TL:DR;
사내 알람 서비스를 구성하기 위해서 Celery Framework를 사용하면서 겪었던 문제들을 기록하기 위해서 작성.
사내 알람서비스를 기획개발함에 있어서 고려했던 부분은 급격하게 늘어나는 유저에 대한 확장성 부분을 많이 고려했다. 그에 따라서 단일 인스턴스 기반으로 운영하기 보다는 Multi Instance를 사용하는 방향으로 진행했고 그에 맞는 Framework로 Celery를 채택하게 됐다.
Celery 란?
Celery 란 Distributed Task Queue (분산 테스크 큐) 이다.
Celery Framework 는 크게 Broker, Worker 두 가지로 나눠지게 되는데 Broker 는 Message Queue 의 역할을 하게 되고 Worker 가 일정 간격마다 Polling을 하면서 Message Queue에 있는 Task들을 가져가서 실행하게 되는 방식이다.
Broker 로는 Redis, RabbitMQ, Amazon SQS 등이 사용된다. Broker는 각각의 장단이 있고 상황에 따라서 사용하면 될 것 같다.
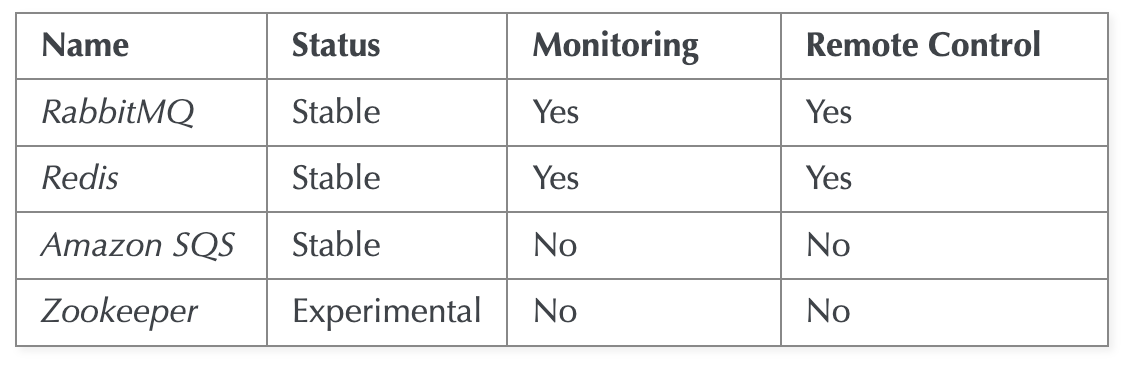
필자는 사용경험이 있고 빠른 성능을 기대해 Redis를 채택하고 사용하기로 결정했다.
Worker 는 Task를 직접 실행하는 서버로 연결된 Queue에 대해서 task를 읽고 수행할 수 있다 또한 Worker 스스로 Task를 등록할 수도 있기 때문에 연계해서 Task를 만들 수도 있다. ( Worker모두가 Task 등록이 가능, 외부에서도 API 통신으로 가능 )
Celery Code 로 보기
Celery instance
from celery import Celery
app = Celery('hello', broker='amqp://guest@localhost//')
@app.task
def hello():
return 'hello world'가장 기본적으로 Celery를 사용하는 방식이다.
Celery Library를 사용하기 위해서는 먼저 Celery()를 통해서 객체생성을 해줘야한다. 이 때 여러 celery application이 생성 될 수 있기 때문에 각 application들은 Thread safe 하게 만들어진다.
Celery 인스턴스에는 이름이 존재하게 되는데 만약 생성시 name을 지어주지 않는다면 해당 main module 을 실행했을 때 __main__ 이 이름으로 붙게 된다.
>>> @app.task
... def add(x, y):
... return x + y
>>> add
<@task: __main__.add>
>>> add.name
__main__.add
>>> app.tasks['__main__.add']
<@task: __main__.add>하지만 다른 module 에서 해당 task를 가져오게 됐을 때는 해당 task가 있는 module의 이름으로 변경해서 생성되기 때문에 같은 task여도 다른 name을 갖게 되는 문제가 발생할 수 있다.
>>> from tasks import add
>>> add.name
tasks.add이로 인한 사이드 이펙트가 발생할 수 있으니 생성시에 application name을 명시해주는 것이 좋다.
>>> app = Celery('tasks')
>>> app.main
'tasks'
>>> @app.task
... def add(x, y):
... return x + y
>>> add.name
tasks.add2. Configuration 설정
Celery configuration설정은 다양한 방식으로 가능하다.
1. app.conf를 직접 변경
app.conf.enable_utc = True
app.conf.update(
enable_utc=True,
timezone='Europe/London',
)2. config_from_object method 활용
Celery instance 의 method 인 config_from_object 를 활용할 수도 있다. 해당 method 를 사용하면 이전 configuration 값들은 reset 되고 지정한 configuration 값으로 변경되게 된다.
직접 module 의 이름을 적어줄 수도 있고 import 해와서 사용하는 것 또한 가능하다.
from celery import Celery
app = Celery()
app.config_from_object('celeryconfig')
---
import celeryconfig
from celery import Celery
app = Celery()
app.config_from_object(celeryconfig)또는 class 를 이용하는 방법 또한 가능하다.
from celery import Celery
app = Celery()
class Config:
enable_utc = True
timezone = 'Europe/London'
app.config_from_object(Config)3. config_from_envvar
환경변수 에 configuration 을 가져올 module을 지정해서 사용할 수 있다.
import os
from celery import Celery
#: Set default configuration module name
os.environ.setdefault('CELERY_CONFIG_MODULE', 'celeryconfig')
app = Celery()
app.config_from_envvar('CELERY_CONFIG_MODULE')Celery 사용 Tip
1. Class based task
보통 Celery task 를 만들기 위해서
@app.task
def add():
...데코레이터를 사용하게 되는데 때에 따라서 Class based task를 사용하고 싶을 수가 있는데 이럴 때는 base task 를 상속하여 CustomTask를 만들고 직접 등록시켜주면 된다.
from celery.app.task import Task
class CustomTask(Task):
def run(self):
print('running')
CustomTask = app.register_task(CustomTask())초기에는 따로 등록을 해줄 필요가 없었지만 version이 변경되면서 decorator를 쓰거나 직접 등록을 하는 방식으로 변경됐다.
2. Worker setting 옵션
Celery worker의 셋팅값을 조절하여서 좀 더 효율적으로 Task를 처리할 수 있다.
1. worker_prefetch_multiplier
해당 설정값은 worker 가 한 번에 받아가는 task를 몇 개로 정할지를 설정할 수 있는 값으로 default 값은 4로 설정되어 있다. 그럼 각 worker 별로 4개의 task를 한 번에 취할 수 있는 것이다.
따라서 만약 task 가 짧고 많을 때 그리고 round trip latency가 중요한 이슈라면 해당 값을 높여서 한 번에 많은 task들을 worker에 할당시켜서 빠르게 처리하는 방식이 효율적일 것이다.
하지만 task 가 작업기간이 길고 양이 적다면 오히려 하나의 worker 에 불필요하게 많은 task가 할당되어서 성능이 저하될 수도 있다. 따라서 상황에 맞게 값을 설정해서 worker를 운영할 필요가 있다.
2. memory 관리
Celery를 parallel하게 사용하게되면 여러 child process가 발생하게 된다. 이 때 child process 에서 memory leak 이 발생할 수 있는데 memory leak 이 일어나도 child process가 종료되지 않으면 해당 memory를 반환 받을 수 없기 때문에 문제가 발생할 수 있다.
추가로 celery issue tracker에 memory leak bug가 존재한다고 하여서 예기치못한 메모리 에러가 발생할 수 있는데 이럴 때를 대비해서 아래 두 가지 옵션을 사용하면 좋다.
- worker_max_tasks_per_child: worker에서 처리하는 총 task의 양으로 해당 값을 넘어가게 되면 worker 를 재생성하게 된다. 따라서 혹시모를 누수가 있었을 때 그 memory를 회수할 수 있게 된다. default 는 0. 이 값을 너무 작게 하면 worker를 새로 띄우는 시간이 너무 많이 생길 수 있기 때문에 적당한 값을 설정할 필요가 있다.
- worker_max_memory_per_child: worker가 점유할 수 있는 최대 memory양을 지정할 수 있다. 단위는 kiB 이고 default 는 No limit이다.
3. Redis, SQS broker visibility timeout
Redis, SQS 를 broker 로 사용한다면 visibility timeout 값을 설정할 수 있다.
broker_transport_options = {'visibility_timeout': 18000} visibility timeout이란 task 를 작업하는 worker 에서 해당 task를 완료하지 못했을 때 다른 worker에게 task를 전달하는 그 limit시간을 설정한 값이다.
만일 task를 해당 시간내에 완료하지 못하면 다른 작업자에게 할당되게 된다.
해당 값을 너무 길게설정하게 되면 중간에 worker가 죽었을 때 해당 task의 재할당이 늦어질 수 있기 때문에 적당한 시간을 설정할 필요가 있다.
4. send_task 활용
task 를 등록할 때 사용할 수 있는 method로는 delay, apply_async 등이 있는데 apply_async 는 delay에 비해 좀 더 부가적인 option들을 추가해서 사용할 수 있는 장점이 있다.
하지만 해당 방식들은 모두 task를 local registry에 등록해야 사용이 가능하다.
이와 같은 등록이 귀찮고 그냥 깔끔하게 사용할 수 있는 방법으로 send_task 가 있다.
send_task 는 task의 이름을 기반으로 등록하게 된다. ( 나머지 args 는 apply_async와 동일 )
from celery import Celery
app = Celery('hello', broker='amqp://guest@localhost//')
@app.task
def hello():
return 'hello world'
hello.apply_async()
hello.delay()
---
app.send_task("hello")
Reference
