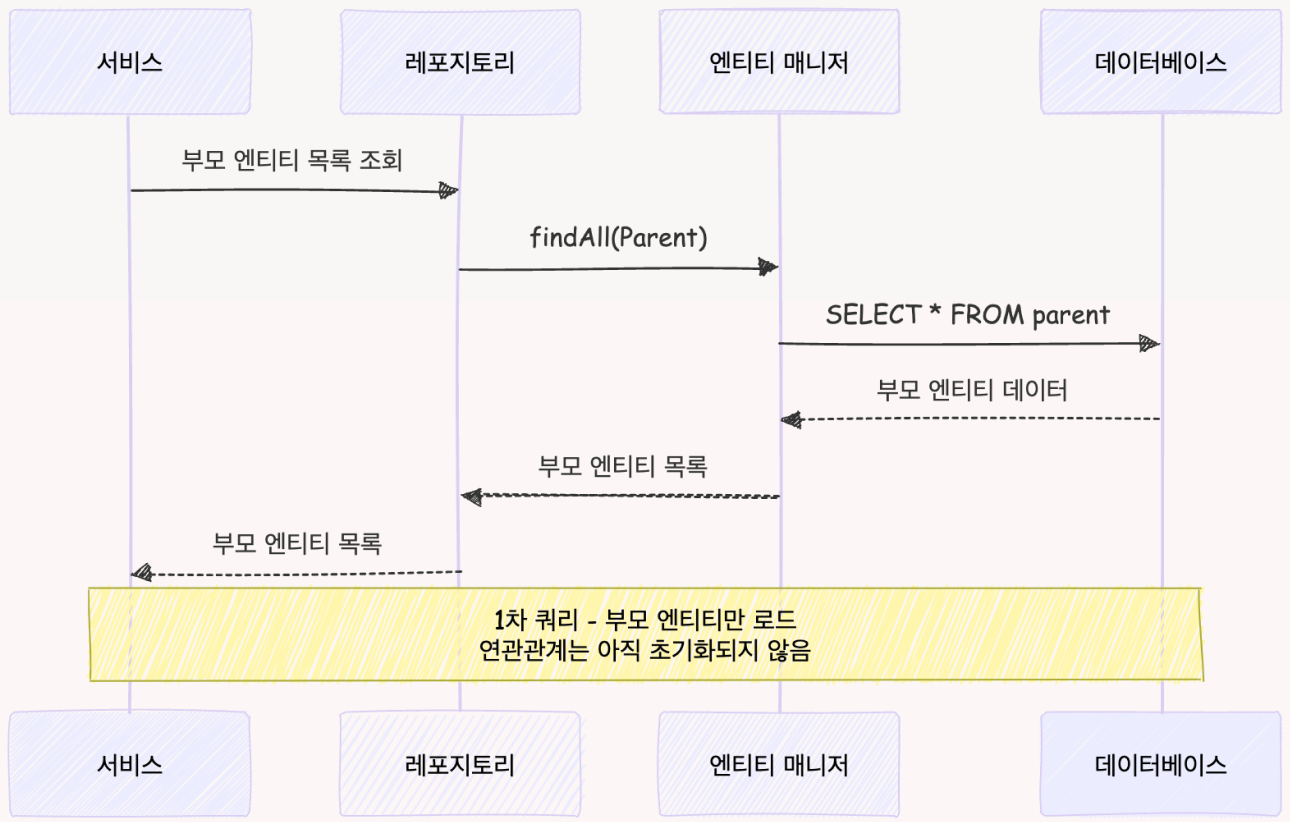 1차 쿼리 조회 순서
1차 쿼리 조회 순서
|
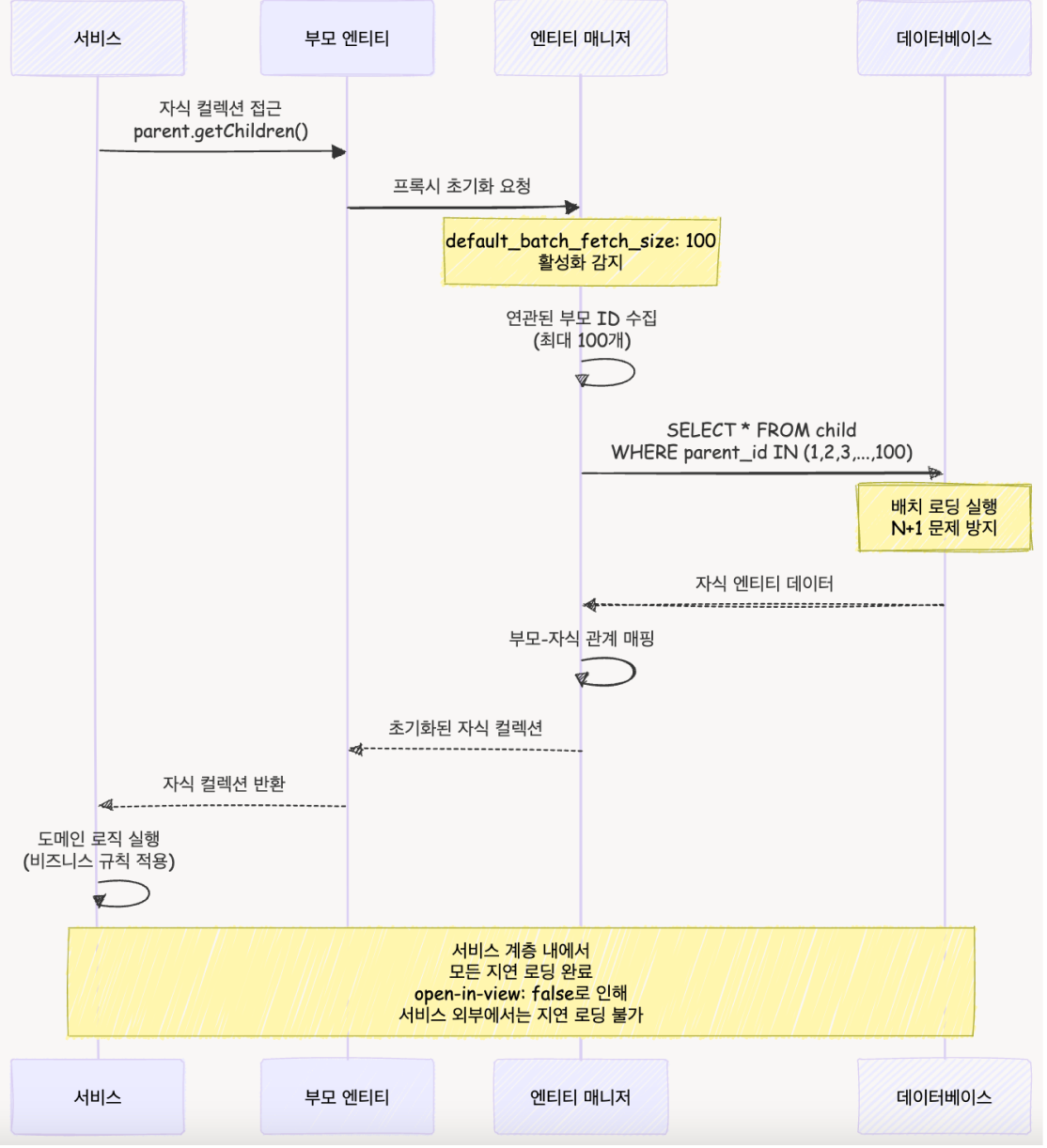 컬렉션 조회 시 순서
컬렉션 조회 시 순서
|
스터디 참여 로직을 시뮬레이션해서 직접 문제 상황을 확인하겠습니다.
문제 상황 시뮬레이션
select su1_0.study_id,su1_0.study_user_id,su1_0.created_at,su1_0.role,su1_0.status,su1_0.updated_at,su1_0.user_id from cocomu_study_user su1_0 where su1_0.study_id=1;
2025-04-18T10:55:00.461+09:00 INFO 26328 --- [nio-8080-exec-3] p6spy : #1744941300461 | took 0ms | statement | connection 7| url jdbc:h2:mem:test
select u1_0.user_id,u1_0.created_at,u1_0.nickname,u1_0.profile_image_url,u1_0.updated_at from cocomu_user u1_0 where u1_0.user_id=2;
...
2025-04-18T10:55:00.461+09:00 INFO 26328 --- [nio-8080-exec-3] p6spy : #1744941300461 | took 0ms | statement | connection 7| url jdbc:h2:mem:test
select u1_0.user_id,u1_0.created_at,u1_0.nickname,u1_0.profile_image_url,u1_0.updated_at from cocomu_user u1_0 where u1_0.user_id=32;
2025-04-18T10:55:00.482+09:00 INFO 26328 --- [nio-8080-exec-3] p6spy : #1744941300482 | took 0ms | statement | connection 7| url jdbc:h2:mem:test
insert into cocomu_study_user (created_at,role,status,study_id,updated_at,user_id,study_user_id) values ('2025-04-18T10:55:00.475+0900','MEMBER','JOIN',1,'2025-04-18T10:55:00.475+0900',1,default);local 환경에서 p6spy library로 직접 sql 로그를 확인한 결과입니다. Study에서 양방향 매핑으로 StudyUser를 불러오고 StudyUser에서 각 user 정보를 한 번씩 더 불러오면서 문제가 발생합니다.
public Long joinPublicStudy(final Long userId, final Long studyId) {
StopWatch stopWatch = new StopWatch();
final User user = userService.getUserWithThrow(userId);
final Study study = studyDomainService.getStudyWithThrow(studyId);
stopWatch.start("N+1 지연 로딩 성능 측정");
study.joinPublicMember(user);
stopWatch.stop();
log.info(stopWatch.prettyPrint());
return study.getId();
}Spring Util에서 제공하는 StopWatch로 이 쿼리의 응답속도를 측정해봤습니다. 인메모리 기반 h2 DB는 성능을 측정하기 힘드므로 MySQL DB로 수정했습니다.
----------------------------------------
Seconds % Task name
----------------------------------------
0.043943667 100% N+1 지연 로딩 성능 측정총 30개의 데이터에서 약 0.044s가 소요되는 것을 확인할 수 있습니다.
select su1_0.study_id,su1_0.study_user_id,su1_0.created_at,su1_0.role,su1_0.status,su1_0.updated_at,su1_0.user_id from cocomu_study_user su1_0 where su1_0.study_id=1;
2025-04-18T09:41:55.621+09:00 INFO 24228 --- [nio-8080-exec-2] p6spy : #1744936915621 | took 0ms | statement | connection 7| url jdbc:h2:mem:test
select u1_0.user_id,u1_0.created_at,u1_0.nickname,u1_0.profile_image_url,u1_0.updated_at from cocomu_user u1_0 where u1_0.user_id in (2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL,NULL);
2025-04-18T09:41:55.640+09:00 INFO 24228 --- [nio-8080-exec-2] p6spy : #1744936915640 | took 0ms | statement | connection 7| url jdbc:h2:mem:test
insert into cocomu_study_user (created_at,role,status,study_id,updated_at,user_id,study_user_id) values ('2025-04-18T09:41:55.630+0900','MEMBER','JOIN',1,'2025-04-18T09:41:55.630+0900',1,default);----------------------------------------
Seconds % Task name
----------------------------------------
0.017521209 100% Batch 로딩 성능 측정이를 해결하기 위해 Hibernate에서 지원하는 batch_fetch_size 옵션을 통해 컬렉션 조회를 최적화해서 성능개선을 했습니다. 결과와 같이 총 30개의 데이터에 대해 User 엔티티의 추가 조회는 batch 옵션으로 in절이 적용되면서 1회로 줄었고, 성능은 약 0.044s -> 0.018s로 개선되었습니다.
하지만, 여전히 양방향 매핑의 문제점은 남아있습니다. StudyUser 리스트에서 각 User를 조회하기 위한 1회의 추가 조회가 발생하는 것입니다. 이것은 단방향 매핑 + fetch Join 혹은 다른 기법을 통해 해결할 수 있지만, MVP 과정에서는 생략하겠습니다.
결과 (Result)
도메인 주도 설계(DDD) 원칙에 따라 스터디와 코딩 스페이스의 생명주기 관리 시스템을 성공적으로 구현했습니다.
구체적인 성과는 다음과 같습니다
도메인 응집성 향상
- 애그리게이트 루트(Study, CodingSpace)를 통해 일관된 비즈니스 규칙 적용
- 각 상태 변화에 따른 명확한 검증 로직 구현으로 데이터 무결성 보장
- 유비쿼터스 언어를 사용한 코드베이스로 비즈니스 도메인을 코드에 명확히 반영
성능 최적화
- N+1 문제 식별 및 해결: 30개 데이터 성능 측정
- 결과 약 60% 향상 (0.044s → 0.018s)
- 최대 효율: 100개의 데이터 더 높은 성능 향상을 기대 가능
- Hibernate의 batch_fetch_size 옵션을 통한 컬렉션 조회 최적화
- 다중 쿼리를 단일 IN절 쿼리로 변환하여 네트워크 오버헤드 감소
확장 가능한 아키텍처
- 상태 다이어그램을 기반으로 한 명확한 도메인 모델 설계
- 후속 기능 추가가 용이한 구조 구축
- 리팩토링 포인트가 명확하게 식별된 코드베이스
추후 개선 방향으로는 단방향 매핑과 fetch join을 통한 추가 최적화, 애그리게이트 경계 재검토를 통한 책임 분산, 그리고 이벤트 기반 아키텍처 도입을 통한 서비스 간 결합도 감소 등이 있습니다. 이러한 개선은 사용자 수가 증가하고 시스템이 확장됨에 따라 단계적으로 적용할 예정입니다.
3. OAuth 2.0 로그인
상황 (Situation)
웹 애플리케이션 '코코무(Cocomu)' 프로젝트에서 사용자 인증 시스템을 구축해야 했습니다. 사용자 경험을 개선하고 보안을 강화하기 위해 외부 서비스(Google, Kakao, GitHub)를 통한 OAuth 2.0 로그인 방식이 필요했습니다. 특히 다양한 서비스와의 연동을 고려하면서, 웹 애플리케이션과 WebSocket, 메시지 큐 등을 함께 사용하는 환경에서 효율적인 인증 시스템이 필요했습니다.
과제 (Task)
다음과 같은 목표를 달성해야 했습니다:
- Google, Kakao, GitHub OAuth2 로그인 연동 구현
- 최초 로그인 시 사용자 정보 저장 및 JWT 발급 시스템 구축
- JWT 인증을 Spring Security 필터 체인 기반으로 처리
- 단일 API 엔드포인트에서 여러 OAuth 제공자 처리
- 보안성 강화를 위한 AccessToken과 RefreshToken 전략 수립
- Stateless 환경에서 안전하고 효율적인 인증 구조 설계
행동 (Action)
1. OAuth 인증 흐름 설계
OAuth 로그인 시퀀스 다이어그램을 작성하고, 전체 인증 프로세스를 4단계로 구분했습니다:
- OAuth Code 요청 및 처리
- 외부 서비스로부터 AccessToken 요청
- 사용자 정보 요청
- 사용자 로그인/회원가입 처리
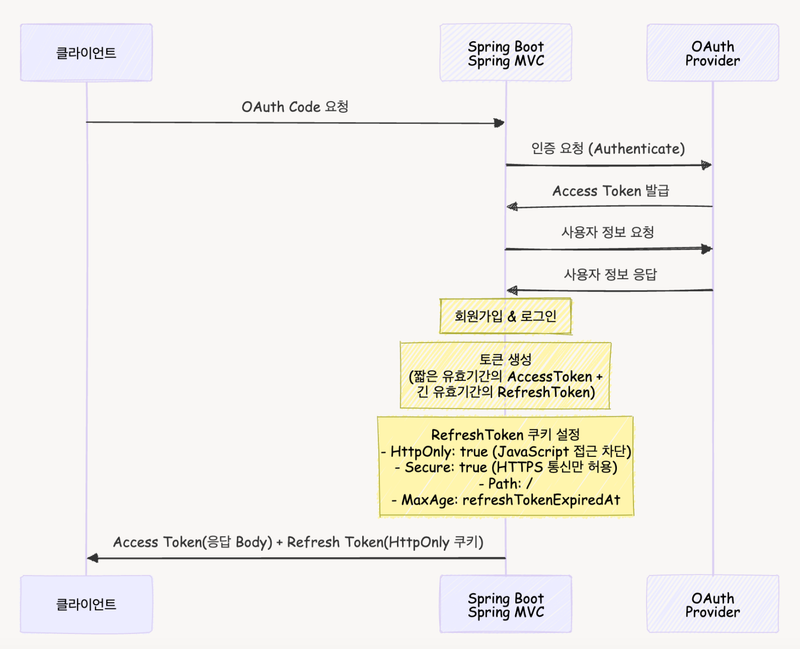 그림 2. OAuth 2.0 인증 시퀀스 다이어그램
그림 2. OAuth 2.0 인증 시퀀스 다이어그램
|
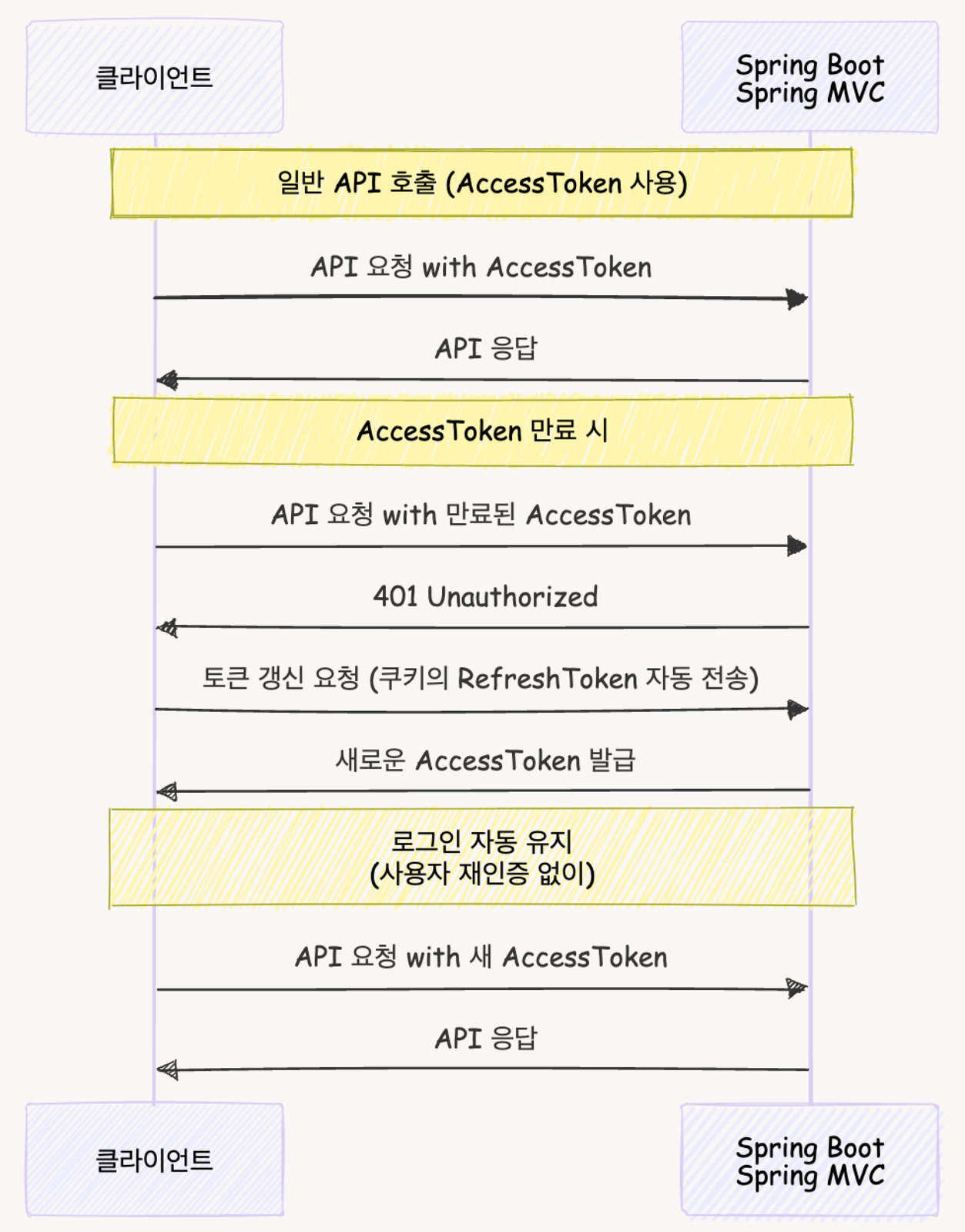 그림 3. Ahthenticate Processing
그림 3. Ahthenticate Processing
|
2. API 엔드포인트 설계
Front-end 팀과 협의하여 각 제공자별 API를 분리하지 않고, 단일 엔드포인트(/oauth-login)에서 provider 파라미터를 통해 분기 처리하는 방식을 선택했습니다.
@PostMapping("/oauth-login")
public Api<AuthResponse> loginWithOAuth2(
@Valid @RequestBody final OAuthRequest request,
final HttpServletResponse response
) {
final Long userId = oAuthLoginByProvider(request, false);
final String accessToken = jwtProvider.issueAccessToken(userId);
final String refreshToken = jwtProvider.issueRefreshToken(userId);
cookieService.setRefreshTokenCookie(response, refreshToken);
return Api.of(AuthApiCode.LOGIN_SUCCESS, new AuthResponse(accessToken));
}3. 외부 서비스 인터페이스 구현
각 OAuth 제공자(GitHub, Kakao, Google)별로 클라이언트를 구현하고, 책임을 명확히 분리했습니다.
- AccessToken을 발급받는 OAuthClient
- 사용자 정보를 요청하는 ApiClient
- 로그인/회원가입 로직을 담당하는 Service
@Component
public class GithubClient {
private final RestClient restClient;
private final String clientId;
private final String clientSecret;
public GithubClient(
@Value("${oauth.github.client-id}") final String clientId,
@Value("${oauth.github.client-secret}") final String clientSecret,
final OAuthClientGenerator generator
) {
this.restClient = generator.generateGithubClient();
this.clientId = clientId;
this.clientSecret = clientSecret;
}
// AccessToken 발급 요청 처리
public TokenResponse getAccessToken(final String code) {
return RestClientExecutor.execute(() -> restClient.post()
.uri("/login/oauth/access_token")
.contentType(MediaType.APPLICATION_FORM_URLENCODED)
.accept(MediaType.APPLICATION_JSON)
.body(FormDataGenerator.generateGithubFormData(clientId, clientSecret, code))
.retrieve()
.body(TokenResponse.class));
}
}
@Component
public class GithubApiClient {
private final RestClient apiClient;
public GithubApiClient(final OAuthClientGenerator generator) {
this.apiClient = generator.generateGitHubApiClient();
}
public GithubUserResponse getUser(final TokenResponse tokenResponse) {
return RestClientExecutor.execute(() -> apiClient.get()
.uri("/user")
.header(HttpHeaders.AUTHORIZATION, tokenResponse.getToken())
.retrieve()
.body(GithubUserResponse.class));
}
}
@Service
@RequiredArgsConstructor
@Transactional
@Slf4j
public class GithubService {
private final UserAuthJpaRepository userAuthJpaRepository;
private final GithubClient githubClient;
private final GithubApiClient githubApiClient;
public Long signupWithLogin(final String oauthCode) {
final TokenResponse tokenResponse = githubClient.getAccessToken(oauthCode);
final GithubUserResponse githubUser = githubApiClient.getUser(tokenResponse);
final String providerId = "GITHUB_" + githubUser.id();
final UserAuth userAuth = userAuthJpaRepository.findById(providerId)
.orElseGet(() -> {
final User user = User.createUser(githubUser.login());
final UserAuth auth = UserAuth.signUp(providerId, user, OAuth2Provider.GITHUB);
return userAuthJpaRepository.save(auth);
});
return userAuth.getUser().getId();
}
}4. 외부 API 호출 예외 처리
외부 서비스 API 호출 시 발생할 수 있는 예외를 효과적으로 처리하기 위해 RestClientExecutor를 구현했습니다.
@Slf4j
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public class RestClientExecutor {
public static <T> T execute(final Supplier<T> apiCall) {
try {
return apiCall.get();
} catch (final HttpClientErrorException e) {
log.error("OAuth Exception: {} - {}", e.getStatusCode(), e.getResponseBodyAsString());
throw new BadGatewayException(AuthExceptionCode.OAUTH_EXCEPTION);
} catch (final Exception e) {
log.error("OAuth Error: {} - {}", e.getClass(), e.getMessage());
throw new BadGatewayException(AuthExceptionCode.OAUTH_ERROR);
}
}
}5. JWT 기반 인증 전략 수립
Session 방식과 Cookie 방식의 한계를 분석하고, JWT 기반 토큰 인증 방식을 선택했습니다.
- AccessToken(짧은 만료 시간)과 RefreshToken(긴 만료 시간) 전략 도입
- AccessToken은 클라이언트 메모리에 저장하고 HTTP 헤더로 전송
- RefreshToken은 HttpOnly + Secure 쿠키로 안전하게 저장
왜 JWT 인증을 채택했을까요?
웹 애플리케이션의 인증 방식에는 대표적으로 Session, Cookie, JWT가 있습니다. 이 중 코코무 프로젝트는 JWT 기반의 토큰 인증 방식을 선택했습니다.
이유는 명확합니다.
WebSocket, RabbitMQ 등에서 발생할 수 있는 세션 관리의 추가 비용을 줄이고,
인증을 stateless하게 처리해 서버 자원 부담을 최소화하기 위해서입니다.
선택 배제: Session 방식
- 서버가 사용자의 로그인 상태를 기억해야 하므로 Stateful
- 수평 확장 시 세션 동기화/공유 부담 발생
- WebSocket 등과 혼합 시 인증 복잡도 증가
왜 JWT인가? (vs Cookie)
- JWT는 자체적으로 사용자 정보를 포함하고 전자 서명되어 위변조가 어렵습니다.
- Cookie 방식도 stateless하긴 하지만, 단순한 세션 ID 전송에 불과하므로
위/변조에 취약하거나 별도 세션 저장소가 필요한 경우가 많습니다. - JWT는 Spring Security 필터 체인 기반에서 유기적으로 통합 처리 가능합니다
| 항목저장 | 위치보안 | 처리 |
|---|---|---|
| AccessToken | 클라이언트 메모리 / 헤더 | JS에서 직접 전송(Bearer) |
| RefreshToken | HttpOnly + Secure 쿠키 | 브라우저에서 접근 불가, HTTPS 전송만 허용 |
String cookieString = ResponseCookie.from("refreshToken", refreshToken)
.httpOnly(true)
.secure(isHttpsEnvironment())
.path("/")
.sameSite("None")
.maxAge(refreshTokenExpiredAt)
.build()
.toString();
response.setHeader("Set-Cookie", cookieString);6. Spring Security 필터 체인 구현
Spring Security를 활용하여 JWT 인증/인가 필터 체인을 구성했습니다.
- JwtExceptionFilter: JWT 처리 중 발생하는 예외 처리
- JwtAuthenticationFilter: JWT 토큰 인증 처리
- AnonymousUserFilter: 인증되지 않은 사용자 처리
@Bean
public SecurityFilterChain defaultSecurityFilterChain(HttpSecurity http) throws Exception {
return http
.securityMatcher("/**")
.addFilterBefore(new JwtExceptionFilter(objectMapper), UsernamePasswordAuthenticationFilter.class)
.addFilterBefore(new JwtAuthenticationFilter(jwtProvider), UsernamePasswordAuthenticationFilter.class)
.addFilterBefore(new AnonymousUserFilter(jwtProvider), UsernamePasswordAuthenticationFilter.class)
.authorizeHttpRequests(auth -> auth.anyRequest().permitAll())
.csrf(AbstractHttpConfigurer::disable)
.cors(Customizer.withDefaults())
.headers(headers -> headers.frameOptions(FrameOptionsConfig::disable))
.build();
}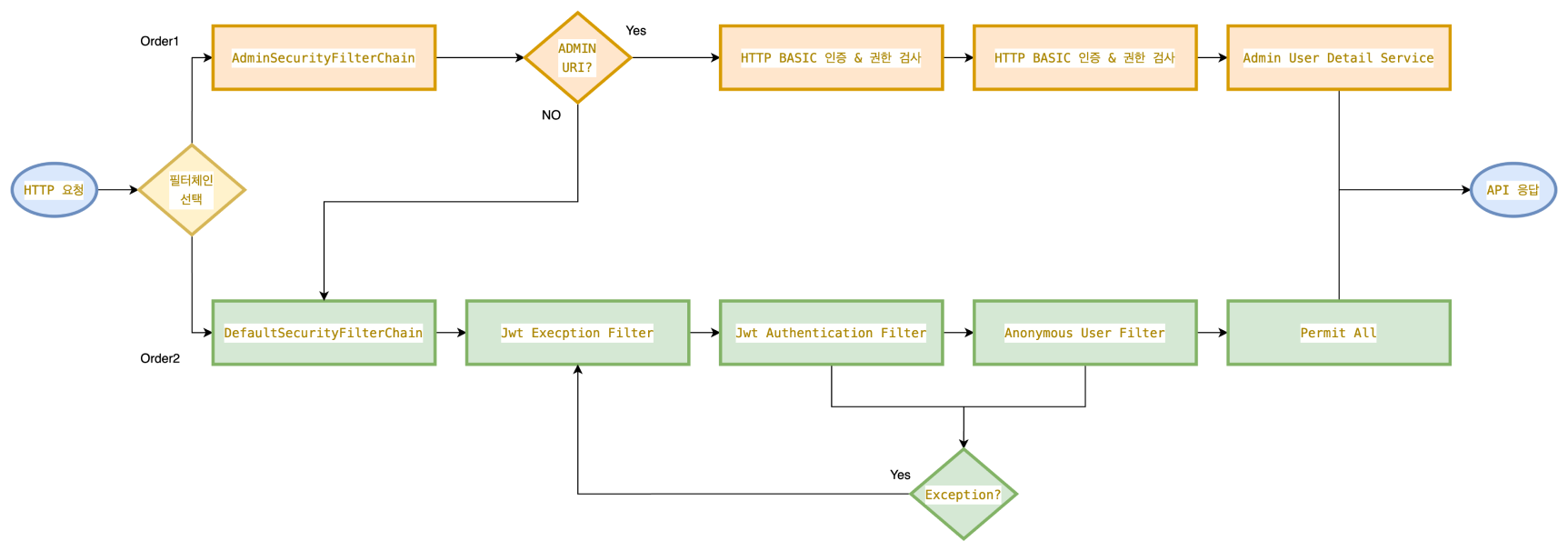 그림 4. FilterChain Flow Chart
그림 4. FilterChain Flow Chart
결과 (Result)
코코무 프로젝트에서는 다음과 같은 성과를 달성했습니다.
- 성공적인 OAuth 2.0 로그인 시스템 구현
- Google, Kakao, GitHub를 통한 외부 서비스 로그인 연동 완료
- 단일 API 엔드포인트로 여러 OAuth 제공자 처리 가능
- 안전하고 효율적인 인증 구조 구축
- JWT 기반 Stateless 인증으로 서버 자원 부담 최소화
- AccessToken과 RefreshToken 전략으로 보안성과 사용자 경험 모두 개선
- RefreshToken을 HttpOnly + Secure 쿠키로 안전하게 보호
- 확장 가능한 아키텍처 설계
- Spring Security 필터 체인을 활용한 유연한 인증/인가 구조
- 향후 Role 기반 인증 등 추가 요구사항에 쉽게 대응 가능
- 외부 서비스 API 호출에 대한 체계적인 예외 처리 구현
- 사용자 경험 개선
- 한 번 로그인하면 RefreshToken을 통해 장기간 로그인 상태 유지
- AccessToken 만료 시 RefreshToken으로 자동 재발급하여 끊김 없는 UX 제공
코코무는 stateless, secure, UX-friendly 인증 전략으로 OAuth 기반 시스템에서 안전하고 효율적인 인증 구조를 성공적으로 구축했습니다. 추가로 JWT를 사용하면서 WebSocket, RabbitMQ 등 다양한 비동기 통신 방식에서도 세션의 불안정성을 감소하고 일관된 인증을 제공하면서, 확장 가능한 아키텍처를 달성했습니다.
4. STOMP 기반 SSE 알림
상황 (Situation)
코코무에서는 Client에게 상황에 따른 STOMP 기반 알림이 발행됩니다.
- 코딩 스페이스에서 스터디원이 입/퇴장에 대한 알림이 발행됩니다.
- 코딩 스페이스에서 방장이 커맨드(
시작 -> 피드백 -> 종료)를 실행할 때마다 페이지 전환을 위한 알림이 발행됩니다. - 코딩 스페이스에서 스터디원이 문제의 히든 테스트 케이스를 발견하고 공유하기 위해 테스트 케이스를 추가할 때, 업데이트를 위해 알림이 발행됩니다.
- IDE에서 입력한 코드를 실행하고 제출 했을 때, Worker 서버에서 처리된 코드 실행 결과를 전달하기 위해 알림이 발행됩니다.
코코무에서는 STOMP 기반 SSE 알림 시스템 구현에 성공했고, 이어서 그 과정을 작성하겠습니다.
과제 (TASK)
STOMP 기반 SSE 알림 시스템 구현 과정
- 코딩 스페이스 알림 구현
- 알림 시스템 보안 처리 추가
행동 (Action)
STOMP 기반 SSE 알림 시스템 구현은 생각보다 쉬운 과제였습니다. 기존의 비즈니스 로직에서 그저 알림 기능만 추가하면 됐습니다.
1. 코딩 스페이스 알림 구현
코딩 스페이스의 핵심 비즈니스 로직은 이미 구현되어 있었고, 각 상황에 따른 알림 이벤트 발행을 추가하면 됩니다.
코딩 스페이스에서 발생하는 알림은 아래와 같습니다.
코딩 스페이스 세션 알림
- 코딩 스페이스 입장
- 코딩 스페이스 퇴장
- 코딩 스페이스 연결 끊김
코딩 스페이스 상태 변화 알림
- 코딩 스페이스 스터디 시작
- 코딩 스페이스 피드백 시작
- 코딩 스페이스 스터디 종료
코딩 스페이스 테스트 케이스 알림
- 테스트 케이스 추가
- 테스트 케이스 제거
코드 실행 결과 알림
- 작성한 코드 실행 결과
- 작성한 코드 제출 결과
단순히 각 비즈니스 로직에 알림 이벤트만 추가하면 되지만, 코딩 스페이스 세션 알림은 다르게 처리해야 했습니다. 다른 알림 시스템들은 API 요청 -> 비즈니스 로직 수행 -> 알림 처리 -> 응답로 처리되지만, 세션 알림은 코딩 스페이스 입장/퇴장 상태를 구분해야 하므로 따로 세션 정보를 관리하는 로직이 필요합니다.
코딩 스페이스 세션 알림 프로세스는 어떻게 진행될까요?
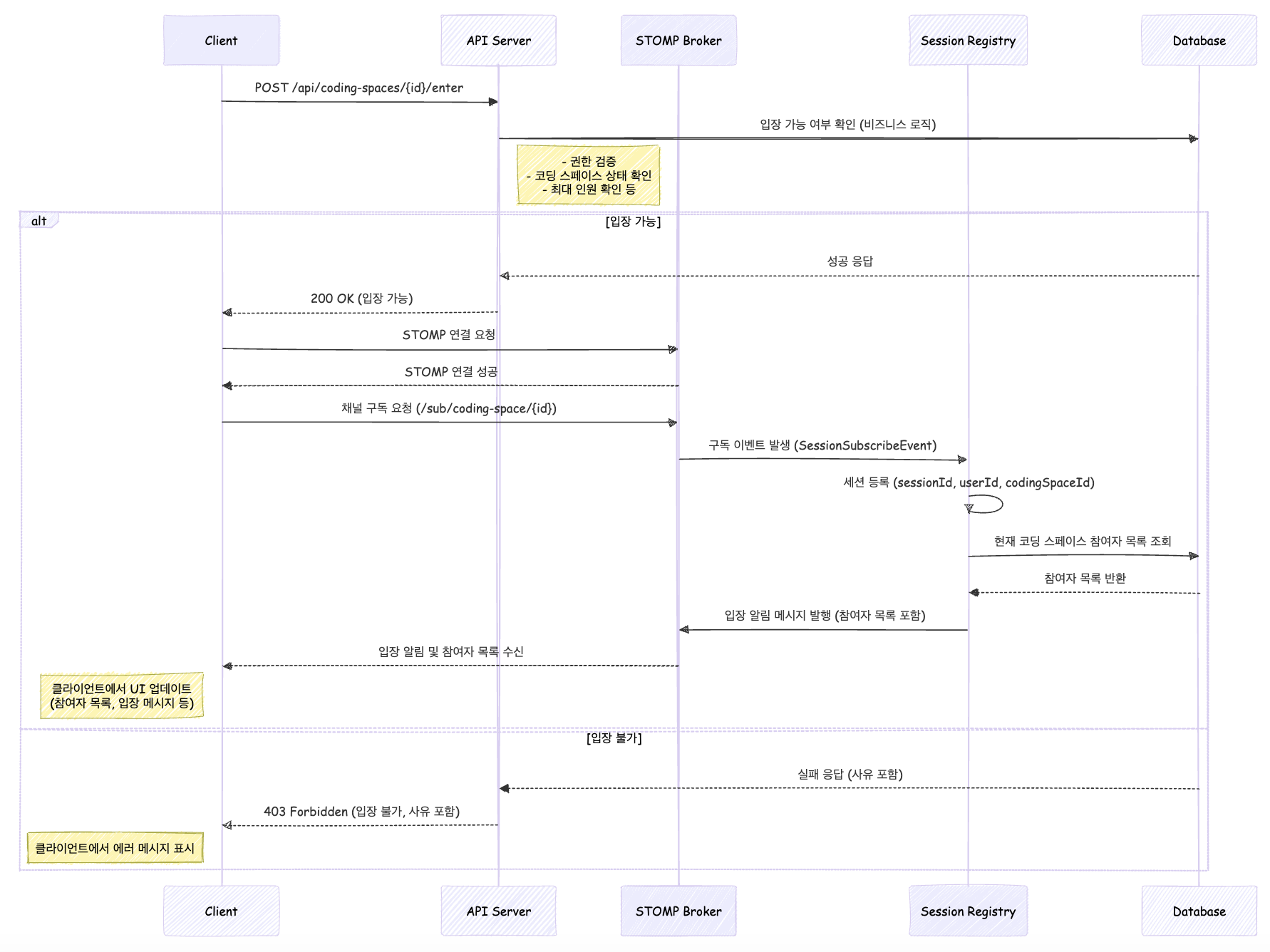 - 코딩 스페이스 세션 입장 프로세스 -
- 코딩 스페이스 세션 입장 프로세스 -
|
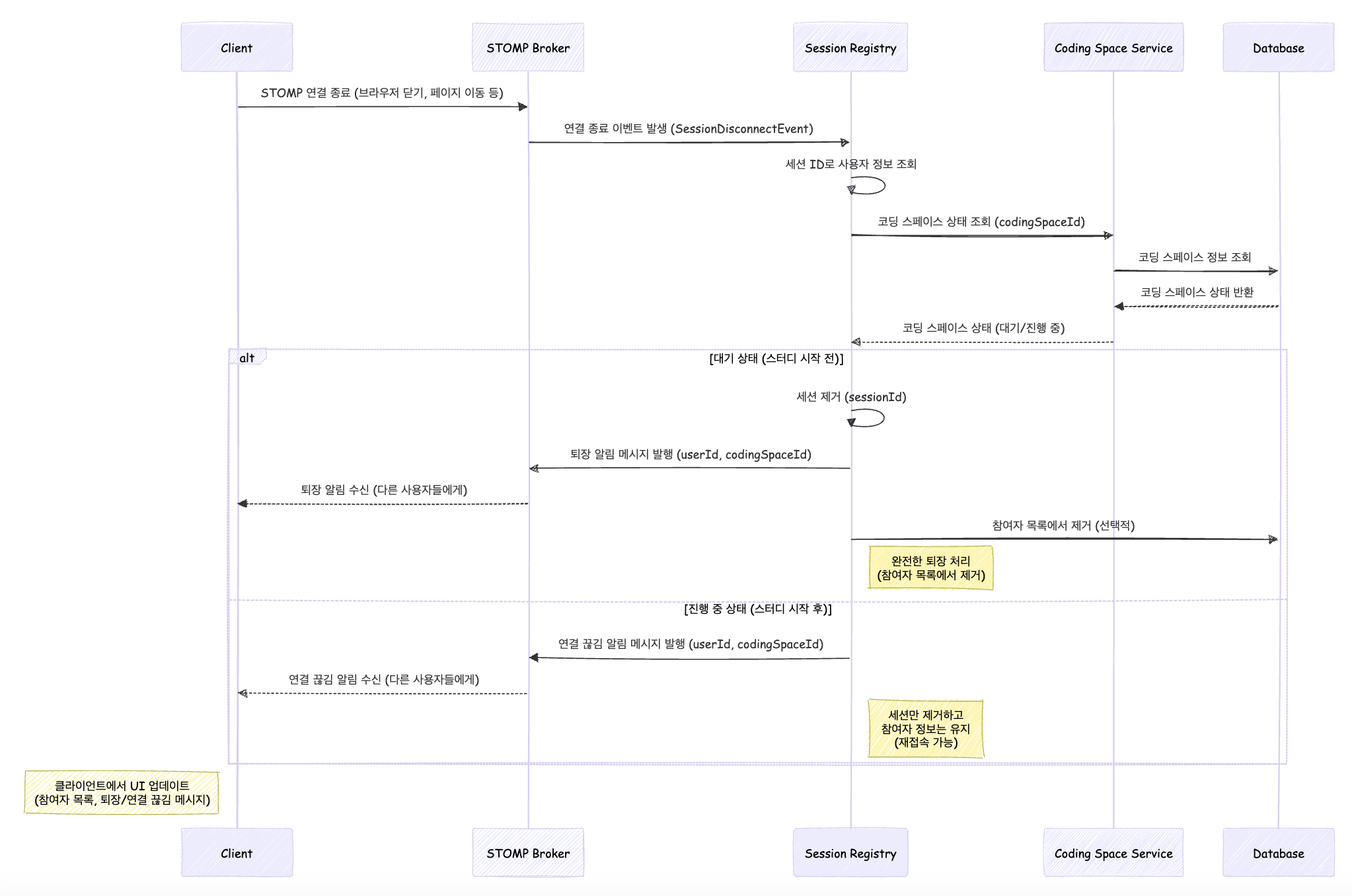 - 코딩 스페이스 세션 퇴장 프로세스 -
- 코딩 스페이스 세션 퇴장 프로세스 -
|
입장 처리는 어떻게 되나요?
기존에 코딩 스페이스 도메인은 코딩 스페이스, 코딩 스페이스 탭으로 구분되어 있습니다. 즉, 코딩 스페이스에 참여하면 코딩 스페이스 탭이 생성되는 것인데 기점이 중요했습니다.
코딩 스페이스에 입장하면 참여한 것인가?, 코딩 스페이스가 시작되면 참여한 것인가? 두 가지 포인트에서 고민을 하게 됐는데 비슷한 사례로 게임 대기방을 떠올랐고 입장과 대기는 세션에서, 스터디가 시작되면 참여하는 방식으로 처리하면서 해결 할 수 있었습니다. 즉, 코딩 스페이스 세션 애그리게이트가 추가됩니다.
코딩 스페이스 입장에는 2가지 처리가 필요합니다.
1. 입장 API 요청 -> 코딩 스페이스 애그리게이트 비즈니스 로직 -> 응답
2. STOMP 세션 연결 -> 대기방 구독 -> 코딩 스페이스 세션 비즈니스 로직 -> 입장 알림 발행
@EventListener
public void handleSubscription(final SessionSubscribeEvent event) {
final StompHeaderAccessor accessor = StompHeaderAccessor.wrap(event.getMessage());
final String sessionId = accessor.getSessionId();
final String destination = accessor.getDestination();
if (sessionId != null && destination != null && destination.startsWith(CODING_SPACE_DEST_PREFIX)) {
final Long userId = extractUserId(accessor);
final Long codingSpaceId = extractCodingSpaceId(destination);
codingSpaceSessionService.enterWaitingSpace(sessionId, userId, codingSpaceId);
}
}퇴장 처리는 어떻게 되나요?
반대로 퇴장에도 추가적인 비즈니스 규칙이 동반되었습니다.
- STOMP 세션 끊김 -> 코딩 스페이스가 시작 중 -> 연결 끊김 -> 퇴장 알림
- STOMP 세션 끊김 -> 코딩 스페이스가 대기 중 -> 퇴장 알림
@EventListener
public void handleDisconnect(final SessionDisconnectEvent event) {
final StompHeaderAccessor accessor = StompHeaderAccessor.wrap(event.getMessage());
final String sessionId = accessor.getSessionId();
if (sessionId != null) {
codingSpaceSessionService.leaveWaitingSpace(sessionId);
}
}다른 비즈니스 알림 시스템은 기존 비즈니스 로직에 그저 추가만 합니다.
// CodingSpace Bounded Context
public void startSpace(final Long codingSpaceId, final Long userId) {
final CodingSpace space = codingSpaceDomainService.getCodingSpace(codingSpaceId);
space.start(userId);
stompSSEProducer.publishStartSpace(codingSpaceId);
}
기존 API는 비즈니스 로직에서 외부 서비스에 알림 발행을 추가합니다.
// Code Executor Bounded Context
@RabbitListener(queues = "${rabbitmq.execution.queue.result}")
public void consumeExecutionMessage(final EventMessage<ExecutionMessage> message) {
stompSseProducer.publishExecutionResult(message);
log.info("코드 실행 결과 전송 완료 = {}", message);
}
@RabbitListener(queues = "${rabbitmq.submission.queue.result}")
public void consumeSubmissionMessage(final EventMessage<SubmissionMessage> message) {
if (message.type() != EventType.SUCCESS) {
stompSseProducer.publishSubmissionResult(message);
return;
}
EventMessage<SubmissionMessage> result = checkAnswer(message.data());
stompSseProducer.publishSubmissionResult(result);
}
private EventMessage<SubmissionMessage> checkAnswer(final SubmissionMessage submissionMessage) {
final ExecutionMessage executionMessage = submissionMessage.executionMessage();
if (executorService.checkAnswer(submissionMessage.testCaseId(), executionMessage.output())) {
return EventMessage.createCorrectMessage(submissionMessage);
}
return EventMessage.createWrongMessage(submissionMessage);
}비동기 처리인 코드 실행/제출은 구독하고 있는 Listener에 알림 발행을 추가합니다. 하지만 이대로는 불안한 포인트가 있습니다. front는 개발자 도구에서 네트워크 탭이나 js 코드 레벨에서 구독하고 있는 stomp의 end point를 알고 있습니다. 즉, 비즈니스 규칙을 눈치챈다면 무단으로 연결해서 다른 사용자의 작업 정보에 영향을 미칠 수 있습니다.
위와 같은 이유로, 의도적으로 코코무에 악의적인 영향을 미칠 수 있다고 판단했고 STOMP에 보안 로직을 추가해야 되겠다는 판단을 했습니다. 이어서 추가한 보안 처리 과정을 설명하겠습니다.
2. 알림 시스템 보안 처리 추가
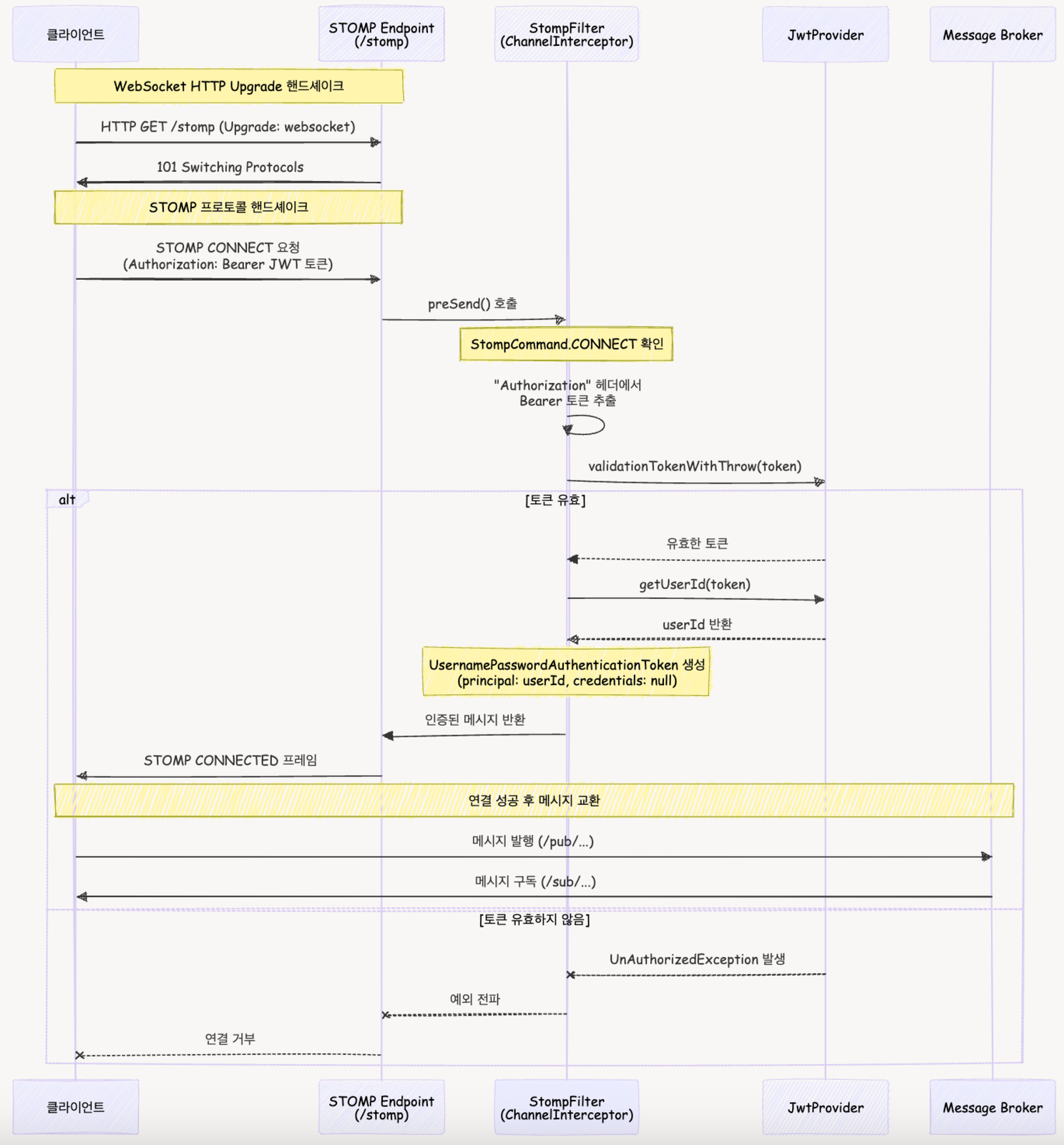 - STOMP 인증 처리 과정 -
- STOMP 인증 처리 과정 -
코코무에서는 이벤트 기반 실시간 알림 처리를 STOMP 프로토콜을 기반으로 합니다. 인증되지 않은 사용자의 접근을 방지하기 위한 보안 메커니즘도 중요합니다. 코코무는 JWT(JSON Web Token)와 Spring AOP를 활용한 인증 방식을 적용했습니다.
@Configuration
@EnableWebSocketMessageBroker
@RequiredArgsConstructor
public class WebSocketConfig implements WebSocketMessageBrokerConfigurer {
private final StompInterceptor stompInterceptor;
@Override
public void configureClientInboundChannel(ChannelRegistration registration) {
registration.interceptors(stompInterceptor);
}
// 나머지 설정...
}
@Component
@RequiredArgsConstructor
public class StompInterceptor implements ChannelInterceptor {
private final JwtProvider jwtProvider;
@Override
public Message<?> preSend(final Message<?> message, final MessageChannel channel) {
final StompHeaderAccessor accessor = MessageHeaderAccessor.getAccessor(message, StompHeaderAccessor.class);
if (StompCommand.CONNECT.equals(accessor.getCommand())) {
final String bearerToken = accessor.getFirstNativeHeader("Authorization");
final String token = extractToken(bearerToken);
jwtProvider.validationTokenWithThrow(token);
final Long userId = jwtProvider.getUserId(token);
accessor.setUser(new UsernamePasswordAuthenticationToken(userId, null, Collections.emptyList()));
}
return message;
}
}이 인증 프로세스는 다음과 같은 단계로 이루어집니다.
- 웹소켓 연결 시작: 클라이언트가 HTTP를 통해 웹소켓 연결을 요청합니다(HTTP Upgrade 메커니즘)
- STOMP CONNECT 명령: 클라이언트가 STOMP 프로토콜 연결을 요청하며, 이때 Authorization 헤더에 JWT 토큰을 포함시킵니다.
- 토큰 검증: StompInterceptor가 preSend() 메서드에서 토큰을 추출하고 JwtProvider를 통해 유효성을 검증합니다.
- 인증 객체 생성: 유효한 토큰에서 추출한 사용자 ID로 인증 객체를 생성하고 메시지 컨텍스트에 설정합니다.
- 연결 완료: 인증이 성공하면 STOMP CONNECTED 프레임이 클라이언트에게 전송되고, 이후 메시지 교환이 가능해집니다.
이러한 인증 메커니즘을 통해 다음과 같은 이점을 얻을 수 있습니다.
- 보안성: 인증된 사용자만 참여할 수 있습니다.
- 사용자 식별: 각 메시지의 출처를 명확히 식별할 수 있습니다.
- 권한 검증: 특정 스페이스에 대한 접근 권한을 검증할 수 있습니다.
- 세션 연속성: HTTP 요청과 웹소켓 연결 간에 일관된 인증 상태를 유지할 수 있습니다.
토큰 유효성이 만료되거나 잘못된 경우, 연결은 거부되고 클라이언트는 인증 오류를 받게 됩니다. 이를 통해 실시간 상태전이 환경에서도 보안을 유지할 수 있습니다.
결과 (Result)
STOMP 기반 알림 시스템을 구현함으로써 코코무 플랫폼에 실시간 상호작용 기능을 성공적으로 추가할 수 있었습니다.
이 과정에서 얻은 주요 성과는 다음과 같습니다.
기술적 성과
- 비즈니스 로직과 알림 시스템의 효과적인 통합
- 기존 비즈니스 로직에 알림 발행 기능을 추가하여 코드 변경을 최소화하면서 실시간 기능을 구현했습니다.
- 도메인 이벤트와 알림 시스템을 연결하여 느슨한 결합을 유지했습니다.
- 세션 관리 메커니즘 개선
- 게임 대기방 모델을 참고하여 '입장/대기'와 '참여' 개념을 분리함으로써 코딩 스페이스의 상태 관리를 더 명확하게 구현했습니다.
- 스터디 시작 전후의 사용자 상태를 명확히 구분하여 적절한 알림을 발송할 수 있게 되었습니다.
- 보안 강화
- JWT 기반 인증 메커니즘을 STOMP 연결에 적용하여 무단 접근을 방지했습니다.
- 메시지의 출처를 명확히 식별할 수 있게 되어 시스템의 신뢰성이 향상되었습니다.
사용자 경험 개선
- 실시간 스터디 환경 제공
- 사용자들이 코딩 스페이스에서 발생하는 모든 이벤트(입장, 퇴장, 상태 변화, 테스트 케이스 추가 등)를 실시간으로 확인할 수 있게 되었습니다.
- 코드 실행 및 제출 결과를 즉시 공유할 수 있어 효율적인 스터디가 가능해졌습니다.
- 상태 전이의 명확한 시각화
- 스터디의 진행 단계(대기→시작→피드백→종료)가 모든 참여자에게 실시간으로 동기화되어 일관된 사용자 경험을 제공합니다.
향후 개선 방향 확립
- 확장성 강화
- 현재는 인메모리 방식으로 세션을 관리하고 있으나, 사용자 수 증가에 대비하여 Redis와 같은 분산 캐시 시스템으로 전환을 고려하고 있습니다.
- 대규모 접속자 환경에서의 성능 테스트와 최적화가 필요합니다.
- 보안 지속 강화
- 메시지 레벨 권한 검증을 추가하여 특정 코딩 스페이스에 대한 접근 제어를 더 세밀하게 구현할 계획입니다.
이번 STOMP 기반 알림 시스템 구현을 통해 코코무는 단순한 코딩 학습 플랫폼에서 실시간으로 스터디 정보를 공유하는 환경으로 한 단계 발전했습니다. 사용자들은 이제 코드 작성부터 실행, 피드백까지의 전 과정을 끊김 없이 경험할 수 있으며, 이는 코딩 교육의 효율성과 몰입도를 크게 향상시킬 것으로 기대됩니다.
마치며: 코코무의 여정, 그리고 앞으로...
4주라는 짧은 시간 속에서 코코무 프로젝트는 코딩 스터디 플랫폼으로서 핵심 기능들을 성공적으로 구현했습니다. 코드 실행기, 도메인 비즈니스 로직, OAuth 2.0 로그인, STOMP 기반 알림 시스템까지 - 각 기능은 단순히 '동작하는' 수준을 넘어 확장성과 성능, 보안을 고려한 설계로 구현되었습니다.
하지만 모든 여정과 마찬가지로, 이 프로젝트 역시 끝이 아닌 또 다른 시작점이라고 생각합니다. 구현하면서 발견한 개선점들과 시간 제약으로 다루지 못한 영역들이 아직 많이 남아있습니다.
개선하고 싶은 부분들
- 비즈니스 로직 리팩토링: 글을 작성하며 보완 및 개선되어야 할 로직을 개선
- 데이터베이스 최적화: 도메인 중심 설계를 완성하기 위한 쿼리 최적화와 인덱싱 전략 개선
- 동시성 처리 강화: 코드 실행기의 부하 테스트와 자동 스케일링 구현
- 모니터링 시스템 구축: 프로메테우스와 그라파나를 활용한 실시간 시스템 모니터링
- 세션 관리 고도화: Redis를 활용한 분산 환경에서의 세션 관리 시스템 구현
- 메시지 큐 확장: 대용량 트래픽에 대응하기 위한 RabbitMQ 클러스터링 구성
앞으로 도전하고 싶은 과제들
- 분산 시스템 아키텍처 도입: MSA(Microservice Architecture)로의 전환을 통한 서비스 확장성 강화
- 컨테이너 오케스트레이션: Kubernetes를 활용한 코드 실행기 워커 노드 관리 자동화
- 실시간 협업 기능 강화: Yorkie -> Operational Transformation 알고리즘을 적용한 자체 실시간 코드 편집 구현
- 성능 테스트 자동화: 지속적 통합/배포(CI/CD) 파이프라인에 성능 테스트 자동화 추가
- 다국어 지원: 더 많은 프로그래밍 언어 실행 환경 지원으로 사용자 경험 확장
최종적으로
이 프로젝트를 통해 단순히 코드를 작성하는 것 이상의 가치를 배웠습니다. 사용자 관점에서 생각하기, 확장 가능한 아키텍처 설계하기, 그리고 무엇보다 문제를 직면했을 때 체계적으로 해결해 나가는 방법을 경험할 수 있었습니다.
코코무는 단순한 코딩 플랫폼을 넘어, 개발자와 개발자를 희망하는 모든 사람들이 함께 성장할 수 있는 커뮤니티로 발전하는 것을 목표로 합니다.
프로젝트 코드와 더 자세한 내용은 GitHub 저장소에서 확인하실 수 있습니다: 깃허브 링크 클릭
