TL;DR
kafka를 활용해 Debezium Postgresql Source Connector를 사용한 CDC 환경을 만들어 보려고 했는데 처음 하다보니 debezium docs나 kafka docs들이 돌이켜보니 잘돼있었지만, 시간이 꽤나 걸렸다. 이를 기록해서 나와 같은 분들이 있다면 빠르게 초기 세팅을 할 수 있으면 좋겠다.
CDC ( Change Data Capture )
CDC는 변경된 데이터를 캡쳐한다는 의미로 우리가 특정 Source Database 에서 Insert, Delete, Update 가 일어난 데이터들을 저장하여 다른 Target System으로 전달하는 것을 말한다.
기존에는 Batch 작업을 통해서 일정 주기마다 변경사항들을 전달하는 방식들이 있었는데 이를 realtime에 가깝게 할 수 있도록 하는 대체 방안으로 현재 많이 사용되고 있다.
이러한 CDC를 직접 application으로 개발하여서 할 수도 있겠지만, 이미 Provider들이 kafka connect형태로 잘 만들어진 구현체들을 만들어 놓았다. 따라서 우리는 이러한 도구들을 잘 가져다 사용하면 보다 빠르게 CDC환경을 구축하고, 비즈니스 로직에 더 집중하여 개발 효율성을 높일 수 있다.
Kafka connect
connect란 kafka의 하나의 component중 하나로 위에서 언급한 대로 우리가 데이터 파이프라인 구축에 필요한 것들이 이미 만들어져 있는 하나의 애플리케이션이다. connnect는 내부적으로 작업을 템플릿 형태로 정의한 커넥터들이 task들을 실행하면서 동작하게 된다.
우린 이러한 connect 중 debeizum postgresql connect를 사용할 것이다. connect의 connector들은 각각 jar 파일로 만들어져 있고, 이를 plugin 형태로 kafka plugin path 에 등록해서 사용해 주면 된다.
Practice
Local 환경에 kafka connect를 활용한 Postgresql 의 CDC 환경을 구축해보자.
우선 minikube를 이용해 k8s 환경을 구축하고, confluent-platform을 이용해서 kafka-cluster를 구축할 것이다. 추가로 postgresql 또한 bitnami/postgersql 을 이용해서 설치를 할 것이다.
Github에 사용했던 소스코드를 올려놓았고, 이를 통해 직접 테스트해보면 된다.
Prerequisite
helm, minikube, kubectl을 설치해줘야 진행이 가능하다. 인터넷을 찾아보면 설치방법은 잘 나와있으니 미리 준비해주면 되겠다.
postgresql 설치
Github source code에는 postgresql chart를 미리 받아놓아서 따로 받을 필요는 없지만, 직접 받고 싶다면 bitnami repo를 추가해서 다운 받으면 된다.
소스코드에 설정한 Postgresql은 wal_level을 logical level로 낮춰 놓았는데 debezium connect는 log level수준의 cdc를 제공하기 때문에 이같이 level을 logical로 낮춰줘야 사용이 가능하다.
wal_level은 postgresql configuration을 통해 변경이 가능하다.
helm repo add bitnami https://charts.bitnami.com/bitnami
helm upgrade --install postgresql bitnami/postgresql소스 코드에 있는 postgresql 를 사용하고 싶다면 아래의 명령어를 사용하면 된다.
helm upgrade --install postgresql ./postgresqlpostgresql를 설치했다면 host pc 에서 접속을 하고 싶을 수 있는데 그 때는 port-fowarding을 통해서 host network로 연결해주면 된다.
kubectl port-foward svc/postgresql 5432:5432
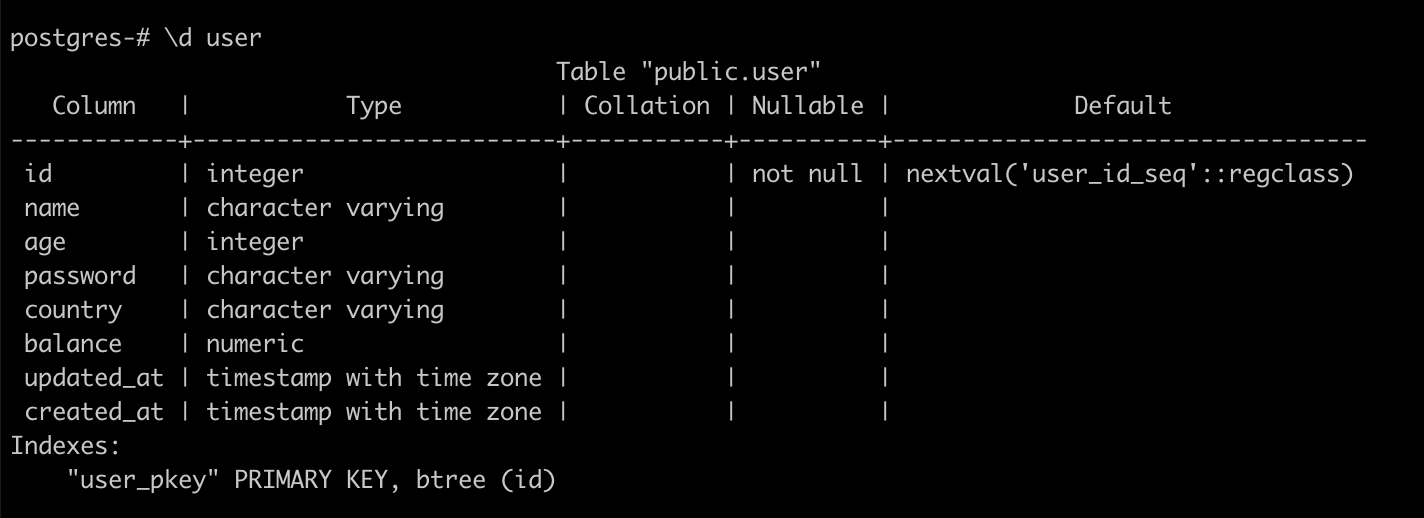
간단하게 user table에 대해서 테스트를 해보기위해서 만들어 보았다
user 테이블의 정보는 아래와 같다.
minikube
Local 환경에 맞게 node 의 사양을 결정해서 multi-node cluster로 만들어준다. confluent-platform을 사용하면 broker를 3개 이상으로 만들기를 권장하고 대부분 default 설정값들이 ( min.insync.replica, replication.factor ) 등이 3으로 설정돼 있어 오류가 나기 쉽다.
필자는 local 환경이 좋지 않아서... 3개의 multi node를 만들고 2개의 broker 만을 운영하여서 테스트 할 예정이다.
그에 따라서 일부 configuration들을 borker 2개에 맞춰서 변경해준 것들이 있다. ( 이것 때문에 초기 세팅이 오래걸렸음... )
minikube 의 cluster를 만드는 명령어는 아래와 같다.
minikube start --nodes 3 --memory 8GB --cpus 3 -p confluent-demo --insecure-registry='0.0.0.0/0'옵션중 insecure-registry옵션은 multi-node cluster에서 docker의 registry와 minikube의 registry를 연결하기 위해서 security 범위를 전체로 열어준 것이다.
또한 registry를 이용하기 위해서 addon을 설치해준다.
minikube addons enable registry -p confluent-demo그 후 connect에서 사용할 custom docker image를 사용하기 위해서 github source에 정의된 dockerfile을 기반으로 이미지를 빌드하고, minikube registry에 등록한다.
아래 명령어를 통해서 docker vm 을 리다이렉트 해준다.
docker run --rm -it -d --network=host alpine ash -c "apk add socat && socat TCP-LISTEN:5000,reuseaddr,fork TCP:$(minikube ip -p confluent-demo):5000"그 후 build 후 push 를 진행
docker build --tag cp-server-connect-psql:latest .
docker tag cp-server-connect-psql:latest localhost:5000/cp-server-connect-psql
docker push localhost:5000/cp-server-connect-psqlkubevirt.io 를 설치
추가로 minikube multi-node에서는 기존 standard storageclass로는 dynamic provisioning이 이루어지지 않는다. 따라서 custom-storageclass를 만들어줘야 하는데, minikube 공식 홈페이지에 나와있는 csi-hostpath-driver를 받아서 사용해봤을 때는 pvc로 만들어진 volume 에 permission 문제가 발생하는 이슈가 있어서 다른 storageclass를 사용했다.
kubevirt.io/hostpath-provisioner 를 사용한다.
kubectl delete sc standard
kubectl apply -f storageclass.yamlCFK 설치
CFK 란 confluent on kubernetes로 confluent사가 공식 배포하는 helm chart이다.
github source code를 받았다면 아래 명령어를 통해서 설치가 가능하다.
helm upgrade --install confluent-operator ./confluent-for-kubernetes --namespace confluent --create-namespace그냥 helm repo를 추가해서 설치를 해도 되지만, 만들어진 crd 들이나 values 값들을 살펴보고 싶어서 따로 chart를 local에 받아서 사용했다.
Node labeling진행
kafka broker들이 하나의 node에 몰리지 않게 하기 위해서 배치하고자 하는 node 에 labeling을 진행했다.
kubectl label nodes confluent-demo-m02 foo.service=broker
kubectl label nodes confluent-demo-m03 foo.service=brokerKafka cluster 구축
./run.sh위 명령어를 사용하면 kafka-cluster가 구축되게 된다.
kafka-cluster 구성이 완료 됐다면, 우선 postgresql에 어떤 변화가 있는지 살펴보자.
replication slot의 형성

connector가 생성이 되면 replication slots이 형성됨을 볼 수 있다. replication slot이란 postgresql 에서 발생하는 wal(write ahead log) segment를 장기간 보관하게 하는 기능중의 하나라고 생각하면 된다.
기본적으로 wal는 2GiB 가 유지되고, 각 segment는 16MB로 구성되어서 관리가 된다. 이 때 용량을 초과하게 되면 이전 log는 지워지게 되기 때문에 missing 되는 log 가 생겨서 원하는 replication이 제대로 이루어지지 않을 수 있다.
그렇기 때문에 장기간 보관을 하기 위해서 replication slot을 설정한다.
publication 설정

또한 table에 publication이 설정되게 된다. publication이란 table에서 발생한 변화의 내역에 대한 데이터셋이라 생각하면 된다. publication은 을 설정한 table은 publisher가 되는 것이고 변경 내역들을 저장하게되는데, 이 때 replication id를 어떻게 할 것인지를 설정할 수 있다.
보통 default로 table의 primary key가 설정되고, 그 외에 index들을 설정한다거나 모든 attribute에 대해서 설정할 수 있는 FULL도 존재한다.
default 타입으로 publication을 만들었다 가정하고, 만약 index가 설정돼 있는 것이 없거나 index를통한 update, delete가 일어나면 replication id가 없다는 에러가 발생하면서 해당 transaction은 롤백되게 된다.
여기서 하나 주의할부분이 있는데 Publication생성시에publication.autocreate.mode=filtered로 설정하지 않으면 모든 table에 대한 publication이 만들어지게 된다. ( 실제 CDC를 사용하지 않는 녀석이라 해도 ) 이에 따라서 다른 기존에 문제가 없던 table에 갑자기 update, delete 작업시 replication id가 없다는 에러가 나올 수 있는데 주의해서 잘 모든 테이블에 설정되지 않도록 해야한다.
confluent 에서 제공해주는 다양한 기능들이 추가되게 되는데 이번 포스팅에서는 controlcenter정도만 사용하면서 topic 에 데이터 전달이 잘 되는지 확인만 해보도록 하자.
controlcenter를 통해 확인해보기
kubectl port-forward controlcenter-0 9021:9021 -n confluent위 명령어를 통해 controlcenter ui 에 접속을 할 수 있게 port forwarding을 해준다.
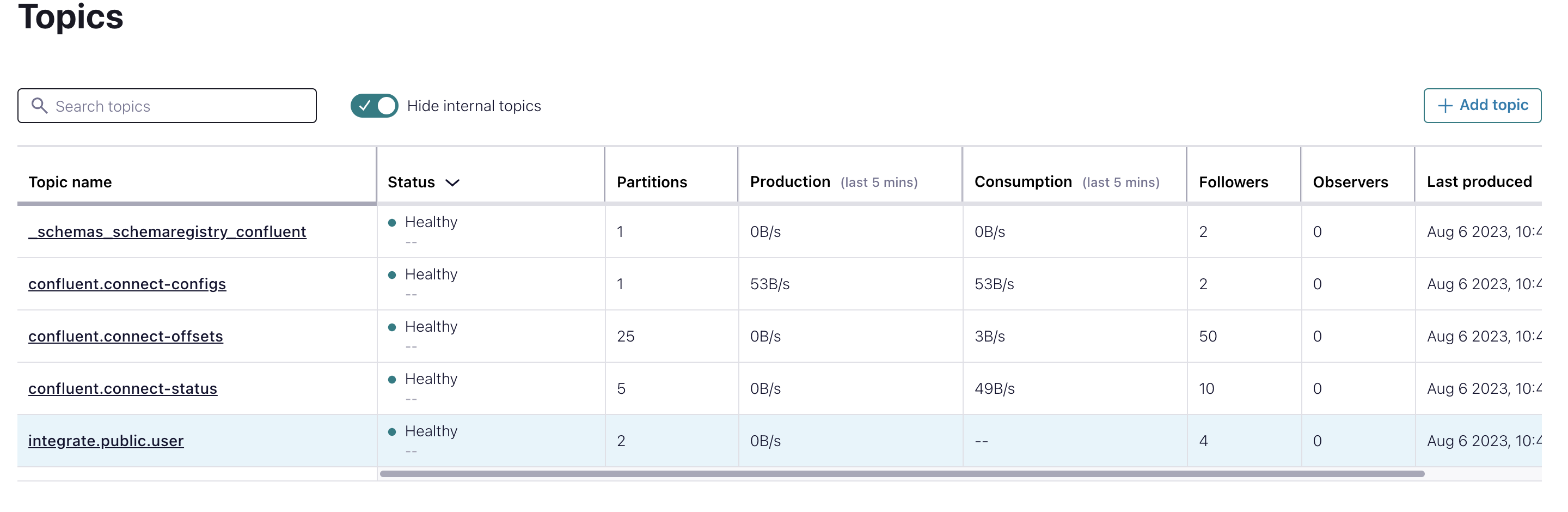
topic을 눌러 들어가서 message들이 잘 들어왔나 확인해보면 된다
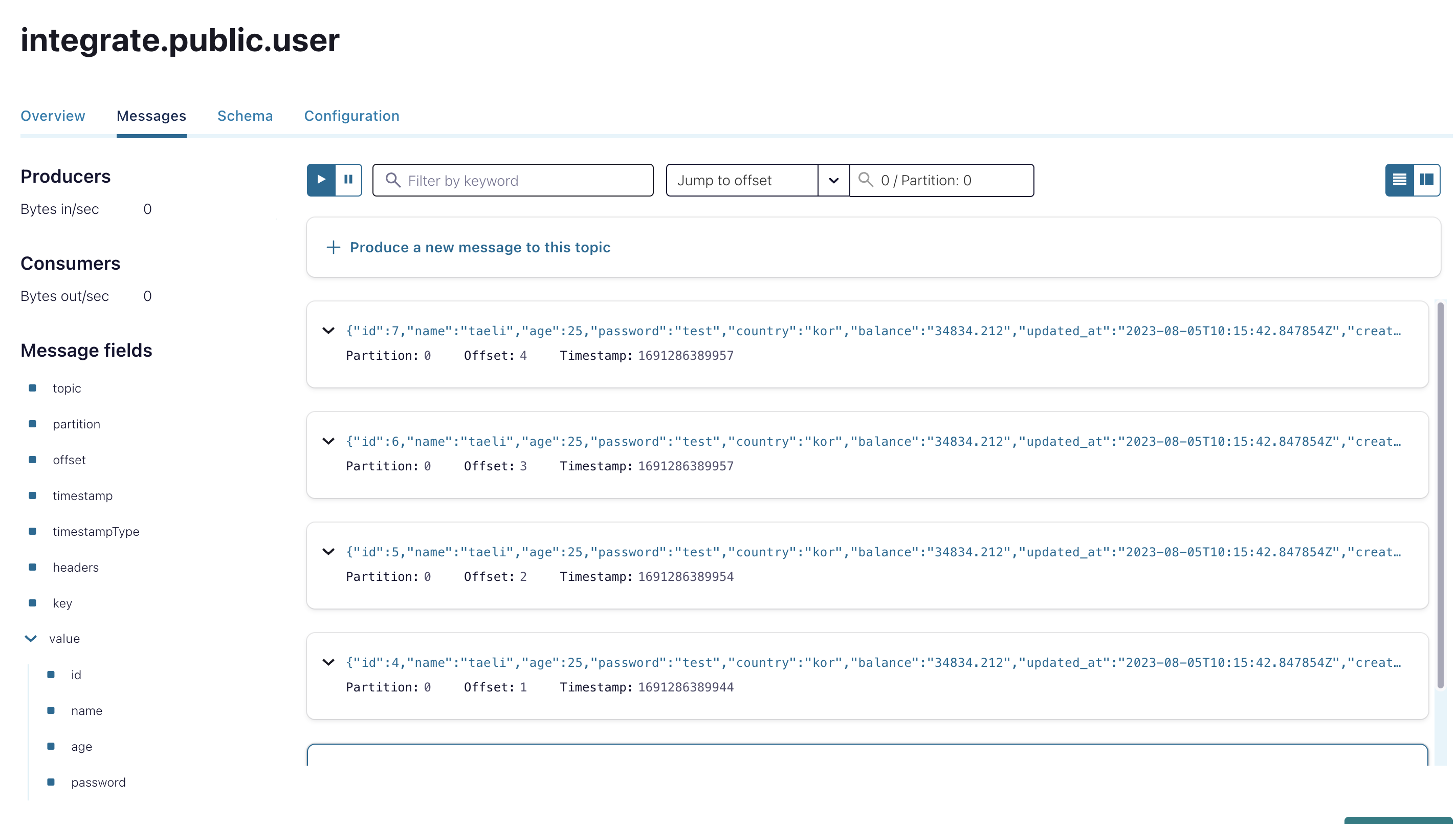
잘 전달됨을 확인할 수 있다.
Debezium PostgreSQL Connector config 확인
apiVersion: platform.confluent.io/v1beta1
kind: Connector
metadata:
name: debezium-postgresql-connector
namespace: confluent
spec:
class: io.debezium.connector.postgresql.PostgresConnector
taskMax: 2
configs:
connector.class: "io.debezium.connector.postgresql.PostgresConnector"
tasks.max: "2"
database.hostname: "postgresql.default.svc.cluster.local"
database.dbname: "postgres"
database.port: "5432"
database.user: "postgres"
database.password: "YOUR_PASSWORD"
database.config.output.plugin: "pgoutput"
key.converter: "org.apache.kafka.connect.storage.StringConverter"
key.converter.schemas.enable: "false"
value.converter: "org.apache.kafka.connect.json.JsonConverter"
value.converter.schemas.enable: "false"
table.include.list: "public.user"
topic.prefix: "integrate"
topic.creation.groups: "public"
topic.creation.default.replication.factor: "2"
topic.creation.default.partitions: "2"
topic.creation.default.cleanup.policy: "delete"
topic.creation.default.compression.type: "producer"
topic.creation.default.retention.ms: "25920000"
topic.creation.public.include: "integrate\\.public\\.*"
topic.creation.public.cleanup.policy: "update"
message.key.columns: "postgres.public.user:id;"
plugin.name: "pgoutput"
transforms: "unwrap,createKey,extractId"
transforms.unwrap.type: "io.debezium.transforms.ExtractNewRecordState"
transforms.unwrap.drop.tombstones: "false"
transforms.unwrap.delete.handling.mode: "rewrite"
transforms.createKey.type: "org.apache.kafka.connect.transforms.ValueToKey"
transforms.createKey.fields: "id"
transforms.extractId.type: "org.apache.kafka.connect.transforms.ExtractField$Key"
transforms.extractId.field: "id"
decimal.handling.mode: "string"
snapshot.mode: "initial"
slot.name: "debezium_test"
publication.name: "dbz_publication_test"
publication.autocreate.mode: "filtered"필자는 다음과 같이 설정해서 connector를 만들었다.
broker는 2대이기 때문에 replication.factor, partition은 2로 설정해주었다.
각각의 table별로 topic이 형성되게 되고, topic_prefix.schema.table_name의 형태로 만들어지게 된다. 각 topic 별 생성하는 기준을 설정할 수 있는데, topic.creation.groups를 이용해 producer group을 형성하고 해당 gorup에 대한 설정값을 별도로 줄 수 있다.
필자는 public이라는 group을 따로 만들고 cleanup policy를 다르게 줘봤다. 여기서 custom group을 적용시키기 위해서 include 옵션을 사용해야하는데 정규표현식을 사용해서 해당 패턴에 맞는 topic에 대해서만 custom group의 설정값을 받아서 사용하도록 설정이 된다.
log cleanup policy
delete로 설정을 해놓았다. 어차피 로컬에서 테스트 하는 부분이라 크게 고민하지는 않았고, 3일 정도 간격으로 cleanup을 진행할 수 있도록 했다.
Slot, Publication
각각 별도의 Slot, publication명을 지정해주어서 구분되어 사용할 수 있도록 하였고, publication같은 경우 filtered로 설정하여서 table.include.list를 기반으로해서 schema,table을 특정지어서 만들 수 있게 했다.
Replication ID의 경우 따로 설정이 없다면 Default로 형성이된다.
Transforms
transforms같은 경우 "io.debezium.transforms.ExtractNewRecordState" 타입을 사용했는데 그 이유는 아무 설정도 하지 않게 되면 아래와 같은 형태의 message가 저장이 된다.
{
"before": null,
"after": {
"pk": "2",
"aa": "1"
},
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "571:53195832",
"total_order": "1",
"data_collection_order": "1"
}
}따라서 format을 좀 더 간단하게 만들기 위해서 predefined된 것들은 제거하고 새로 형성되는 record들만 보일 수 있게 했다. 또한 delete에 대한 정보를 따로 확인해보기 위해서 transforms.unwrap.delete.handling.mode: "rewrite" 옵션을 추가해줬다.
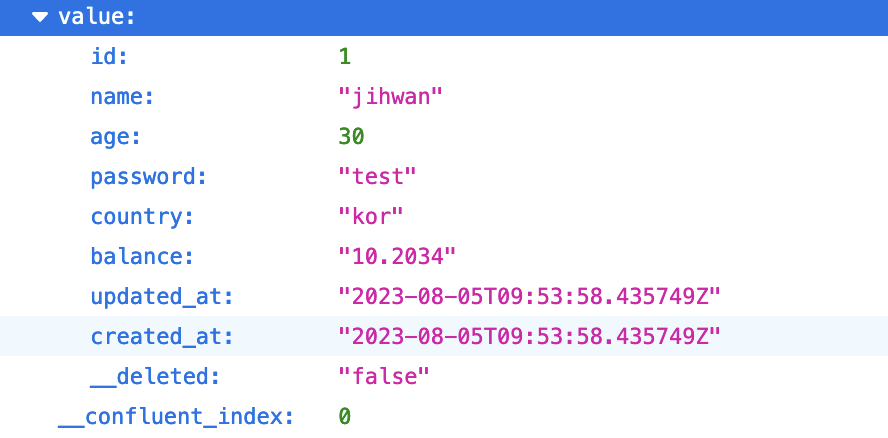
추가로 message_key 를 만드는데 있어서
"Struct{id=1}" 이러한 구조를 제거하기 위해서 다음의 transforms를 추가했다.
transforms.createKey.type: "org.apache.kafka.connect.transforms.ValueToKey"
transforms.createKey.fields: "id"
transforms.extractId.type: "org.apache.kafka.connect.transforms.ExtractField$Key"
transforms.extractId.field: "id"id Value를 key로 만들고 id 값만 추출해서 사용하는 방식이다.
최종적으로는 아래와 같은 형태의 record를 기록하게 된다.
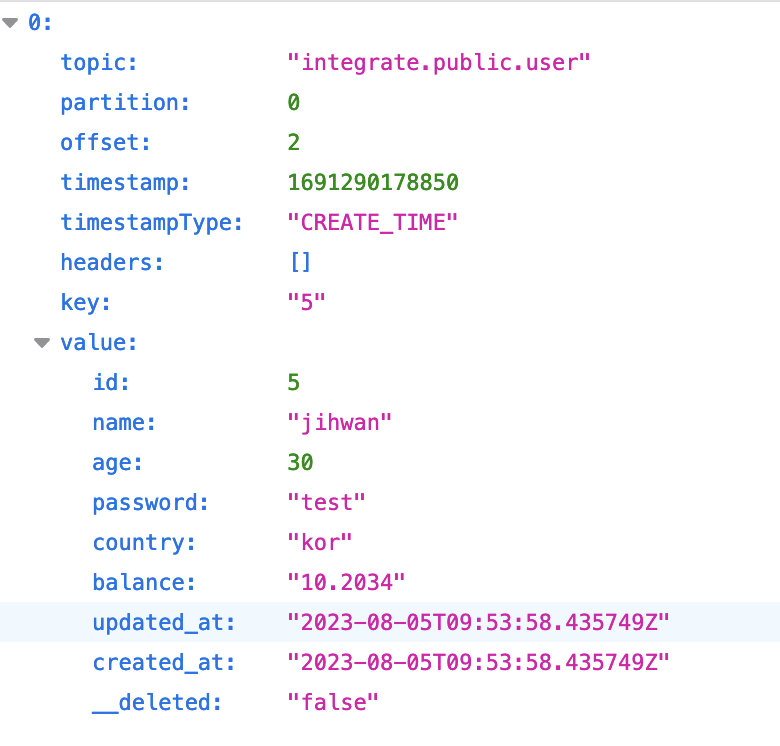
결론
Confluent-platform 구축부터 시작해 Debezium postgresql connect를 사용하여 실제 CDC까지 진행을 해보았다. 이번 포스팅에서는 confluent-platform구축에 대한 자세한 설명을 적지 않았는데 이 부분도 따로 포스팅으로 만들어보면 좋을 것 같다. CDC를 위한 connector의 사용에 생각보다 고려해줘야 할 부분이 많았다. SMT가 가장 머리가 아픈 부분이었는데 postgresql의 column type 별로 topic 에 저장되는 방식들이 다르다. 예로 timestamp, timtestamptz의 저장 방식이 다른 것이 있고, numeric타입 같은 경우 처음에는 json 형태로 저장이 되게 된다. 이러한 부분들은 경험적으로 알게 되고, 이에 맞춰서 잘 커스터마이징을 해줘야할 것 같다. 모든 저장 타입들을 외울 수는 없으니까 말이다.
그 밖에도 slot, publication 설정들에 대해서 어느정도 깊이의 지식은 있어야할 것 같다. 그렇지 않으면 예기치 못한 문제들이 발생해서 대처가 어려울 수 있기 때문이다. 앞으로 좀 더 경험을 쌓아나가면서 생길 수 있는 문제들을 기록해나가도록 해야겠다.

글 잘 봤습니다.