준비 : 데이터 불러오기 및 데이터 탐색
import pandas as pd
# 데이터 불러오기 (한글파일인 경우 encoding 방식 명시 cp949, utf-8, utf-8-sig)
pd.read_csv('파일경로/파일명.csv', encoding = '')
# -------------------------------------------------------
# 데이터 잘 불러와졌는지 확인
df.head()
# 데이터 요약 정보 확인 (컬럼, null값, dtype)
df.info()
# 전체 컬럼명 확인 및 특정 인덱스 컴럼명 확인
df.columns
df.columns[index]
# 특정 열의 unique값 확인
df[df.columns[index]].unique()
df['컬럼명'].unique()
# 조건에 해당되는 값을 데이터프레임형태로 확인
df[df['컬럼명'] == '조건']집계가 완료된 형태의 데이터를 재구조화하는 메서드
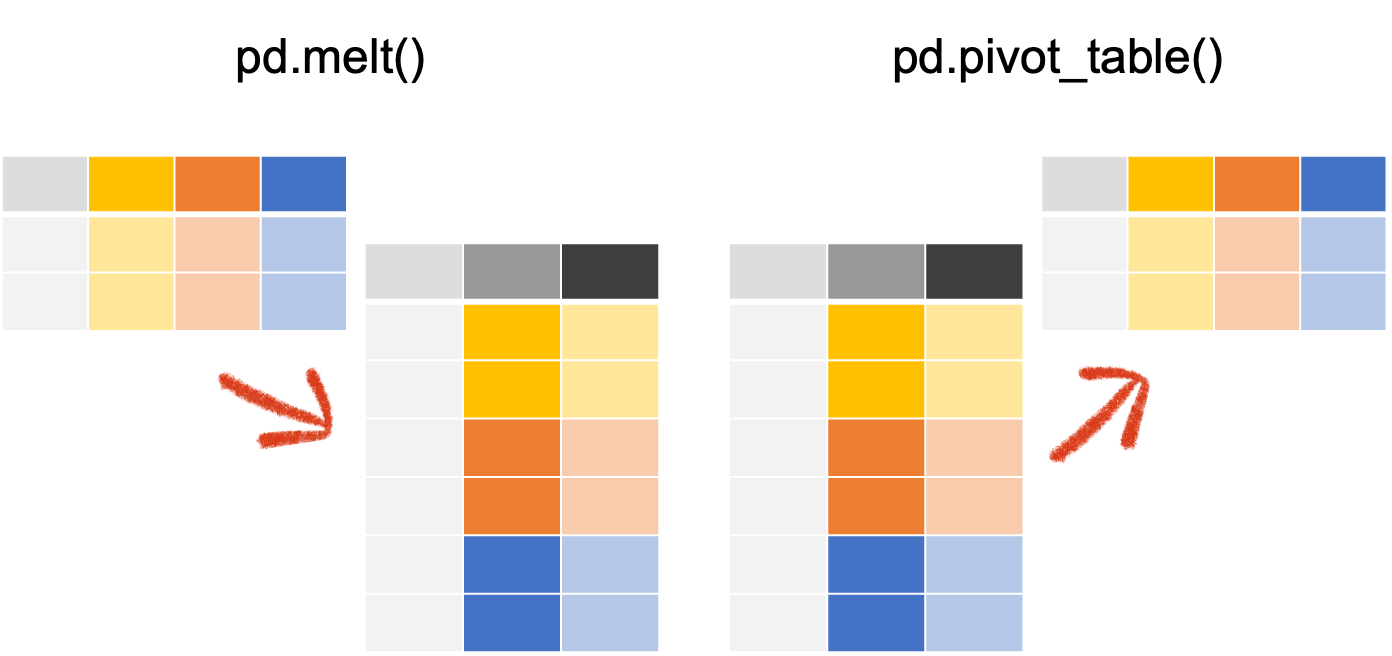
pd.melt()
: 이미 집계된 형태의 데이터를 다시 세로로 나열하는 메서드
pd.melt(df, id_vars=None, value_vars=None, var_name=None, value_name='value')
df.melt(id_vars=None, value_vars=None, var_name=None, value_name='value')id_vars : 유지할 컬럼
value_vars : 변환할 컬럼
var_name : 변환 후 생성되는 컬럼 이름
value_name : 변환 후 생성되는 값 컬럼 이름
pd.pivot_table()
: 세로로 나열된 형태를 가로로 집계된 형태로 나열
값을 집계하고 모양도 바꿀 수 있음 (행, 열 지정)
df.pivot_table(values=None, index=None, columns=None, aggfuc='mean')values : 집계값
index : 집계기준(행)
columns : 집계기준(열)
aggfunc : 집계방식
- pivot_table을 사용하기 위해서는 숫자로 된 컬럼이 있어야 집계가 가능한데, 예제에서 거래액이 숫자로 보이지만 type을 확인해보니 int, str이 모두 있음
# list comprehension으로 컬럼 데이터의 모든 타입 리스트로 확인 후 set으로 중복 제외하여 unique값만 확인
set([type(i) for i in df['컬럼명']])
# 특정 컬럼이 int타입이 아닌 값만 리스트 출력
[i for i in df['컬럼명'] if type(i) != int]데이터 타입 변경
문자열을 정수로 변경하는 함수 선언
def strtoint(x):
# 데이터 타입이 문자열이면
if type(x) == str:
# '-' > '0' 변경 후 int로 변경
x = x.replace('-', '0') # 참고) replace는 문자열끼리만 바꿀 수 있음
x = int(x)
# 데이터 타입이 문자열이 x
else:
pass
return x
# 일괄적으로 함수 적용후 df에 적용
df['컬럼명'] = df['컬럼명'].apply(strtoint) 참고) pivot_table에서 기본적으로 사용하는 집계함수는 '평균'
→ 다른 연산을 하고자 한다면 aggfunc='' 옵션 사용
데이터셋에 필요하지 않은 값 빼기
행
df = df[df['컬럼명'] != '조건'] : 조건에 해당되지 않는 데이터만 추출하여 데이터셋에 적용
df = df[df['컬럼명'] == '조건'] : 조건에 해당되는 데이터만 추출하여 데이터셋에 적용
열
df.drop('컬럼명', axis = 'columns', (inplace = True))
- 컬럼명 기준으로 column 삭제
- axis = 'columns' → 1(열), 0(행)
- inplace = False (default)
- 원본 데이터를 변경하지 않는 메서드를 사용하는 경우 다시 한 번 변수에 지정하거나
inplace = True옵션 (지정할 수 있는 경우) 사용하여 결과값에 바로 반영 가능
컬럼 양식 불일치 해결
# " p" 제거
df['컬럼명'] = df['컬럼명'].apply(lambda x : x.replace(' p)', '')
# 날짜 값을 2017.01 → 2017/01 양식으로 (. → /) 변환
df['날짜'] = df['날짜'].apply(lambda x : x.replace(".", "/"))apply: 컬럼에 함수 적용- 간단한 함수는
lambda함수를 쓰면 따로 def로 정의하지 않아도 됨
저장하기
df.to_csv('파일경로+파일명.csv', encoding = 'cp949', index = False)- 저장할 때도 encoding 필요
index = False: 인덱스를 없애고 저장
(설정 안하면 인덱스가 새로운 컬럼으로 저장됨)
